 常用的解決內存錯誤的方法
常用的解決內存錯誤的方法
1. 內存管理功能問題
由于C++語言對內存有主動控制權,內存使用靈活和效率高,但代價是不小心使用就會導致以下內存錯誤:
? memory overrun:寫內存越界 ? double free:同一塊內存釋放兩次 ? use after free:內存釋放后使用 ? wild free:釋放內存的參數為非法值 ? access uninitialized memory:訪問未初始化內存 ? read invalid memory:讀取非法內存,本質上也屬于內存越界 ? memory leak:內存泄露 ? use after return:caller訪問一個指針,該指針指向callee的棧內內存 ? stack overflow:棧溢出
常用的解決內存錯誤的方法
- 代碼靜態檢測
靜態代碼檢測是指無需運行被測代碼,通過詞法分析、語法分析、控制流、數據流分析等技術對程序代碼進行掃描,找出代碼隱藏的錯誤和缺陷,如參數不匹配,有歧義的嵌套語句,錯誤的遞歸,非法計算,可能出現的空指針引用等等。統計證明,在整個軟件開發生命周期中,30%至70%的代碼邏輯設計和編碼缺陷是可以通過靜態代碼分析來發現和修復的。在C++項目開發過程中,因為其為編譯執行語言,語言規則要求較高,開發團隊往往要花費大量的時間和精力發現并修改代碼缺陷。所以C++靜態代碼分析工具能夠幫助開發人員快速、有效的定位代碼缺陷并及時糾正這些問題,從而極大地提高軟件可靠性并節省開發成本。
靜態代碼分析工具的優勢:
1、自動執行靜態代碼分析,快速定位代碼隱藏錯誤和缺陷。
2、幫助代碼設計人員更專注于分析和解決代碼設計缺陷。
3、減少在代碼人工檢查上花費的時間,提高軟件可靠性并節省開發成本。
一些主流的靜態代碼檢測工具,免費的cppcheck,clang static analyzer;
商用的coverity,pclint等
各個工具性能對比:
- 代碼動態檢測
所謂的代碼動態檢測,就是需要再程序運行情況下,通過插入特殊指令,進行動態檢測和收集運行數據信息,然后分析給出報告。
