 如何實現一個多讀多寫的線程安全的無鎖隊列
如何實現一個多讀多寫的線程安全的無鎖隊列
在ZMQ無鎖隊列的原理與實現一文中,我們已經知道了ypipe可以實現一線程寫一線程讀的無鎖隊列,那么其劣勢就很明顯了,無法適應多寫多讀的場景,因為其在讀的時候沒有對r指針加鎖,在寫的時候沒有對w指針加鎖。那么如何實現一個多讀多寫的線程安全的無鎖隊列呢?
- 互斥鎖:mutexqueue(太簡單不介紹了)
- 互斥鎖+條件變量:blockqueue(太簡單不介紹了)
- 內存屏障:lockfreequeue(SimpleLockFreeQueue.h 暫時未寫文章介紹)
- 雙重CAS原子操作:arraylockfreequeue(本文)
2. ArrayLockFreeQueue的類接?和變量
該程序使用 gcc 內置的__sync_bool_compare_and_swap,但重新做了宏定義封裝。
所謂循環數組,就是RingBuffer

#define ARRAY_LOCK_FREE_Q_DEFAULT_SIZE 65535 // 2^16
template
class ArrayLockFreeQueue {
public:
ArrayLockFreeQueue();
virtual ~ArrayLockFreeQueue();
QUEUE_INT size();
bool enqueue(const ELEM_T &a_data);// ?隊列
bool dequeue(ELEM_T &a_data);// 出隊列
private:
ELEM_T m_thequeue[Q_SIZE];
volatile QUEUE_INT m_count;// 隊列內有多少元素
volatile QUEUE_INT m_writeIndex;//新元素?列時存放位置在數組中的下標
volatile QUEUE_INT m_readIndex;//下?個出列元素在數組中的下標
volatile QUEUE_INT m_maximumReadIndex;最后?個已經完成?列操作的元素在數組中的下標
//取余
inline QUEUE_INT countToIndex(QUEUE_INT a_count);
};
2.1 變量介紹
- m_count:隊列的元素個數
- m_writeIndex:新元素?列時存放位置在數組中的下標
- m_readIndex:下?個出列元素在數組中的下標
- m_maximumReadIndex:最后?個已經完成?列操作的元素在數組中的下標。如果它的值跟m_writeIndex不?致,表明有寫請求尚未完成。這意味著,有寫請求成功申請了空間但數據還沒完全寫進隊列。所以如果有線程要讀取,必須要等到寫線程將數據完全寫?到隊列之后。
必須指明的是使?3種不同的下標都是必須的,因為隊列允許任意數量的?產者和消費者圍繞著它?作。已經存在?種基于循環數組的?鎖隊列,使得唯?的?產者和唯?的消費者可以良好的?作。它的實現相當簡潔?常值得閱讀。
2.2 函數介紹
2.2.1 取余函數QUEUE_INT countToIndex(QUEUE_INT a_count);
這個函數非常有用,因為我們實現的是循環隊列,所以一定要對數組長度取余。
inline QUEUE_INT ArrayLockFreeQueue::countToIndex(QUEUE_INT a_count) {
return (a_count % Q_SIZE); // 取余的時候
},>
隊列已滿判斷如下
countToIndex(currentWriteIndex + 1) == countToIndex(currentReadIndex)
隊列為空判斷如下
countToIndex(currentReadIndex) == countToIndex(currentMaximumReadIndex)
需要C/C++ Linux服務器架構師學習資料加qun812855908獲取(資料包括C/C++,Linux,golang技術,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK,ffmpeg等),免費分享

