 Linux線程、線程與異步編程、協程與異步介紹
Linux線程、線程與異步編程、協程與異步介紹
協程不是系統級線程,很多時候協程被稱為“輕量級線程”、“微線程”、“纖程(fiber)”等。簡單來說可以認為協程是線程里不同的函數,這些函數之間可以相互快速切換。
協程和用戶態線程非常接近,用戶態線程之間的切換不需要陷入內核,但部分操作系統中用戶態線程的切換需要內核態線程的輔助。
協程是編程語言(或者 lib)提供的特性(協程之間的切換方式與過程可以由編程人員確定),是用戶態操作。協程適用于 IO 密集型的任務。常見提供原生協程支持的語言有:c++20、golang、python 等,其他語言以庫的形式提供協程功能,比如 C++20 之前騰訊的 fiber 和 libco 等等
Linux 線程資源消耗分析
大腦 && 流水線 && 分工
上下文切換可以類比于人腦的工作方式。工作中不斷切換工作內容與場景一般非常累且效率低下(這是流水線發明的初衷也是勞動分工要解決的問題),但在同一個場景下有關聯的幾個子任務之間相互切換并不耗神,這與線程和協程的切換非常相似
人腦支持異步處理,我們的饑餓感可以認為是系統中斷;我們的生物鐘可以認為是類似于定時器一樣的后臺硬件;我們的感情、知識、意識都在潛移默化中慢慢發生變化,這說明大腦也有“后臺任務”
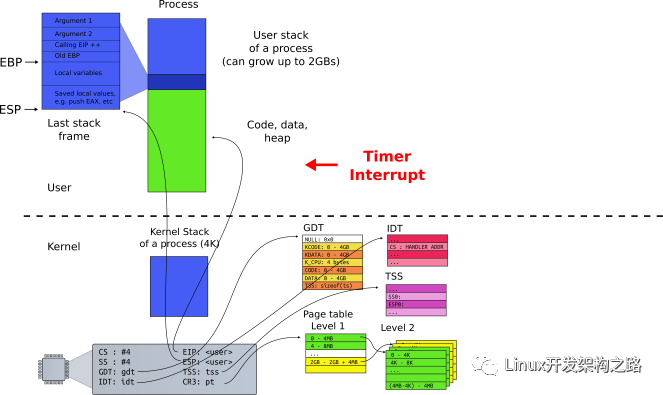
進程、線程上下文切換
下圖展示了進程/線程在運行過程 CPU 需要的一些信息(CPU Context,CPU 上下文),比如通用寄存器、棧信息(EBP/ESP)等。進程/線程切換時需要保存與恢復這些信息
進程/內核態線程切換的時候需要與 OS 內核進行交互,保存/讀取 CPU 上下文信息。內核態(Kernel)的一些數據是共享的,讀寫時需要同步機制,所以操作一旦陷入內核態就會消耗更多的時間
進程需要與操作系統中所有其他進程進行資源爭搶,且操作系統中資源的鎖是全局的;線程之間的數據一般在進程內共享,所以線程間資源共享相比如進程而言要輕一些。雖然很多操作系統(比如 Linux)進程與線程區別不是非常明顯,但線程還是比進程要輕
Linux 線程切換耗時分析
線程的切換(Context Switch)相比于其他操作而言并不是非常耗時,如下圖所示(2018 年):

Linux 2.6 之后 Linux 多線程的性能提高了很多,大部分場景下線程切換耗時在 2us 左右。下面是 Linux 下線程切換耗時統計(2013 年)
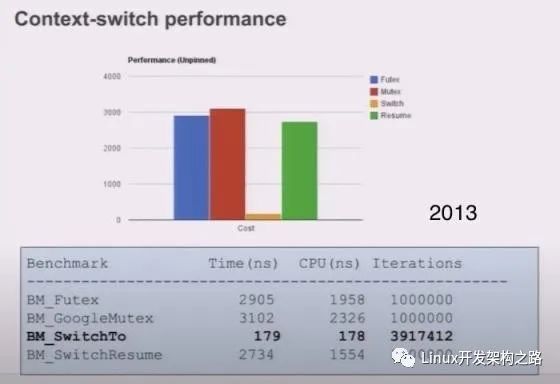
正常情況下線程有用的 CPU 時間片都在數十毫秒級別,線程切換占總耗時的千分之幾以內。協程的使用可以將這個損耗進一步降低(主要是去除了其他操作,比如 futex 等)
雖然線程切換對于常見業務而言并不重要,但不是所有語言或者系統都支持一次創建很多線程。32 位系統即使使用了虛內存空間,因為進程能訪問的虛內存空間大概是 3GB,所以單進程最多創建 300 多條線程(假設系統為每條線程分配 10M 棧空間)。太多線程也有線程切換觸發了缺頁中斷的風險
創建很多線程(比如 64 位系統下創建 1 萬條線程),不考慮優先級且假設 CPU 有 10 個核心,那么每個線程每秒有 1ms 的時間片,整個業務的耗時大概是 (n-1) * 1 + n * 0.001(n?1)?1+n?0.001 秒(n 是線程在處理業務的過程中被調度的次數),如果大量線程之間存在資源競爭,那么系統行為將難以預測。所以在有限的資源下創建大量線程是不合理的,服務線程的個數和 CPU 核心數應該在一個合理的比例內。

內存資源占用
默認情況下 Linux 系統給每條線程分配的棧空間最大是 6~8MB,這個大小是上限,也是虛內存空間,并不是每條線程真實的棧使用情況。線程真實棧內存使用會隨著線程執行而變化,如果線程只使用了少量局部變量,那么真實線程棧可能只有幾十個字節的大小。系統在維護線程時需要分配額外的空間,所以線程數的增加還是會提高內存資源的消耗
總結
如果線程之間沒有競爭關系、線程占用的內存資源較少且對延時不是非常敏感或者說線程創建不頻繁(數分鐘創建一次),那么直接在使用的時候創建新的線程(std::thread+detach/std::async)也是不錯的選擇
如果業務處理時間遠小于 IO 耗時,線程切換非常頻繁,那么使用協程是不錯的選擇
協程的優勢并不僅僅是減少線程之間切換,從編程的角度來看,協程的引入簡化了異步編程。協程為一些異步編程提供了無鎖的解決方案,這些將在下文進行介紹