1.為了檢測內存非法使用,需要hook內存分配和操作函數。hook的方法可以是用C-preprocessor,也可以是在鏈接庫中直接定義(因為Glibc中的malloc/free等函數都是weak symbol),或是用LD_PRELOAD。另外,通過hook strcpy(),memmove()等函數可以檢測它們是否引起buffer overflow。
- 為了檢查內存的非法訪問,需要對程序的內存進行bookkeeping,然后截獲每次訪存操作并檢測是否合法。bookkeeping的方法大同小異,主要思想是用shadow memory來驗證某塊內存的合法性。至于instrumentation的方法各種各樣。有run-time的,比如通過把程序運行在虛擬機中或是通過binary translator來運行;或是compile-time的,在編譯時就在訪存指令時就加入檢查操作。另外也可以通過在分配內存前后加設為不可訪問的guard page,這樣可以利用硬件(MMU)來觸發SIGSEGV,從而提高速度。
3.為了檢測棧的問題,一般在stack上設置canary,即在函數調用時在棧上寫magic number或是隨機值,然后在函數返回時檢查是否被改寫。另外可以通過mprotect()在stack的頂端設置guard page,這樣棧溢出會導致SIGSEGV而不至于破壞數據。
工具總結對比,常用valgrind(檢測內存泄露),gperftools(統計內存消耗)等:
DBI:動態二進制工具 CTI:編譯時工具 UMR:未初始化的存儲器讀取 UAF:釋放后使用(又名懸掛指針) UAR:返回后使用 OOB:越界 x86:包括32和64-少量。在GCC 4.9中已刪除了 Mudflap,因為它已被AddressSanitizer取代。 Guard Page:一系列內存錯誤檢測器(Linux上為電子圍欄或DUMA,Windows上為Page Heap,OS X上為 libgmalloc)gperftools:與TCMalloc捆綁在一起的各種性能工具/錯誤檢測器。堆檢查器(檢漏器)僅在Linux上可用。調試分配器同時提供了保護頁和Canary值,以更精確地檢測OOB寫入,因此它比僅保護頁的檢測器要好。
2. C++內存管理效率問題
1、內存管理可以分為三個層次
