 自動駕駛公開數據集的現狀與挑戰
自動駕駛公開數據集的現狀與挑戰
隨著數據采集設備的優化升級,自動駕駛數據集也在不斷升級迭代。國內外各大自動駕駛公司、研究所都先后推出自動駕駛數據集,為未來自動駕駛領域的技術發展提供重要研究材料。 《自動駕駛開源數據體系:現狀與未來》一文系統性地梳理自動駕駛開源數據集,對于助推產業生態良性循環有著重要意義。該文章是由上海人工智能實驗室聯合上海交大、復旦大學、百度、比亞迪、蔚來等多個單位,發布的自動駕駛開源數據集綜述。該綜述首次系統性梳理了國內外七十余種開源自動駕駛數據集,對如何構建高質量數據集、數據在算法閉環體系中發揮的核心作用、如何利用生成式大模型規模化生產數據等進行了總結。在此基礎上,對未來第三代自動駕駛數據集所應具有的特征、數據規模、需要解決的關鍵科學和技術問題展開深入分析與討論。
概述
自動駕駛作為人工智能重要應用領域之一,有望重塑現有的交通和運輸模式,極大提升交通效率和安全性,對未來城市和社會發展產生深遠影響。目前,國內的智能網聯汽車產業已經邁入商業化的試水和起步階段。道路測試和示范應用場景趨于成熟,自動駕駛功能技術加速迭代,車聯網應用場景日益豐富,各層面相關法規政策加速出臺,共同推動市場進入高速發展期。 一方面,自動駕駛技術需要大量數據來訓練算法模型,以識別和理解道路環境,從而做出正確的決策和行動,實現準確、穩定和安全的駕駛體驗,數據的建設對于自動駕駛技術的發展至關重要。另一方面,自然語言處理和通用視覺領域大模型的出現,更加印證了海量高質量數據的重要性,給予自動駕駛的數據集建設以啟發!
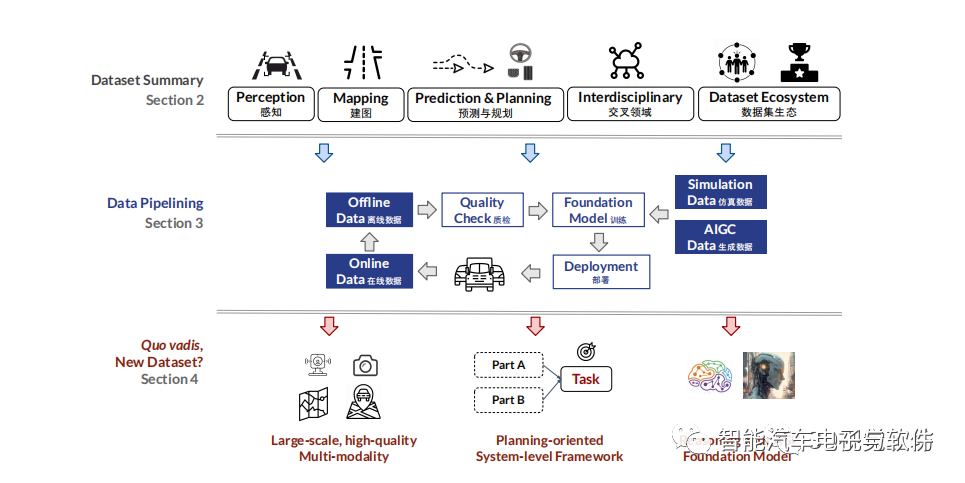
綜述文章架構
自動駕駛數據集
該綜述把目前開源的近百種數據集分為兩代:第一代數據集以 KITTI為標志,該數據集于2012年提出,輸入傳感模態由單目攝像頭與激光雷達構成,并提出了一系列綜合感知任務。第二代數據集以 nuScenes 及 Waymo 數據集為代表,傳感模態復雜度變高,環視相機、激光雷達、定位信息以及高精地圖成為常見組成部分,下游任務面向感知、建圖、預測與路徑規劃綜合任務。
傳感器模態復雜度逐漸提高:環視相機,激光雷達,高精地圖,超聲波雷達傳感器,GPS、IMU、HD Map等。
數據集規模與多樣性日益增長:在數據豐富度方面,主流自動駕駛數據集的采集時長由最初的10小時左右逐漸提升至100小時,隨著自動標注技術及標注工具的演進,近些年也出現了超過 1000 小時的數據集。駕駛場景的多樣性也是自動駕駛系統表現的另一關鍵因素。為了提高算法在特定場景下的表現能力,部分數據集分別在多個大洲多個城市進行采集。
數據集任務從感知延伸至預測與規劃:2016 年推出的 Cityscapes 與 Mapillary 等數據集下游任務聚焦于動態物體檢測。2019 年推出的 SemanticKITTI 、DrivingStereo等數據集引入語義分割、深度估計、光流估計等任務。在傳統預測與規劃模塊一般應用數值計算、優化、搜索等方法求解。2019 年前后提出的 nuScenes、Waymo 、Argoverse V2 等數據集,不僅包括感知任務還涵蓋預測與規劃任務,實現了在同一數據集上進行多種任務研究,同時引領社區在傳統多個模塊范式下端到端自動駕駛研究的潮流。
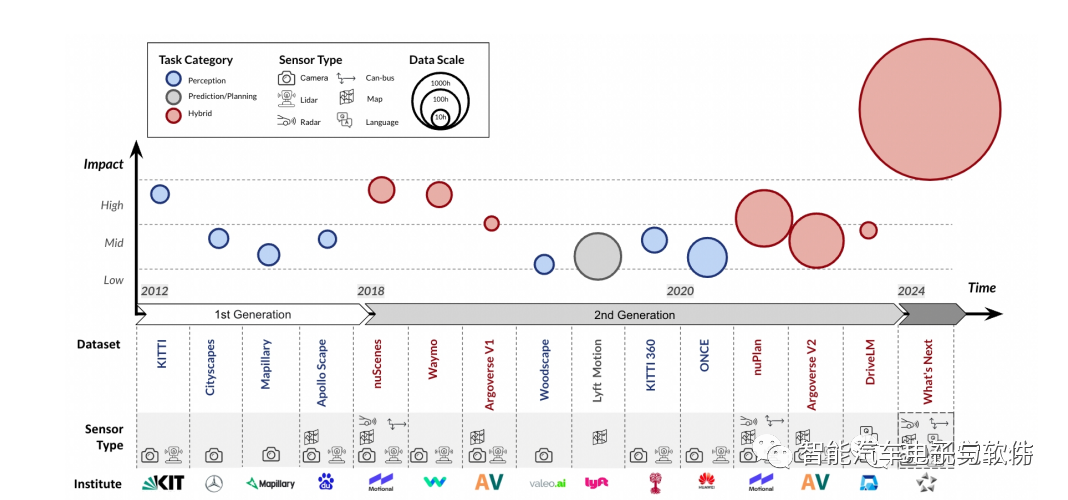
自動駕駛開源數據集影響力估計
數據算法閉環體系
模塊化自動駕駛系統包括感知、決策、規劃、控制等組件,其中大部分功能是通過數據驅動的神經網絡模型實現的。對于這些模塊來說,海量和高質量的數據是確保模塊性能的必要條件。 首先,海量數據的引入對于解決現存自動駕駛系統中的各種問題都很有必要。自動駕駛工程中一直存在的問題是長尾問題。其產生原因在于訓練模型的數據量不足而導致存在少量情況未被模型學習,而在模型推理階段,模型并不能對這些邊緣場景給出正確的結果。另外,對于基于規則的模塊,現有的方式是通過人工設計各種規則來使模塊輸出符合人為設計邏輯的結果。這個方法耗時耗力,并且難以覆蓋所有情況,有可能導致自動駕駛系統在某些未見場景下失效。而使用數據驅動的神經網絡代替這些模塊是一個可能的解決方案。 同時,在神經網絡學習過程中,數據噪聲的引入會不可避免地對優化過程產生負面影響,并降低模型性能。數據質量不僅包括傳感器數據的分辨率和同步性等,還包括標簽的準確性。在這兩個方面中,任意一個方面存在質量問題都直接影響著自動駕駛系統的性能和安全性。 綜上,海量和高質量的數據成為構建自動駕駛系統必不可少的一個環節。
大模型時代下的新一代自動駕駛數據集
當前基礎大模型在自然語言處理、計算機視覺等領域取得了舉世矚目的成果,但目前市面上還沒有面向自動駕駛垂直領域的大模型。以其他領域的大模型作為參照,新一代數據集至少應將數據量提升至與其他領域相近才能夠賦能自動駕駛大模型。 在保證數據數量的前提下,場景豐富度對算法性能更為重要。自動駕駛車輛在真實世界中會不可避免地遇到訓練數據之外的場景大規模地應用自動駕駛技術必然要求模型能夠在罕見場景中做出正確行為,避免發生危險或功能失效的情況。對于絕大多數交通場景來說,并不需要十分大量的數據就能夠覆蓋,而更需要關注的是長尾場景,由于某些交通場景十分罕見,如撞車等,數據的缺失會對自動駕駛系統的性能影響巨大。
第一、二代自動駕駛數據集已經不能夠繼續滿足自動駕駛系統的發展需求,新一代數據集的建設亟待提上日程。在大模型時代,大數據成為新一代數據集不可缺少的一個特點。同時,模塊化設計的自動駕駛系統在落地過程遇到迭代成本高、性能上界受限等問題,端到端自動駕駛架構逐步受到業界的青睞。除此之外,多模態傳感器、高質量標注、模型邏輯推理能力等方面也需要得到重視。基于此,該綜述總結歸納了新一代數據集的發展目標:面向多模態、保質保量;面向端到端、決策導向;面向智能化、邏輯推理。

