 基于Http和Tcp協議自主實現的WebServer
基于Http和Tcp協議自主實現的WebServer
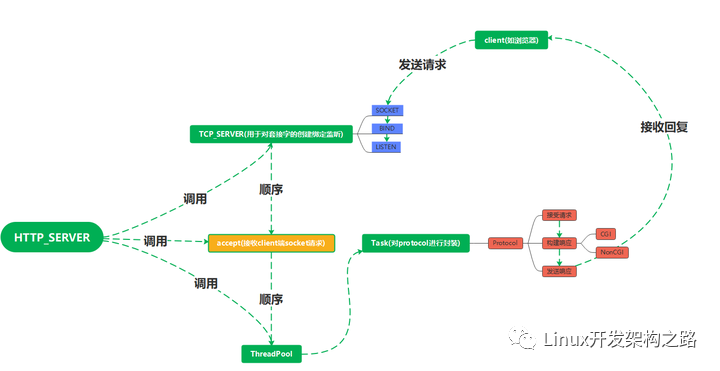
項目介紹
該項目是一個基于Http和Tcp協議自主實現的WebServer,用于實現服務器對客戶端發送過來的GET和POST請求的接收、解析、處理,并返回處理結果給到客戶端。該項目主要背景知識涉及C++、網絡分層協議棧、HTTP協議、網絡套接字編程、CGI技術、單例模式、多線程編程、線程池等。
CGI技術
CGI技術可能大家比較陌生,單拎出來提下。
概念
CGI(通用網關接口,Common Gateway Interface)是一種用于在Web服務器上執行程序并生成動態Web內容的技術。CGI程序可以是任何可執行程序,通常是腳本語言,例如Perl或Python。
CGI技術允許Web服務器通過將Web請求傳遞給CGI程序來執行任意可執行文件。CGI程序接收HTTP請求,并生成HTTP響應以返回給Web服務器,最終返回給Web瀏覽器。這使得Web服務器能夠動態地生成網頁內容,與靜態HTML文件不同。CGI程序可以處理表單數據、數據庫查詢和其他任務,從而實現動態Web內容。一些常見的用途包括創建動態網頁、在線購物車、用戶注冊、論壇、網上投票等。
原理
通過Web服務器將Web請求傳遞給CGI程序,CGI程序處理請求并生成響應,然后將響應傳遞回Web服務器,最終返回給客戶端瀏覽器。這個過程可以概括為:
- 客戶端發送HTTP請求到Web服務器。
- Web服務器檢查請求類型,如果是CGI請求,Web服務器將環境變量和請求參數傳遞給CGI程序,并等待CGI程序的響應。
- CGI程序接收請求參數,并執行相應的操作,例如讀取數據庫或處理表單數據等。
- CGI程序生成HTTP響應,將響應返回給Web服務器。
- Web服務器將響應返回給客戶端瀏覽器。
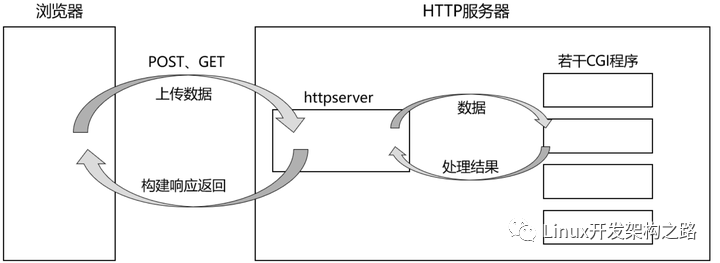
在這個過程中,Web服務器和CGI程序之間通過標準輸入和標準輸出(建立管道并重定向到標準輸入輸出)進行通信。Web服務器將請求參數通過環境變量傳遞給CGI程序,CGI程序將生成的響應通過標準輸出返回給Web服務器。此外,CGI程序還可以通過其他方式與Web服務器進行通信,例如通過命令行參數或文件進行交互。
設計框架
日志文件
用于記錄下服務器運行過程中產生的一些事件。日志格式如下:

日志級別說明:
- INFO: 表示正常的日志輸出,一切按預期運行。
- WARNING: 表示警告,該事件不影響服務器運行,但存在風險。
- ERROR: 表示發生了某種錯誤,但該事件不影響服務器繼續運行。
- FATAL: 表示發生了致命的錯誤,該事件將導致服務器停止運行。
文件名稱和行數可以通過C語言中的預定義符號__FILE__和__LINE__,分別可以獲取當前文件的名稱和當前的行數。
#define WARNING 2
#define ERROR 3
#define FATAL 4
// #將宏參數level轉為字符串格式
#define LOG(level, message) Log(#level, message, __FILE__, __LINE__)
TCPServer
思路是:創建一個TCP服務器,并通過初始化、綁定和監聽等步驟實現對外服務。
具體實現中,單例模式通過一個名為GetInstance的靜態方法實現,該方法首先使用pthread_mutex_t保證線程安全,然后使用靜態變量 _svr指向單例對象,如果 _svr為空,則創建一個新的TcpServer對象并初始化,最后返回 _svr指針。由于 _svr是static類型的,因此可以確保整個程序中只有一個TcpServer實例。
Socket方法用于創建一個監聽套接字,Bind方法用于將端口號與IP地址綁定,Listen方法用于將監聽套接字置于監聽狀態,等待客戶端連接。Sock方法用于返回監聽套接字的文件描述符。
class TcpServer{
private:
int _port; // 端口號
int _listen_sock; // 監聽套接字
static TcpServer* _svr; // 指向單例對象的static指針
private:
TcpServer(int port)
:_port(port)
,_listen_sock(-1)
{}
TcpServer(const TcpServer&) = delete;
TcpServer* operator=(const TcpServer&) = delete;
public:
static TcpServer* GetInstance(int port)// 單例
{
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
if (_svr == nullptr)
{
pthread_mutex_lock(&mtx);
if (_svr == nullptr)// 為什么要兩個if? 原因:當首個拿鎖者完成了對象創建,之后的線程都不會通過第一個if了,而這期間阻塞的線程開始喚醒,它們則需要靠第二個if語句來避免再次創建對象。
{
_svr = new TcpServer(port);
_svr -> InitServer();
}
pthread_mutex_unlock(&mtx);
}
return _svr;
}
void InitServer()
{
Socket(); // 創建
Bind(); // 綁定
Listen(); // 監聽
LOG(INFO, "TcpServer Init Success");
}
void Socket() // 創建監聽套接字
{
_listen_sock = socket(AF_INET, SOCK_STREAM, 0);