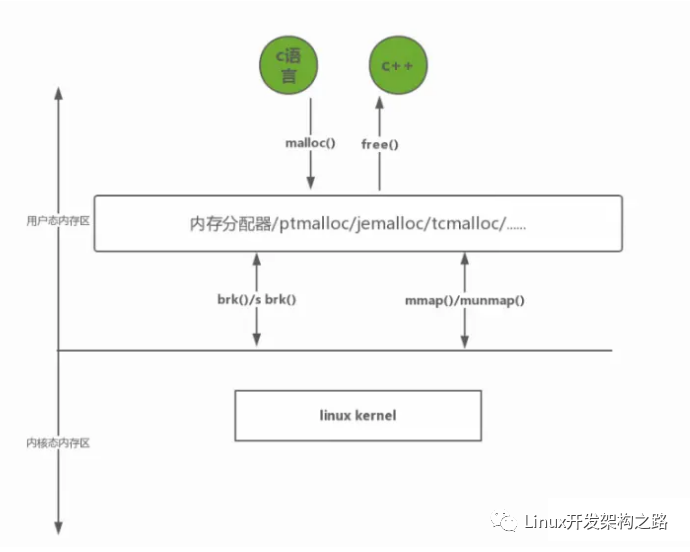
自底向上分別是:
- 第一層:操作系統內核的內存管理-虛擬內存管理
- 第二層:glibc層維護的內存管理算法
- 第三層:應用程序從glibc動態分配內存后,根據應用程序本身的程序特性進行優化, 比如SGI STL allocator,使用引用計數std::shared_ptr,RAII,實現應用的內存池等等。
當然應用程序也可以直接使用系統調用從內核分配內存,自己根據程序特性來維護內存,但是會大大增加開發成本。
2、C++內存管理問題
- 頻繁的new/delete勢必會造成內存碎片化,使內存再分配和回收的效率下降;
- new/delete分配內存在linux下默認是通過調用glibc的api-malloc/free來實現的,而這些api是通過調用到linux的系統調用:
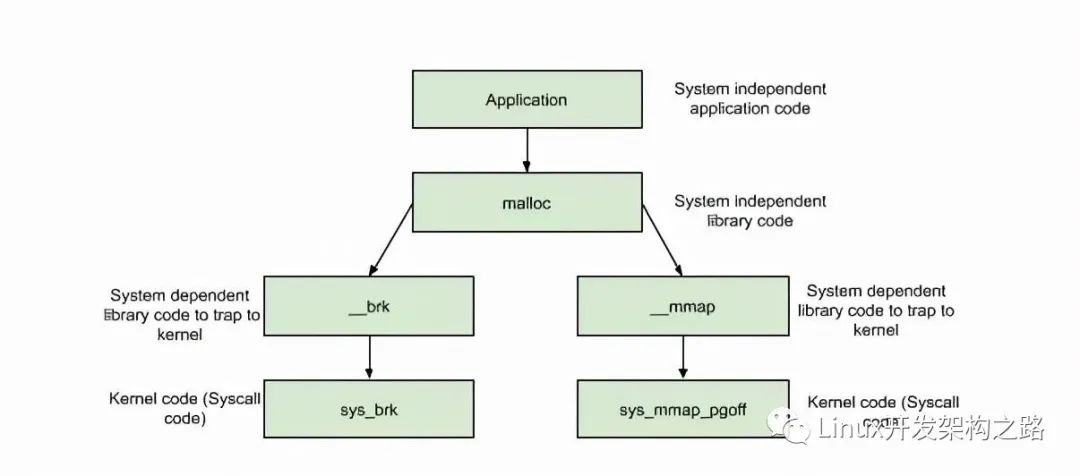
brk()/sbrk() // 通過移動Heap堆頂指針brk,達到增加內存目的 mmap()/munmap() // 通過文件影射的方式,把文件映射到mmap區
分配內存 < DEFAULT_MMAP_THRESHOLD,走brk,從內存池獲取,失敗的話走brk系統調用
分配內存 > DEFAULT_MMAP_THRESHOLD,走mmap,直接調用mmap系統調用
其中,DEFAULT_MMAP_THRESHOLD默認為128k,可通過mallopt進行設置。
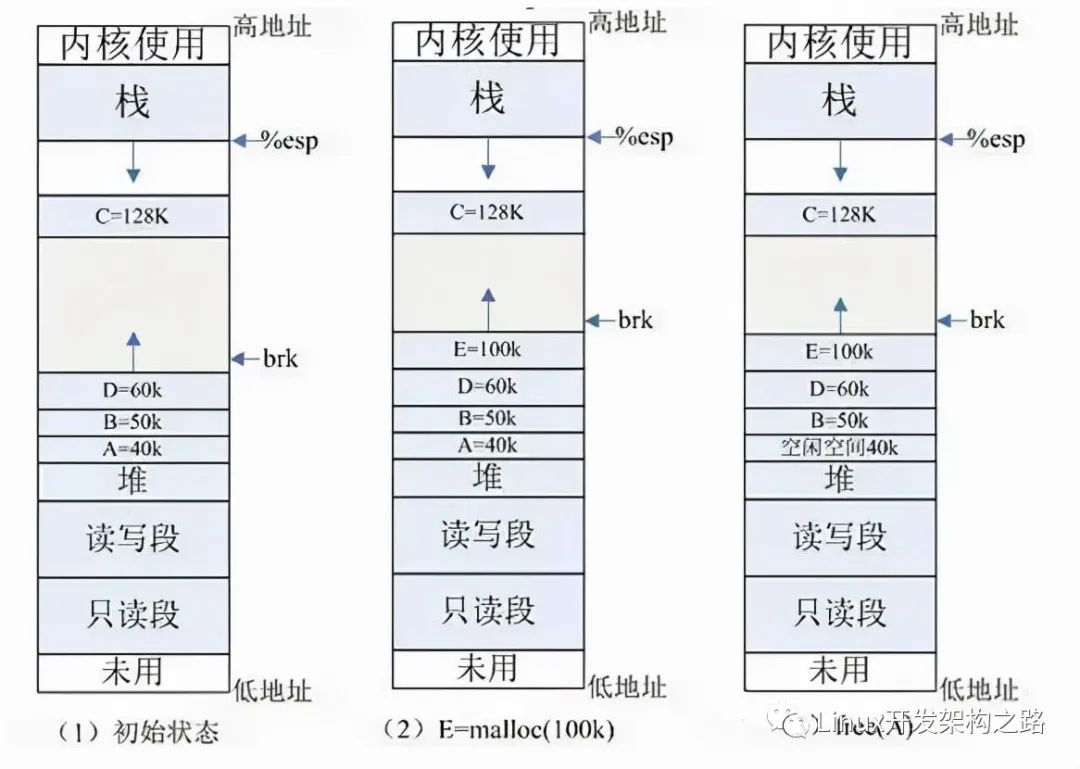
sbrk/brk系統調用的實現:分配內存是通過調節堆頂的位置來實現, 堆頂的位置是通過函數 brk 和 sbrk 進行動態調整,參考例子:
(1) 初始狀態:如圖 (1) 所示,系統已分配 ABCD 四塊內存,其中 ABD 在堆內分配, C 使用 mmap 分配。為簡單起見,圖中忽略了如共享庫等文件映射區域的地址空間。
(2) E=malloc(100k) :分配 100k 內存,小于 128k ,從堆內分配,堆內剩余空間不足,擴展堆頂 (brk) 指針。
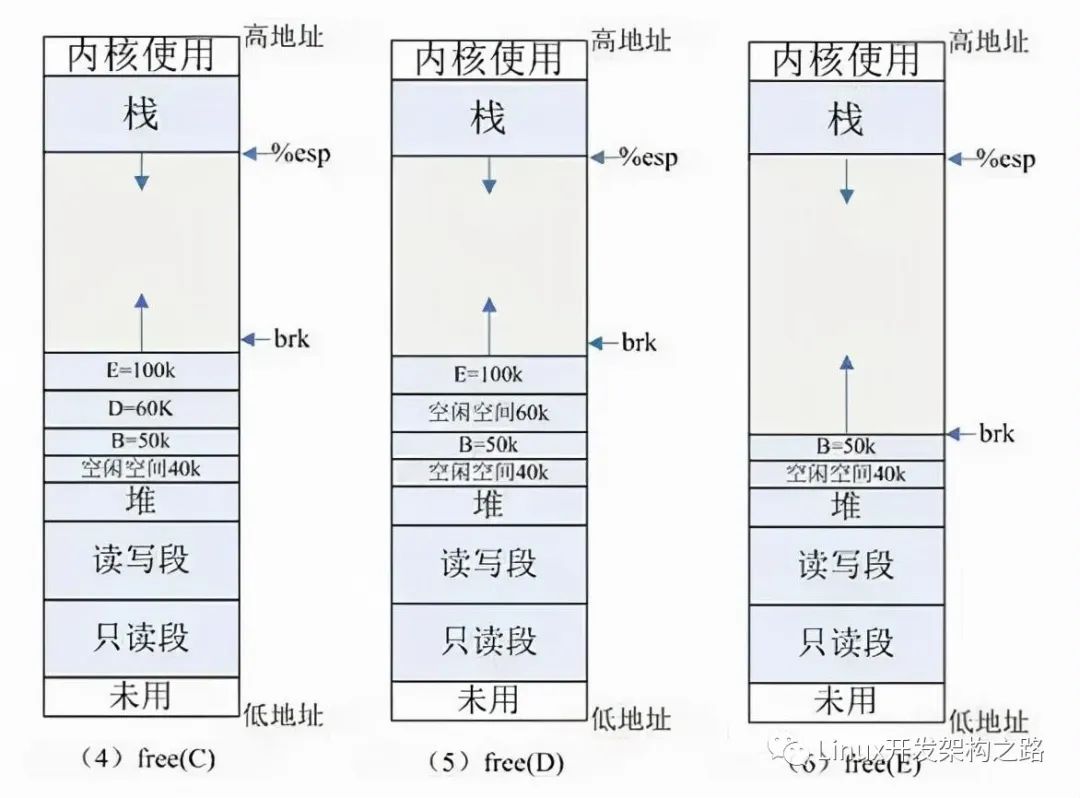