2.2.2 文字舉例
2.2.2.1 入隊函數bool enqueue(const ELEM_T &a_data);
下面以文字舉例說明函數,后續再圖示舉例。
假設現在有兩個線程都進入了enqueue這個函數,m_writeIndex,m_readIndex和m_maximumReadIndex都為0。
- 線程1在第一個while和CAS處:
currentReadIndex = 0
CAS(0,0,1)----> m_writeIndex = 1
m_maximumReadIndex = 0
- 線程2在第一個while和CAS處:
currentReadIndex = 0
CAS(1,0,1)----> m_writeIndex = m_writeIndex false
while再次循環
currentWriteIndex = 1
currentReadIndex = 0
CAS(1,1,2)----> m_writeIndex = 2
m_maximumReadIndex = 0
- 線程2在第二個while和CAS處:
yidld讓出CPU
此時線程1執行↓
- 線程1在第二個while和CAS處:
執行結束,此時線程2恢復執行
- 線程2在第二個while和CAS處:
執行結束
bool ArrayLockFreeQueue::enqueue(const ELEM_T &a_data) {
QUEUE_INT currentWriteIndex; // 獲取寫指針的位置
QUEUE_INT currentReadIndex;
// 1. 獲取可寫入的位置
do {
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex)) {
return false; // 隊列已經滿了
}
// 目的是為了獲取一個能寫入的位置
} while (!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex + 1)));
// 獲取寫入位置后 currentWriteIndex 是一個臨時變量,保存我們寫入的位置
// We know now that this index is reserved for us. Use it to save the data
m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把數據更新到對應的位置
// 2. 更新可讀的位置,按著m_maximumReadIndex+1的操作
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while (!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1))) {
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield(); // 當線程超過cpu核數的時候如果不讓出cpu導致一直循環在此。
}
//printf("m_writeIndex:%d currentWriteIndex:%d m_maximumReadIndex:%dn",m_writeIndex,currentWriteIndex,m_maximumReadIndex);
AtomicAdd(&m_count, 1);
return true;
},>
2.2.2.2 出隊函數bool dequeue(ELEM_T &a_data);
下面以文字舉例說明函數,后續再圖示舉例。
假設現在有兩個線程都進入了dequeue這個函數,currentReadIndex為0,currentMaximumReadIndex為2。
- 線程1執行
currentMaximumReadIndex = 2
data = m_thequeue[0]
CAS(0,0,1) ----> m_readIndex = 1
- 線程2執行
currentMaximumReadIndex = 2
data = m_thequeue[0]
CAS(1,0,1) ----> m_readIndex = m_readIndex false
while再循環
currentReadIndex = 1
currentMaximumReadIndex = 2
data = m_thequeue[1]
CAS(1,1,2) ----> m_readIndex = 2
如果沒有新數據寫入,再次讀取數據,則currentReadIndex(2)==currentMaximumReadIndex(2)相等,return false,沒有數據可讀。
bool ArrayLockFreeQueue::dequeue(ELEM_T &a_data) {
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do {
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex)) // 如果不為空,獲取到讀索引的位置
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_thequeue[countToIndex(currentReadIndex)]; // 從臨時位置讀取的
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1))) {
//printf("m_readIndex:%d currentReadIndex:%d m_maximumReadIndex:%dn",m_readIndex,currentReadIndex,m_maximumReadIndex);
AtomicSub(&m_count, 1); // 真正讀取到了數據,元素-1
return true;
}
} while (true);
assert(0);
// Add this return statement to avoid compiler warnings
return false;
},>
2.2.3 圖示舉例
2.2.3.1 入隊函數bool enqueue(const ELEM_T &a_data);
下面的圖我就不分目錄了,直接一口氣說明完。
以下插圖展示了對隊列執?操作時各下標是如何變化的。如果?個位置被標記為X,標識這個位置?存放了數據。空?表示位置是空的。對于下圖的情況,隊列中存放了兩個元素。WriteIndex指示的位置是新元素將會被插?的位置。ReadIndex指向的位置中的元素將會在下?次pop操作中被彈出。

當?產者準備將數據插?到隊列中,它?先通過增加WriteIndex的值來申請空間。MaximumReadIndex指向最后?個存放有效數據的位置(也就是實際的隊列尾)。

?旦空間的申請完成,?產者就可以將數據拷?到剛剛申請到的位置中。完成之后增加MaximumReadIndex使得它與WriteIndex的?致。

現在隊列中有3個元素,接著?有?個?產者嘗試向隊列中插?元素。

在第?個?產者完成數據拷?之前,?有另外?個?產者申請了?個新的空間準備拷?數據。現在有兩個?產者同時向隊列插?數據。

現在?產者開始拷?數據,在完成拷?之后,對MaximumReadIndex的遞增操作必須嚴格遵循?個順序:第?個?產者線程?先遞增MaximumReadIndex,接著才輪到第?個?產者。這個順序必須被嚴格遵守的原因是,我們必須保證數據被完全拷?到隊列之后才允許消費者線程將其出列。讓出cpu的?的也是為了讓排在最前?的?產者完成m_maximumReadIndex的更新
sched_yield(); // 當線程超過cpu核數的時候如果不讓出cpu導致一直循環在此。
}