線程與異步編程
同步與異步

同步與異步的區別是順序與并行,同步編程意味著只有前置操作執行完成才能執行后續流程,如上圖 AB 和 CD;異步說明二者可以同時執行,如上圖中的 AC(這里不區分并發、并行的區別)
常見異步編程方式
C++11 async && future

async 與 future 相關知識可參考其他文章,這里不做詳細介紹。術語 future(期貨)&& promise(承諾) 源自金融領域
下面代碼使用多線程實現數據的累加。線程的創建/調度與其他操作會造成了一些消耗,所以少量數據不建議使用多線程
int64_t multi_thread_acc(const std::vector< int >& data) {
if (data.size() < ELEM_NUM_MULTI_TH_LIMIT) { // 少于一定數量的累加直接使用單線程會更好
return std::accumulate(data.begin(), data.end(), int64_t(0));
} else {
auto step = data.size() / USED_CORE_NUM; // or std::hardware_currency
std::vector< std::future< int64_t >> ret_vec;
ret_vec.reserve(USED_CORE_NUM);
for (int i = 0; i < USED_CORE_NUM; i++) {
auto lhs_it = data.begin() + i * step;
auto rhs_it = (i == USED_CORE_NUM - 1) ? data.end() : lhs_it + step;
ret_vec.emplace_back(
// 持續創建少量線程并不會給系統造成太大的壓力
std::async([lhs_it, rhs_it] {
return std::accumulate(lhs_it, rhs_it, int64_t(0));
}));
}
int64_t ret = 0;
// 阻塞調用
for (auto& fu : ret_vec) {
ret += fu.get();
}
return ret;
}
}
從上面的代碼中可以看出,常規的異步編程手段還是需要一個同步的過程來搜集異步線程的執行結果
Reactor/Proactor
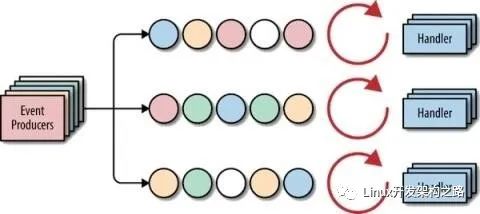
網絡編程的發展與模式大概有下面幾種:
- 每個請求一個線程/進程,阻塞式 IO
- 阻塞式 IO,線程池
- 非阻塞式 IO && IO 復用,類似于 Reactor
- Leader/Folloer 等模式
Reactor 編程模式是事件驅動的,并以回調(handle)的方式完成具體業務,Reactor 有幾個基本概念
- nonblockingIO+IOmultiplexing,請參考 epoll
- Event loop,一個監控事件源(epoll fd)的“死循環”
// ... 前置設置略
while(true) { // event loop
nfds = epoll_wait(epollFd, events, MAX_EVENTS, -1);
if(nfds == -1){
printf("epoll_wait failedn");
exit(EXIT_FAILURE);
}
for(int i = 0; i < nfds; i++){
if(events[i].data.fd == listenFd){
connectFd = accept(listenFd, (sockaddr*)NULL, NULL);
printf("Connected ...n");
pthread_t thread;
// 使用線程池可以減少系統消耗
pthread_create(&thread, NULL, handleConnection, (void *) &connectFd);
}
else {
if() // readable
if() // writeable
}
}
}
優點與缺點
優點:
- 線程數目基本固定,可以在程序啟動的時候設置,不會頻繁創建與銷毀
- 可以很方便地在線程間調配負載
- IO 事件發生的線程是固定的,同一個 TCP 連接不必考慮事件并發
缺點:
基于事件的模型有個非常明顯的缺陷,回調函數(handle)不能阻塞(非搶占式調度),否則線程或者進程有耗盡的風險,即使不耗盡,也會給系統帶來負擔。參考上文的介紹,創建大量進程/線程是不合理的
響應式編程(基于回調)
響應式編程( Reactive Programming)主要關注的是數據流的變換和流轉,因此它更注描述數據輸入和輸出之間 的關系。輸入和輸出之間用函數變換來連接,函數之間也只對輸入輸出負責,因此我們可以很輕松地通過將這些 函數調用分發到其他線程上的方法來實現異步
響應式編程中的邏輯單元也不能阻塞,否則也有耗盡工作線程的風險;非阻塞式 handle 又有陷入回調地獄的風險
回調地獄
大部分異步編程框架都是基于回調的,當一個業務需要多個步驟時回調函數會分布在不同的執行單元中,這對代碼的維護與理解造成了壓力。當執行鏈條非常長時回調鏈路也會很深
基于事件與回調的編碼風格將業務割裂到不同的 handle 函數中,理解與維護起來比較麻煩
Coroutine
通過上面的敘述,在資源有限的前提下,高性能服務需要解決的問題如下:
- 減少線程的重復高頻創建
- 常規解決辦法:線程池
- 盡量避免線程的阻塞
- Reactor && 非阻塞回調,解決問題的能力有限
- 響應式編程,容易陷入回調地獄,割裂業務邏輯
- 其他方法,例如協程
- 提升代碼的可維護與可理解性,盡量避免回調地獄
- 少使用回調函數,減少回調鏈深度
使用協程可以解決上面 2/3 兩個問題。協程可以用同步編程的方式實現異步編程才能實現的功能
協程與狀態機
A computer is a state machine. Threads are for people who can’t program state machines ——Alan Cox
無棧協程是對計算機是狀態機的實踐
協程的原理
協程的切換和線程進程的切換機制是相似的(CPU 上下文與棧信息的保存與恢復),協程在切換出去的時候需要保存當前的運行狀態,比如 CPU 寄存器、棧信息等等
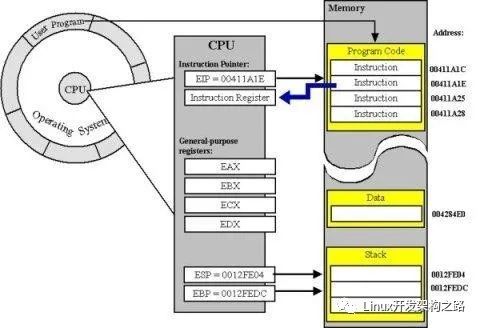
Stackless && Stackful
有棧協程與無棧協程是協程的兩種實現方式,這里的棧是“邏輯棧”,不是內存棧
比如協程 A 調用了協程 B,如果只有 B 完成之后才能調用 A 那么這個協程就是 Stackful,此時 A/B 是非對稱協程;如果 A/B 被調用的概率相同那么這個協程就是 Stackless,此時 A/B 是對稱協程
下面主要介紹無棧協程的實現方法,如果對有棧協程有興趣,可以看 libco 等庫等實現。C++20 引入的是無棧協程
使用 setjmp/longjmp 實現的簡單協程
下面代碼模擬了單線程并發執行兩個 while(true){...} 函數,細節可以查看原始 文檔 和 代碼
setjmp/longjmp 不能作為協程實現的底層機制,因為 setjmp/longjmp 對棧信息的支持有限
int max_iteration = 9;
int iter;
jmp_buf Main;
jmp_buf PointPing;
jmp_buf PointPong;
void Ping(void);
void Pong(void);
int main(int argc, char* argv[]) {
iter = 1;
if (setjmp(Main) == 0) Ping();
if (setjmp(Main) == 0) Pong();
longjmp(PointPing, 1);
}
void Ping(void) {
if (setjmp(PointPing) == 0) longjmp(Main, 1); // 可以理解為重置,reset the world
while (1) {
printf("%3d : Ping-", iter);
if (setjmp(PointPing) == 0) longjmp(PointPong, 1);
}
}
void Pong(void) {
if (setjmp(PointPong) == 0) longjmp(Main, 1);
while (1) {
printf("Pongn");
iter++;
if (iter > max_iteration) exit(0);
if (setjmp(PointPong) == 0) longjmp(PointPing, 1);
}
}
通過命令 gcc test.c 編譯后執行 ./a.out 7 ,輸出如下:
1 : Ping-Pong
2 : Ping-Pong
3 : Ping-Pong