(3) free(A) :釋放 A 的內存,在 glibc 中,僅僅是標記為可用,形成一個內存空洞 ( 碎片 ),并沒有真正釋放。如果此時需要分配 40k 以內的空間,可重用此空間,剩余空間形成新的小碎片。
(4) free(C) :C 空間大于 128K ,使用 mmap 分配,如果釋放 C ,會調用 munmap 系統調用來釋放,并會真正釋放該空間,還給 OS ,如圖 (4) 所示。
所以free的內存不一定真正的歸還給OS,隨著系統頻繁地 malloc 和 free ,尤其對于小塊內存,堆內將產生越來越多不可用的碎片,導致“內存泄露”。而這種“泄露”現象使用 valgrind 是無法檢測出來的。
- 綜上,頻繁內存分配釋放還會導致大量系統調用開銷,影響效率,降低整體性能;
3. 常用解決上述問題的方案
內存池技術
內存池方案通常一次從系統申請一大塊內存塊,然后基于在這塊內存塊可以進行不同內存策略實現,可以比較好得解決上面提到的問題,一般采用內存池有以下好處:
1.少量系統申請次數,非常少(幾沒有) 堆碎片。2.由于沒有系統調用等,比通常的內存申請/釋放(比如通過malloc, new等)的方式快。3.可以檢查應用的任何一塊內存是否在內存池里。4.寫一個”堆轉儲(Heap-Dump)”到你的硬盤(對事后的調試非常有用)。5.可以更方便實現某種內存泄漏檢測(memory-leak detection)。
6.減少額外系統內存管理開銷,可以節約內存;
內存管理方案實現的指標:
- 額外的空間損耗盡量少
- 分配速度盡可能快
- 盡量避免內存碎片
- 多線程性能好
- 緩存本地化友好
- 通用性,兼容性,可移植性,易調試等
各個內存分配器的實現都是在以上的各種指標中進行權衡選擇.
4. 一些業界主流的內存管理方案
SGI STL allocator
是比較優秀的 C++庫內存分配器(細節參考上面描述)
ptmalloc
是glibc的內存分配管理模塊, 主要核心技術點:
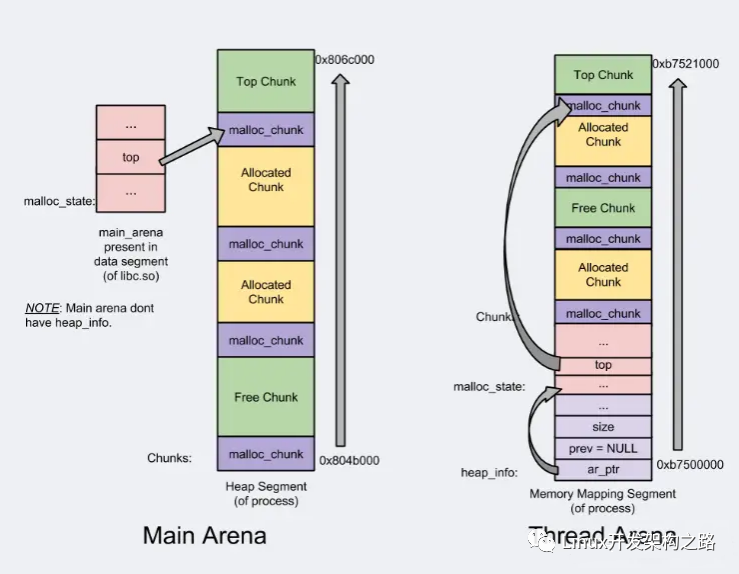
- Arena-main /thread;支持多線程
- Heap segments;for thread arena via by mmap call ;提高管理