第?個?產者完成了數據拷?,并對MaximumReadIndex完成了遞增,現在第?個?產者可以遞增MaximumReadIndex了。

第?個?產者完成了對MaximumReadIndex的遞增,現在隊列中有5個元素。
bool ArrayLockFreeQueue::enqueue(const ELEM_T &a_data) {
QUEUE_INT currentWriteIndex; // 獲取寫指針的位置
QUEUE_INT currentReadIndex;
// 1. 獲取可寫入的位置
do {
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex)) {
return false; // 隊列已經滿了
}
// 目的是為了獲取一個能寫入的位置
} while (!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex + 1)));
// 獲取寫入位置后 currentWriteIndex 是一個臨時變量,保存我們寫入的位置
// We know now that this index is reserved for us. Use it to save the data
m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把數據更新到對應的位置
// 2. 更新可讀的位置,按著m_maximumReadIndex+1的操作
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while (!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1))) {
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield(); // 當線程超過cpu核數的時候如果不讓出cpu導致一直循環在此。
}
// printf("m_writeIndex:%d currentWriteIndex:%d m_maximumReadIndex:%dn",m_writeIndex,currentWriteIndex,m_maximumReadIndex);
AtomicAdd(&m_count, 1);
return true;
},>
2.2.3.2 出隊函數bool dequeue(ELEM_T &a_data);
以下插圖展示了元素出列的時候各種下標是如何變化的,隊列中初始有2個元素。WriteIndex指示的位置是新元素將會被插?的位置。ReadIndex指向的位置中的元素將會在下?次pop操作中被彈出。

消費者線程拷?數組ReadIndex位置的元素,然后嘗試?CAS操作將ReadIndex加1。如果操作成功消費者成功的將數據出列。因為CAS操作是原?的,所以只有唯?的線程可以在同?時刻更新ReadIndex的值。如果操作失敗,讀取新的ReadIndex值,以重復以上操作(copy數據,CAS)。

現在?有?個消費者將元素出列,隊列變成空。

現在有?個?產者正在向隊列中添加元素。它已經成功的申請了空間,但尚未完成數據拷?。任何其它企圖從隊列中移除元素的消費者都會發現隊列?空(因為writeIndex不等于readIndex)。但它不能讀取readIndex所指向位置中的數據,因為readIndex與MaximumReadIndex相等(相等break)。直到?產者完成數據拷?增加MaximumReadIndex的值才能讀取這個數據。

