") Linux內(nèi)核中的各種鎖介紹
Linux內(nèi)核中的各種鎖介紹
首先得搞清楚,不同鎖的作用對象不同。
下面分別是作用于臨界區(qū)、CPU、內(nèi)存、cache 的各種鎖的歸納:
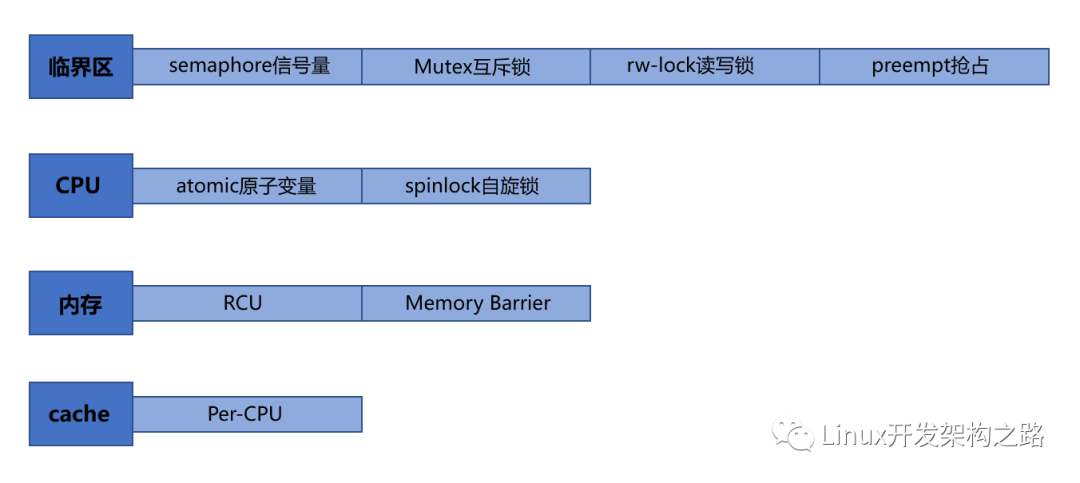
一、atomic原子變量/spinlock自旋鎖 — —CPU
既然是鎖CPU,那就都是針對多核處理器或多CPU處理器。單核的話,只有發(fā)生中斷會使任務(wù)被搶占,那么可以進入臨界區(qū)之前先關(guān)中斷,但是對多核CPU光關(guān)中斷就不夠了,因為對當前CPU關(guān)了中斷只能使得當前CPU不會運行其它要進入臨界區(qū)的程序,但其它CPU還是可能執(zhí)行進入臨界區(qū)的程序。
原子變量:
在x86多核環(huán)境下,多核競爭數(shù)據(jù)總線的時候,提供Lock指令鎖住總線,保證“讀-修改-寫”操作在芯片級的原子性。這個好說,我們一般對某個被多線程會訪問的變量設(shè)置為atomic類型的即可,比如atomic_int x;或atomic x;
自旋鎖:
當一個線程在獲取鎖的時候,如果鎖已經(jīng)被其它線程獲取,那么該線程將循環(huán)等待,然后不斷的判斷鎖是否能夠被成功獲取。使用實例如下:
#include < linux/spinlock.h >
// 定義自旋鎖
spinlock_t my_lock;
void my_function(void)
{
spin_lock(&my_lock);
// 訪問共享資源的操作
spin_unlock(&my_lock);
}
互斥鎖中,要是當前線程沒拿到鎖,就會出讓CPU;而自旋鎖中,要是當前線程沒有拿到鎖,當前線程在CPU上忙等待直到鎖可用,這是為了保證響應(yīng)速度更快。但是這種線程多了,那意味著多個CPU核都在忙等待,使得系統(tǒng)性能下降。
因此一定不能自旋太久,所以用戶態(tài)編程里用自旋鎖保護臨界區(qū)的話,這個臨界區(qū)一定要盡可能小,鎖的粒度得盡可能小。
為什么自旋鎖的響應(yīng)速度會比互斥鎖更快?
