 異步IO框架iouring介紹
異步IO框架iouring介紹
前言
Linux內核5.1支持了新的異步IO框架iouring,由Block IO大神也即Fio作者Jens Axboe開發,意在提供一套公用的網絡和磁盤異步IO,不過io_uring目前在磁盤方面要比網絡方面更加成熟。
目錄
背景簡介
熟悉Linux系統編程的同學都清楚,Linux并沒有提供完善的異步IO(網絡IO、磁盤IO)機制。
在網絡編程中,我們通常使用epoll IO多路復用來處理網絡IO,然而epoll也并不是異步網絡IO,僅僅是內核提供了IO復用機制,epoll回調通知的是數據可以讀取或者寫入了,具體的讀寫操作仍然需要用戶去做,而不是內核代替完成。
在存儲IO棧中,做存儲的同學大都使用過libaio,然而那是一個巨難用啊Linux AIO這個奇葩。首先只能在DIO下使用,用不了pagecache;其次用戶的數據地址空間起始地址和大小必須頁大小對齊;然后在submit_io時仍然可能因為文件系統、pagecache、sync發生阻塞,除此之外,我們在使用libaio的時候會設置io_depth的大小,還可能因為內核的/sys/block/sda/queue/nr_requests(128)設置的過小而發生阻塞;而且libaio提供的sync命令關鍵還不起作用,想要sync數據還得依賴fsync/fdatasync,真的是心塞塞,libaio想說愛你不容易啊。
所以Linux迫切需要一個完善的異步機制。同時在Linux平臺上跑的大多數程序都是專用程序,并不需要內核的大多數功能,而且這幾年也流行kernel bypass,intel也發起的用戶態IO DPDK、SPDK。但是這些用戶態IO API不統一,使用成本過高,所以內核便推出了io_uring來統一網絡和磁盤的異步IO,提供一套統一完善的異步API,也支持異步、輪詢、無鎖、zero copy。真的是姍姍來遲啊,不過也算是在高性能IO方面也算是是扳回了一城。
io_uring
io_uring的設計目標是提供一個統一、易用、可擴展、功能豐富、高效的網絡和磁盤系統接口。其高性能依賴于以下幾個方面:
- 用戶態和內核態共享提交隊列(submission queue)和完成隊列(completion queue)。
- 用戶態支持Polling模式,不依賴硬件的中斷,通過調用IORING_ENTER_GETEVENTS不斷輪詢收割完成事件。
- 內核態支持Polling模式,IO 提交和收割可以 offload 給 Kernel,且提交和完成不需要經過系統調用(system call)。
- 在DirectIO下可以提前注冊用戶態內存地址,減小地址映射的開銷。
系統API
io_uring提供了3個系統調用API,雖然只有3個,但是直接使用起來還是蠻復雜的。
- io_uring_setup
entries:queue depth,表示隊列深度。
io_uring_params:初始化時候的參數。
在io_uring_setup返回的時候就已經初始化好了 SQ 和 CQ,此外,還有內核還提供了一個 Submission Queue Entries(SQEs)數組。