當?產者完成數據拷?,隊列的??是1,消費者線程可以讀取這個數據了。
bool ArrayLockFreeQueue::dequeue(ELEM_T &a_data) {
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do {
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex)) // 如果不為空,獲取到讀索引的位置
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_thequeue[countToIndex(currentReadIndex)]; // 從臨時位置讀取的
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1))) {
//printf("m_readIndex:%d currentReadIndex:%d m_maximumReadIndex:%dn",m_readIndex,currentReadIndex,m_maximumReadIndex);
AtomicSub(&m_count, 1); // 真正讀取到了數據,元素-1
return true;
}
} while (true);
assert(0);
// Add this return statement to avoid compiler warnings
return false;
},>
2.2.4 計算隊列的大小size函數的ABA問題與解決方案
QUEUE_INT ArrayLockFreeQueue::size() {
QUEUE_INT currentWriteIndex = m_writeIndex;
QUEUE_INT currentReadIndex = m_readIndex;
if (currentWriteIndex >= currentReadIndex)
return currentWriteIndex - currentReadIndex;
else
return Q_SIZE + currentWriteIndex - currentReadIndex;
},>
下面的場景描述了 size 為何會返回一個不正確的值:
2. 之后操作線程被搶占,且在它停止運行的這段時間內,有 2 個元素被插入和從隊列中移除。所以 m_writeIndex=5,m_readIndex = 4,而 size 還是 1;
3. 現在被搶占的線程恢復執行,讀取 m_readIndex 值,這個時候 currentReadIndex=4,currentWriteIndex=3;
4. currentReadIndex > currentWriteIndex'所以 m_totalSize + currentWriteIndex - currentReadIndex`被返回,這個值意味著隊列幾乎是滿的,而實際上隊列幾乎是空的。
解決方案:添加一個用于保存隊列中元素數量的成員 count.這個成員可以通過 AtomicAdd/AtomicSub 來實現原子的遞增和遞減。
但需要注意的是這增加了一定開銷,因為原子遞增,遞減操作比較昂貴也很難被編譯器優化。如果可以容忍size函數的ABA問題,則可以不用count與AtomicAdd/AtomicSub。使用者可以根據自己的使用場合選擇是否承受額外的運行時開銷。
2.2.5 與智能指針一起使用,內存無法得到釋放
如果你打算用這個隊列來存放智能指針對象.需要注意,將一個智能指針存入隊列之后,如果它所占用的位置沒有被另一個智能指針覆蓋,那么它所指向的內存是無法被釋放的(因為它的引用計數器無法下降為 0).這對于一個操作頻繁的隊列來說沒有什么問題,但是程序員需要注意的是,一旦隊列被填滿過一次那么應用程序所占用的內存就不會下降,即使隊列被清空.除非自己做改動,每次 pop 手動 delete。
3. 多個?產者線程的情況下yielding處理器的必要性
讀者可能注意到了enqueue函數中使?了sched_yield()來主動的讓出處理器,對于?個聲稱?鎖的算法??,這個調?看起來有點奇怪。正如?章開始的部分解釋過的,多線程環境下影響性能的其中?個因素就是Cache損壞。?產?Cache損壞的?種情況就是?個線程被搶占,操作系統需要保存被搶占線程的上下?,然后將被選中作為下?個調度線程的上下?載?。此時Cache中緩存的數據都會失效,因為它是被搶占線程的數據?不是新線程的數據。
所以,當此算法調?sched_yield()意味著告訴操作系統:“我要把處理器時間讓給其它線程,因為我要等待某件事情的發?”。?鎖算法和通過阻塞機制同步的算法的?個主要區別在于?鎖算法不會阻塞在線程同步上,那么為什么在這?我們要主動請求操作系統搶占??呢?這個問題的答案沒那么簡單。它與有多少個?產者線程在并發的往隊列中存放數據有關:每個?產者線程所執?的CAS操作都必須嚴格遵循FIFO次序,?個?于申請空間,另?個?于通知消費者數據已經寫?完成可以被讀取了。
如果我們的應?程序只有唯?的?產者操作這個隊列,sche_yield()將永遠沒有機會被調?,第2個CAS操作永遠不會失敗。因為在?個?產者的情況下沒有?能破壞?產者執?這兩個CAS操作的FIFO順序。
?當多于?個?產者線程往隊列中存放數據的時候,問題就出現了。概括來說,?個?產者通過第1個CAS操作申請空間,然后將數據寫?到申請到的空間中,然后執?第2個CAS操作通知消費者數據準備完畢可供讀取了。這第2個CAS操作必須遵循FIFO順序,也就是說,如果A線程第?先執?完第?個CAS操作,那么它也要第1個執?完第2個CAS操作,如果A線程在執?完第?個CAS操作之后停?,然后B線程執?完第1個CAS操作,那么B線程將?法完成第2個CAS操作,因為它要等待A先完成第2個CAS操作。?這就是問題產?的根源。讓我們考慮如下場景,3個消費者線程和1個消費者線程:
- 線程1,2,3按順序調?第1個CAS操作申請了空間。那么它們完成第2個CAS操作的順序也應該與這個順序?致,1,2,3。
- 線程2?先嘗試執?第2個CAS,但它會失敗,因為線程1還沒完成它的第2此CAS操作呢。同樣對于線程3也是?樣的。
- 線程2和3將會不斷的調?它們的第2個CAS操作,直到線程1完成它的第2個CAS操作為?。
- 線程1最終完成了它的第2個CAS,現在線程3必須等線程2先完成它的第2個CAS。
- 線程2也完成了,最終線程3也完成。
在上?的場景中,?產者可能會在第2個CAS操作上?旋?段時間,?于等待先于它執?第1個CAS操作的線程完成它的第2次CAS操作。在?個物理處理器數量?于操作隊列線程數量的系統上,這不會有太嚴重的問題:因為每個線程都可以分配在??的處理器上執?,它們最終都會很快完成各?的第2次CAS操作。雖然算法導致線程處理忙等狀態,但這正是我們所期望的,因為這使得操作更快的完成。也就是說在這種情況下我們是不需要sche_yield()的,它完全可以從代碼中刪除。
但是,在?個物理處理器數量少于線程數量的系統上,sche_yield()就變得?關重要了。讓我們再次考查上?3個線程的場景,當線程3準備向隊列中插?數據:如果線程1在執?完第1個CAS操作,在執?第2個CAS操作之前被搶占,那么線程2,3就會?直在它們的第2個CAS操作上忙等(它們忙等,不讓出處理器,線程1也就沒機會執?,它們就只能繼續忙等,也就是說,如果不適用 sched_yield,一直自旋,那么可能多個線程同時阻塞在第二個 CAS 那兒),直到線程1重新被喚醒,完成它的第2個CAS操作。這就是需要sche_yield()的場合了,操作系統應該避免讓線程2,3處于忙等狀態。它們應該盡快的讓出處理器讓線程1執?,使得線程1可以把它的第2個CAS操作完成。這樣線程2和3才能繼續完成它們的操作。
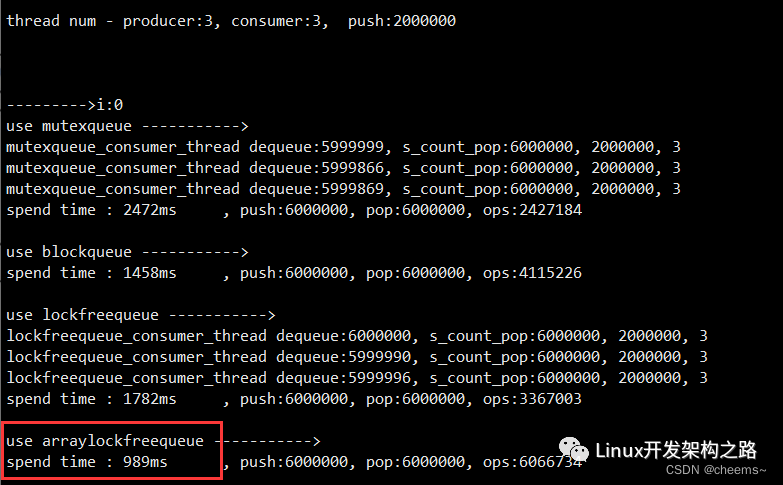
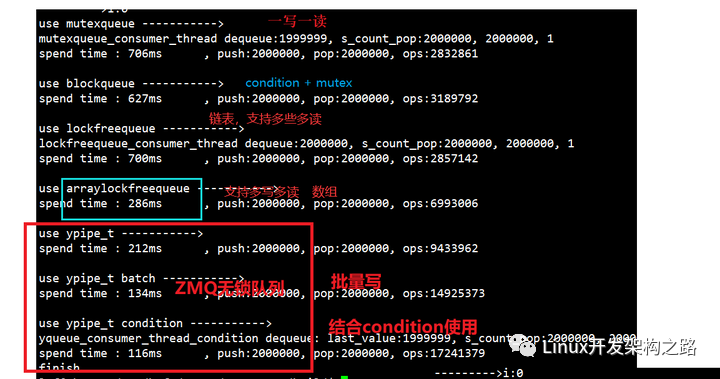
4. 循環數組無鎖隊列的性能測試
4.1 性能測試
互斥鎖隊列 vs 互斥鎖+條件變量隊列 vs 內存屏障鏈表 vs RingBuffer CAS 實現。
4寫1讀:性能中等

