") 16個(gè)OpenCV函數(shù)開始你的計(jì)算機(jī)視覺之旅
16個(gè)OpenCV函數(shù)開始你的計(jì)算機(jī)視覺之旅
計(jì)算機(jī)視覺是當(dāng)前行業(yè)中比較熱門的領(lǐng)域之一。由于技術(shù)和研究的飛速發(fā)展,它正在蓬勃發(fā)展。但這對于新來者來說仍是個(gè)艱巨的任務(wù)。XR開發(fā)者或數(shù)據(jù)科學(xué)家在過渡到計(jì)算機(jī)視覺時(shí)面臨著一些常見的挑戰(zhàn),包括:
1.我們?nèi)绾吻謇韴D像數(shù)據(jù)集?圖像有不同的形狀和大小
2.數(shù)據(jù)獲取中一直存在的問題。在建立計(jì)算機(jī)視覺模型之前,我們應(yīng)該收集更多圖像嗎?
3.學(xué)習(xí)深度學(xué)習(xí)對建立計(jì)算機(jī)視覺模型是否必不可少?我們可以不使用機(jī)器學(xué)習(xí)技術(shù)嗎?
4.我們可以在自己的機(jī)器上建立計(jì)算機(jī)vsiion模型嗎?并非每個(gè)人都可以使用GPU和TPU!

什么是CV
在進(jìn)入OpenCV之前,讓我快速解釋一下什么是計(jì)算機(jī)視覺。對本文其余部分將要討論的內(nèi)容有一個(gè)直觀的了解。人類能夠自然地看到和感知世界。通過視覺和感知的天賦從周圍環(huán)境收集信息是我們的第二天性。
快速瀏覽上圖。我們花了不到一秒鐘的時(shí)間發(fā)現(xiàn)其中有一只貓,一條狗和一條人的腿。對于機(jī)器,這種學(xué)習(xí)過程變得很復(fù)雜。解析圖像和檢測對象的過程涉及多個(gè)復(fù)雜步驟,包括特征提取(邊緣檢測,形狀等),特征分類等。
計(jì)算機(jī)視覺是當(dāng)前行業(yè)中最熱門的領(lǐng)域之一。可以預(yù)計(jì),未來2-4年將會(huì)有大量的職位空缺。那么問題是你準(zhǔn)備好利用這些機(jī)會(huì)了嗎?請花點(diǎn)時(shí)間考慮一下–當(dāng)你想到計(jì)算機(jī)視覺時(shí),會(huì)想到哪些應(yīng)用程序或產(chǎn)品?我們每天都使用其中一些,使用面部識別功能解鎖手機(jī),智能手機(jī)攝像頭,自動(dòng)駕駛汽車等功能,無處不在。
關(guān)于OpenCV
OpenCV庫最初是英特爾的一項(xiàng)研究項(xiàng)目。就其擁有的功能而言,它是目前最大的計(jì)算機(jī)視覺庫。OpenCV包含2500多種算法的實(shí)現(xiàn)!它可免費(fèi)用于商業(yè)和學(xué)術(shù)目的。該庫具有適用于多種語言的接口,包括Python,Java和C ++。
OpenCV的第一個(gè)版本1.0于2006年發(fā)布,此后OpenCV社區(qū)發(fā)展迅猛。
現(xiàn)在,讓我們將注意力轉(zhuǎn)移到本文背后的思想上-OpenCV提供的眾多功能!我們將從數(shù)據(jù)科學(xué)家的角度研究OpenCV,并了解一些使開發(fā)和理解計(jì)算機(jī)視覺模型的任務(wù)變得更加容易的功能。
讀取,寫入和顯示圖像
機(jī)器使用數(shù)字來查看和處理一切,包括圖像和文本。你如何把圖像轉(zhuǎn)換成數(shù)字?沒錯(cuò),像素!
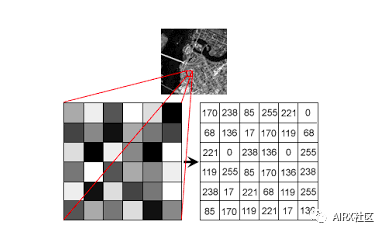
每個(gè)數(shù)字表示該特定位置的像素強(qiáng)度。在上面的圖像中,我展示了灰度圖像的像素值,其中每個(gè)像素只包含一個(gè)值,即該位置的黑色強(qiáng)度。
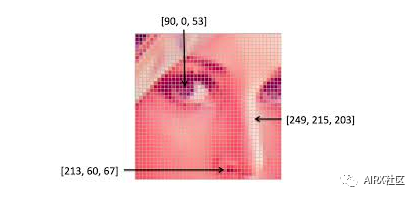
注意,彩色圖像對于單個(gè)像素有多個(gè)值。這些值表示各自通道的強(qiáng)度——例如,RGB圖像的紅色、綠色和藍(lán)色通道。
讀和寫圖像是必不可少的任何計(jì)算機(jī)視覺項(xiàng)目。OpenCV庫使這個(gè)函數(shù)變得非常簡單。
#import the libraries
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlibinline
#readingtheimage
image = cv2.imread('index.png')
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
#plotting the image
plt.imshow(image)
#saving image
cv2.imwrite('test_write.jpg',image)

