 進程間通信的原理
進程間通信的原理
一.為什么進程間需要通信?
1).數據傳輸
一個進程需要將它的數據發送給另一個進程;
2).資源共享
多個進程之間共享同樣的資源;
3).通知事件
一個進程需要向另一個或一組進程發送消息,通知它們發生了某種事件;
4).進程控制
有些進程希望完全控制另一個進程的執行(如Debug進程),該控制進程希望能夠攔截另一個進程的所有操作,并能夠及時知道它的狀態改變。
基于以上幾個原因,所以就有了進程間通信的概念,那仫進程間通信的原理是什仫呢?目前有哪幾種進程間通信的機制?他們是如何實現進程間通信的呢?在這篇文章中我會就這幾個問題進行詳細的講解。
二.進程間通信的原理
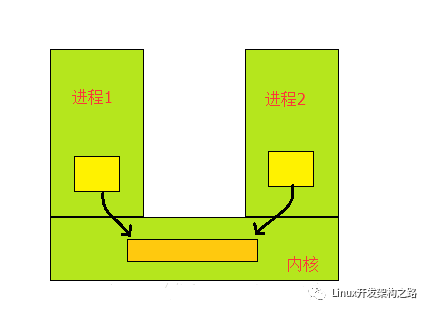
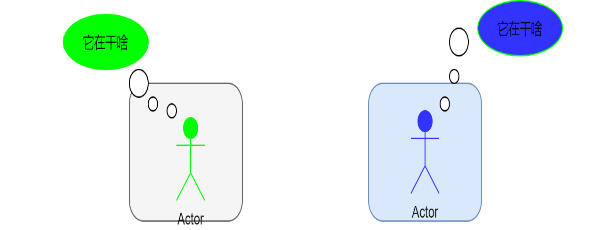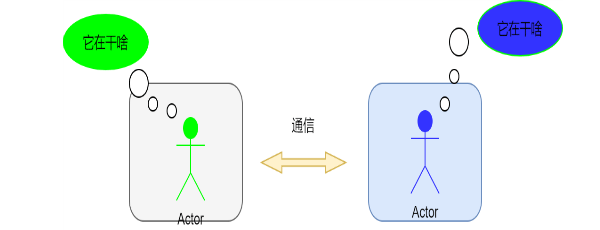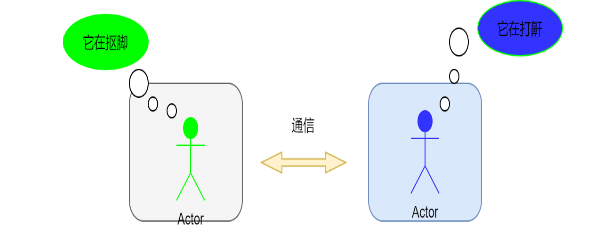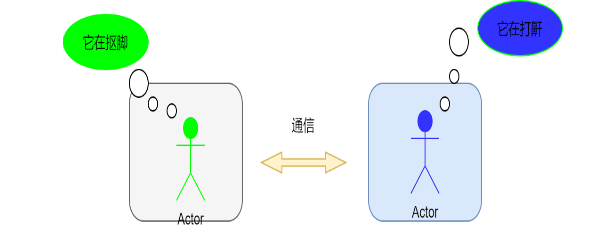
每個進程各自有不同的用戶地址空間,任何一個進程的全局變量在另一個進程中都看不到,所以進程之間要交換數據必須通過內核,在內核中開辟一塊緩沖區,進程1把數據從用戶空間拷到內核緩沖區,進程2再從內核緩沖區把數據讀走,內核提供的這種機制稱為進程間通信機制。
主要的過程如下圖所示:
三.進程間通信的幾種方式
1.管道(pipe)
管道又名匿名管道,這是一種最基本的IPC機制,由pipe函數創建:
#include
int pipe(int pipefd[2]);
返回值:成功返回0,失敗返回-1;
調用pipe函數時在內核中開辟一塊緩沖區用于通信,它有一個讀端,一個寫端:pipefd[0]指向管道的讀端,pipefd[1]指向管道的寫端。所以管道在用戶程序看起來就像一個打開的文件,通過read(pipefd[0])或者write(pipefd[1])向這個文件讀寫數據,其實是在讀寫內核緩沖區。
使用管道的通信過程:



1.父進程調用pipe開辟管道,得到兩個文件描述符指向管道的兩端。
2.父進程調用fork創建子進程,那么子進程也有兩個文件描述符指向同一管道。
3.父進程關閉管道讀端,子進程關閉管道寫端。父進程可以往管道里寫,子進程可以從管道里讀,管道是用環形隊列實現的,數據從寫端流入從讀端流出,這樣就實現了進程間通信。
管道出現的四種特殊情況:
1.寫端關閉,讀端不關閉;
那么管道中剩余的數據都被讀取后,再次read會返回0,就像讀到文件末尾一樣。
2.寫端不關閉,但是也不寫數據,讀端不關閉;
此時管道中剩余的數據都被讀取之后再次read會被阻塞,直到管道中有數據可讀了才重新讀取數據并返回;
3.讀端關閉,寫端不關閉;
此時該進程會收到信號SIGPIPE,通常會導致進程異常終止。
4.讀端不關閉,但是也不讀取數據,寫端不關閉;
此時當寫端被寫滿之后再次write會阻塞,直到管道中有空位置了才會寫入數據并重新返回。
使用管道的缺點:
1.兩個進程通過一個管道只能實現單向通信,如果想雙向通信必須再重新創建一個管道或者使用sockpair才可以解決這類問題;
2.只能用于具有親緣關系的進程間通信,例如父子,兄弟進程。
一個簡單的關于管道的例子:
代碼實現如下:
#include
#include
#include
#include
int main()
{
int _pipe[2]={0,0};
int ret=pipe(_pipe); //創建管道
if(ret == -1)
{
perror("create pipe error");
return 1;
}
printf("_pipe[0] is %d,_pipe[1] is %dn",_pipe[0],_pipe[1]);
pid_t id=fork(); //父進程fork子進程
if(id < 0)
{
perror("fork error");
return 2;
}
else if(id == 0) //child,寫
{
printf("child writingn");
close(_pipe[0]);
int count=5;
const char *msg="i am from XATU";
while(count--)
{
write(_pipe[1],msg,strlen(msg));
sleep(1);
}
close(_pipe[1]);
exit(1);
}
else //father,讀
{
printf("father readingn");