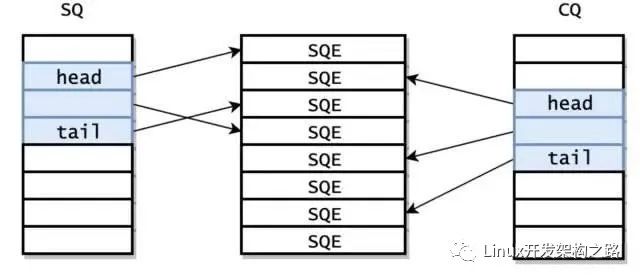
之所以額外采用了一個數組保存 SQEs,是為了方便通過 RingBuffer 提交內存上不連續的請求。SQ 和 CQ 中每個節點保存的都是 SQEs 數組的偏移量,而不是實際的請求,實際的請求只保存在 SQEs 數組中。這樣在提交請求時,就可以批量提交一組 SQEs 上不連續的請求。但由于 SQ,CQ,SQEs 是在內核中分配的,所以用戶態程序并不能直接訪問。io_setup 的返回值是一個 fd,應用程序使用這個 fd 進行 mmap,和 kernel 共享一塊內存。這塊內存共分為三個區域,分別是 SQ,CQ,SQEs。kernel 返回的 io_sqring_offset 和 io_cqring_offset 分別描述了 SQ 和 CQ 的指針在 mmap 中的 offset。而 SQEs 則直接對應了 mmap 中的 SQEs 區域。mmap 的時候需要傳入 MAP_POPULATE 參數,以防止內存被 page fault。
- io_uring_enter
io_uring_enter即可以提交io,也可以來收割完成的IO,一般IO完成時內核會自動將SQE 的索引放入到CQ中,用戶可以遍歷CQ來處理完成的IO。
IO 提交的做法是找到一個空閑的 SQE,根據請求設置 SQE,并將這個 SQE 的索引放到 SQ 中。SQ 是一個典型的 RingBuffer,有 head,tail 兩個成員,如果 head == tail,意味著隊列為空。SQE 設置完成后,需要修改 SQ 的 tail,以表示向 RingBuffer 中插入一個請求。
io_uring_enter 被調用后會陷入到內核,內核將 SQ 中的請求提交給 Block 層。to_submit 表示一次提交多少個 IO。
如果 flags 設置了 IORING_ENTER_GETEVENTS,并且 min_complete > 0,那么這個系統調用會同時處理 IO 收割。這個系統調用會一直 block,直到 min_complete 個 IO 已經完成。
這個流程貌似和 libaio 沒有什么區別,IO 提交的過程中依然會產生系統調用。
但 io_uring 的精髓在于,提供了 submission offload 模式,使得提交過程完全不需要進行系統調用。
如果在調用 io_uring_setup 時設置了 IORING_SETUP_SQPOLL 的 flag,內核會額外啟動一個內核線程,我們稱作 SQ 線程。這個內核線程可以運行在某個指定的 core 上(通過 sq_thread_cpu 配置)。這個內核線程會不停的 Poll SQ,除非在一段時間內沒有 Poll 到任何請求(通過 sq_thread_idle 配置),才會被掛起。
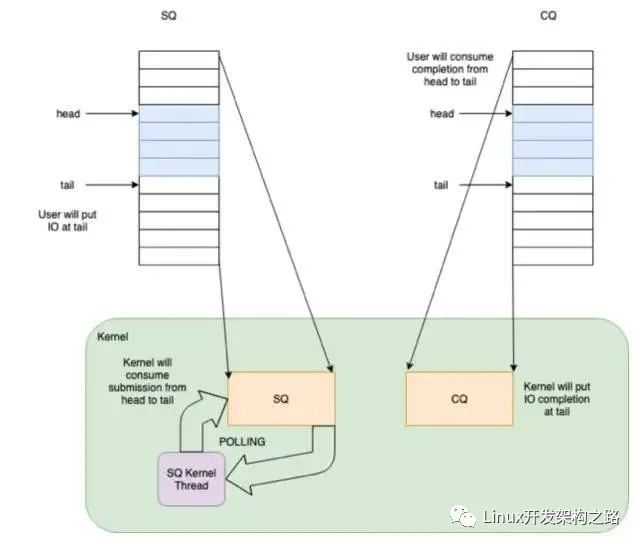
當程序在用戶態設置完 SQE,并通過修改 SQ 的 tail 完成一次插入時,如果此時 SQ 線程處于喚醒狀態,那么可以立刻捕獲到這次提交,這樣就避免了用戶程序調用 io_uring_enter 這個系統調用。如果 SQ 線程處于休眠狀態,則需要通過調用 io_uring_enter,并使用 IORING_SQ_NEED_WAKEUP 參數,來喚醒 SQ 線程。用戶態可以通過 sqring 的 flags 變量獲取 SQ 線程的狀態。