4 : Ping-Pong
5 : Ping-Pong
6 : Ping-Pong
7 : Ping-Pong
協程的特點
- 協程可以自動讓出 CPU 時間片。注意,不是當前線程讓出 CPU 時間片,而是線程內的某個協程讓出時間片供同線程內其他協程運行
- 協程可以恢復 CPU 上下文。當另一個協程繼續執行時,其需要恢復 CPU 上下文環境
- 協程有個管理者,管理者可以選擇一個協程來運行,其他協程要么阻塞,要么 ready,或者 died
- 運行中的協程將占有當前線程的所有計算資源
- 協程天生有棧屬性,而且是 lock free
其他協程庫
ucontext,CPU 上下文管理
下面關于 ucontext 的介紹源自:
http://pubs.opengroup.org/onlinepubs/7908799/xsh/ucontext.h.html 。ucontext lib 已經不推薦使用了,但依舊是不錯的協程入門資料。其他底層協程庫實現可以查看 Boost.Context / tbox 等,協程庫的對比可以參考:https://github.com/tboox/benchbox/wiki/switch
linux 系統一般都有 ucontext 這個 c 語言庫,這個庫主要用于操控當前線程下的 CPU 上下文。和 setjmp/longjmp 不同,ucontext 直接提供了設置函數運行時棧的方式(makecontext),避免不同函數棧空間的重疊
ucontext 只操作與當前線程相關的 CPU 上下文,所以下文中涉及 ucontext 的上下文均指當前線程的上下文。一般 CPU 有多個核心,一個線程在某一時刻只能使用其中一個,所以 ucontext 只涉及一個與當前線程相關的 CPU 核心
ucontext.h 頭文件中定義了 ucontext_t 這個結構體,這個結構體中至少包含以下成員:
ucontext_t *uc_link // next context
sigset_t uc_sigmask // 阻塞信號阻塞
stack_t uc_stack // 當前上下文所使用的棧
mcontext_t uc_mcontext // 實際保存 CPU 上下文的變量,這個變量與平臺&機器相關,最好不要訪問這個變量
同時,ucontext.h 頭文件中定義了四個函數,下面分別介紹:
int getcontext(ucontext_t *); // 獲得當前 CPU 上下文
int setcontext(const ucontext_t *);// 重置當前 CPU 上下文
void makecontext(ucontext_t *, (void *)(), int, ...); // 修改上下文信息,比如設置棧指針
int swapcontext(ucontext_t *, const ucontext_t *);
getcontext & setcontext
#include < ucontext.h >
int getcontext(ucontext_t *ucp);
int setcontext(ucontext_t *ucp);
getcontext 函數使用當前 CPU 上下文初始化 ucp 所指向的結構體,初始化的內容包括 CPU 寄存器、信號 mask 和當前線程所使用的棧空間
返回值:getcontext 成功返回 0,失敗返回 -1。注意,如果 setcontext 執行成功,那么調用 setcontext 的函數將不會返回,因為當前 CPU 的上下文已經交給其他函數或者過程了,當前函數完全放棄了 對 CPU 的“所有權”
應用:當信號處理函數需要執行的時候,當前線程的上下文需要保存起來,隨后進入信號處理階段。可移植的程序最好不要讀取與修改 ucontext_t 中的 uc_mcontext,因為不同平臺下 uc_mcontext 的實現是不同的
makecontext & swapcontext
#include < ucontext.h >
void makecontext(ucontext_t *ucp, (void *func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);
makecontext 修改由 getcontext 創建的上下文 ucp。如果 ucp 指向的上下文由 swapcontext 或 setcontext 恢復,那么當前線程將執行傳遞給 makecontext 的函數 func(...)