默認(rèn)情況下,imread函數(shù)以BGR(藍(lán)綠色紅色)格式讀取圖像。我們可以使用imread函數(shù)中的額外標(biāo)志來讀取不同格式的圖像:
-
cv2.IMREAD_COLOR: 加載彩色圖像的默認(rèn)標(biāo)志
-
cv2.IMREAD_GRAYSCALE: 以灰度格式加載圖像
-
cv2.IMREAD_UNCHANGED: 以給定格式(包括Alpha通道)加載圖像。Alpha通道存儲透明度信息,Alpha通道的值越高,像素越不透明。
改變色彩空間
顏色空間是一種協(xié)議,用于以一種使顏色易于復(fù)制的方式表示顏色。我們知道灰度圖像有單個(gè)像素值,而彩色圖像每個(gè)像素包含3個(gè)值——紅、綠、藍(lán)通道的強(qiáng)度。
大多數(shù)計(jì)算機(jī)視覺用例處理RGB格式的圖像。然而,像視頻壓縮和設(shè)備獨(dú)立存儲這樣的應(yīng)用程序嚴(yán)重依賴于其他顏色空間,比如顏色-飽和度-值或HSV顏色空間。
正如你所理解的,RGB圖像是由不同顏色通道的顏色強(qiáng)度組成的,即強(qiáng)度和顏色信息混合在RGB顏色空間中,而在HSV顏色空間中,顏色和強(qiáng)度信息是相互分離的。這使得HSV顏色空間對光線變化更加健壯。OpenCV默認(rèn)以BGR格式讀取給定的圖像。因此,在使用OpenCV讀取圖像時(shí),需要將圖像的顏色空間從BGR更改為RGB。讓我們看看怎么做:
#import the required libraries
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
image = cv2.imread('index.jpg')
#converting image to Gray scale
gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#plotting the grayscale image
plt.imshow(gray_image)
#converting image to HSV format
hsv_image = cv2.cvtColor(image,cv2.COLOR_BGR2HSV)
#plotting the HSV image
plt.imshow(hsv_image)
調(diào)整圖像大小
機(jī)器學(xué)習(xí)模型在固定大小的輸入下工作。同樣的想法也適用于計(jì)算機(jī)視覺模型。我們用于訓(xùn)練模型的圖像必須具有相同的尺寸。
現(xiàn)在,如果我們通過從各種來源抓取圖像來創(chuàng)建自己的數(shù)據(jù)集,這可能會(huì)成為問題。這就是調(diào)整圖像大小的功能。
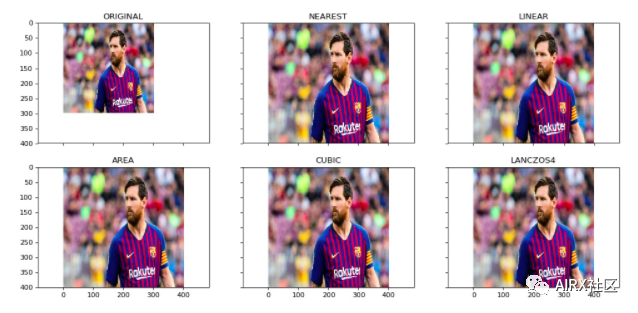
使用OpenCV可以輕松地放大和縮小圖像。當(dāng)我們需要將圖像轉(zhuǎn)換為模型的輸入形狀時(shí),此操作對于訓(xùn)練深度學(xué)習(xí)模型很有用。OpenCV支持不同的插值和下采樣方法,這些參數(shù)可以由以下參數(shù)使用:
1.INTER_NEAREST: 最近鄰居插值
2.INTER_LINEAR: 雙線性插值
3.INTER_AREA: 使用像素面積關(guān)系進(jìn)行重采樣
4.INTER_CUBIC: 在4×4像素鄰域上的雙三次插值
5.INTER_LANCZOS4:在8×8鄰域內(nèi)進(jìn)行Lanczos插值
OpenCV的調(diào)整大小功能默認(rèn)情況下使用雙線性插值。
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#reading the image
image = cv2.imread('index.jpg')
#converting image to size (100,100,3)
smaller_image = cv2.resize(image,(100,100),inerpolation='linear')
#plot the resized image
plt.imshow(smaller_image)
影像旋轉(zhuǎn)
“你需要大量數(shù)據(jù)來訓(xùn)練深度學(xué)習(xí)模型”。大多數(shù)深度學(xué)習(xí)算法在很大程度上取決于數(shù)據(jù)的質(zhì)量和數(shù)量。但是,如果你沒有足夠大的數(shù)據(jù)集怎么辦?并非所有人都能負(fù)擔(dān)得起手動(dòng)收集和標(biāo)記圖像的費(fèi)用。
假設(shè)我們正在建立一個(gè)圖像分類模型來識別圖像中存在的動(dòng)物。因此,下面顯示的兩個(gè)圖像都應(yīng)歸類為“狗”:

但是,如果沒有對第二幅圖像進(jìn)行訓(xùn)練,該模型可能會(huì)發(fā)現(xiàn)很難將其歸類為狗。那么我們應(yīng)該怎么做呢?
讓我來介紹一下數(shù)據(jù)擴(kuò)充技術(shù)。該方法允許我們生成更多的樣本來訓(xùn)練我們的深度學(xué)習(xí)模型。數(shù)據(jù)擴(kuò)充利用現(xiàn)有的數(shù)據(jù)樣本,通過應(yīng)用旋轉(zhuǎn)、縮放、平移等圖像操作來生成新的數(shù)據(jù)樣本。這使我們的模型對輸入的變化具有魯棒性,并導(dǎo)致更好的泛化。
旋轉(zhuǎn)是最常用和最容易實(shí)現(xiàn)的數(shù)據(jù)擴(kuò)充技術(shù)之一。顧名思義,它包括以任意角度旋轉(zhuǎn)圖像,并為其提供與原始圖像相同的標(biāo)簽。想想你在手機(jī)中旋轉(zhuǎn)圖像以達(dá)到一定角度的次數(shù)——這基本上就是這個(gè)功能的作用。
#importing the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread('index.png')
rows,cols = image.shape[:2]
#(col/2,rows/2) is the center of rotation for the image
# M is the cordinates of the center
M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1)
dst = cv2.warpAffine(image,M,(cols,rows))
plt.imshow(dst)

圖片翻譯
圖像平移是一種幾何變換,它將圖像中每個(gè)對象的位置映射到最終輸出圖像中的新位置。平移操作之后,輸入圖像中位置(x,y)處的對象將移動(dòng)到新位置(X,Y):
X = x + dx
Y = y + dy
在此,dx和dy是沿不同維度的各自平移。圖像平移可用于為模型增加平移不變性,因?yàn)橥ㄟ^翻譯,我們可以更改圖像中對象的位置,從而使模型具有更多多樣性,從而導(dǎo)致更好的泛化性。
以下面的圖片為例。即使圖像中沒有完整的鞋子,模型也應(yīng)該能夠?qū)⑵錃w類為鞋子。

此轉(zhuǎn)換功能通常在圖像預(yù)處理階段使用。查看下面的代碼,看看它在實(shí)際情況下如何工作:
#importing the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#reading the image
image = cv2.imread('index.png')
#shifting the image 100 pixels in both dimensions
M = np.float32([[1,0,-100],[0,1,-100]])
dst = cv2.warpAffine(image,M,(cols,rows))
plt.imshow(dst)