- chunk/Top chunk/Last Remainder chunk;提高內存分配的局部性
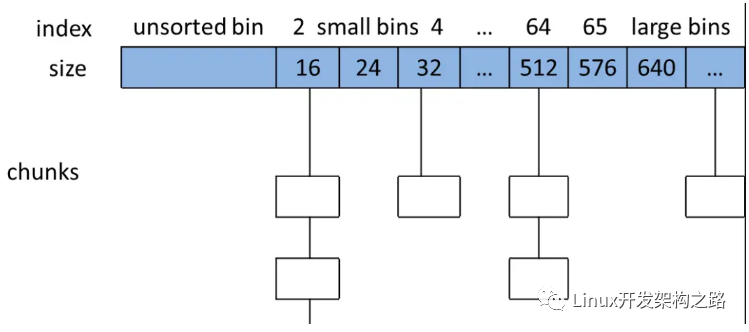
- bins/fast bin/unsorted bin/small bin/large bin;提高分配效率
ptmalloc的缺陷
- 后分配的內存先釋放,因為 ptmalloc 收縮內存是從 top chunk 開始,如果與 top chunk 相鄰的 chunk 不能釋放, top chunk 以下的 chunk 都無法釋放。
- 多線程鎖開銷大, 需要避免多線程頻繁分配釋放。
- 內存從thread的areana中分配, 內存不能從一個arena移動到另一個arena, 就是說如果多線程使用內存不均衡,容易導致內存的浪費。比如說線程1使用了300M內存,完成任務后glibc沒有釋放給操作系統,線程2開始創建了一個新的arena, 但是線程1的300M卻不能用了。
- 每個chunk至少8字節的開銷很大
- 不定期分配長生命周期的內存容易造成內存碎片,不利于回收。64位系統最好分配32M以上內存,這是使用mmap的閾值。
tcmalloc
google的gperftools內存分配管理模塊, 主要核心技術點:
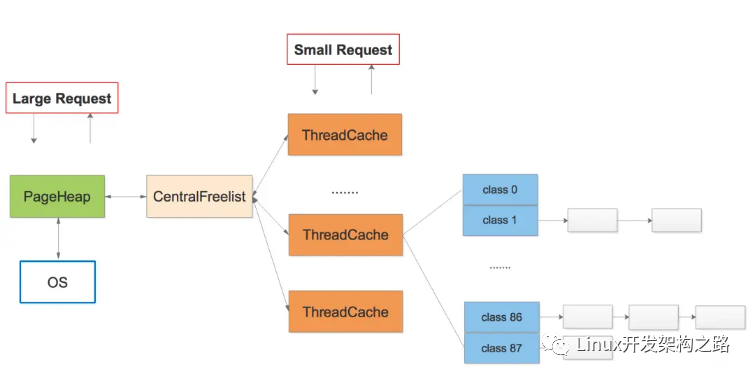
- thread-localcache/periodic garbagecollections/CentralFreeList;提高多線程性能,提高cache利用率
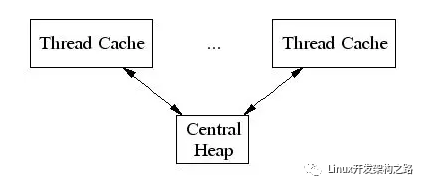
TCMalloc給每個線程分配了一個線程局部緩存。小分配可以直接由線程局部緩存來滿足。需要的話,會將對象從中央數據結構移動到線程局部緩存中,同時定期的垃圾收集將用于把內存從線程局部緩存遷移回中央數據結構中:
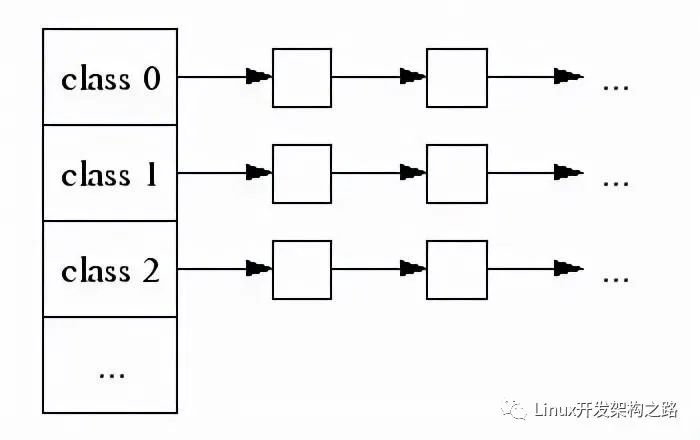
- Thread Specific Free List/size-classes [8,16,32,…32k]: 更好小對象內存分配;