close(_pipe[1]);
char msg[1024];
int count=5;
while(count--)
{
ssize_t s=read(_pipe[0],msg,sizeof(msg)-1);
if(s > 0){
msg[s]='?';
printf("client# %sn",msg);
}
else{
perror("read error");
exit(1);
}
}
if(waitpid(id,0,NULL) != -1){
printf("wait successn");
}
}
return 0;
}

2.命名管道(FIFO)
上一種進程間通信的方式是匿名的,所以只能用于具有親緣關系的進程間通信,命名管道的出現正好解決了這個問題。FIFO不同于管道之處在于它提供一個路徑名與之關聯,以FIFO的文件形式存儲文件系統中。命名管道是一個設備文件,因此即使進程與創建FIFO的進程不存在親緣關系,只要可以訪問該路徑,就能夠通過FIFO相互通信。
命名管道的創建與讀寫:
1).是在程序中使用系統函數建立命名管道;
2).是在Shell下交互地建立一個命名管道,Shell方式下可使用mknod或mkfifo命令來創建管道,兩個函數均定義在頭文件sys/stat.h中;
#include
#include
#include
#include
int mknod(const char *pathname, mode_t mode, dev_t dev);
#include
#include
int mkfifo(const char *pathname, mode_t mode);
返回值:都是成功返回0,失敗返回-1;
path為創建的命名管道的全路徑名;
mod為創建的命名管道的模式,指明其存取權限;
dev為設備值,該值取決于文件創建的種類,它只在創建設備文件時才會用到;
mkfifo函數的作用:在文件系統中創建一個文件,該文件用于提供FIFO功能,即命名管道。
命名管道的特點:
1.命名管道是一個存在于硬盤上的文件,而管道是存在于內存中的特殊文件。所以當使用命名管道的時候必須先open將其打開。
2.命名管道可以用于任何兩個進程之間的通信,不管這兩個進程是不是父子進程,也不管這兩個進程之間有沒有關系。
一個簡單的關于命名管道的例子:
代碼實現如下:
server.c
#include
#include
#include
#include
#include
void testserver()
{
int namepipe=mkfifo("myfifo",S_IFIFO|0666); //創建一個存取權限為0666的命名管道
if(namepipe == -1){
perror("mkfifo error");
exit(1);
}
int fd=open("./myfifo",O_RDWR); //打開該命名管道
if(fd == -1){
perror("open error");
exit(2);
}
char buf[1024];
while(1)
{
printf("sendto# ");
fflush(stdout);
ssize_t s=read(0,buf,sizeof(buf)-1); //從標準輸入獲取消息
if(s > 0){
buf[s-1]='?'; //過濾掉從標準輸入中獲取的換行
if(write(fd,buf,s) == -1){ //把該消息寫入到命名管道中
perror("write error");
exit(3);
}
}
}
close(fd);
}
int main()
{
testserver();
return 0;
}
client.c
#include
#include
#include
#include
#include
void testclient()
{
int fd=open("./myfifo",O_RDWR);
if(fd == -1){
perror("open error");
exit(1);
}
char buf[1024];
while(1){
ssize_t s=read(fd,buf,sizeof(buf)-1);
if(s > 0){
printf("client# %sn",buf);
}
else{ //讀失敗或者是讀取到字符結尾
perror("read error");
exit(2);
}
}
close(fd);
}
int main()
{
testclient();
return 0;
}

3.消息隊列(msg)
由于內容較多,以后再詳細分享
4.信號量(sem)
什仫是信號量?