執行 makecontext 后需要為新上下文分配一個棧空間,如果不創建,那么新函數func執行時會使用舊上下文的棧,而這個棧可能已經不存在了。argc 必須和 func 中整型參數的個數相等。
swapcontext 將當前上下文信息保存到 oucp 中并使用 ucp 重置 CPU 上下文
返回值:swapcontext 成功則返回 0,失敗返回 -1 并置 errno。如果 ucp 所指向的上下文沒有足夠的棧空間以執行余下的過程,swapcontext 將返回 -1
進一步學習
有很多協程庫的實現是基于 ucontext 的,我們可以在學習這些庫的時候順便學習一下 ucontext 庫的使用方法
coroutine,簡單的 C 協程庫
coroutine 是基于 ucontext 的一個 C 語言協程庫實現。包含示例代碼在內,全部代碼行數不超過 300 行,Mac&&Linux 可以直接編譯運行
下面是一段示例代碼:
#include < stdio.h >
#include "coroutine.h"
struct args { int n; };
static void foo(struct schedule* S, void* ud) {
struct args* arg = ud;
int start = arg- >n;
int i;
for (i = 0; i < 5; i++) {
printf("coroutine %d : %dn", coroutine_running(S), start + i);
coroutine_yield(S);
}
}
int main() {
struct schedule* S = coroutine_open(); // 創建協程管理對象
struct args arg1 = {0};
struct args arg2 = {100};
int co1 = coroutine_new(S, foo, &arg1); // 注冊協程函數
int co2 = coroutine_new(S, foo, &arg2);
printf("main startn");
while (coroutine_status(S, co1) || coroutine_status(S, co2)) {
coroutine_resume(S, co1); // 執行協程
coroutine_resume(S, co2);
}
printf("main endn");
coroutine_close(S);
return 0;
}
fiber/libco 等
協程常用于異步編程,libco 等庫利用協程劫持并封裝了底層網絡 IO 相關的函數,以同步編程的方式實現了網絡事件的異步處理
具體細節請參考其他資料,本文不展開介紹
N:1 && N:M 協程
和線程綁定的協程只有在對應線程運行的時候才有被執行的可能,如果對應線程中的某一個協程完全占有了當前線程,那么當前線程中的其他所有協程都不會被執行
協程的所有信息都保存在上下文(Contex)對象中,將不同上下文分發給不同的線程就可以實現協程的跨線程執行,如此,協程被阻塞的概率將減小
借用 BRPC 中對 N:M 協程的介紹,來解釋下什么是 N:M 協程
我們常說的協程特指 N:1 線程庫,即所有的協程運行于一個系統線程中,計算能力和各類 eventloop 庫等價。由于不跨線程,協程之間的切換不需要系統調用,可以非常快(100ns-200ns),受 cache 一致性的影響也小。但代價是協程無法高效地利用多核,代碼必須非阻塞,否則所有的協程都被卡住…… bthread 是一個 M:N 線程庫,一個 bthread 被卡住不會影響其他 bthread。關鍵技術兩點:work stealing 調度和 butex,前者讓 bthread 更快地被調度到更多的核心上,后者讓 bthread 和 pthread 可以相互等待和喚醒。這兩點協程都不需要。更多線程的知識查看這里
總結
協程的組成
通過上面的描述,N:M 模式下的協程其實就是可用戶確定調度順序的用戶態線程。與系統級線程對照可以將協程框架分為以下幾個模塊
- 協程上下文,對應操作系統中的 PCB/TCB(Process/Thread Control Block)
- 保存協程上下文的容器,對應操作系統中保存 PCB/TCB 的容器,一般是一個列表。協程上下文容器可以使用一個也可以使用多個,比如普通協程隊列、定時的協程優先隊列等
- 協程的執行器
- 協程的調度器,對應操作系統中的進程/線程調度器
- 執行協程的 worker 線程,對應實際線程/進程所使用的 CPU 核心
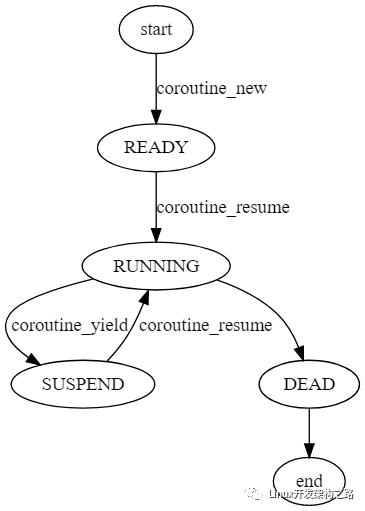
協程的調度
協程的調度與 OS 線程調度十分相似,如下圖協程調度示例所示
協程工具
系統級線程有鎖(mutex)、條件變量(condition)等工具,協程也有對應的工具。比如 libgo 提供了協程之間使用的鎖 Co_mutex/Co_rwmutex 。不同協程框架對工具的支持程度不同,實現方式也不盡相同,本文不做深入介紹