4寫4讀:性能中上

1寫4讀:性能最好

7寫7讀:性能比互斥鎖隊列還差

4.2 分析
雖然沒有分析第三個內存屏障鏈表的代碼,但是我們不難看出互斥鎖+條件變量 與 內存屏障鏈表 的性能差別不大。為什么呢?鏈表的方式需要不斷的申請和釋放元素。當然,用內存池可以適當改善這個影響,但是內存池在分配內存與釋放內存的時候也會涉及到線程間的數據競爭,所以用鏈表的方式性能相對提升不多。
隨著生產者數量的增加,無鎖隊列的效率迅速下降。因為在多個生產者的情況下,第 2 個 CAS 將對性能產生影響。我們通過測試得出循環數組的?鎖隊列在1寫4讀的場景下性能提升是最高的,因為只有一個生產者,那么第二個CAS不會有yield的情況出現。由此我們可以得出一個結論,在一寫多讀的場景,我們可以優先使用循環數組的?鎖隊列,比如下圖的場景。

-
接口
+關注
關注
33文章
8497瀏覽量
150834 -
封裝
+關注
關注
126文章
7780瀏覽量
142722 -
內存
+關注
關注
8文章
2999瀏覽量
73882 -
線程安全
+關注
關注
0文章
13瀏覽量
2456
發布評論請先 登錄
相關推薦
Linux下線程間通訊---讀寫鎖和條件變量
探索字節隊列的魔法:多類型支持、函數重載與線程安全

在MCU開發中使用多線程操作一寫一讀是否需要保護?
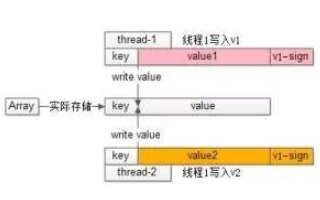

關于CAS等原子操作介紹 無鎖隊列的鏈表實現方法
發燒友實測 | i.MX8MP 編譯DPDK源碼實現rte_ring無鎖環隊列進程間通信

無鎖隊列解決的問題





 工商網監
工商網監
評論