大模型時代下的自動駕駛數據集展望
結論
該綜述全面回顧了自動駕駛公開數據集的現狀與挑戰。針對數據算法閉環體系,結合當前大模型發展趨勢,提出了下一代自動駕駛數據集的愿景與規劃。該綜述系統性地總結了自動駕駛發展歷程中所使用的數據集,并展示了通過挑戰賽與榜單促進社區發展的重要性;概括性地分析了自動駕駛數據算法閉環體系,并總結其中各個重要環節的作用,最后通過應用案例展現對數據算法閉環體系的使用方法。
-
算法
+關注
關注
23文章
4599瀏覽量
92643 -
數據集
+關注
關注
4文章
1205瀏覽量
24644 -
自動駕駛
+關注
關注
783文章
13684瀏覽量
166147
原文標題:自動駕駛公開數據集的現狀與挑戰
文章出處:【微信號:智能汽車電子與軟件,微信公眾號:智能汽車電子與軟件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
標貝科技:自動駕駛中的數據標注類別分享

標貝科技:自動駕駛中的數據標注類別分享

淺談自動駕駛技術的現狀及發展趨勢

FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
中級自動駕駛架構師應該學習哪些知識
初級自動駕駛架構師應該學習哪些知識
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
自動駕駛發展問題及解決方案淺析
自動駕駛數據集的生成模型之WoVoGen框架原理







 工商網監
工商網監
評論