每個小對象的大小都會被映射到170個可分配的尺寸類別中的一個。例如,在分配961到1024字節時,都會歸整為1024字節。尺寸類別這樣隔開:較小的尺寸相差8字節,較大的尺寸相差16字節,再大一點的尺寸差32字節,如此類推。最大的間隔(對于尺寸 >= ~2K的)是256字節。一個線程緩存對每個尺寸類都包含了一個自由對象的單向鏈表
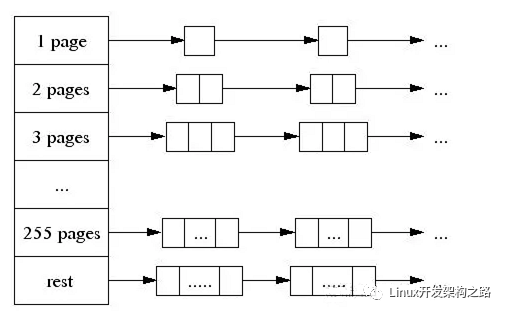
- The central page heap:更好的大對象內存分配,一個大對象的尺寸(> 32K)會被除以一個頁面尺寸(4K)并取整(大于結果的最小整數),同時是由中央頁面堆來處理 的。中央頁面堆又是一個自由列表的陣列。對于i < 256而言,第k個條目是一個由k個頁面組成的自由列表。第256個條目則是一個包含了長度>= 256個頁面的自由列表:
- Spans:
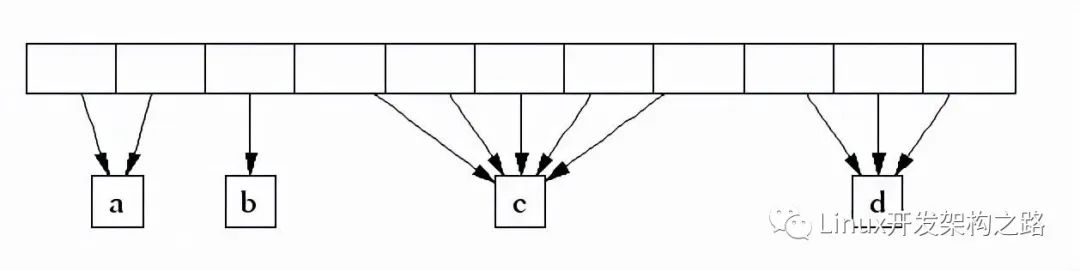
TCMalloc管理的堆由一系列頁面組成。連續的頁面由一個“跨度”(Span)對象來表示。一個跨度可以是_已被分配_或者是_自由_的。如果是自由的,跨度則會是一個頁面堆鏈表中的一個條目。如果已被分配,它會是一個已經被傳遞給應用程序的大對象,或者是一個已經被分割成一系列小對象的一個頁面。如果是被分割成小對象的,對象的尺寸類別會被記錄在跨度中。
由頁面號索引的中央數組可以用于找到某個頁面所屬的跨度。例如,下面的跨度_a_占據了2個頁面,跨度_b_占據了1個頁面,跨度_c_占據了5個頁面最后跨度_d_占據了3個頁面。
tcmalloc的改進
- ThreadCache會階段性的回收內存到CentralCache里。解決了ptmalloc2中arena之間不能遷移的問題。
- Tcmalloc占用更少的額外空間。例如,分配N個8字節對象可能要使用大約8N * 1.01字節的空間。即,多用百分之一的空間。Ptmalloc2使用最少8字節描述一個chunk。
- 更快。小對象幾乎無鎖, >32KB的對象從CentralCache中分配使用自旋鎖。并且>32KB對象都是頁面對齊分配,多線程的時候應盡量避免頻繁分配,否則也會造成自旋鎖的競爭和頁面對齊造成的浪費。
jemalloc