自旋鎖是通過 CPU 提供的 CAS 函數(shù)(Compare And Swap), =在「 用戶態(tài) 」完成加鎖和解鎖操作= **,不會主動產(chǎn)生線程上下文切換,所以相比互斥鎖來說,會快一些,開銷也小一些。**
而互斥鎖則不是,前面說互斥鎖加鎖失敗,線程會出讓CPU,這個過程其實是由內(nèi)核來完成線程切換的,因此加鎖失敗時,1)首先從用戶態(tài)切換至內(nèi)核態(tài),內(nèi)核會把線程的狀態(tài)從「運行」狀態(tài)設(shè)置為「睡眠」狀態(tài),然后把 CPU 切換給其他線程運行;2)當互斥鎖可用時,之前「睡眠」狀態(tài)的線程會變?yōu)椤妇途w」狀態(tài)(要進入就緒隊列了),之后內(nèi)核會在合適的時間,把 CPU 切換給該線程運行。
然后返回用戶態(tài)。
這個過程中,不僅有用戶態(tài)到內(nèi)核態(tài)的切換開銷,還有兩次線程上下文切換的開銷。
線程的上下文切換主要是線程棧、寄存器、線程局部變量等。
而自旋鎖在當前線程獲取鎖失敗時不會進行線程的切換,而是一直循環(huán)等待直到獲取鎖成功。因此,自旋鎖不會切換至內(nèi)核態(tài),也沒有線程切換開銷。
所以如果這個鎖被占有的時間很短,或者說各個線程對臨界區(qū)是快進快出,那么用自旋鎖是開銷最小的!
自旋鎖的缺點前面也說了,就是如果自旋久了或者自旋的線程數(shù)量多了,CPU的利用率就下降了,因為上面執(zhí)行的每個線程都在忙等待— —占用了CPU但什么事都沒做。
二、信號量/互斥鎖 — —臨界區(qū)
信號量:
信號量(信號燈)本質(zhì)是一個計數(shù)器,是描述臨界區(qū)中可用資源數(shù)目的計數(shù)器。
信號量為3,表示可用資源為3。加入初始信號量為3,某時刻信號量為1,說明可用資源數(shù)為1,那么有2個進程/線程在使用資源或者說有兩個資源被消耗了(具體資源是什么得看具體情況)。進程對信號量有PV操作,P操作就是進入共享資源區(qū)前-1,V操作就是離開共享資源后+1(這個時候信號量就表明還可以允許多少個進程進入該臨界區(qū))。
信號量進行多線程通信編程的時候,往往初始化信號量為0,然后用兩個函數(shù)做線程間同步:
sem_wait():等待信號量,如果信號量的值大于0,將信號量的值減1,立即返回。如果信號量的值為0,則線程阻塞。
sem_post():釋放資源,信號量+1 ,相當于unlock,這樣執(zhí)行了sem_wait()的線程就不阻塞了。
要注意:信號量本身也是個共享資源,它的++操作(釋放資源)和--操作(獲取資源)也需要保護。其實就是用的自旋鎖保護的。如果有中斷的話,會把中斷保存到eflags寄存器,待操作完成,就去該寄存器上讀取,然后執(zhí)行中斷。
struct semaphore {
spinlock_t lock; // 自旋鎖
unsigned int count;
struct list_head wait_list;
};
互斥鎖:
信號量的話表示可用資源的數(shù)量,是允許多個進程/線程在臨界區(qū)的。但是互斥鎖不是,它的目的就是只讓一個線程進入臨界區(qū),其余線程沒拿到鎖,就只能阻塞等待。線程互斥的進入臨界區(qū),這就是互斥鎖名字由來。
另外提一下std::timed_mutex睡眠鎖,它和互斥鎖的區(qū)別是:
互斥鎖中,沒拿到鎖的線程就一直阻塞等待,而睡眠鎖則是設(shè)置一定的睡眠時間比如2s,線程睡眠2s,如果過了之后還沒拿到鎖,那就放棄拿鎖(可以輸出獲取鎖失敗),如果拿到了,那就繼續(xù)做事。比如 用成員函數(shù)try_lock_for()
std::timed_mutex g_mutex;
//先睡2s再去搶鎖
if(g_mutex.try_lock_for(std::chrono::seconds(2)))){
// do something
}
else{
// 沒搶到
std::cout< "獲取鎖失敗";
}
三、讀寫鎖/搶占 — —臨界區(qū)
讀寫鎖:
用于讀操作比寫操作更頻繁的場景,讓讀和寫分開加鎖,這樣可以減小鎖的粒度,提高程序的性能。
它允許多個線程同時讀取共享資源,但只允許一個線程寫入共享資源。這可以提高并發(fā)性能,因為讀操作通常比寫操作頻繁得多。讀寫鎖這種就屬于高階鎖了,它的實現(xiàn)就可以用自旋鎖。
搶占:
搶占必須涉及進程上下文的切換,而中斷則是涉及中斷上下文的切換。
內(nèi)核從2.6開始就支持內(nèi)核搶占,之前的內(nèi)核不支持搶占,只要進程在占用CPU且時間片沒用完,除非有中斷,否則它就能一直占用CPU;
搶占的情況:
比如某個優(yōu)先級高的任務(wù)(進程),因為需要等待資源,就主動讓出CPU(又或者因為中斷被打斷了),然后低優(yōu)先級的任務(wù)先占用CPU,當資源到了,內(nèi)核就讓該優(yōu)先級高的任務(wù)搶占那個正在CPU上跑的任務(wù)。也就是說,當前的優(yōu)先級低的進程跑著跑著,時間片沒用完,也沒發(fā)生中斷,但是自己被踢掉了。
為了支持內(nèi)核搶占,內(nèi)核引入了preempt_count字段,該計數(shù)初始值為0,每當使用鎖時+1,釋放鎖時-1。當preempt_count為0時,表示內(nèi)核可以安全的搶占,大于0時,則禁止內(nèi)核搶占
Per-CPU— —作用于cache
per-cpu變量用于解決各個CPU里L2 cache和內(nèi)存間的數(shù)據(jù)不一致性。
四、RCU機制/內(nèi)存屏障 — —內(nèi)存
RCU機制是read copy update,即讀 復(fù)制 更新。
和讀寫鎖一樣,RCU機制也是允許多個讀者同時讀,但更新數(shù)據(jù)的時候,需要先復(fù)制一份副本,在副本上完成修改,然后再一次性地替換舊數(shù)據(jù)。
比如鏈表里修改某個節(jié)點的數(shù)據(jù),先拷貝該節(jié)點出來,修改里面的值,然后把節(jié)點前的指針指向拷貝出的節(jié)點
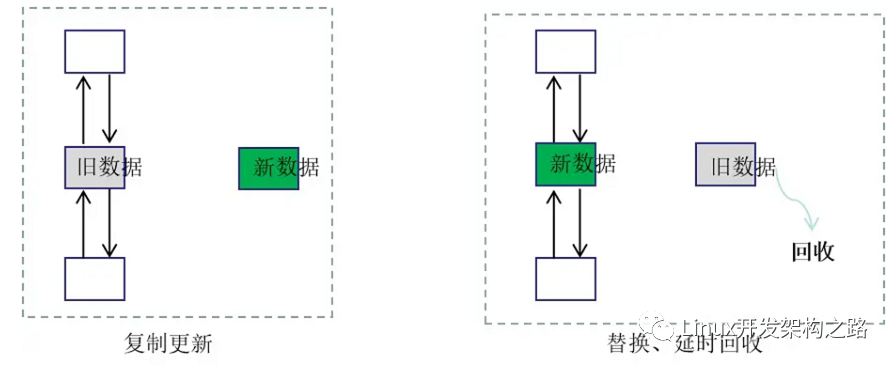
等到舊數(shù)據(jù)沒有人要讀的時,就把該內(nèi)存回收。
所以RCU機制的核心有兩個:1)復(fù)制后更新;2)延遲回收內(nèi)存
有RCU機制的話,讀寫就不需要做同步,也不會發(fā)生讀寫競爭了,因為讀者是對原來的數(shù)據(jù)進行讀,而寫者是對拷貝出來的那份內(nèi)存進行修改,讀寫可以并行。
他們的讀寫是根據(jù)內(nèi)存的指針來進行的,寫者寫完之后,就把舊讀者的指針賦值為新的數(shù)據(jù)的指針,指針的賦值操作是原子的,這樣新的讀者將訪問新數(shù)據(jù)。
舊內(nèi)存由一個線程專門負責回收。
內(nèi)存屏障:
內(nèi)存屏障則是用于控制內(nèi)存訪問順序,確保指令的執(zhí)行順序符合預(yù)期。
因為代碼往往不是看我們寫的這種順序被執(zhí)行的,它有兩個層面的亂序:
1)編譯器層面的。因為編譯器的優(yōu)化往往會對代碼的匯編指令進行重排
2)CPU層面的。多 CPU 間存在內(nèi)存亂序訪問的情況。
內(nèi)存屏障就是讓編譯器或CPU對內(nèi)存的訪問有序。
編譯時的亂序訪問:
int x, y, r;
void f()
{
x = r;
y = 1;
}
開了優(yōu)化選項后編譯,得到的匯編可能是y = 1先執(zhí)行,再x =r執(zhí)行。可以用g++ -O2 -S test.cpp生成匯編代碼,查看開了-O2優(yōu)化后的匯編:
我們可以使用內(nèi)核提供的宏函數(shù)barrier()來避免編譯器的這種亂序:
#define barrier() __asm__ __volatile__("" ::: "memory")
int x, y, r;
void f()
{
x = r;
__asm__ __volatile__("" ::: "memory");
y = 1;
}
或者將涉及到的相關(guān)變量x和y用volatile關(guān)鍵字修飾:
volatile int x, y;