if (_listen_sock < 0)
{
LOG(FATAL, "socket error!");
exit(1);
}
int opt = 1;// 將 SO_REUSEADDR 設置為 1 將允許在端口上快速重啟套接字
setsockopt(_listen_sock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
LOG(INFO, "creat listen_sock success");
}
void Bind() // 綁定端口
{
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(_listen_sock, (struct sockaddr*)&local, sizeof(local)) < 0)
{
LOG(FATAL, "bind error");
exit(2);
}
LOG(INFO, "port bind listen_sock success");
}
void Listen() // 監聽
{
if (listen(_listen_sock, BACKLOG) < 0) // 聲明_listen_sock處于監聽狀態,并且最多允許有backlog個客戶端處于連接等待狀態,如果接收到更多的連接請求就忽略
{
LOG(FATAL, "listen error");
exit(3);
}
LOG(INFO, "listen listen_sock success");
}
int Sock() // 獲取監聽套接字fd
{
return _listen_sock;
}
~TcpServer()
{
if (_listen_sock >= 0)
{
close(_listen_sock);
}
}
};
// 單例對象指針初始化
TcpServer* TcpServer::_svr = nullptr;
任務類
class Task{
private:
int _sock; // 通信套接字
CallBack _handler; // 回調函數
public:
Task()
{}
~Task()
{}
Task(int sock) // accept建立連接成功產生的通信套接字sock
:_sock(sock)
{}
// 執行任務
void ProcessOn()
{
_handler(_sock); //_handler對象的運算符()已經重裝,直接調用重載的()
}
};
初始化與啟動HttpServer
這部分包含一個初始化服務器的方法InitServer()和一個啟動服務器的方法Loop()。其中InitServer()函數注冊了一個信號處理函數,忽略SIGPIPE信號(避免寫入崩潰)。而Loop()函數則通過調用TcpServer類的單例對象獲取監聽套接字,然后通過accept()函數等待客戶端連接,每當有客戶端連接進來,就創建一個線程來處理該客戶端的請求,并把任務放入線程池中。這里的Task是一個簡單的封裝,它包含一個處理客戶端請求的成員函數,該成員函數讀取客戶端請求,解析請求,然后調用CGI程序來執行請求,最后將響應發送給客戶端。
class HttpServer
{
private:
int _port;// 端口號
public:
HttpServer(int port)
:_port(port)
{}
~HttpServer()
{}
// 初始化服務器
void InitServer()
{
signal(SIGPIPE, SIG_IGN); // 直接粗暴處理cgi程序寫入管道時崩潰的情況,忽略SIGPIPE信號,避免因為一個被關閉的socket連接而使整個進程終止
}
// 啟動服務器
void Loop()
{
LOG(INFO, "loop begin");
TcpServer* tsvr = TcpServer::GetInstance(_port); // 獲取TCP服務器單例對象
int listen_sock = tsvr->Sock(); // 獲取單例對象的監聽套接字
while(true)
{
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);// 跟客戶端建立連接
if (sock < 0)
{
continue;
}
// 打印客戶端信息
std::string client_ip = inet_ntoa(peer.sin_addr);
int client_port = ntohs(peer.sin_port);
LOG(INFO, "get a new link:[" + client_ip + ":" + std::to_string(client_port) + "]");
// 搞個線程池,代替下面簡單的線程分離方案
// 構建任務并放入任務隊列
Task task(sock);
ThreadPool::GetInstance()->PushTask(task);
}
}
};
HTTP請求結構
將HTTP請求封裝成一個類,這個類當中包括HTTP請求的內容、HTTP請求的解析結果以及是否需要使用CGI模式的標志位。后續處理請求時就可以定義一個HTTP請求類,讀取到的HTTP請求的數據就存儲在這個類當中,解析HTTP請求后得到的數據也存儲在這個類當中。
public:
// Http請求內容
std::string _request_line; // 請求行
std::vector _request_header; // 請求報頭
std::string _blank; // 空行
std::string _request_body; // 請求正文
// 存放解析結果
std::string _method; // 請求方法
std::string _uri; // URI
std::string _version; // 版本號
