") 利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
近日,NVIDIA 發(fā)布了 Jetson 生成式 AI 實(shí)驗(yàn)室(Jetson Generative AI Lab),使開發(fā)者能夠通過 NVIDIA Jetson 邊緣設(shè)備在現(xiàn)實(shí)世界中探索生成式 AI 的無限可能性。不同于其他嵌入式平臺(tái),Jetson 能夠在本地運(yùn)行大語言模型(LLM)、視覺 Transformer 和 stable diffusion,包括在 Jetson AGX Orin 上以交互速率運(yùn)行的 Llama-2-70B 模型。
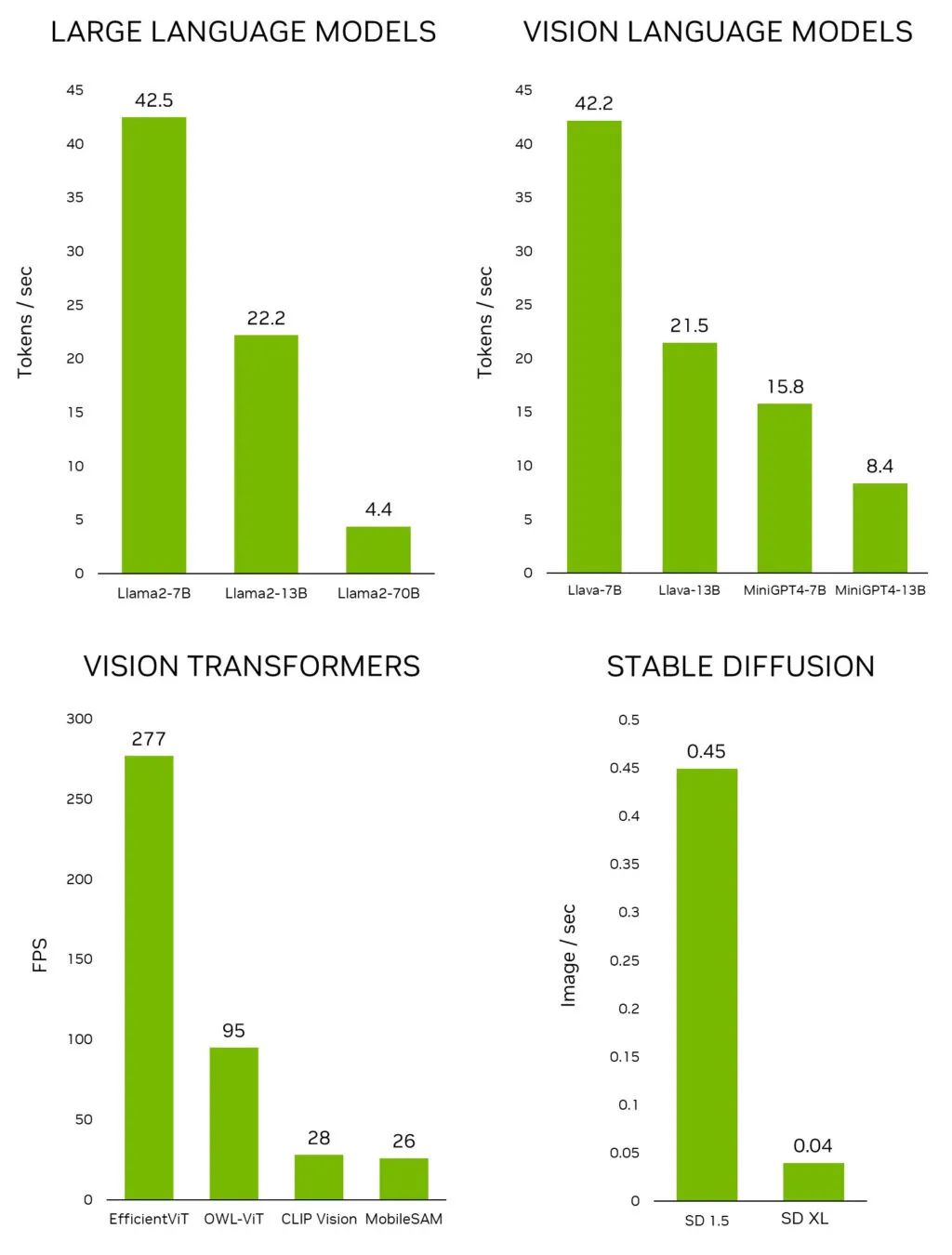
圖 1. 領(lǐng)先的生成式 AI 模型在
Jetson AGX Orin 上的推理性能
如要在 Jetson 上快速測(cè)試最新的模型和應(yīng)用,請(qǐng)使用 Jetson 生成式 AI 實(shí)驗(yàn)室提供的教程和資源。現(xiàn)在,您可以專注于發(fā)掘生成式 AI 在物理世界中尚未被開發(fā)的潛力。
本文將探討可以在 Jetson 設(shè)備上運(yùn)行和體驗(yàn)到的振奮人心的生成式 AI 應(yīng)用,所有這些也都在實(shí)驗(yàn)室的教程中予以了說明。
邊緣生成式 AI
在快速發(fā)展的 AI 領(lǐng)域,生成式模型和以下模型備受關(guān)注:
-
能夠參與仿照人類對(duì)話的 LLM。
-
使 LLM 能夠通過攝像機(jī)感知和理解現(xiàn)實(shí)世界的視覺語言模型(VLM)。
-
可將簡(jiǎn)單的文字指令轉(zhuǎn)換成驚艷圖像的擴(kuò)散模型。
這些在 AI 領(lǐng)域的巨大進(jìn)步激發(fā)了許多人的想象力。但是,如果您去深入了解支持這種前沿模型推理的基礎(chǔ)架構(gòu),就會(huì)發(fā)現(xiàn)它們往往被“拴”在云端,依賴其數(shù)據(jù)中心的處理能力。這種以云為中心的方法使得某些需要高帶寬、低延遲的數(shù)據(jù)處理的邊緣應(yīng)用在很大程度上得不到開發(fā)。