簡單圖像閾值
閾值化是一種圖像分割方法。它將像素值與閾值進(jìn)行比較,并相應(yīng)地進(jìn)行更新。OpenCV支持閾值的多種變化。可以這樣定義一個(gè)簡單的閾值函數(shù):
如果Image(x,y)> threshold,則Image(x,y)= 1
否則,Image(x,y)= 0
閾值只能應(yīng)用于灰度圖像。圖像閾值化的一個(gè)簡單應(yīng)用就是將圖像分為前景和背景。
#importing the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#here 0 means that the image is loaded in gray scale format
gray_image = cv2.imread('index.png',0)
ret,thresh_binary = cv2.threshold(gray_image,127,255,cv2.THRESH_BINARY)
ret,thresh_binary_inv = cv2.threshold(gray_image,127,255,cv2.THRESH_BINARY_INV)
ret,thresh_trunc = cv2.threshold(gray_image,127,255,cv2.THRESH_TRUNC)
ret,thresh_tozero = cv2.threshold(gray_image,127,255,cv2.THRESH_TOZERO)
ret,thresh_tozero_inv = cv2.threshold(gray_image,127,255,cv2.THRESH_TOZERO_INV)
#DISPLAYING THE DIFFERENT THRESHOLDING STYLES
names = ['Oiriginal Image','BINARY','THRESH_BINARY_INV','THRESH_TRUNC','THRESH_TOZERO','THRESH_TOZERO_INV']
images = gray_image,thresh_binary,thresh_binary_inv,thresh_trunc,thresh_tozero,thresh_tozero_inv
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(names[i])
plt.xticks([]),plt.yticks([])
plt.show()

自適應(yīng)閾值
在自適應(yīng)閾值的情況下,對于圖像的不同部分使用不同的閾值。此功能可為光照條件變化的圖像提供更好的結(jié)果,因此稱為“自適應(yīng)”。Otsu的二值化方法為整個(gè)圖像找到最佳閾值。它適用于雙峰圖像(直方圖中具有2個(gè)峰的圖像)。
#import the libraries
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
#ADAPTIVE THRESHOLDING
gray_image = cv2.imread('index.png',0)
ret,thresh_global = cv2.threshold(gray_image,127,255,cv2.THRESH_BINARY)
#here 11 is the pixel neighbourhood that is used to calculate the threshold value
thresh_mean = cv2.adaptiveThreshold(gray_image,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
thresh_gaussian = cv2.adaptiveThreshold(gray_image,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
names = ['Original Image','Global Thresholding','Adaptive Mean Threshold','Adaptive Gaussian Thresholding']
images = [gray_image,thresh_global,thresh_mean,thresh_gaussian]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(names[i])
plt.xticks([]),plt.yticks([])
plt.show()

圖像分割(分水嶺算法)
圖像分割是將圖像中的每個(gè)像素分類為某個(gè)類的任務(wù)。例如,將每個(gè)像素分類為前景或背景。圖像分割對于從圖像中提取相關(guān)部分非常重要。
分水嶺算法是一種經(jīng)典的圖像分割算法。它將圖像中的像素值視為地形。為了找到對象邊界,它以初始標(biāo)記作為輸入。然后,該算法開始從標(biāo)記中泛洪盆地,直到標(biāo)記在對象邊界處相遇。
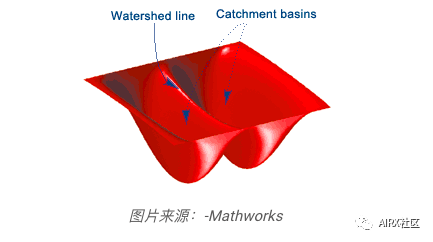
假設(shè)我們有多個(gè)盆地。現(xiàn)在,如果我們用不同顏色的水填充不同的盆地,那么不同顏色的交點(diǎn)將為我們提供對象邊界。
#importing required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
#reading the image
image = cv2.imread('coins.jpg')
#converting image to grayscale format
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#apply thresholding
ret,thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
#get a kernel
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel,iterations = 2)
#extract the background from image
sure_bg = cv2.dilate(opening,kernel,iterations = 3)
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret,sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_bg)
ret,markers = cv2.connectedComponents(sure_fg)
markers = markers+1
markers[unknown==255] = 0
markers = cv2.watershed(image,markers)
image[markers==-1] = [255,0,0]
plt.imshow(sure_fg)