std::unordered_map _header_kv; // 請求報頭的內容是以鍵值對的形式存在的,用hash保存
int _content_length; // 正文長度
std::string _path; // 請求資源的路徑
std::string _query_string; // URI攜帶的參數
// 是否使用CGI
bool _cgi;
public:
HttpRequest()
:_content_length(0) // 默認請求正文長度為0
,_cgi(false) // 默認不適用CGI模式
{}
~HttpRequest()
{}
};,>
HTTP響應結構
類似的,HTTP響應也封裝成一個類,這個類當中包括HTTP響應的內容以及構建HTTP響應所需要的數據。構建響應需要使用的數據就存儲在這個類當中,構建后得到的響應內容也存儲在這個類當中。
public:
// Http響應內容
std::string _status_line; // 狀態行
std::vector _response_header; // 響應報頭
std::string _blank; // 空行
std::string _response_body; // 響應正文(如果CGI為true(即Get帶_query_string或者Post),響應正文才存在)
// 所需數據
int _status_code; // 狀態碼
int _fd; // 響應文件的fd
int _size; // 響應文件的大小
std::string _suffix; // 響應文件的后綴
public:
HttpResponse()
:_blank(LINE_END)
,_status_code(OK)
,_fd(-1)
,_size(0)
{}
~HttpResponse()
{}
};
線程回調
該回調函數實際上是一個函數對象,其重載了圓括號運算符“()”。當該函數對象被調用時,會傳入一個int類型的套接字描述符作為參數,代表與客戶端建立的連接套接字。該函數對象內部通過創建一個EndPoint對象來處理該客戶端發來的HTTP請求,包括讀取請求、處理請求、構建響應和發送響應。處理完畢后,該連接套接字將被關閉,EndPoint對象也會被釋放。
public:
CallBack()
{}
~CallBack()
{}
// 重載運算符 ()
void operator()(int sock)
{
HandlerRequest(sock);
}
void HandlerRequest(int sock)
{
LOG(INFO, "HandlerRequest begin");
EndPoint* ep = new EndPoint(sock);
ep->RecvHttpRequest(); //讀取請求
if (!ep->IsStop())
{
LOG(INFO, "RecvHttpRequest Success");
ep->HandlerHttpRequest(); //處理請求
ep->BulidHttpResponse(); //構建響應
ep->SendHttpResponse(); //發送響應
if (ep->IsStop())
{
LOG(WARNING, "SendHttpResponse Error, Stop Send HttpResponse");
}
}
else
{
LOG(WARNING, "RecvHttpRequest Error, Stop handler Response");
}
close(sock); //響應完畢,關閉與該客戶端建立的套接字
delete ep;
LOG(INFO, "handler request end");
}
};
EndPoint類
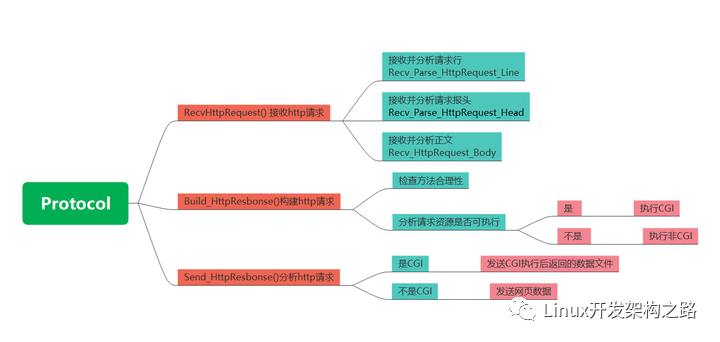
EndPoint主體框架
EndPoint類中包含三個成員變量:
- sock:表示與客戶端進行通信的套接字。
- http_request:表示客戶端發來的HTTP請求。
- http_response:表示將會發送給客戶端的HTTP響應。
- _stop:是否異常停止本次處理
EndPoint類中主要包含四個成員函數:
- RecvHttpRequest:讀取客戶端發來的HTTP請求。
- HandlerHttpRequest:處理客戶端發來的HTTP請求。
- BuildHttpResponse:構建將要發送給客戶端的HTTP響應。
- SendHttpResponse:發送HTTP響應給客戶端。
class EndPoint{
private:
int _sock; //通信的套接字
HttpRequest _http_request; //HTTP請求
HttpResponse _http_response; //HTTP響應
bool _stop; //是否停止本次處理
public:
EndPoint(int sock)
:_sock(sock)
{}
//讀取請求
void RecvHttpRequest();
//處理請求
void HandlerHttpRequest();
//構建響應
void BuildHttpResponse();
//發送響應
void SendHttpResponse();
~EndPoint()
{}
};
讀取HTTP請求
讀取HTTP請求的同時可以對HTTP請求進行解析,這里我們分為五個步驟,分別是讀取請求行、讀取請求報頭和空行、解析請求行、解析請求報頭、讀取請求正文。
void RecvHttpRequest()
{
if (!RecvHttpRequestLine() && !RecvHttpRequestHeader())// 請求行與請求報頭讀取均正常讀取
{
ParseHttpRequestLine();