FreeBSD的提供的內存分配管理模塊, 主要核心技術點:
- 與tcmalloc類似,每個線程同樣在<32KB的時候無鎖使用線程本地cache;
- Jemalloc在64bits系統上使用下面的size-class分類:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840] Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] Huge: [4 MiB, 8 MiB, 12 MiB, …]
- small/large對象查找metadata需要常量時間, huge對象通過全局紅黑樹在對數時間內查找
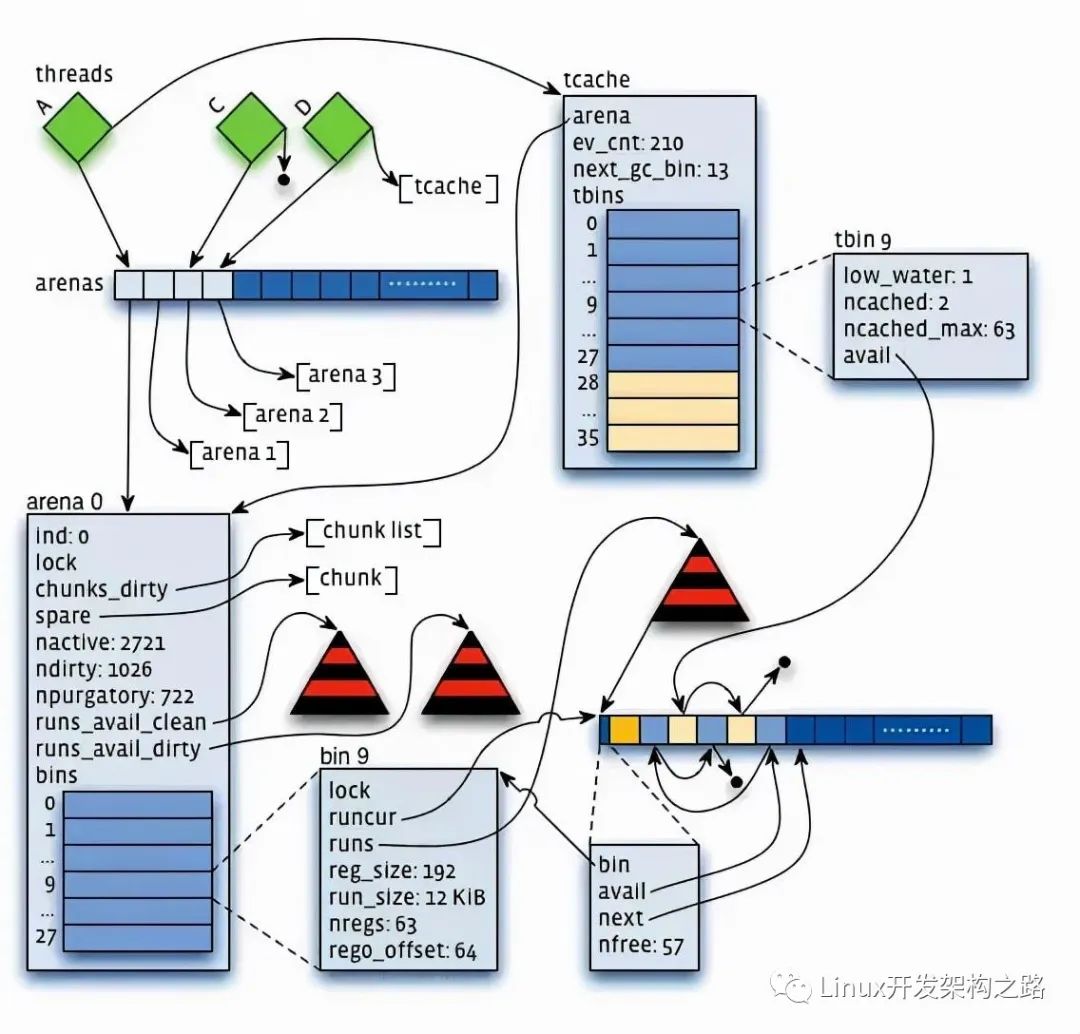
- 虛擬內存被邏輯上分割成chunks(默認是4MB,1024個4k頁),應用線程通過round-robin算法在第一次malloc的時候分配arena, 每個arena都是相互獨立的,維護自己的chunks, chunk切割pages到small/large對象。free()的內存總是返回到所屬的arena中,而不管是哪個線程調用free().
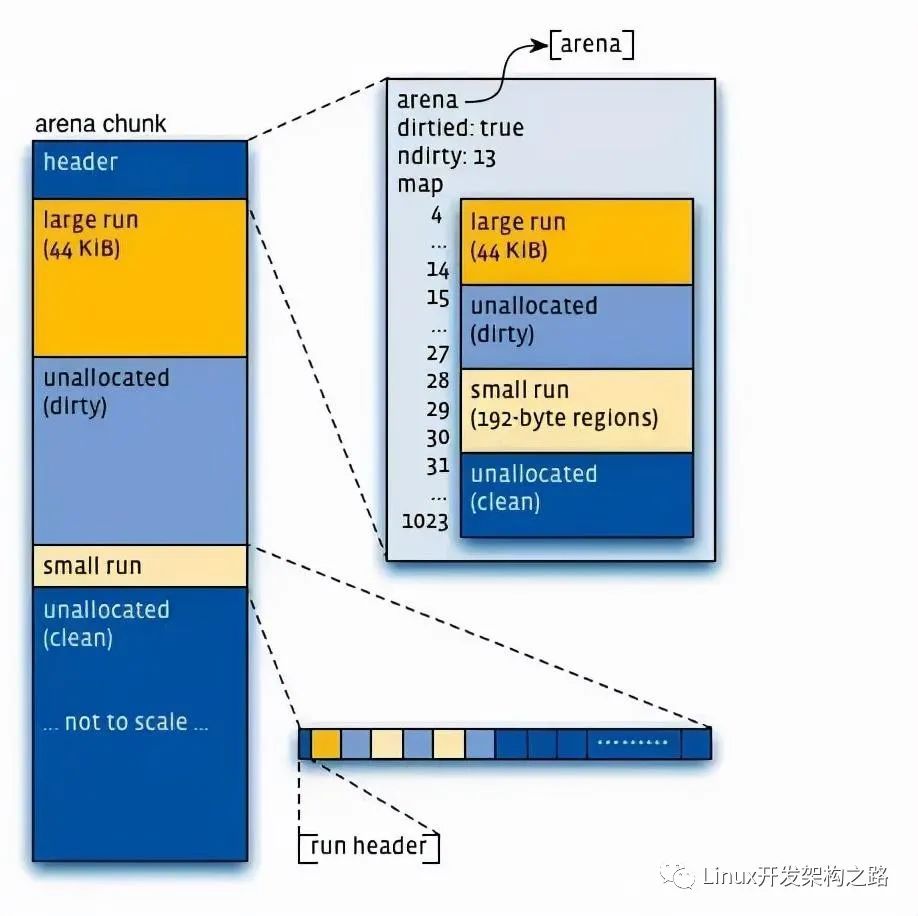
上圖可以看到每個arena管理的arena chunk結構, 開始的header主要是維護了一個page map(1024個頁面關聯的對象狀態), header下方就是它的頁面空間。Small對象被分到一起, metadata信息存放在起始位置。large chunk相互獨立,它的metadata信息存放在chunk header map中。
- 通過arena分配的時候需要對arena bin(每個small size-class一個,細粒度)加鎖,或arena本身加鎖。并且線程cache對象也會通過垃圾回收指數退讓算法返回到arena中。
jemalloc的優化
- Jmalloc小對象也根據size-class,但是它使用了低地址優先的策略,來降低內存碎片化。
- Jemalloc大概需要2%的額外開銷。(tcmalloc 1%, ptmalloc最少8B).