注意,C++里的volatile關(guān)鍵字只能避免編譯期的指令重排,對于多CPU的指令重排不起作用,所以實際上代碼真正運行的時候,可能又是亂序的。而Java的volatile關(guān)鍵字好像具有編譯器、CPU兩個層面的內(nèi)存屏障作用。
多CPU亂序訪問內(nèi)存:
在單 CPU 上,不考慮編譯器優(yōu)化導致亂序的前提下,多線程執(zhí)行不存在內(nèi)存亂序訪問的問題。因為單個CPU獲取指令是有序的(隊列FIFO),返回指令執(zhí)行的結(jié)果至寄存器也是有序的(也是通過隊列)
但是在多CPU處理器中,因為每個 CPU 都存有 cache,當數(shù)據(jù)x第一次被一個 CPU 獲取時,x顯然不在 該CPU 的 cache 中(這就是 cache miss)。cache miss發(fā)生那意味著 CPU 需要從內(nèi)存中獲取數(shù)據(jù),然后數(shù)據(jù)x將被加載到 CPU 的 cache 中,這樣后續(xù)就能直接從 cache 上快速訪問。
當某個 CPU 進行寫操作時,它必須確保其他的 CPU 已經(jīng)將數(shù)據(jù)x從它們的 cache 中移除(以便保證一致性),只有在移除操作完成后此 CPU 才能安全的修改數(shù)據(jù)。
顯然,存在多個 cache 時,我們必須通過 cache 的一致性協(xié)議來避免數(shù)據(jù)不一致的問題,而這個通訊的過程就可能導致亂序訪問的出現(xiàn)。
CPU級別的內(nèi)存屏障有三種:
- 通用 barrier,保證讀寫操作都有序的,mb() 和 smp_mb() //
mb即memory barrier - 寫操作 barrier,僅保證寫操作有序的,wmb() 和 smp_wmb()
- 讀操作 barrier,僅保證讀操作有序的,rmb() 和 smp_rmb()
上述這些函數(shù)也是有宏定義的比如mb(),用在上述的編譯期間亂序的例子中就是加個mfence:
#define mb() _asm__volatile("mfence":::"memory")
void f()
{
x = 1;
__asm__ __volatile__("mfence" ::: "memory");
r1 = y;
}
// GNU中的內(nèi)存屏障#define mfence() _asm__volatile_("mfence": : :"memory")
注意,所有的 CPU級別的 Memory Barrier(除了數(shù)據(jù)依賴 barrier 之外)都隱含了編譯器 barrier。
而且,實際上很多線程同步機制,都在底層有內(nèi)存屏障作為支撐,比如原子鎖和自旋鎖都是依賴CPU提供的CAS操作實現(xiàn)。CAS即Compare and Swap,它的基本思想是:
在多線程環(huán)境下,如果需要修改共享變量的值,先讀取該變量的值,然后修改該變量的值,最后將新值與舊值進行比較,如果相同,則修改成功,否則修改失敗,需要重新執(zhí)行該操作。
在實現(xiàn)CAS操作時,需要使用內(nèi)存屏障來保證操作的順序和一致性。例如,在Java中,使用Atomic類的compareAndSet方法實現(xiàn)CAS操作時,會自動插入內(nèi)存屏障來保證操作的正確性。
對于應(yīng)用層的編程而言,C++11引入了內(nèi)存模型,它確保了多線程程序中的同步和一致性。內(nèi)存屏障(CPU級別)就是內(nèi)存模型的一部分,用于確保特定的內(nèi)存操作順序,X86-64下僅支持一種指令重排:Store-Load ,即讀操作可能會重排到寫操作前面。
內(nèi)存屏障有兩種類型:store和load,使用示例如下:
// store屏障
std::atomic< int > x;
x.store(1, std::memory_order_release); // store屏障確保之前的寫操作在之后的寫操作之前完成
// load屏障
std::atomic< int > y;