ParseHttpRequestHeader();
RecvHttpRequestBody();
}
}
處理HTTP請求
首先判斷請求方法是否為GET或POST,如果不是則返回錯誤信息;然后判斷請求是GET還是POST,設置對應的cgi、路徑和查詢字符串;接著拼接web根目錄和請求資源路徑,并判斷路徑是否以/結尾,如果是則拼接index.html;獲取請求資源文件的屬性信息,并根據屬性信息判斷是否需要使用CGI模式處理;獲取請求資源文件的后綴,進行CGI或非CGI處理。
void HandlerHttpRequest()
{
auto& code = _http_response._status_code;
//非法請求
if (_http_request._method != "GET" && _http_request._method != "POST")
{
LOG(WARNING, "method is not right");
code = BAD_REQUEST;
return;
}
// 判斷請求是get還是post,設置cgi,_path,_query_string
if (_http_request._method == "GET")
{
size_t pos = _http_request._uri.find('?');
if (pos != std::string::npos)// uri中攜帶參數
{
// 切割uri,得到客戶端請求資源的路徑和uri中攜帶的參數
Util::CutString(_http_request._uri, _http_request._path, _http_request._query_string, "?");
LOG(INFO, "GET方法分割路徑和參數");
_http_request._cgi = true;// 上傳了參數,需要使用CGI模式
}
else // uri中沒有攜帶參數
{
_http_request._path = _http_request._uri;// uri即是客戶端請求資源的路徑
}
}
else if (_http_request._method == "POST")
{
_http_request._path = _http_request._uri;// uri即是客戶端請求資源的路徑
_http_request._cgi = true; // 上傳了參數,需要使用CGI模式
}
else
{
// 只是為了代碼完整性
}
// 為請求資源路徑拼接web根目錄
std::string path = _http_request._path;
_http_request._path = WEB_ROOT;
_http_request._path += path;
// 請求資源路徑以/結尾,說明請求的是一個目錄
if (_http_request._path[_http_request._path.size() - 1] == '/')
{
_http_request._path += HOME_PAGE; // 拼接上該目錄下的index.html
}
LOG(INFO, _http_request._path);
//獲取請求資源文件的屬性信息
struct stat st;
if (stat(_http_request._path.c_str(), &st) == 0) // 屬性信息獲取成功,說明該資源存在
{
if (S_ISDIR(st.st_mode)) // 該資源是一個目錄
{
_http_request._path += "/"; // 以/結尾的目錄前面已經處理過了,這里處理不是以/結尾的目錄情況,需要拼接/
_http_request._path += HOME_PAGE; // 拼接上該目錄下的index.html
stat(_http_request._path.c_str(), &st); // 重新獲取資源文件的屬性信息
}
else if (st.st_mode&S_IXUSR||st.st_mode&S_IXGRP||st.st_mode&S_IXOTH) // 該資源是一個可執行程序
{
_http_request._cgi = true; //需要使用CGI模式
}
_http_response._size = st.st_size; //設置請求資源文件的大小
}
else // 屬性信息獲取失敗,可以認為該資源不存在
{
LOG(WARNING, _http_request._path + "NOT_FOUND");
code = NOT_FOUND;
return;
}
// 獲取請求資源文件的后綴
size_t pos = _http_request._path.rfind('.');
if (pos == std::string::npos)
{
_http_response._suffix = ".html";
}
else
{
_http_response._suffix = _http_request._path.substr(pos);// 把'.'也帶上
}
// 進行CGI或非CGI處理
// CGI為true就三種情況,GET方法的uri帶參(_query_string),或者POST方法,又或者請求的資源是一個可執行程序
if (_http_request._cgi == true)
{
code = ProcessCgi(); // 以CGI的方式進行處理
}
else
{
code = ProcessNonCgi(); // 簡單的網頁返回,返回靜態網頁
}
}
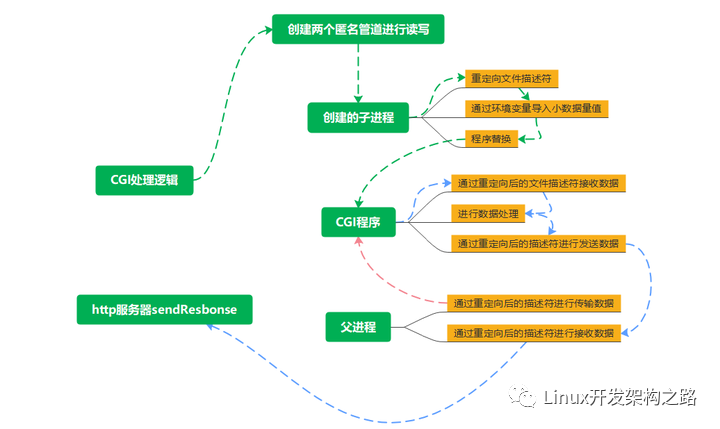
CGI處理
CGI處理時需要創建子進程進行進程程序替換,但是在創建子進程之前需要先創建兩個匿名管道。這里站在父進程角度對這兩個管道進行命名,父進程用于讀取數據的管道叫做input,父進程用于寫入數據的管道叫做output。