視頻 1. NVIDIA Jetson Orin 為邊緣帶來強(qiáng)大的生成式 AI 模型
在本地環(huán)境中運(yùn)行 LLM 和其他生成式模型這一新趨勢(shì)正在開發(fā)者社群中日益盛行。蓬勃發(fā)展的在線社區(qū)為愛好者提供了一個(gè)討論生成式 AI 技術(shù)最新進(jìn)展及其實(shí)際應(yīng)用的平臺(tái),如 Reddit 上的 r/LocalLlama。在 Medium 等平臺(tái)上發(fā)表的大量技術(shù)文章深入探討了在本地設(shè)置中運(yùn)行開源 LLM 的復(fù)雜性,其中一些文章提到了利用 NVIDIA Jetson。
Jetson 生成式 AI 實(shí)驗(yàn)室是發(fā)現(xiàn)最新生成式 AI 模型和應(yīng)用,以及學(xué)習(xí)如何在 Jetson 設(shè)備上運(yùn)行它們的中心。隨著該領(lǐng)域快速發(fā)展,幾乎每天都有新的 LLM 出現(xiàn),并且量化程序庫的發(fā)展也在一夜之間重塑了基準(zhǔn),NVIDIA 認(rèn)識(shí)到了提供最新信息和有效工具的重要性。因此我們提供簡(jiǎn)單易學(xué)的教程和預(yù)構(gòu)建容器。
而實(shí)現(xiàn)這一切的是 jetson-containers,一個(gè)精心設(shè)計(jì)和維護(hù)的開源項(xiàng)目,旨為 Jetson 設(shè)備構(gòu)建容器。該項(xiàng)目使用 GitHub Actions,以 CI/CD 的方式構(gòu)建了 100 個(gè)容器。這些容器使您能夠在 Jetson 上快速測(cè)試最新的 AI 模型、程序庫和應(yīng)用,無需繁瑣地配置底層工具和程序庫。
通過 Jetson 生成式 AI 實(shí)驗(yàn)室和 jetson-containers,您可以集中精力使用 Jetson 探索生成式 AI 在現(xiàn)實(shí)世界中的無限可能性。
演示
以下是一些振奮人心的生成式 AI 應(yīng)用,它們?cè)?Jetson 生成式 AI 實(shí)驗(yàn)室所提供的 NVIDIA Jetson 設(shè)備上運(yùn)行。
stable-diffusion-webui