信號量的本質是一種數據操作鎖,用來負責數據操作過程中的互斥,同步等功能。
信號量用來管理臨界資源的。它本身只是一種外部資源的標識,不具有數據交換功能,而是通過控制其他的通信資源實現進程間通信。可以這樣理解,信號量就相當于是一個計數器。當有進程對它所管理的資源進行請求時,進程先要讀取信號量的值:大于0,資源可以請求;等于0,資源不可以用,這時進程會進入睡眠狀態直至資源可用。
當一個進程不再使用資源時,信號量+1(對應的操作稱為V操作),反之當有進程使用資源時,信號量-1(對應的操作為P操作)。對信號量的值操作均為原子操作。
為什仫要使用信號量?
為了防止出現因多個程序同時訪問一個共享資源而引發的一系列問題,我們需要一種方法,它可以通過生成并使用令牌來授權,在任一時刻只能有一個執行線程訪問代碼的臨界區域。
什仫是臨界區?什仫是臨界資源?
臨界資源:一次只允許一個進程使用的資源。
臨界區:訪問臨界資源的程序代碼片段。
信號量的工作原理?
P(sv):如果sv的值大于零,就給它減1;如果它的值為零,就掛起該進程的執行等待操作;
V(sv):如果有其他進程因等待sv而被掛起,就讓它恢復運行,如果沒有進程因等待sv而掛起,就給它加1;
舉個例子,就是兩個進程共享信號量sv,一旦其中一個進程執行了P(sv)操作,它將得到信號量,并可以進入臨界區,使sv減1。而第二個進程將被阻止進入臨界區,因為當它試圖執行P(sv)時,sv為0,它會被掛起以等待第一個進程離開臨界區域并執行V(sv)釋放信號量,這時第二個進程就可以恢復執行了。
與信號量有關的函數操作?
1).創建/獲取一個信號量集合
#include
#include
#include
int semget(key_t key, int nsems, int semflg);
返回值:成功返回信號量集合的semid,失敗返回-1。
key:可以用函數key_t ftok(const char *pathname, int proj_id);來獲取。
nsems:這個參數表示你要創建的信號量集合中的信號量的個數。信號量只能以集合的形式創建。
semflg:同時使用IPC_CREAT和IPC_EXCL則會創建一個新的信號量集合。若已經存在的話則返回-1。單獨使用IPC_CREAT的話會返回一個新的或者已經存在的信號量集合。
2).信號量結合的操作
#include
#include
#include
int semop(int semid, struct sembuf *sops, unsigned nsops);
int semtimedop(int semid, struct sembuf *sops, unsigned nsops,struct timespec *timeout);
返回值:成功返回0,失敗返回-1;
semid:信號量集合的id;
struct sembuf *sops;
struct sembuf
{
unsigned short sem_num; /* semaphore number */
short sem_op; /* semaphore operation */
short sem_flg; /* operation flags */
}
sem_num:為信號量是以集合的形式存在的,就相當于所有信號在一個數組里面,sem_num表示信號量在集合中的編號;
sem_op:示該信號量的操作(P操作還是V操作)。如果其值為正數,該值會加到現有的信號內含值中。通常用于釋放所控資源的使用權;如果sem_op的值為負數,而其絕對值又大于信號的現值,操作將會阻塞,直到信號值大于或等于sem_op的絕對值。通常用于獲取資源的使用權 。
sem_flg:信號操作標志,它的取值有兩種:IPC_NOWAIT和SEM_UNDO。
IPC_NOWAIT:對信號量的操作不能滿足時,semop()不會阻塞,而是立即返回,同時設定錯誤信息;
SEM_UNDO: 程序結束時(不管是正常還是不正常),保證信號值會被設定;
nsops:表示要操作信號量的個數。因為信號量是以集合的形式存在,所以第二個參數可以傳一個數組,同時對一個集合中的多個信號量進行操作。
semop()調用之前的值。這樣做的目的在于避免程序在異常的情況下結束未將鎖定的資源解鎖(死鎖),造成資源永遠鎖定。
3).int semctl(int semid,int semnum,int cmd,...);
semctl()在semid標識的信號量集合上,或者該信號量集合上第semnum個信號量上執行cmd指定的控制命令。根據cmd不同,這個函數有三個或四個參數,當有第四個參數時,第四個參數的類型是union。
union semun{
int val; //使用的值
struct semid_ds *buf; //IPC_STAT、IPC_SET使用緩存區
unsigned short *array; //GETALL、SETALL使用的緩存區
struct seminfo *__buf; //IPC_INFO(linux特有)使用緩存區
};
返回值:成功返回0,失敗返回-1;
semid:信號量集合的編號。
semnum:信號量在集合中的標號。
4).信號量類似消息隊列也是隨內核的,除非用命令才可以刪除該信號量
ipcs -s //查看創建的信號量集合的個數
ipcrm -s semid //刪除一個信號量集合
一個簡單的關于信號量的例子?