換位運(yùn)算
按位運(yùn)算包括AND,OR,NOT和XOR。你可能在編程課上還記得它們!在計(jì)算機(jī)視覺中,當(dāng)我們有一個(gè)遮罩圖像并且想要將該遮罩應(yīng)用于另一個(gè)圖像以提取感興趣區(qū)域時(shí),這些操作非常有用。
#import required libraries
import numpy as np
import matplotlib.pyplot as plt
import cv2
%matplotlib inline
#read the image
image = cv2.imread('coins.jpg')
#apply thresholdin
ret,mask = cv2.threshold(sure_fg,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
#apply AND operation on image and mask generated by thrresholding
final = cv2.bitwise_and(image,image,mask = mask)
#plot the result
plt.imshow(final)

在上圖中,我們可以看到使用分水嶺算法計(jì)算的輸入圖像及其分割蒙版。此外,我們應(yīng)用了按位“與”運(yùn)算以從圖像中刪除背景并從圖像中提取相關(guān)部分。
邊緣檢測
邊緣是圖像中圖像亮度急劇變化或不連續(xù)的點(diǎn)。這種不連續(xù)通常對應(yīng)于:
-
深度不連續(xù)
-
表面取向不連續(xù)
-
材料特性的變化
-
場景照明的變化
邊緣是圖像的非常有用的功能,可以用于不同的應(yīng)用程序,例如圖像中的對象分類和定位。甚至深度學(xué)習(xí)模型也會(huì)計(jì)算邊緣特征,以提取有關(guān)圖像中存在的對象的信息。
邊緣與輪廓不同,因?yàn)樗鼈兣c對象無關(guān),而是表示圖像像素值的變化。邊緣檢測可用于圖像分割甚至圖像銳化。
#import the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#read the image
image = cv2.imread('coins.jpg')
#calculate the edges using Canny edge algorithm
edges = cv2.Canny(image,100,200)
#plot the edges
plt.imshow(edges)

圖像過濾
在圖像過濾中,使用像素的鄰近值更新像素值。但是這些值首先如何更新?
嗯,有多種更新像素值的方法,例如從鄰居中選擇最大值,使用鄰居的平均值等。每種方法都有其自己的用途。例如,將鄰域中的像素值平均用于圖像模糊。
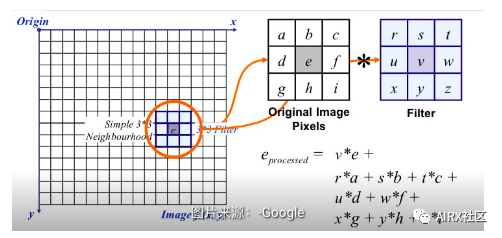
高斯濾波還用于圖像模糊,該模糊基于相鄰像素與所考慮像素的距離為它們賦予不同的權(quán)重。
對于圖像過濾,我們使用內(nèi)核。內(nèi)核是具有不同形狀的數(shù)字矩陣,例如3 x 3、5 x 5等。內(nèi)核用于計(jì)算帶有圖像一部分的點(diǎn)積。在計(jì)算像素的新值時(shí),內(nèi)核中心與像素重疊。相鄰像素值與內(nèi)核中的相應(yīng)值相乘。將計(jì)算出的值分配給與內(nèi)核中心一致的像素。
#importing the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread('index.png')
#using the averaging kernel for image smoothening
averaging_kernel = np.ones((3,3),np.float32)/9
filtered_image = cv2.filter2D(image,-1,kernel)
plt.imshow(dst)
#get a one dimensional Gaussian Kernel
gaussian_kernel_x = cv2.getGaussianKernel(5,1)
gaussian_kernel_y = cv2.getGaussianKernel(5,1)
#converting to two dimensional kernel using matrix multiplication
gaussian_kernel = gaussian_kernel_x * gaussian_kernel_y.T
#you can also use cv2.GaussianBLurring(image,(shape of kernel),standard deviation) instead of cv2.filter2D
filtered_image = cv2.filter2D(image,-1,gaussian_kernel)
plt.imshow()