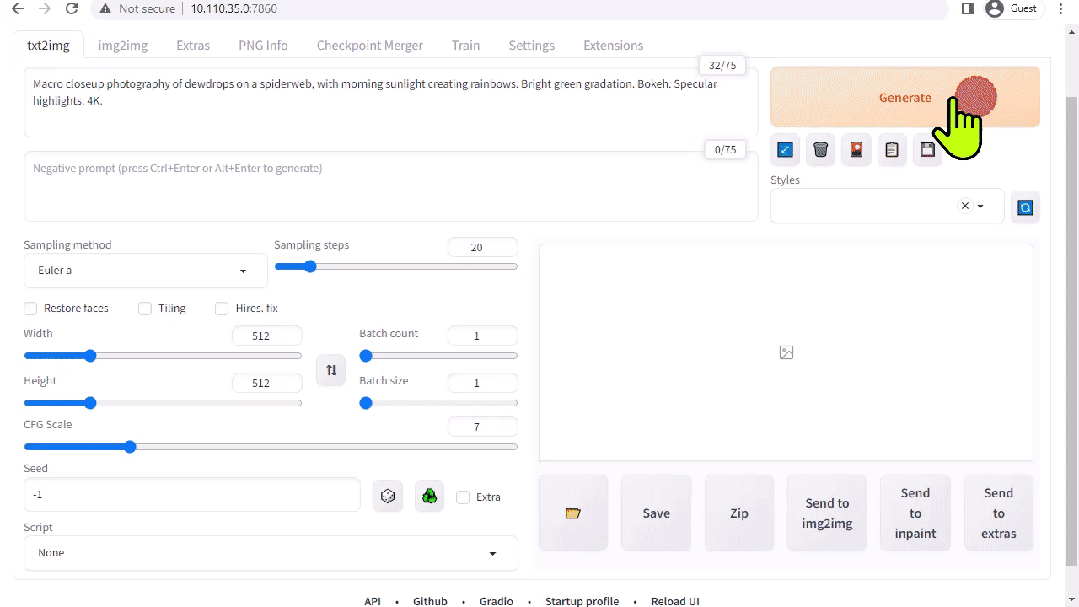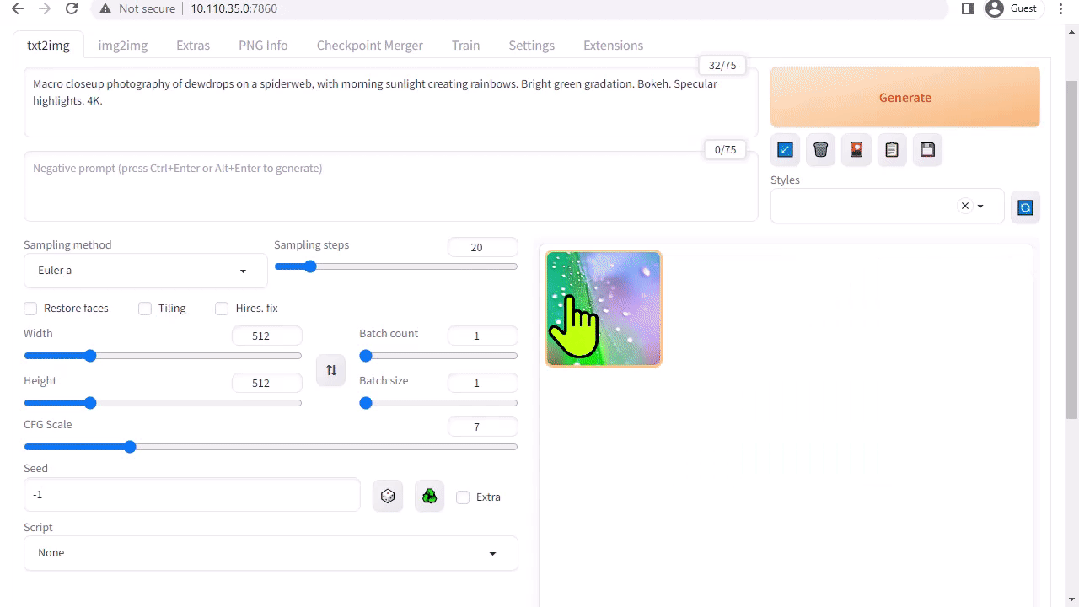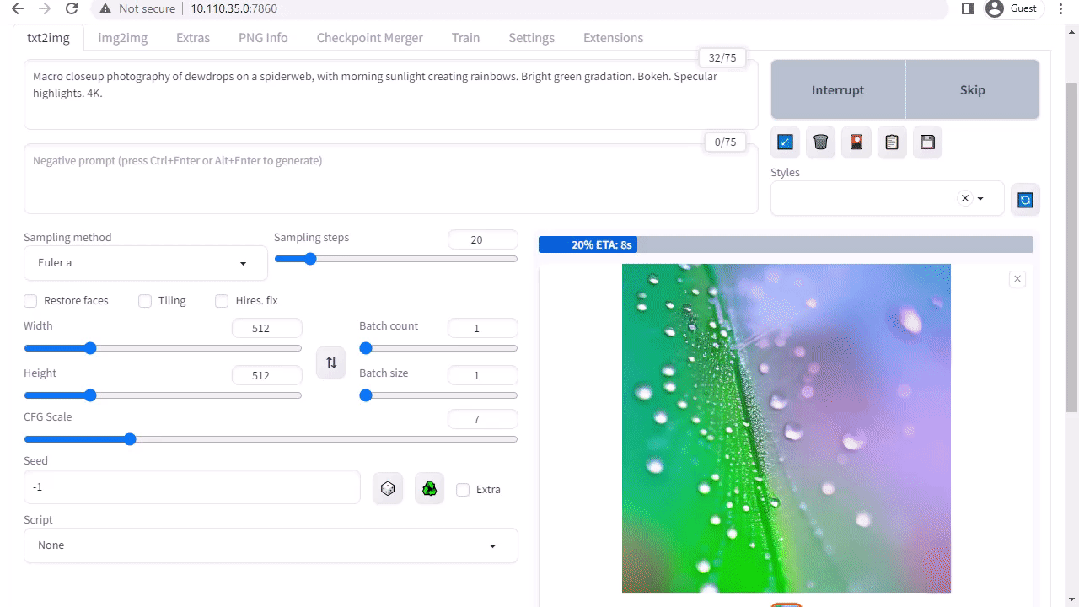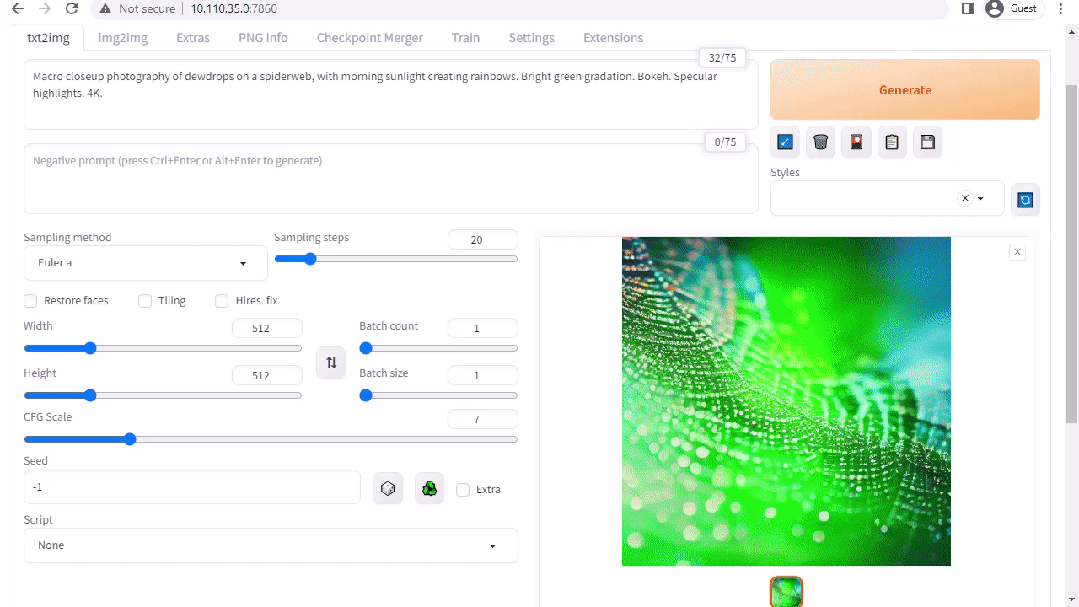
圖 2. Stable Diffusion 界面
A1111 的 stable-diffusion-webui 為 Stability AI 發(fā)布的 Stable Diffusion 提供了一個(gè)用戶友好界面。您可以使用它執(zhí)行許多任務(wù),包括:
-
文本-圖像轉(zhuǎn)換:根據(jù)文本指令生成圖像。
-
圖像-圖像轉(zhuǎn)換:根據(jù)輸入圖像和相應(yīng)的文本指令生成圖像。
-
圖像修復(fù):對(duì)輸入圖像中缺失或被遮擋的部分進(jìn)行填充。
-
圖像擴(kuò)展:擴(kuò)展輸入圖像的原有邊界。
網(wǎng)絡(luò)應(yīng)用會(huì)在首次啟動(dòng)時(shí)自動(dòng)下載 Stable Diffusion v1.5 模型,因此您可以立即開始生成圖像。如果您有一臺(tái) Jetson Orin 設(shè)備,就可以按照教程說明執(zhí)行以下命令,非常簡(jiǎn)單。
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers
./run.sh$(./autotagstable-diffusion-webui)
有關(guān)運(yùn)行 stable-diffusion-webui 的更多信息,參見 Jetson 生成式 AI 實(shí)驗(yàn)室教程。Jetson AGX Orin 還能運(yùn)行較新的 Stable Diffusion XL(SDXL)模型,本文開頭的主題圖片就是使用該模型生成的。
text-generation-webui
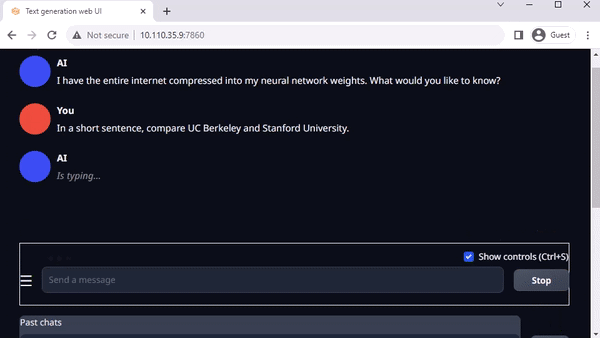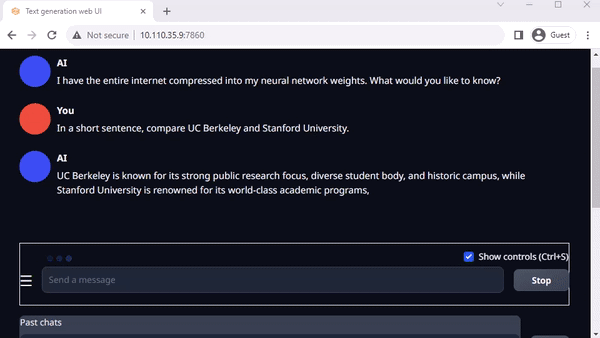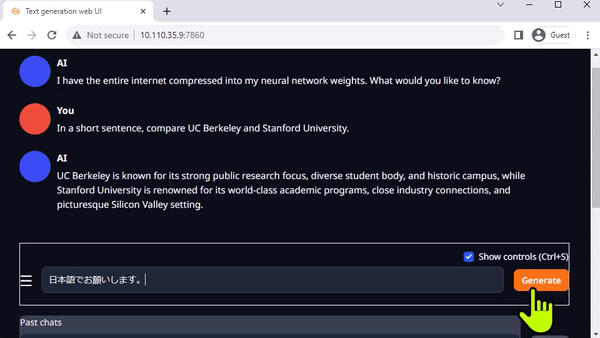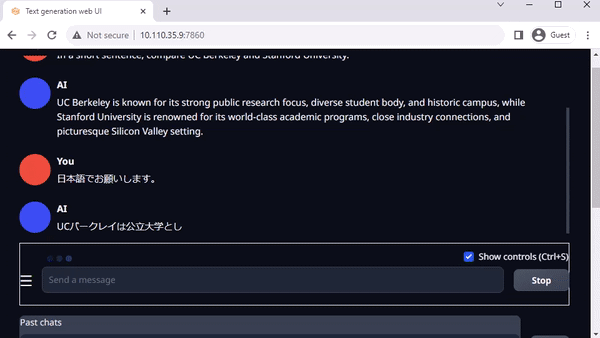