系統級線程和協程處于不同的系統層級,所以兩者的同步工具不完全通用,如果在協程中使用了線程的鎖(例如:std::mutex),則整個線程將會被阻塞,當前線程將不會再調度與執行其他協程
協程 vs 線程
- 調度方式
- 協程由編程者控制,協程之間可以有優先級;線程由系統控制,一般沒有優先級
- 調度速度
- 協程幾乎比線程快一個數量級。協程調用由編碼者控制,可以減少無效的調度
- 資源占用
- 協程可以控制內存占用量,靈活性更好;線程由系統控制
- 創建數量
- 協程的使用更靈活(有優先級控制、資源使用可控),調度速度更快,相比于線程而言調度損耗更小,所以真實可創建且有效的協程數量可以比線程多很多,這是使用協程實現異步編程的重要基礎。同樣因為調度與資源的限制,有效協程的數量也是有上限的
協程與異步
C++20 只引入了協程需要的底層支持,所以直接使用相對比較難,不過很多庫已經提供了封裝,比如 ASIO 和 cppcoro 。C++20 協程的性能還是非常高的,等 C++23 提供簡化后的 lib,就可以方便使用協程了
編譯協程相關代碼需要 g++10 或者更高版本(clang++12 對協程支持有限)
- Mac,brew install gcc@10
- Ubuntu,apt install gcc-10 / apt install g++-10
將協程的使用做了封裝,大部分情況下我們都不會和底層協程工具打交到,代碼的編寫風格和常規的同步編碼風格相同
協程對 CPU/IO 的影響
協程的目的在于剔除線程的阻塞,盡可能提高 CPU 的利用率
很多服務在處理業務時需要請求第三方服務,向第三方服務發起 RPC 調用。RPC 調用的網絡耗時一般耗時在毫秒級別,RPC 服務的處理耗時也可能在毫秒級別,如果當前服務使用同步調用,即 RPC 返回后才進行后續邏輯,那么一條線程每秒處理的業務數量是可以估算的
假設每次業務處理花費在 RPC 調用上的耗時是 20ms,那么一條線程一秒最多處理 50 次請求。如果在等待 RPC 返回時當前線程沒有被系統調度轉換為 Ready 狀態,那當前 CPU 核心就會空轉,浪費了 CPU 資源。通過增加線程數量提高系統吞吐量的效果非常有限,而且創建大量線程也會造成其他問題
協程雖然不一定能減少一次業務請求的耗時,但一定可以提升系統的吞吐量:
- 當前業務只有一次第三方 RPC 的調用,那么協程不會減少業務處理的耗時,但可以提升 QPS
- 當前業務需要多個第三方 RPC 調用,同時創建多個協程可以讓多個 RPC 調用一起執行,則當前業務的 RPC 耗時由耗時最長的 RPC 調用決定
ASIO C++ 網絡編程(同步/異步/協程)
ASIO 是一個跨平臺的 C++ 網絡庫,有非常大的可能進入 C++ 標準庫。ASIO 不僅僅提供了網絡功能(TCP/UDP/ICMP 等)也提供了很多編程工具,比如串口、定時器等。ASIO 可以脫離 Boost 編譯,且只需要[頭文件](
https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/),使用起來很方便。下面的代碼均基于 [ASIO 1.19.2](https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/)
阻塞型網絡服務(Echo)
參考代碼:blocking_tcp_echo_server ,每個請求一個線程。海量請求對系統而言負擔比較重
// g++-10 -I. echo_server.cpp
void session(tcp::socket sock) {
// 同步讀寫操作,下面代碼忽略了錯誤處理邏輯
for (;;) {
size_t length = sock.read_some(asio::buffer(data), error);
asio::write(sock, asio::buffer(data, length));
}
}
void server(asio::io_context& io_context, unsigned short port) {
tcp::acceptor a(io_context, tcp::endpoint(tcp::v4(), port));
// 注意這里的 a.accept() 是阻塞型操作,accept 返回后才會創建線程
for (;;) std::thread(session, a.accept()).detach();
}
int main(int argc, char* argv[]) {
asio::io_context io_context;
server(io_context, std::atoi(argv[1]));
return 0;
}
非阻塞型 Echo
參考代碼:async_tcp_echo_server ,基于事件與回調。所有回調函數中都有對其他接口的調用(比如 do_read 中調用了 do_write),業務邏輯被割裂在不同的回調中
// g++-10 -I. echo_server.cpp
class session : public std::enable_shared_from_this< session > {