在上面的輸出中,右側(cè)的圖像顯示了在輸入圖像上應(yīng)用高斯核的結(jié)果。我們可以看到原始圖像的邊緣被抑制了。具有不同sigma值的高斯核被廣泛用于計(jì)算我們圖像的高斯差。這是特征提取過程中的重要步驟,因?yàn)樗梢詼p少圖像中存在的噪點(diǎn)。
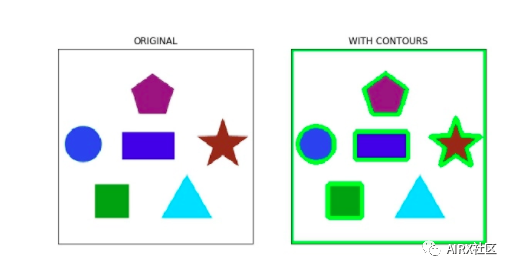
影像輪廓
輪廓是點(diǎn)或線段的閉合曲線,代表圖像中對象的邊界。輪廓實(shí)質(zhì)上是圖像中對象的形狀。
與邊緣不同,輪廓不是圖像的一部分。相反,它們是與圖像中對象形狀相對應(yīng)的點(diǎn)和線段的抽象集合。
我們可以使用輪廓來計(jì)算圖像中對象的數(shù)量,根據(jù)對象的形狀對對象進(jìn)行分類,或者從圖像中選擇特定形狀的對象。
#importing the required libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
image = cv2.imread('shapes.png')
#converting RGB image to Binary
gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(gray_image,127,255,0)
#calculate the contours from binary image
im,contours,hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
with_contours = cv2.drawContours(image,contours,-1,(0,255,0),3)
plt.imshow(with_contours)
尺度不變特征變換(SIFT)
關(guān)鍵點(diǎn)是在處理圖像時(shí)應(yīng)注意的概念。這些基本上是圖像中的關(guān)注點(diǎn)。關(guān)鍵點(diǎn)類似于給定圖像的特征。
它們是定義圖像中有趣內(nèi)容的位置。關(guān)鍵點(diǎn)很重要,因?yàn)闊o論如何修改圖像(旋轉(zhuǎn),縮小,擴(kuò)展,變形),我們始終會(huì)為圖像找到相同的關(guān)鍵點(diǎn)。
尺度不變特征變換(SIFT)是一種非常流行的關(guān)鍵點(diǎn)檢測算法。它包括以下步驟:
-
尺度空間極值檢測
-
關(guān)鍵點(diǎn)本地化
-
方向分配
-
關(guān)鍵點(diǎn)描述符
-
關(guān)鍵點(diǎn)匹配
從SIFT提取的特征可用于圖像拼接,物體檢測等應(yīng)用。以下代碼和輸出顯示了關(guān)鍵點(diǎn)及其使用SIFT計(jì)算得出的方向。
#import required libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#show OpenCV version
print(cv2.__version__)
#read the iamge and convert to grayscale
image = cv2.imread('index.png')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#create sift object
sift = cv2.xfeatures2d.SIFT_create()
#calculate keypoints and their orientation
keypoints,descriptors = sift.detectAndCompute(gray,None)
#plot keypoints on the image
with_keypoints = cv2.drawKeypoints(gray,keypoints)
#plot the image
plt.imshow(with_keypoints)

SURF
SURF是SIFT的增強(qiáng)版本。它的工作速度更快,并且對圖像轉(zhuǎn)換更健壯。在SIFT中,比例空間使用高斯的拉普拉斯算子近似。什么是高斯的拉普拉斯算子?
拉普拉斯算子是用于計(jì)算圖像邊緣的內(nèi)核。拉普拉斯核通過近似圖像的二階導(dǎo)數(shù)來工作。因此,它對噪聲非常敏感。我們通常將高斯核應(yīng)用于拉普拉斯核之前的圖像,因此將其命名為高斯拉普拉斯。
在SURF中,高斯的拉普拉斯算子是使用盒式濾波器(核)來計(jì)算的。盒式濾波器的卷積可以針對不同的比例并行進(jìn)行,這是SURF速度提高的根本原因(與SIFT相比)。
#import required libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#show OpenCV version
print(cv2.__version__)
#read image and convert to grayscale
image = cv2.imread('index.png')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#instantiate surf object
surf = cv2.xfeatures2d.SURF_create(400)
#calculate keypoints and their orientation
keypoints,descriptors = surf.detectAndCompute(gray,None)
with_keypoints = cv2.drawKeypoints(gray,keypoints)
plt.imshow(with_keypoints)