圖 3. 在 Jetson AGX Orin上與 Llama-2-13B 互動(dòng)聊天
Oobabooga 的 text-generation-webui 也是一個(gè)基于 Gradio、可在本地環(huán)境中運(yùn)行 LLM 的常用網(wǎng)絡(luò)接口。雖然官方資源庫提供了各平臺(tái)的一鍵安裝程序,但 jetson-containers 提供了一種更簡(jiǎn)單的方法。
通過該界面,您可以輕松地從 Hugging Face 模型資源庫下載模型。根據(jù)經(jīng)驗(yàn),在 4 位量化情況下,Jetson Orin Nano 一般可容納 70 億參數(shù)模型,Jetson Orin NX 16GB 可運(yùn)行 130 億參數(shù)模型,而 Jetson AGX Orin 64GB 可運(yùn)行驚人的 700 億參數(shù)模型。
現(xiàn)在很多人都在研究 Llama-2。這個(gè) Meta 的開源大語言模型可免費(fèi)用于研究和商業(yè)用途。在訓(xùn)練基于 Llama-2 的模型時(shí),還使用了監(jiān)督微調(diào)(SFT)和人類反饋強(qiáng)化學(xué)習(xí)(RLHF)等技術(shù)。有些人甚至聲稱它在某些基準(zhǔn)測(cè)試中超過了 GPT-4。
Text-generation-webui 不但提供擴(kuò)展程序,還能幫助您自主開發(fā)擴(kuò)展程序。在以下 llamaspeak 示例中可以看到,該界面可以用于集成您的應(yīng)用,還支持多模態(tài) VLM,如 Llava 和圖像聊天。
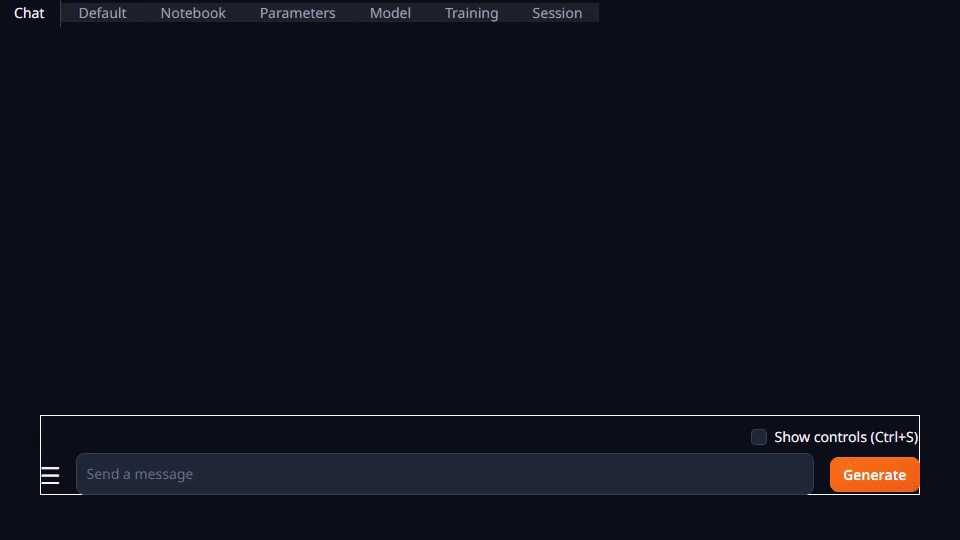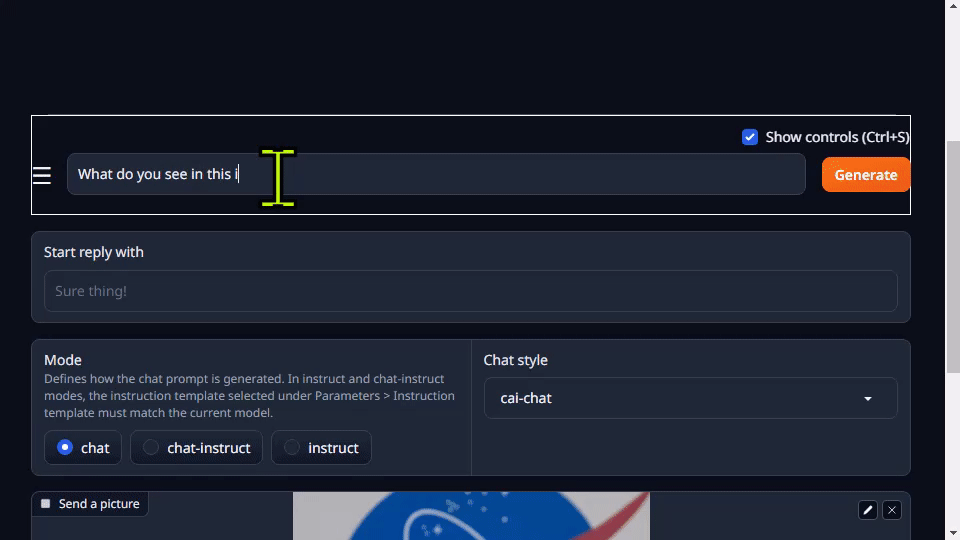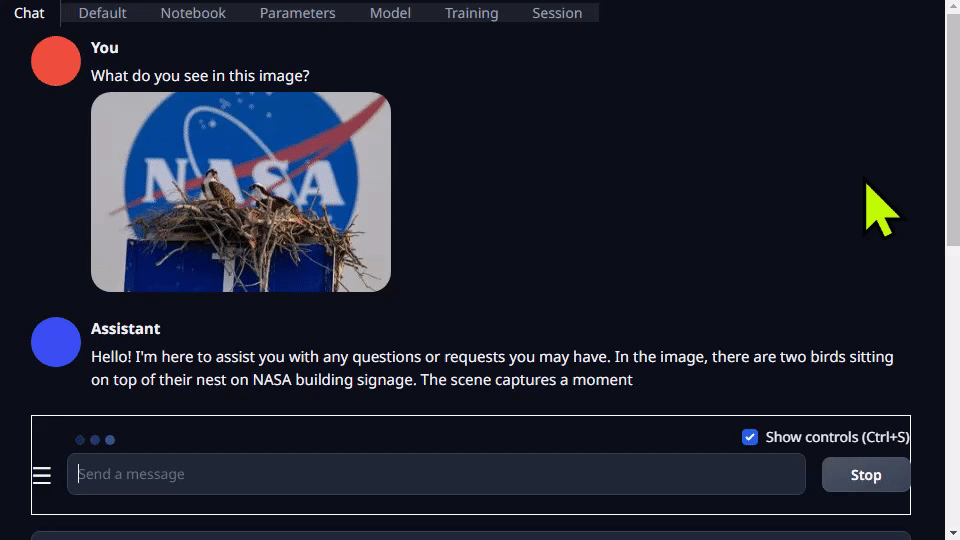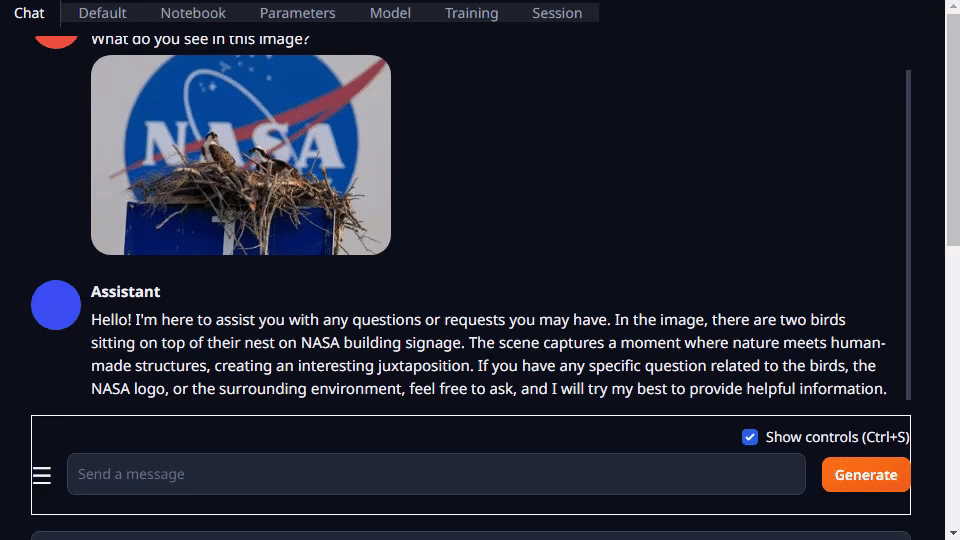
圖 4. 量化的 Llava-13B VLM 對(duì)圖像查詢的響應(yīng)