- Jemalloc和tcmalloc類似的線程本地緩存,避免鎖的競爭 .
- 相對未使用的頁面,優先使用dirty page,提升緩存命中。
性能比較
測試環境:2x Intel E5/2.2Ghz with 8 real cores per socket,16 real cores, 開啟hyper-threading, 總共32個vcpu。16個table,每個5M row。OLTP_RO測試包含5個select查詢:select_ranges, select_order_ranges, select_distinct_ranges, select_sum_ranges:
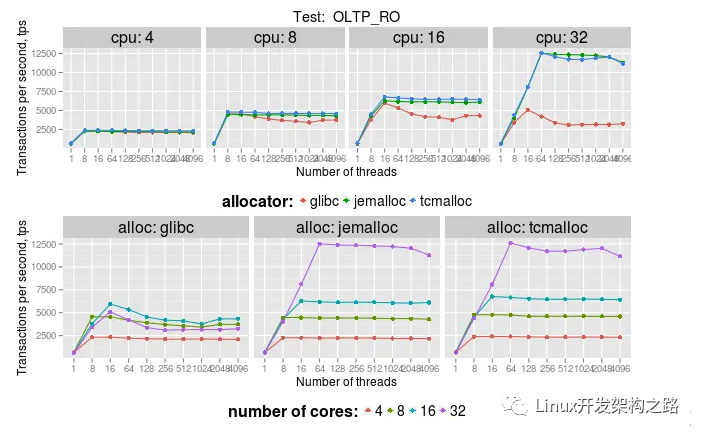
facebook的測試結果:
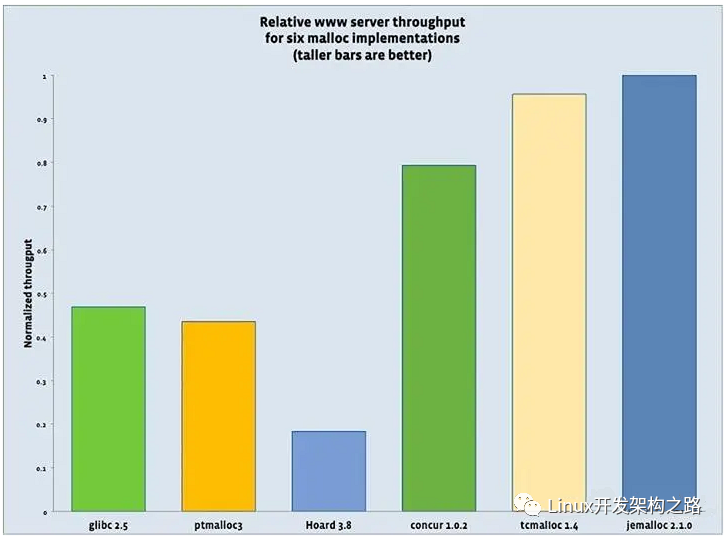
服務器吞吐量分別用6個malloc實現的對比數據,可以看到tcmalloc和jemalloc最好(tcmalloc這里版本較舊)。
總結
可以看出tcmalloc和jemalloc性能接近,比ptmalloc性能要好,在多線程環境使用tcmalloc和jemalloc效果非常明顯。一般支持多核多線程擴展情況下可以使用jemalloc;反之使用tcmalloc可能是更好的選擇。
-
內存
+關注
關注
8文章
3004瀏覽量
73900 -
軟件
+關注
關注
69文章
4799瀏覽量
87175 -
代碼
+關注
關注
30文章
4753瀏覽量
68368 -
C++語言
+關注
關注
0文章
147瀏覽量
6972
發布評論請先 登錄
相關推薦
C程序中10個與內存有關的常見錯誤
內存故障及解決方法
內存錯誤提示的分析解決

java中三種常見內存溢出錯誤的處理方法
內存讀寫錯誤的原因分析及解決辦法
什么是段錯誤?
內存泄漏問題原理及檢視方法
C語言常見內存錯誤及解決方法
【openssl】從openssl的常用接口淺談【內存泄漏】





 工商網監
工商網監
評論