if (IO_URING_READ_ONCE(*ring->sq.kflags) & IORING_SQ_NEED_WAKEUP) {
*flags |= IORING_ENTER_SQ_WAKEUP;
return true;
}
- io_uring_register
主要包含IORING_REGISTER_FILES、IORING_REGISTER_BUFFERS,在高級特性章節會描述。
liburing
我們知道io_uring雖然僅僅提供了3個系統API,但是想要用好還是有一定難度的,所提fio大神本人封裝了一個Liburing,簡化了io_uring的使用,通過使用liburing,我們很容易寫出異步IO程序。
代碼位置:github.com/axboe/liburi,在使用的時候目前仍然需要拉取代碼,自己編譯,估計之后將會融入內核,在用戶程序中需要包含#include "liburing.h"。
列舉一些比較常用的封裝的API:github.com/axboe/liburi
extern int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags);
// 非系統調用,清理io_uring
extern void io_uring_queue_exit(struct io_uring *ring);
// 非系統調用,獲取一個可用的 submit_queue_entry,用來提交IO
extern struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
// 非系統調用,準備階段,和libaio封裝的io_prep_writev一樣
static inline void io_uring_prep_writev(struct io_uring_sqe *sqe, int fd,const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 非系統調用,準備階段,和libaio封裝的io_prep_readv一樣
static inline void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd, const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 非系統調用,把準備階段準備的data放進 submit_queue_entry
static inline void io_uring_sqe_set_data(struct io_uring_sqe *sqe, void *data)
// 非系統調用,設置submit_queue_entry的flag
static inline void io_uring_sqe_set_flags(struct io_uring_sqe *sqe, unsigned flags)