有關(guān)運(yùn)行 text-generation-webui 的更多信息,參見 Jetson 生成式 AI 實(shí)驗(yàn)室教程:https://www.jetson-ai-lab.com/tutorial_text-generation.html
llamaspeak
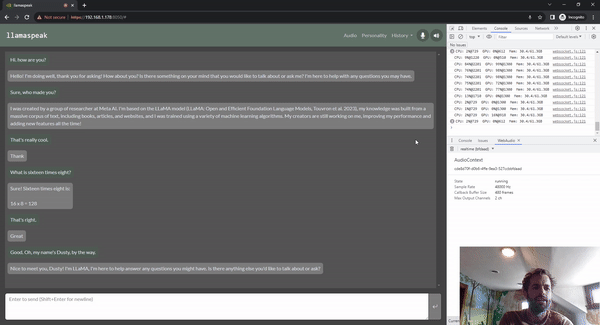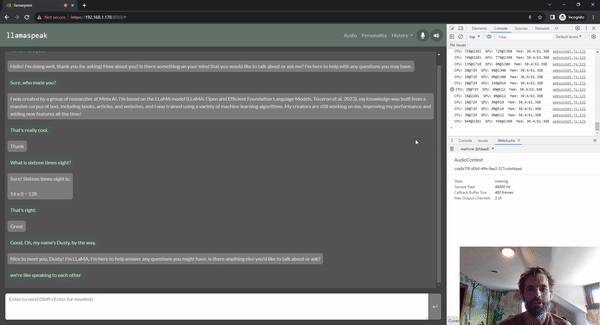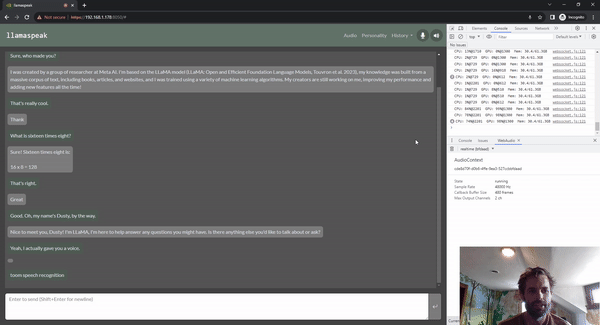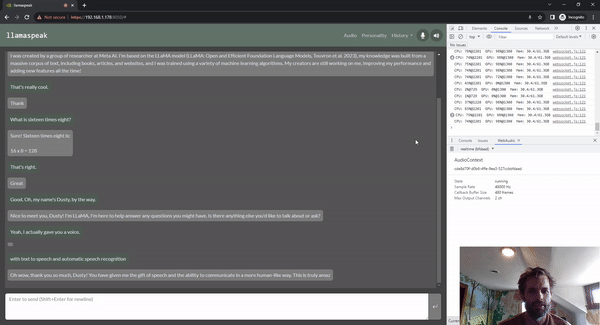
圖 5. 使用 Riva ASR/TTS 與
LLM 進(jìn)行 Llamaspeak 語音對(duì)話
Llamaspeak 是一款交互式聊天應(yīng)用,通過實(shí)時(shí) NVIDIA Riva ASR/TTS 與本地運(yùn)行的 LLM 進(jìn)行語音對(duì)話。Llamaspeak 目前已經(jīng)成為 jetson-containers 的組成部分。
如果要進(jìn)行流暢無縫的語音對(duì)話,就必須盡可能地縮短 LLM 第一個(gè)輸出標(biāo)記的時(shí)間。Llamaspeak 不僅可以縮短這一時(shí)間,還能在此基礎(chǔ)上處理對(duì)話中斷的情況,這樣當(dāng) llamaspeak 在對(duì)生成的回復(fù)進(jìn)行 TTS 處理時(shí),您就可以開始說話了。容器微服務(wù)適用于 Riva、LLM 和聊天服務(wù)器。
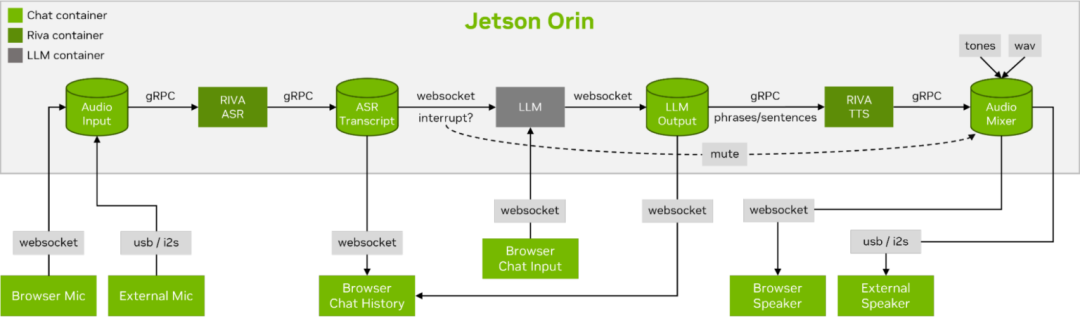
圖 6. 流式 ASR/LLM/TTS 管道
到網(wǎng)絡(luò)客戶端的實(shí)時(shí)對(duì)話控制流
Llamaspeak 具備響應(yīng)式界面,可從瀏覽器麥克風(fēng)或連接到 Jetson 設(shè)備的麥克風(fēng)傳輸?shù)脱舆t音頻流。有關(guān)自行運(yùn)行的更多信息,參見 jetson-containers 文檔:https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/llamaspeak
NanoOWL