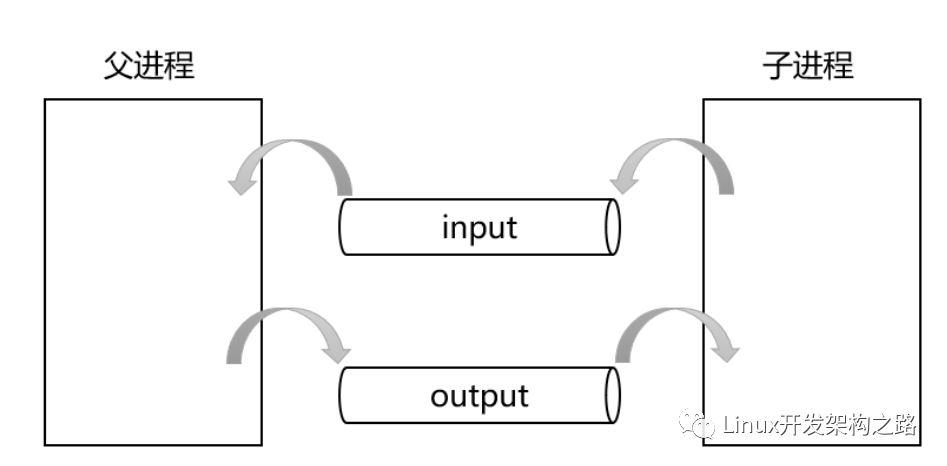
創建匿名管道并創建子進程后,需要父子進程各自關閉兩個管道對應的讀寫端:
- 對于父進程來說,input管道是用來讀數據的,因此父進程需要保留input[0]關閉input[1],而output管道是用來寫數據的,因此父進程需要保留output[1]關閉output[0]。
- 對于子進程來說,input管道是用來寫數據的,因此子進程需要保留input[1]關閉input[0],而output管道是用來讀數據的,因此子進程需要保留output[0]關閉output[1]。
此時父子進程之間的通信信道已經建立好了,但為了讓替換后的CGI程序從標準輸入讀取數據等價于從管道讀取數據,向標準輸出寫入數據等價于向管道寫入數據,因此在子進程進行進程程序替換之前,還需要對子進程進行重定向。
假設子進程保留的input[1]和output[0]對應的文件描述符分別是3和4,那么子進程對應的文件描述符表的指向大致如下:
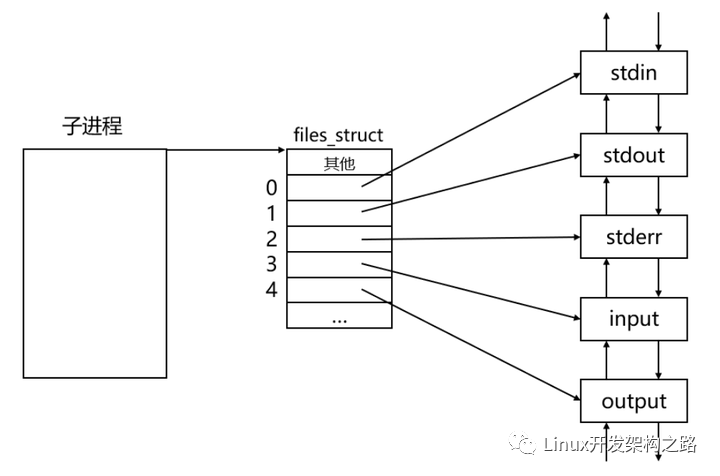
現在我們要做的就是將子進程的標準輸入重定向到output管道,將子進程的標準輸出重定向到input管道,也就是讓子進程的0號文件描述符指向output管道,讓子進程的1號文件描述符指向input管道。
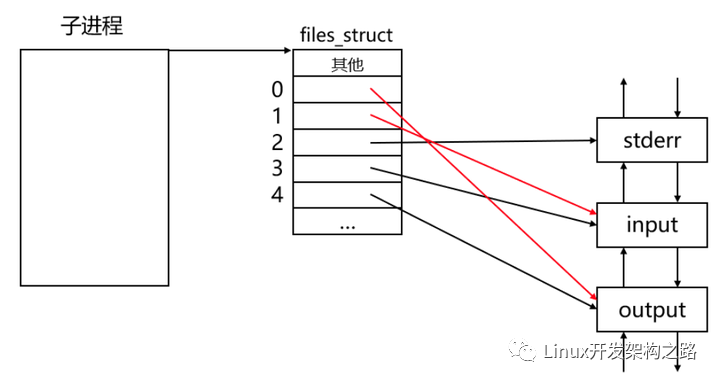
此外,在子進程進行進程程序替換之前,還需要進行各種參數的傳遞:
- 首先需要將請求方法通過putenv函數導入環境變量,以供CGI程序判斷應該以哪種方式讀取父進程傳遞過來的參數。
- 如果請求方法為GET方法,則需要將URL中攜帶的參數通過導入環境變量的方式傳遞給CGI程序。
- 如果請求方法為POST方法,則需要將請求正文的長度通過導入環境變量的方式傳遞給CGI程序,以供CGI程序判斷應該從管道讀取多少個參數。
此時子進程就可以進行進程程序替換了,而父進程需要做如下工作:
- 如果請求方法為POST方法,則父進程需要將請求正文中的參數寫入管道中,以供被替換后的CGI程序進行讀取。
- 然后父進程要做的就是不斷調用read函數,從管道中讀取CGI程序寫入的處理結果,并將其保存到HTTP響應類的response_body當中。
- 管道中的數據讀取完畢后,父進程需要調用waitpid函數等待CGI程序退出,并關閉兩個管道對應的文件描述符,防止文件描述符泄露。
int ProcessCgi()
{
int code = OK; // 要返回的狀態碼,默認設置為200
auto& bin = _http_request._path; // 需要執行的CGI程序
auto& method = _http_request._method; // 請求方法
//需要傳遞給CGI程序的參數
auto& query_string = _http_request._query_string; // GET
auto& request_body = _http_request._request_body; // POST
int content_length = _http_request._content_length; // 請求正文的長度
auto& response_body = _http_response._response_body; // CGI程序的處理結果放到響應正文當中
// 1、創建兩個匿名管道(管道命名站在父進程角度)
// 在調用 pipe 函數創建管道成功后,pipefd[0] 用于讀取數據,pipefd[1] 用于寫入數據。
// 1.1 創建從子進程到父進程的通信信道
int input[2];
if(pipe(input) < 0){ // 管道創建失敗,pipe()返回-1
LOG(ERROR, "pipe input error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
// 1.2 創建從父進程到子進程的通信信道
int output[2];
if(pipe(output) < 0){ // 管道創建失敗,pipe()返回-1
LOG(ERROR, "pipe output error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
//2、創建子進程
pid_t pid = fork();
if(pid == 0){ //child
// 子進程關閉兩個管道對應的讀寫端
close(input[0]);
close(output[1]);
//將請求方法通過環境變量傳參
std::string method_env = "METHOD=";
method_env += method;
putenv((char*)method_env.c_str());
if(method == "GET"){ //將query_string通過環境變量傳參
std::string query_env = "QUERY_STRING=";
query_env += query_string;
putenv((char*)query_env.c_str());
LOG(INFO, "GET Method, Add Query_String env");
}
else if(method == "POST"){ //將正文長度通過環境變量傳參
std::string content_length_env = "CONTENT_LENGTH=";
content_length_env += std::to_string(content_length);
putenv((char*)content_length_env.c_str());