// 非系統調用,提交sq的entry,不會阻塞等到其完成,內核在其完成后會自動將sqe的偏移信息加入到cq,在提交時需要加鎖
extern int io_uring_submit(struct io_uring *ring);
// 非系統調用,提交sq的entry,阻塞等到其完成,在提交時需要加鎖。
extern int io_uring_submit_and_wait(struct io_uring *ring, unsigned wait_nr);
// 非系統調用 宏定義,會遍歷cq從head到tail,來處理完成的IO
#define io_uring_for_each_cqe(ring, head, cqe)
// 非系統調用 遍歷時,可以獲取cqe的data
static inline void *io_uring_cqe_get_data(const struct io_uring_cqe *cqe)
// 非系統調用 遍歷完成時,需要調整head往后移nr
static inline void io_uring_cq_advance(struct io_uring *ring, unsigned nr)
高級特性
io_uring里面提供了polling機制:IORING_SETUP_IOPOLL可以讓內核采用 Polling 的模式收割 Block 層的請求;IORING_SETUP_SQPOLL可以讓內核新起線程輪詢提交sq的entry。
IORING_REGISTER_FILES
這個的用途是避免每次 IO 對文件做 fget/fput 操作,當批量 IO 的時候,這組原子操作可以避免掉。
IORING_REGISTER_BUFFERS
如果應用提交到內核的虛擬內存地址是固定的,那么可以提前完成虛擬地址到物理 pages 的映射,避免在 IO 路徑上進行轉換,從而優化性能。用法是,在 setup io_uring 之后,調用 io_uring_register,傳遞 IORING_REGISTER_BUFFERS 作為 opcode,參數是一個指向 iovec 的數組,表示這些地址需要 map 到內核。在做 IO 的時候,使用帶 FIXED 版本的opcode(IORING_OP_READ_FIXED /IORING_OP_WRITE_FIXED)來操作 IO 即可。
內核在處理 IORING_REGISTER_BUFFERS 時,提前使用 get_user_pages 來獲得 userspace 虛擬地址對應的物理 pages。在做 IO 的時候,如果提交的虛擬地址曾經被注冊過,那么就免去了虛擬地址到 pages 的轉換。
IORING_SETUP_IOPOLL
這個功能讓內核采用 Polling 的模式收割 Block 層的請求。當沒有使用 SQ 線程時,io_uring_enter 函數會主動的 Poll,以檢查提交給 Block 層的請求是否已經完成,而不是掛起,并等待 Block 層完成后再被喚醒。使用 SQ 線程時也是同理。
編程示例
通過liburing使用起來還是比較方便的,不用操心內核的一些事情,簡直爽歪歪啊。具體可參考ceph:github.com/ceph/ceph/bl