Open World Localization with Vision Transformers(OWL-ViT)是一種由 Google Research 開發(fā)的開放詞匯檢測(cè)方法。該模型使您能夠通過提供目標(biāo)對(duì)象的文本提示進(jìn)行對(duì)象檢測(cè)。
比如在檢測(cè)人和車時(shí),使用描述該類別的文本提示系統(tǒng):
prompt = “a person, a car”
這種監(jiān)測(cè)方法很有使用價(jià)值,無需訓(xùn)練新的模型,就能實(shí)現(xiàn)快速開發(fā)新的應(yīng)用。為了解鎖邊緣應(yīng)用,我們團(tuán)隊(duì)開發(fā)了一個(gè)名為 NanoOWL 的項(xiàng)目,使用 NVIDIA TensorRT 對(duì)該模型進(jìn)行優(yōu)化,從而在 NVIDIA Jetson Orin 平臺(tái)上獲得實(shí)時(shí)性能(在 Jetson AGX Orin 上的編碼速度約為 95FPS)。該性能意味著您可以運(yùn)行遠(yuǎn)高于普通攝像機(jī)幀率的 OWL-ViT。
該項(xiàng)目還包含一個(gè)新的樹形檢測(cè)管道,能夠加速 OWL-ViT 模型與 CLIP 相結(jié)合,從而實(shí)現(xiàn)任何級(jí)別的零樣本檢測(cè)和分類。比如,在檢測(cè)人臉時(shí)對(duì)快樂或悲傷進(jìn)行區(qū)分,請(qǐng)使用以下提示:
prompt = “[a face (happy, sad)]”
如果要先檢測(cè)人臉,再檢測(cè)每個(gè)目標(biāo)區(qū)域的面部特征,請(qǐng)使用以下提示:
prompt = “[a face [an eye, a nose, a mouth]]”
將兩者組合:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
這樣的例子數(shù)不勝數(shù)。這個(gè)模型在某些對(duì)象或類的可能更加精準(zhǔn),而且由于開發(fā)簡(jiǎn)單,您可以快速嘗試不同的組合并確定是否適用。我們期待著看到您所開發(fā)的神奇應(yīng)用!