父進程中打印BB,子進程中打印AA。利用信號量機制使得AA和BB之間不出現亂序。此時的顯示器就是臨界資源,我們需要在父子進程的臨界區進行加鎖。
comm.h
#ifndef COMM_H
#define COMM_H
#include
#include
#include
#include
#include
#include
#include
#include
#define PATHNAME "."
#define PROJID 0x6666
union semun{
int val; /* Value for SETVAL */
struct semid_ds buf; / Buffer for IPC_STAT, IPC_SET */
unsigned short array; / Array for GETALL, SETALL */
struct seminfo __buf; / Buffer for IPC_INFO(Linux-specific) */
};
int CreateSemSet(int num);//創建信號量
int GetSemSet(); //獲取信號量
int InitSem(int sem_id,int which);
int P(int sem_id,int which); //p操作
int V(int sem_id,int which); //v操作
int DestroySemSet(int sem_id);//銷毀信號量
#endif //COMM_H
comm.c
#include"comm.h"
static commSemSet(int num,int flag)
{
key_t key=ftok(PATHNAME,PROJID);
if(key == -1)
{
perror("ftok error");
exit(1);
}
int sem_id=semget(key,num,flag);
if(sem_id == -1)
{
perror("semget error");
exit(2);
}
return sem_id;
}
int CreateSemSet(int num)
{
return commSemSet(num,IPC_CREAT|IPC_EXCL|0666);
}
int InitSem(int sem_id,int which)
{
union semun un;
un.val=1;
int ret=semctl(sem_id,which,SETVAL,un);
if(ret < 0)
{
perror("semctl");
return -1;
}
return 0;
}
int GetSemSet()
{
return commSemSet(0,IPC_CREAT);
}
static int SemOp(int sem_id,int which,int op)
{
struct sembuf buf;
buf.sem_num=which;
buf.sem_op=op;
buf.sem_flg=0; //
int ret=semop(sem_id,&buf,1);
if(ret < 0)
{
perror("semop error");
return -1;
}
return 0;
}
int P(int sem_id,int which)
{
return SemOp(sem_id,which,-1);
}
int V(int sem_id,int which)
{
return SemOp(sem_id,which,1);
}
int DestroySemSet(int sem_id)
{
int ret=semctl(sem_id,0,IPC_RMID);
if(ret < 0)
{
perror("semctl error");
return -1;
}
return 0;
}
SemSet.c
#include"comm.h"
void testSemSet()
{
int sem_id=CreateSemSet(1); //創建信號量
InitSem(sem_id,0);
pid_t id=fork();
if(id < 0){
perror("fork error");
exit(1);
}
else if(id == 0){ //child,打印AA
printf("child is running,pid=%d,ppid=%dn",getpid(),getppid());
while(1)
{
P(sem_id,0); //p操作,信號量的值減1
printf("A");
usleep(10031);
fflush(stdout);
printf("A");
usleep(10021);
fflush(stdout);
V(sem_id,0); //v操作,信號量的值加1
}
}
else //father,打印BB
{
printf("father is running,pid=%d,ppid=%dn",getpid(),getppid());
while(1)
{
P(sem_id,0);
printf("B");
usleep(10051);
fflush(stdout);
printf("B");
usleep(10003);
fflush(stdout);
V(sem_id,0);
}
wait(NULL);
}
DestroySemSet(sem_id);
}
int main()
{
testSemSet();
return 0;
}
5.共享內存(shm)
共享內存的原理圖:

與共享內存有關的函數:
1). 創建共享內存
#include
#include