int val = y.load(std::memory_order_acquire); // load屏障確保之前的讀操作在之后的讀操作之前完成
CPU級別的內(nèi)存屏障除了保證指令順序外,還要保證數(shù)據(jù)的可見性,不可見就會導致數(shù)據(jù)的不一致性。
所以上述代碼中也用到了acquire和release語義分別對讀和寫設(shè)置屏障:
acquire:保證acquire后的讀寫操作不會發(fā)生在acquire動作之前
release:保證release前的讀寫操作不會發(fā)生在release動作之后
除了上面的atomic的load和store,C++11還提供了單獨的內(nèi)存屏障函數(shù)std::atomic_thread_fence,其用法和上述的類似:
#include < atomic >
std::atomic_thread_fence(std::memory_order_acquire);
std::atomic_thread_fence(std::memory_order_release);
五、內(nèi)核中使用這些鎖的示例
進程調(diào)度:內(nèi)核鎖用于保護調(diào)度器的數(shù)據(jù)結(jié)構(gòu),以避免多個CPU同時修改它們而導致錯誤。
// 自旋鎖
spin_lock(&rq- >lock);
...
spin_unlock(&rq- >lock);
文件系統(tǒng):內(nèi)核鎖用于保護文件系統(tǒng)的元數(shù)據(jù),如inode、dentry等數(shù)據(jù)結(jié)構(gòu),以避免多個進程同時訪問它們而導致錯誤。
spin_lock(&inode- >i_lock);
...
spin_unlock(&inode- >i_lock);
網(wǎng)絡(luò)協(xié)議棧:內(nèi)核鎖用于保護網(wǎng)絡(luò)協(xié)議棧的數(shù)據(jù)結(jié)構(gòu),如套接字、路由表等,以避免多個進程同時訪問它們而導致錯誤。
read_lock(&rt_hash_lock);
...
read_unlock(&rt_hash_lock);
內(nèi)存管理:內(nèi)核鎖用于保護內(nèi)存管理的數(shù)據(jù)結(jié)構(gòu),如頁表、內(nèi)存映射等,以避免多個進程同時訪問它們而導致錯誤
spin_lock(&mm- >page_table_lock);
...
spin_unlock(&mm- >page_table_lock);
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3002瀏覽量
73887 -
線程
+關(guān)注
關(guān)注
0文章
504瀏覽量
19651 -
LINUX內(nèi)核
+關(guān)注
關(guān)注
1文章
316瀏覽量
21618 -
CPU處理器
+關(guān)注
關(guān)注
0文章
20瀏覽量
9828
發(fā)布評論請先 登錄
相關(guān)推薦
Linux內(nèi)核開發(fā)工具介紹
詳解linux內(nèi)核中的mutex同步機制
Linux讀寫鎖邏輯解析—Linux為何會引入讀寫鎖?
Linux內(nèi)核中RCU的用法
Linux內(nèi)核開發(fā)工具介紹
Linux內(nèi)核同步機制的自旋鎖原理是什么?
Linux內(nèi)核同步機制的自旋鎖原理
Linux內(nèi)核中有哪些鎖
Linux中的傷害/等待互斥鎖介紹
Linux內(nèi)核結(jié)構(gòu)介紹
介紹一下Linux內(nèi)核中的各種鎖
linux內(nèi)核中的driver_register介紹
使用 PREEMPT_RT 在 Ubuntu 中構(gòu)建實時 Linux 內(nèi)核

Linux內(nèi)核測試技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論