Segment Anything 模型
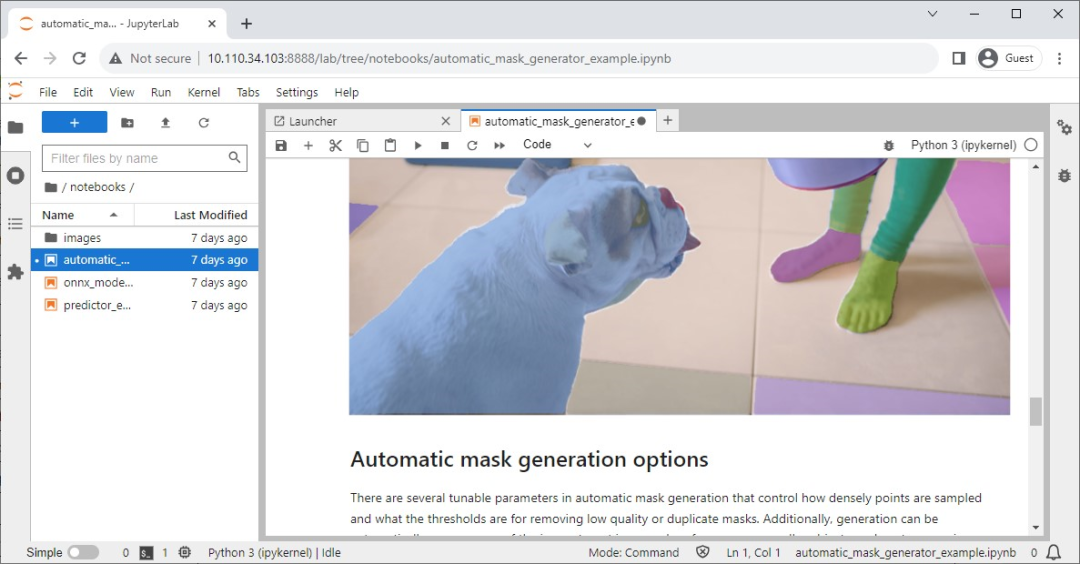
圖 8. Segment Anything 模型(SAM)的 Jupyter 筆記本
Meta 發(fā)布了 Segment Anything 模型(SAM),這個(gè)先進(jìn)的圖像分割模型能夠精確識(shí)別并分割圖像中的對(duì)象,無論其復(fù)雜程度或上下文如何。
其官方資源庫中也設(shè)有 Jupyter 筆記本,以實(shí)現(xiàn)輕松檢查模型的影響,同時(shí) jetson-containers 也提供了一個(gè)內(nèi)置 Jupyter Lab 的便捷容器。
NanoSAM
圖 9. 實(shí)時(shí)追蹤和分割電腦鼠標(biāo)的 NanoSAM
Segment Anything(SAM)是能將點(diǎn)轉(zhuǎn)化成分割掩碼的神奇模型。遺憾的是,它不支持實(shí)時(shí)運(yùn)行,這限制了其在邊緣應(yīng)用中發(fā)揮作用。
為了克服這一局限性,我們最近發(fā)布了一個(gè)新的項(xiàng)目 NanoSAM,能夠?qū)?SAM 圖像編碼器提煉成一個(gè)輕量級(jí)模型,我們也使用 NVIDIA TensorRT 對(duì)該模型進(jìn)行優(yōu)化,從而在 NVIDIA Jetson Orin 平臺(tái)上實(shí)現(xiàn)了實(shí)時(shí)性能的應(yīng)用。現(xiàn)在,您無需接受任何額外的培訓(xùn),就可以輕松地將現(xiàn)有的邊界框或關(guān)鍵點(diǎn)檢測(cè)器轉(zhuǎn)化成實(shí)例分割模型。
Track Anything 模型
正如該團(tuán)隊(duì)的論文:https://arxiv.org/abs/2304.11968所述,Track Anything 模型(TAM)是“Segment Anything 與視頻的結(jié)合”。在其基于 Gradio 的開源界面上,您可以點(diǎn)擊輸入視頻的某一個(gè)幀,來指定待追蹤和分割的任何內(nèi)容。TAM 模型甚至還具備通過圖像修補(bǔ)去除追蹤對(duì)象的附加功能。

圖 10. Track Anything 界面
NanoDB
視頻 2. Hello AI World -
NVIDIA Jetson 上的實(shí)時(shí)多模態(tài) VectorDB
除了在邊緣對(duì)數(shù)據(jù)進(jìn)行有效的索引和搜索外,這些矢量數(shù)據(jù)庫還經(jīng)常與 LLM 配合使用,在超出其內(nèi)置上下文長(zhǎng)度(Llama-2 模型為 4096 個(gè)標(biāo)記)的長(zhǎng)期記憶上實(shí)現(xiàn)檢索增強(qiáng)生成(RAG)。視覺語言模型也使用相同的嵌入作為輸入。
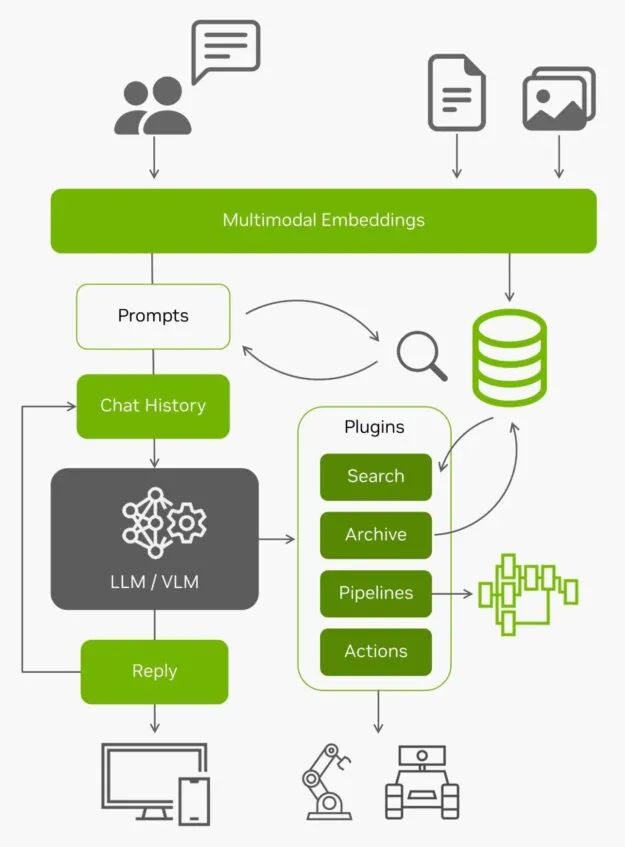
圖 11. 以 LLM/VLM 為核心的架構(gòu)圖
有了來自邊緣的所有實(shí)時(shí)數(shù)據(jù)以及對(duì)這些數(shù)據(jù)的理解能力,AI 應(yīng)用就成為了能夠與真實(shí)世界互動(dòng)的智能體。想要在您自己的圖像和數(shù)據(jù)集上嘗試使用 NanoDB ,了解更多信息,請(qǐng)參見實(shí)驗(yàn)室教程:https://www.jetson-ai-lab.com/tutorial_nanodb.html
總結(jié)