LOG(INFO, "POST Method, Add Content_Length env");
}
else{
//Do Nothing
}
//3、將子進程的標準輸入輸出進行重定向,子進程會繼承了父進程的所有文件描述符
dup2(output[0], 0); //標準輸入重定向到管道的輸入
dup2(input[1], 1); //標準輸出重定向到管道的輸出
//4、將子進程替換為對應的CGI程序,代碼、數據全部替換掉
execl(bin.c_str(), bin.c_str(), nullptr);
exit(1); // 替換失敗則exit(1)
}
else if(pid < 0){ //創建子進程失敗,則返回對應的錯誤碼
LOG(ERROR, "fork error!");
code = INTERNAL_SERVER_ERROR;
return code;
}
else{ //father
//父進程關閉兩個管道對應的讀寫端
close(input[1]);
close(output[0]);
if(method == "POST") // 將正文中的參數通過管道傳遞給CGI程序
{
const char* start = request_body.c_str();
int total = 0;
int size = 0;
while(total < content_length && (size = write(output[1], start + total, request_body.size() - total)) > 0)
{
total += size;
}
}
// 讀取CGI程序的處理結果
char ch = 0;
while(read(input[0], &ch, 1) > 0)// 不會一直讀,當另一端關閉后會繼續往下執行
{
response_body.push_back(ch);
}
// 等待子進程(CGI程序)退出
// status 保存退出狀態
int status = 0;
pid_t ret = waitpid(pid, &status, 0);
if(ret == pid){
if(WIFEXITED(status)){ // 子進程正常退出
if(WEXITSTATUS(status) == 0){ // 子進程退出碼結果正確
LOG(INFO, "CGI program exits normally with correct results");
code = OK;
}
else{
LOG(INFO, "CGI program exits normally with incorrect results");
code = BAD_REQUEST;
}
}
else{
LOG(INFO, "CGI program exits abnormally");
code = INTERNAL_SERVER_ERROR;
}
}
//關閉兩個管道對應的文件描述符
close(input[0]);
close(output[1]);
}
return code; //返回狀態碼
}
非CGI處理
非CGI處理時只需要將客戶端請求的資源構建成HTTP響應發送給客戶端即可,理論上這里要做的就是打開目標文件,將文件中的內容讀取到HTTP響應類的response_body中,以供后續發送HTTP響應時進行發送即可,但這種做法還可以優化。
因為HTTP響應類的response_body屬于用戶層的緩沖區,而目標文件是存儲在服務器的磁盤上的,按照這種方式需要先將文件內容讀取到內核層緩沖區,再由操作系統將其拷貝到用戶層緩沖區,發送響應正文的時候又需要先將其拷貝到內核層緩沖區,再由操作系統將其發送給對應的網卡進行發送。我們完全可以調用sendfile函數直接將磁盤當中的目標文件內容讀取到內核,再由內核將其發送給對應的網卡進行發送。
sendfile函數是一個系統調用函數,用于將一個文件描述符指向的文件內容直接發送給另一個文件描述符指向的套接字,從而實現了零拷貝(Zero Copy)技術。這種技術避免了數據在用戶態和內核態之間的多次拷貝,從而提高了數據傳輸效率。
sendfile函數的使用場景通常是在Web服務器中,用于將靜態文件直接發送給客戶端瀏覽器,從而避免了將文件內容復制到用戶空間的過程。在Linux系統中,sendfile函數的原型為:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
其中,out_fd表示目標文件描述符,in_fd表示源文件描述符,offset表示源文件偏移量,count表示要發送的字節數。函數返回值表示成功發送的字節數,如果返回-1則表示出現了錯誤。
int ProcessNonCgi()
{
// 打開客戶端請求的資源文件,以供后續發送
_http_response._fd = open(_http_request._path.c_str(), O_RDONLY);
if(_http_response._fd >= 0){ // 打開文件成功
return OK;
}
return INTERNAL_SERVER_ERROR; // 打開文件失敗
}
構建HTTP響應
構建 HTTP 響應報文,首先根據響應的狀態碼構建狀態行(包含 HTTP 版本、狀態碼和狀態碼描述),然后根據狀態碼分別構建不同的響應報頭和響應正文。如果狀態碼為 200 OK,則調用 BuildOkResponse() 函數構建成功的響應報頭和響應正文;如果狀態碼為 404 NOT FOUND、400 BAD REQUEST 或 500 INTERNAL SERVER ERROR,則根據不同的狀態碼構建相應的錯誤響應報頭和響應正文,并調用 HandlerError() 函數處理錯誤。
void BulidHttpResponse()
{
int code = _http_response._status_code;