特征匹配
可以匹配使用SIFT或SURF從不同圖像中提取的特征,以找到存在于不同圖像中的相似對象/圖案。OpenCV庫支持多種功能匹配算法,例如蠻力匹配,knn特征匹配等。
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
#reading images in grayscale format
image1 = cv2.imread('messi.jpg',0)
image2 = cv2.imread('team.jpg',0)
#finding out the keypoints and their descriptors
keypoints1,descriptors1 = cv2.detectAndCompute(image1,None)
keypoints2,descriptors2 = cv2.detectAndCompute(image2,None)
#matching the descriptors from both the images
bf = cv2.BFMatcher()
matches = bf.knnMatch(ds1,ds2,k = 2)
#selecting only the good features
good_matches = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append([m])
image3 = cv2.drawMatchesKnn(image1,kp1,image2,kp2,good,flags = 2)

在上圖中,我們可以看到從原始圖像(左側(cè))提取的關(guān)鍵點(diǎn)與其旋轉(zhuǎn)版本的關(guān)鍵點(diǎn)匹配。這是因?yàn)樘卣魇鞘褂肧IFT提取的,而SIFT對于此類變換是不變的。
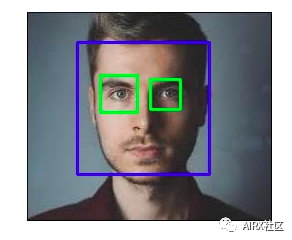
人臉檢測
OpenCV支持基于haar級聯(lián)的對象檢測。Haar級聯(lián)是基于機(jī)器學(xué)習(xí)的分類器,可計(jì)算圖像中的不同特征(如邊緣,線條等)。然后,這些分類器使用多個(gè)正樣本和負(fù)樣本進(jìn)行訓(xùn)練。
OpenCV Github存儲庫中提供了針對不同對象(如面部,眼睛等)的訓(xùn)練分類器,你還可以針對任何對象訓(xùn)練自己的haar級聯(lián)。
#import required libraries
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
%matplotlib inline
#load the classifiers downloaded
face_cascade = cv.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv.CascadeClassifier('haarcascade_eye.xml')
#read the image and convert to grayscale format
img = cv.imread('rotated_face.jpg')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
#calculate coordinates
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
for (x,y,w,h) in faces:
cv.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
#draw bounding boxes around detected features
for (ex,ey,ew,eh) in eyes:
cv.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
#plot the image
plt.imshow(img)
#write image
cv2.imwrite('face_detection.jpg',img)
-
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45928 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8378瀏覽量
132415 -
OpenCV
+關(guān)注
關(guān)注
30文章
628瀏覽量
41264
原文標(biāo)題:【建議收藏】16個(gè)OpenCV函數(shù)開始你的計(jì)算機(jī)視覺之旅
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
采用OpenCV計(jì)算機(jī)視覺庫實(shí)現(xiàn)人臉檢測系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
深度學(xué)習(xí)與傳統(tǒng)計(jì)算機(jī)視覺簡介
如何在RK3288上去安裝Opencv開源計(jì)算機(jī)視覺庫呢
【RISC-V + OpenCV 計(jì)算機(jī)視覺】用 VisionFive 2 昉·星光 2 進(jìn)行物體識別
基于OpenCV的計(jì)算機(jī)視覺技術(shù)實(shí)現(xiàn)

開放源代碼的計(jì)算機(jī)視覺類庫OpenCv的應(yīng)用
OpenCV讓計(jì)算機(jī)視覺性能更加強(qiáng)大實(shí)現(xiàn)嵌入式視覺應(yīng)用
計(jì)算機(jī)視覺應(yīng)用之OpenCV基礎(chǔ)教程
基于Vivado HLS的計(jì)算機(jī)視覺開發(fā)
計(jì)算機(jī)視覺與機(jī)器視覺區(qū)別
OpenCV跨平臺計(jì)算機(jī)視覺庫的詳細(xì)資料簡介






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論