- io_uring_queue_init 來初始化 io_uring。IORING_SETUP_IOPOLL / IORING_SETUP_SQPOLL。
- io_uring_submit 來提交 IO,在這個函數里面會判斷是否需要調用系統調用io_uring_enter。設置了IORING_SETUP_SQPOLL則不需要調用,沒有設置則需要用戶調用。
- io_uring_for_each_cqe 來收割完成的IO,這是一個for循環宏定義,后面直接跟 {} 就可以。
性能對比
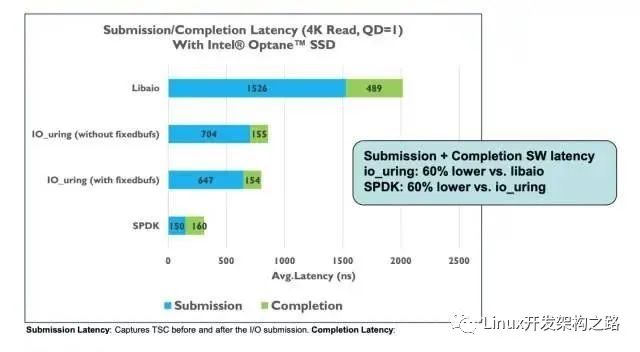
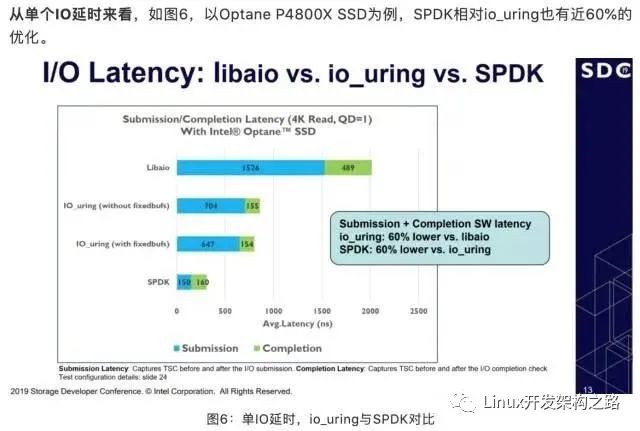
intel團隊測試結果
可以看出來intel自己測試的結果表明延遲方面spdk比io_uring要低60%。使用了自己帶的perf的測試工具測的。
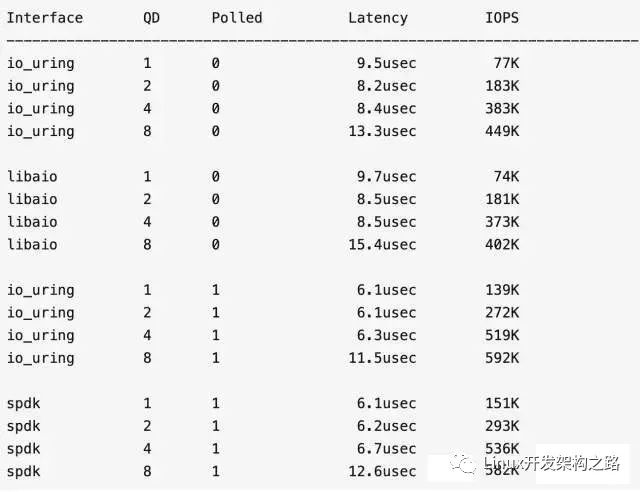
fio作者測試結果
4k randread,3D Xpoint 盤:
io_uring vs libaio,在非 polling 模式下,io_uring 性能提升不到 10%,好像并沒有什么了不起的地方。
然而 io_uring 提供了 polling 模式。在 polling 模式下,io_uring 和 SPDK 的性能非常接近,特別是高 QueueDepth 下,io_uring 有趕超的架勢,同時完爆 libaio。
模式對比
| 項目 | io_uring | spdk |
|---|---|---|
| 驅動程序 | 內核態驅動程序有鎖 | 用戶態驅動程序、無鎖、輪詢、線程綁定 |
| run_to_completion | 非rtc模型,可能會有上下文切換? | rtc模型,單線程擼到底 |
| 內存管理 | mmu、4k | 2MB大頁 |
| 提交任務有無鎖 | 無鎖 | 無鎖 |
| 系統調用 | 可有可無 | 無系統調用 |
| 用戶內核態切換 | 輕量級的 | 無內核切換 |
| poll模型 | 可選 | polling |
線上應用
目前發現已經有幾個項目在做嘗試性的應用:rocksdb、ceph、spdk、第三方適配(nginx、redis、echo_server)
rocksdb
rocksdb官方實現了PosixRandomAccessFile::MultiRead()使用io_uring。
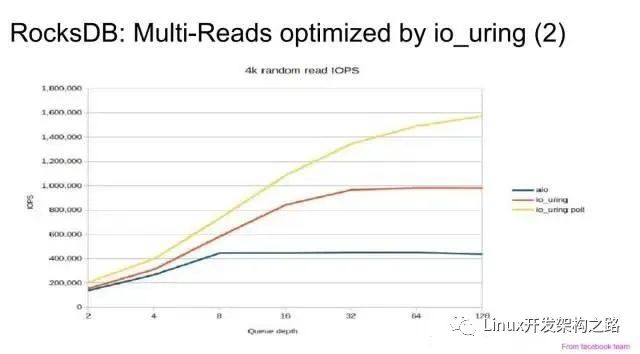
除此之外,tikv擴展了一些實現:openinx.github.io/ppt/i
- wal和sstbale的寫入使用io_uring,但是測完之后性能提升不明顯。
- compaction file write的時間降低了一半。
- 可用io_uring優化的點:參考 Conclusion & Future work 章節。
spdk
SPDK與io_uring新異步IO機制,在其抽象的通用塊層加入了io_uring的支持。