int shmget(key_t key, size_t size, int shmflg);
返回值:成功返回共享內存的id,失敗返回-1;
key:和上面介紹的信號量的semget函數的參數key一樣;
size:表示要申請的共享內存的大小,一般是4k的整數倍;
flags:IPC_CREAT和IPC_EXCL一起使用,則創建一個新的共享內存,否則返回-1。IPC_CREAT單獨使用時返回一個共享內存,有就直接返回,沒有就創建。
2).掛接函數
void *shmat(int shmid);
返回值:返回這塊內存的虛擬地址;
shmat的作用是將申請的共享內存掛接在該進程的頁表上,是將虛擬內存和物理內存相對應;
3).去掛接函數
int shmdt(const void *shmaddr);
返回值:失敗返回-1;
shmdt的作用是去掛接,將這塊共享內存從頁表上剝離下來,去除兩者的映射關系;
shmaddr:表示這塊物理內存的虛擬地址。
4).int shmctl(int shmid,int cmd,const void* addr);
shmctl用來設置共享內存的屬性。當cmd是IPC_RMID時可以用來刪除一塊共享內存。
5).共享內存類似消息隊列和信號量,它的生命周期也是隨內核的,除非用命令才可以刪除該共享內存;
ipcs -m //查看創建的共享內存的個數
ipcrm -m shm_id //刪除共享內存
一個簡單的關于共享內存的例子:
利用共享內存實現在serve這個進程中向共享內存中寫入數據A,從client讀出數據。
comm.h
#ifndef COMM
#define COMM
#include
#include
#include
#include
#include
#define PATHNAME "."
#define PROCID 0x6666
#define SIZE 4096*1
int CreatShm();
int GetShm();
//int AtShm();
//int DtShm();
int DestroyShm(int shm_id);
#endif
comm.c
#include"comm.h"
static int CommShm(int flag)
{
key_t key=ftok(PATHNAME,PROCID);
if(key < 0)
{
perror("ftok");
return -1;
}
int shm_id=shmget(key,SIZE,flag);
if(shm_id < 0)
{
perror("shmget");
return -2;
}
return shm_id;
}
int CreatShm()
{
return CommShm(IPC_CREAT|IPC_EXCL|0666);
}
int GetShm()
{
return CommShm(IPC_CREAT);
}
//int AtShm();
//int DtShm();
int DestroyShm(int shm_id)
{
int ret=shmctl(shm_id,IPC_RMID,NULL);
if(ret < 0)
{
perror("shmctl");
return -1;
}
return 0;
}
server.c
#include"comm.h"
void testserver()
{
int shm_id=CreatShm();
printf("shm_id=%dn",shm_id);
char *mem=(char *)shmat(shm_id,NULL,0);
while(1)
{
sleep(1);
printf("%sn",mem);
}
shmdt(mem);
DestroyShm(shm_id);
}
int main()
{
testserver();
return 0;
}
client.c
#include"comm.h"
void testclient()
{
int shm_id=GetShm();
char *mem=(char *)shmat(shm_id,NULL,0);
int index=0;
while(1)
{
sleep(1);
mem[index++]='A';
index %= (SIZE-1);
mem[index]='?';
}
shmdt(mem);
DestroyShm(shm_id);
}
int main()
{
testclient();
return 0;
}
共享內存的特點:
共享內存是這五種進程間通信方式中效率最高的。但是因為共享內存沒有提供相應的互斥機制,所以一般共享內存都和信號量配合起來使用。
為什仫共享內存的方式比其他進程間通信的方式效率高?
消息隊列,FIFO,管道的消息傳遞方式一般為 :
1).服務器獲取輸入的信息;
2).通過管道,消息隊列等寫入數據至內存中,通常需要將該數據拷貝到內核中;
3).客戶從內核中將數據拷貝到自己的客戶端進程中;
4).然后再從進程中拷貝到輸出文件;
上述過程通常要經過4次拷貝,才能完成文件的傳遞。
而共享內存只需要:
1).輸入內容到共享內存區
2).從共享內存輸出到文件
上述過程不涉及到內核的拷貝,這些進程間數據的傳遞就不再通過執行任何進入內核的系統調用來傳遞彼此的數據,節省了時間,所以共享內存是這五種進程間通信方式中效率最高的。
-
數據
+關注
關注
8文章
6909瀏覽量
88849 -
通信
+關注
關注
18文章
5977瀏覽量
135870 -
緩沖
+關注
關注
0文章
51瀏覽量
17811 -
程序
+關注
關注
116文章
3778瀏覽量
80859
發布評論請先 登錄
相關推薦
Linux下進程間通信
使用MQTT作為進程間通信的方式





 工商網監
工商網監
評論