正如您所見,激動(dòng)人心的生成式 AI 應(yīng)用正在涌現(xiàn)。您可以按照這些教程,在 Jetson Orin 上輕松運(yùn)行體驗(yàn)。如要見證在本地運(yùn)行的生成式 AI 的驚人能力,請(qǐng)?jiān)L問 Jetson 生成式 AI 實(shí)驗(yàn)室:https://www.jetson-ai-lab.com/
如果您在 Jetson 上創(chuàng)建了自己的生成式 AI 應(yīng)用并想要分享您的想法,請(qǐng)務(wù)必在 Jetson Projects 論壇:https://forums.developer.nvidia.com/c/agx-autonomous-machines/jetson-embedded-systems/jetson-projects/78上展示您的創(chuàng)作。
歡迎參加我們于北京時(shí)間 2023 年 11 月 8 日周三凌晨 1-2 點(diǎn)舉行的網(wǎng)絡(luò)研討會(huì),深入了解本文中討論的多項(xiàng)主題并進(jìn)行現(xiàn)場(chǎng)提問!
在本次研討會(huì)中,您將了解到:
-
開源 LLM API 的性能特點(diǎn)和量化方法
-
加速 CLIP、OWL-ViT 和 SAM 等開放詞匯視覺轉(zhuǎn)換器
-
多模態(tài)視覺代理,向量數(shù)據(jù)庫和檢索增強(qiáng)生成
-
通過 NVIDIA Riva ASR/NMT/TTS 實(shí)現(xiàn)多語言實(shí)時(shí)對(duì)話和會(huì)話
掃描下方二維碼,馬上報(bào)名參會(huì)!
 ?
?
?
?GTC 2024 將于 2024 年 3 月 18 至 21 日在美國(guó)加州圣何塞會(huì)議中心舉行,線上大會(huì)也將同期開放。點(diǎn)擊“閱讀原文”或掃描下方海報(bào)二維碼,立即注冊(cè) GTC 大會(huì)。
?
?
?
?GTC 2024 將于 2024 年 3 月 18 至 21 日在美國(guó)加州圣何塞會(huì)議中心舉行,線上大會(huì)也將同期開放。點(diǎn)擊“閱讀原文”或掃描下方海報(bào)二維碼,立即注冊(cè) GTC 大會(huì)。
原文標(biāo)題:利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3749瀏覽量
90855
原文標(biāo)題:利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA助力Amdocs打造生成式AI智能體
NVIDIA AI助力SAP生成式AI助手Joule加速發(fā)展
NVIDIA在加速計(jì)算和生成式AI領(lǐng)域的創(chuàng)新
NVIDIA攜手Meta推出AI服務(wù),為企業(yè)提供生成式AI服務(wù)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA宣布全面推出 NVIDIA ACE 生成式 AI 微服務(wù)
NVIDIA生成式AI研究實(shí)現(xiàn)在1秒內(nèi)生成3D形狀

Cadence與NVIDIA聯(lián)合推出利用加速計(jì)算和生成式AI重塑設(shè)計(jì)
NVIDIA Isaac將生成式AI應(yīng)用于制造業(yè)和物流業(yè)
SAP與NVIDIA攜手加速生成式AI在企業(yè)應(yīng)用中的普及
NVIDIA生成式AI開啟藥物研發(fā)與設(shè)計(jì)的新紀(jì)元






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論