//構建狀態行
auto& status_line = _http_response._status_line;
status_line += HTTP_VERSION;
status_line += " ";
status_line += std::to_string(code);
status_line += " ";
status_line += CodeToDesc(code); //根據狀態碼獲取狀態碼描述
status_line += LINE_END;
//構建響應報頭
std::string path = WEB_ROOT;
path += "/";
switch(code){
case OK:
BuildOkResponse();
break;
case NOT_FOUND:
path += PAGE_404;
HandlerError(path);
break;
case BAD_REQUEST:
path += PAGE_400;
HandlerError(path);
break;
case INTERNAL_SERVER_ERROR:
path += PAGE_500;
HandlerError(path);
break;
default:
break;
}
}
發送HTTP響應
發送HTTP響應的步驟如下:
- 調用send函數,依次發送狀態行、響應報頭和空行。
- 發送響應正文時需要判斷本次請求的處理方式,如果本次請求是以CGI方式成功處理的,那么待發送的響應正文是保存在HTTP響應類的response_body中的,此時調用send函數進行發送即可。
- 如果本次請求是以非CGI方式處理或在處理過程中出錯的,那么待發送的資源文件或錯誤頁面文件對應的文件描述符是保存在HTTP響應類的fd中的,此時調用sendfile進行發送即可,發送后關閉對應的文件描述符。
bool SendHttpResponse()
{
//發送狀態行
if(send(_sock, _http_response._status_line.c_str(), _http_response._status_line.size(), 0) <= 0)
{
_stop = true; //發送失敗,設置_stop
}
//發送響應報頭
if(!_stop){
for(auto& iter : _http_response._response_header)
{
if(send(_sock, iter.c_str(), iter.size(), 0) <= 0)
{
_stop = true; //發送失敗,設置_stop
break;
}
}
}
//發送空行
if(!_stop)
{
if(send(_sock, _http_response._blank.c_str(), _http_response._blank.size(), 0) <= 0)
{
_stop = true; //發送失敗,設置_stop
}
}
//發送響應正文
if(_http_request._cgi)
{
if(!_stop)
{
auto& response_body = _http_response._response_body;
const char* start = response_body.c_str();
size_t size = 0;
size_t total = 0;
while(total < response_body.size()&&(size = send(_sock, start + total, response_body.size() - total, 0)) > 0){
total += size;
}
}
}
else
{
if(!_stop)
{
// sendfile:這是一個系統調用,用于高效地從文件傳輸數據到套接字中。它避免了在內核空間和用戶空間之間復制數據的需求,從而實現更快的數據傳輸。
if(sendfile(_sock, _http_response._fd, nullptr, _http_response._size) <= 0)
{
_stop = true; //發送失敗,設置_stop
}
}
//關閉請求的資源文件
close(_http_response._fd);
}
return _stop;
}
接入線程池
當前多線程版服務器存在的問題:
- 每當獲取到新連接時,服務器主線程都會重新為該客戶端創建為其提供服務的新線程,而當服務結束后又會將該新線程銷毀,這樣做不僅麻煩,而且效率低下。
- 如果同時有大量的客戶端連接請求,此時服務器就要為每一個客戶端創建對應的服務線程,而計算機中的線程越多,CPU壓力就越大,因為CPU要不斷在這些線程之間來回切換。此外,一旦線程過多,每一個線程再次被調度的周期就變長了,而線程是為客戶端提供服務的,線程被調度的周期變長,客戶端也就遲遲得不到應答。
考慮接入線程池簡單優化下(其實也可以直接上epoll)
- 在服務器端預先創建一批線程和一個任務隊列,每當獲取到一個新連接時就將其封裝成一個任務對象放到任務隊列當中。
- 線程池中的若干線程就不斷從任務隊列中獲取任務進行處理,如果任務隊列當中沒有任務則線程進入休眠狀態,當有新任務時再喚醒線程進行任務處理。
//線程池
class ThreadPool{
private:
std::queue _task_queue; //任務隊列
int _num; //線程池中線程的個數
pthread_mutex_t _mutex; //互斥鎖
pthread_cond_t _cond; //條件變量
static ThreadPool* _inst; //指向單例對象的static指針
private:
//構造函數私有
ThreadPool(int num = NUM)
:_num(num)
{
//初始化互斥鎖和條件變量