public:
session(tcp::socket socket) : socket_(std::move(socket)) {}
void start() { do_read(); }
private:
void do_read() {
auto self(shared_from_this());
socket_.async_read_some(asio::buffer(data_, max_length),
[this, self](...) { if (!ec) do_write(length);});
}
void do_write(std::size_t length) {
auto self(shared_from_this());
asio::async_write(socket_, asio::buffer(data_, length),
[this, self](...) { if (!ec) do_read(); });
}
tcp::socket socket_;
enum { max_length = 1024 };
char data_[max_length];
};
class server {
public:
server(asio::io_context& io_context, short port)
: acceptor_(io_context, tcp::endpoint(tcp::v4(), port)) { do_accept(); }
private:
void do_accept() {
acceptor_.async_accept([this](std::error_code ec, tcp::socket socket) {
if (!ec) std::make_shared< session >(std::move(socket))- >start();
do_accept();
});
}
tcp::acceptor acceptor_;
};
int main(int argc, char* argv[]) {
asio::io_context io_context;
server s(io_context, std::atoi(argv[1]));
io_context.run();
return 0;
}
協程版 Echo
ASIO 1.19.2 已經支持 C++20 的協程,作者 github 倉庫中已經包含了協程的使用示例(coroutines_ts),下面是其中 echo_server 的示例,使用支持 C++20 標準的編譯器可直接編譯運行
// g++-10 -fcoroutines -std=c++20 -I. echo_server.cpp
awaitable< void > echo(tcp::socket socket) {
try {
char data[1024];
size_t n = 0;
for (;;) {
n = co_await socket.async_read_some(asio::buffer(data), use_awaitable);
co_await async_write(socket, asio::buffer(data, n), use_awaitable);
}
} catch (std::exception& e) { ... }
}
awaitable< void > listener() {
auto executor = co_await this_coro::executor;
tcp::acceptor acceptor(executor, {tcp::v4(), 55555});
for (;;) {
tcp::socket socket = co_await acceptor.async_accept(use_awaitable);
co_spawn(executor, echo(std::move(socket)), detached);
}
}
int main() {
asio::io_context io_context(1);
asio::signal_set signals(io_context, SIGINT, SIGTERM);
signals.async_wait([&](auto, auto) { io_context.stop(); });
co_spawn(io_context, listener(), detached);
io_context.run();
return 0;
}
-
Linux
+關注
關注
87文章
11232瀏覽量
208949 -
編程
+關注
關注
88文章
3596瀏覽量
93609 -
函數
+關注
關注
3文章
4308瀏覽量
62444 -
線程
+關注
關注
0文章
504瀏覽量
19653
發布評論請先 登錄
相關推薦

異步程序到底是什么
如何使用多線程和異步操作等并發設計方法來最大化程序的性能
linux多線程編程課件

單線程也能開發異步任務?ACE JS框架到底是如何做到的





 工商網監
工商網監
評論