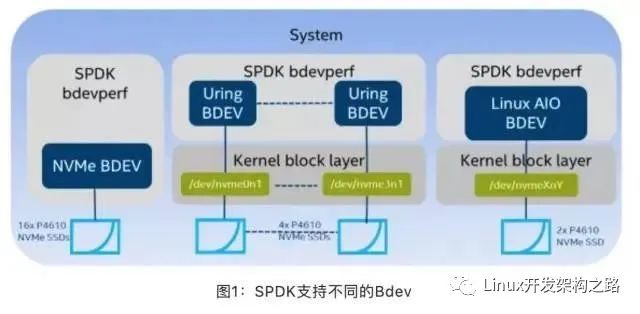
ceph
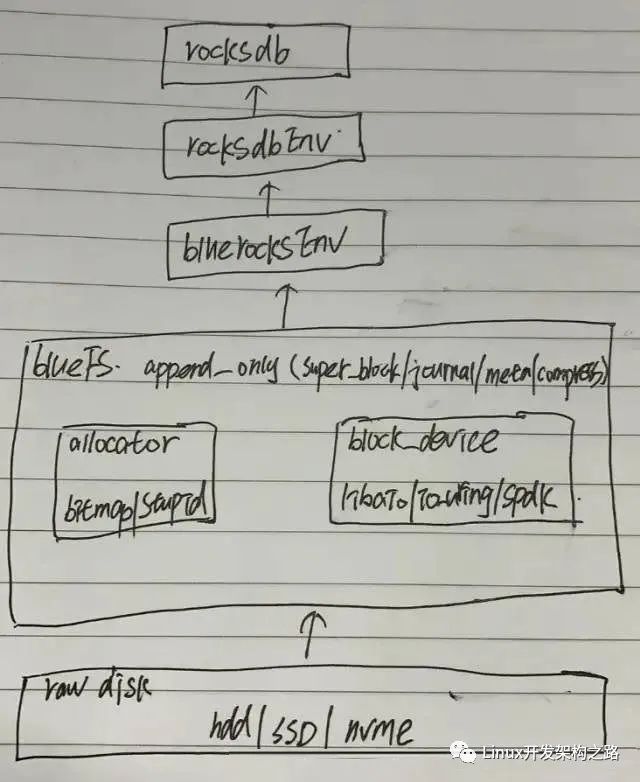
ceph的io_uring主要使用在block_device,抽象出了統一的塊設備,直接操作裸設備,對上層提供統一的讀寫方法。
bluefs僅僅需要提供append only的寫入即可,不需要提供隨機寫,大大簡化了bluefs的實現。
第三方適配(nginx、redis、echo_server)
第三方io_uring適配(nginx、redis、echo_server)性能測試結果:
redis:
以下是 redis 在 event poll 和 io_uring 下的 qps 對比:
- 高負載情況下,io_uring 相比 event poll,吞吐提升 8%~11%。
- 開啟 sqpoll 時,吞吐提升 24%~32%。這里讀者可能會有個疑問,開啟 sqpoll 額外使用了一個 CPU,性能為什么才提升 30% 左右?那是因為 redis 運行時同步讀寫就消耗了 70% 以上的 CPU,而 sq_thread 只能使用一個 CPU 的能力,把讀寫工作交給 sq_thread 之后,理論上 QPS 最多能提升 40% 左右(1/0.7 - 1 = 0.42),再加上 sq_thread 還需要處理中斷以及本身的開銷,因此只能有 30% 左右的提升。
nginx:
- 單 worker 場景,當連接數超過 500 時,QPS提升 20% 以上。
- connection 固定 1000,worker 數目在 8 以下時,QPS 有 20% 左右的提升。隨著 worker 數目增大,收益逐漸降低。
- 短連接場景,io uring 相對于 event poll 非但沒有提升,甚至在某些場景下有 5%~10% 的性能下降。究其原因,除了 io uring 框架本身帶來的開銷以外,還可能跟 io uring 編程模式下請求批量下發帶來的延遲有關。
-
IO
+關注
關注
0文章
418瀏覽量
38881 -
Linux系統
+關注
關注
4文章
587瀏覽量
27181 -
磁盤
+關注
關注
1文章
355瀏覽量
25094 -
程序
+關注
關注
115文章
3720瀏覽量
80358
發布評論請先 登錄
相關推薦
異步IO是什么
異步的功能介紹
HarmonyOS多媒體框架介紹
《Linux設備驅動開發詳解》第9章、Linux設備驅動中的異步通知與異步IO

簡單實用的框架,可用于快速增加或修改IO配置
一個高性能異步計算框架介紹
多路IO復用模型和異步IO模型介紹
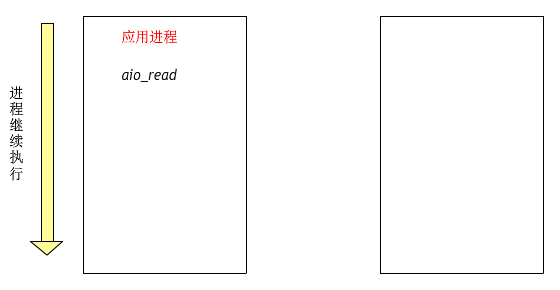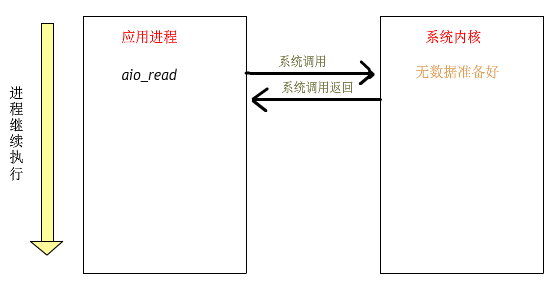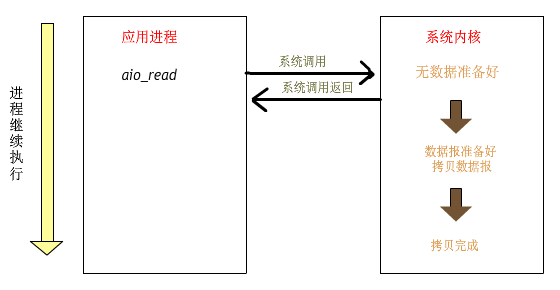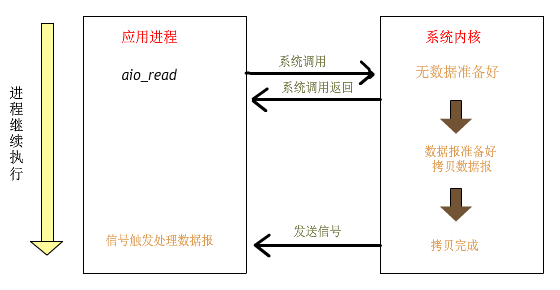
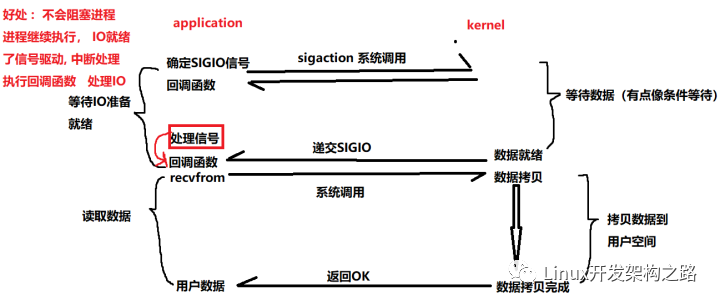
linux異步io框架iouring應用






 工商網監
工商網監
評論