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
}
// 刪除拷貝構造函數(防拷貝)
ThreadPool(const ThreadPool&)=delete;
//判斷任務隊列是否為空
bool IsEmpty()
{
return _task_queue.empty();
}
//任務隊列加鎖
void LockQueue()
{
pthread_mutex_lock(&_mutex);
}
//任務隊列解鎖
void UnLockQueue()
{
pthread_mutex_unlock(&_mutex);
}
//讓線程在條件變量下進行等待
void ThreadWait()
{
pthread_cond_wait(&_cond, &_mutex);
}
//喚醒在條件變量下等待的一個線程
void ThreadWakeUp()
{
pthread_cond_signal(&_cond);
}
public:
//獲取單例對象
static ThreadPool* GetInstance()
{
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; //定義靜態的互斥鎖
//雙檢查加鎖
if(_inst == nullptr){
pthread_mutex_lock(&mtx); //加鎖
if(_inst == nullptr){
//創建單例線程池對象并初始化
_inst = new ThreadPool();
_inst->InitThreadPool();
}
pthread_mutex_unlock(&mtx); //解鎖
}
return _inst; //返回單例對象
}
//線程的執行例程
static void* ThreadRoutine(void* arg)
{
pthread_detach(pthread_self()); //線程分離
ThreadPool* tp = (ThreadPool*)arg;
while(true){
tp->LockQueue(); //加鎖
while(tp->IsEmpty()){
//任務隊列為空,線程進行wait
tp->ThreadWait();
}
Task task;
tp->PopTask(task); //獲取任務
tp->UnLockQueue(); //解鎖
task.ProcessOn(); //處理任務
}
}
//初始化線程池
bool InitThreadPool()
{
//創建線程池中的若干線程
pthread_t tid;
for(int i = 0;i < _num;i++){
if(pthread_create(&tid, nullptr, ThreadRoutine, this) != 0){
LOG(FATAL, "create thread pool error!");
return false;
}
}
LOG(INFO, "create thread pool success");
return true;
}
//將任務放入任務隊列
void PushTask(const Task& task)
{
LockQueue(); //加鎖
_task_queue.push(task); //將任務推入任務隊列
UnLockQueue(); //解鎖
ThreadWakeUp(); //喚醒一個線程進行任務處理
}
//從任務隊列中拿任務
void PopTask(Task& task)
{
//獲取任務
task = _task_queue.front();
_task_queue.pop();
}
~ThreadPool()
{
//釋放互斥鎖和條件變量
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
}
};
//單例對象指針初始化為nullptr
ThreadPool* ThreadPool::_inst = nullptr;
簡單測試
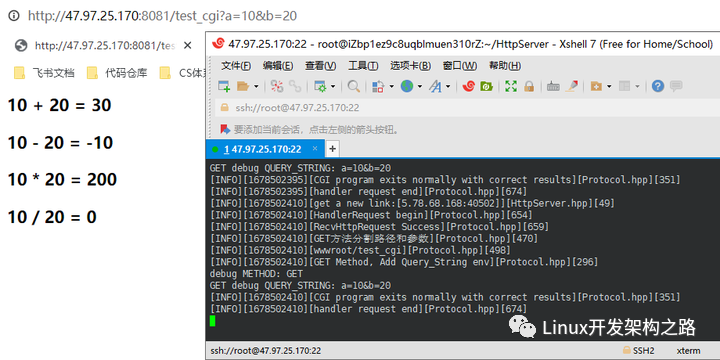
默認頁面測試:
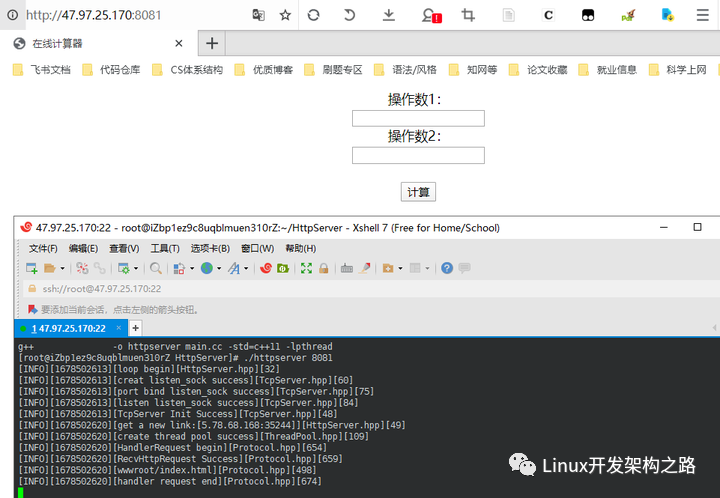
帶query_string,CGI傳參測試:
項目擴展
當前項目的重點在于HTTP服務器后端的處理邏輯,主要完成的是GET和POST請求方法,以及CGI機制的搭建。還可以進行不少擴展,比如:
- 當前項目編寫的是HTTP1.0版本的服務器,每次連接都只會對一個請求進行處理,當服務器對客戶端的請求處理完畢并收到客戶端的應答后,就會直接斷開連接。可以將其擴展為HTTP1.1版本,讓服務器支持長連接,即通過一條連接可以對多個請求進行處理,避免重復建立連接(涉及連接管理)。
- 當前項目雖然在后端接入了線程池,但是效果有限,可以將線程池換成epoll版本,讓服務器的IO變得更高效。
- 可以給當前的HTTP服務器新增代理功能,也就是可以替代客戶端去訪問某種服務,然后將訪問結果再返回給客戶端(比如課題中的數據備份、數據計算等等)。
-
服務器
+關注
關注
12文章
9021瀏覽量
85184 -
HTTP
+關注
關注
0文章
501瀏覽量
31065 -
TCP協議
+關注
關注
1文章
91瀏覽量
12063 -
WebServer
+關注
關注
0文章
11瀏覽量
2992
發布評論請先 登錄
相關推薦
HTTP、TCP、QUIC協議詳解
簡述基于HTTP協議實現WebClient軟件包的工作原理
TCP-IP詳解卷3:TCP事務協議,HTTP,NNTP和UNI
tcp和http的區別在哪里

為了速度犧牲安全,下一代HTTP底層協議或將放棄TCP協議
通信協議中的HTTP、TCP、UDP你了解多少(上)
你了解清楚了嘛-TCP、HTTP、MQTT協議






 工商網監
工商網監
評論