 內存是如何泄露的
內存是如何泄露的
作為 C++ 程序員,內存泄露始終是懸在頭上的一顆炸彈。在過去幾年的 C++ 開發過程中,由于我們采用了一些技術,我們的程序發生內存泄露的情況屈指可數。今天就在這里向大家做一個簡單的介紹。
內存是如何泄露的
在 C++ 程序中,主要涉及到的內存就是『棧』和『堆』(其他部分不在本文中介紹了)。
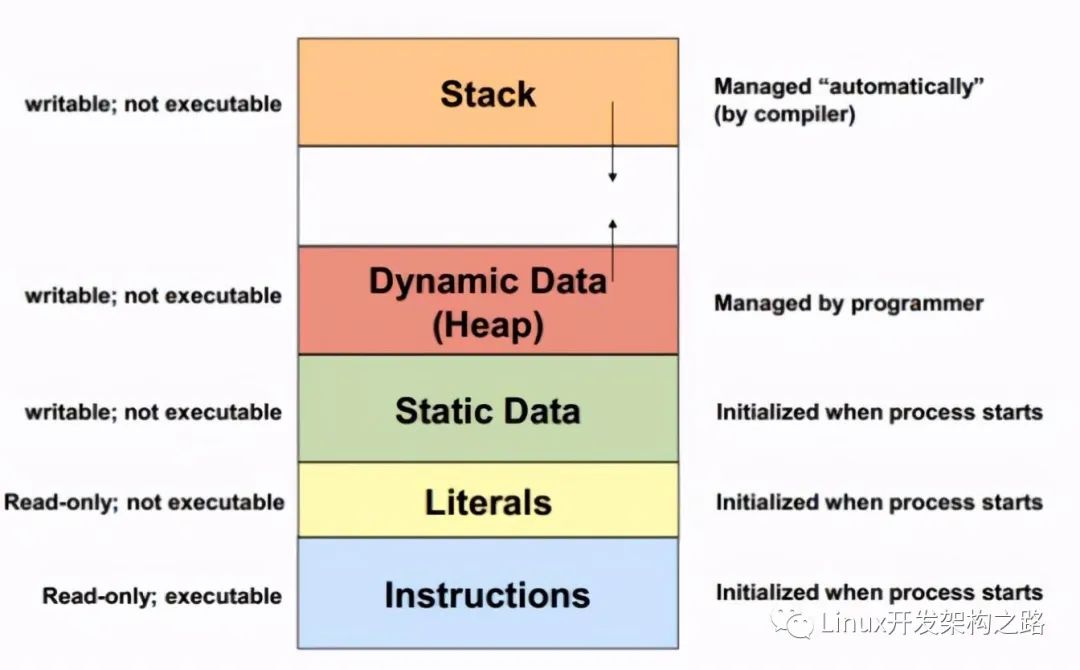
通常來說,一個線程的棧內存是有限的,通常來說是 8M 左右(取決于運行的環境)。棧上的內存通常是由編譯器來自動管理的。當在棧上分配一個新的變量時,或進入一個函數時,棧的指針會下移,相當于在棧上分配了一塊內存。我們把一個變量分配在棧上,也就是利用了棧上的內存空間。當這個變量的生命周期結束時,棧的指針會上移,相同于回收了內存。
由于棧上的內存的分配和回收都是由編譯器控制的,所以在棧上是不會發生內存泄露的,只會發生棧溢出(Stack Overflow),也就是分配的空間超過了規定的棧大小。
而堆上的內存是由程序直接控制的,程序可以通過 malloc/free 或 new/delete 來分配和回收內存,如果程序中通過 malloc/new 分配了一塊內存,但忘記使用 free/delete 來回收內存,就發生了內存泄露。
經驗 #1:盡量避免在堆上分配內存
既然只有堆上會發生內存泄露,那第一原則肯定是避免在堆上面進行內存分配,盡可能的使用棧上的內存,由編譯器進行分配和回收,這樣當然就不會有內存泄露了。
然而,只在棧上分配內存,在有 IO 的情況下是存在一定局限性的。
舉個例子,為了完成一個請求,我們通常會為這個請求構造一個 Context 對象,用于描述和這個請求有關的一些上下文。例如下面一段代碼:
void Foo(Reuqest* req) {
RequestContext ctx(req);
HandleRequest(&ctx);
}
如果 HandleRequest 是一個同步函數,當這個函數返回時,請求就可以被處理完成,那么顯然 ctx 是可以被分配在棧上的。
但如果 HandleRequest 是一個異步函數,例如:
void HandleRequest(RequestContext* ctx, Callback cb);
那么顯然,ctx 是不能被分配在棧上的,因為如果 ctx 被分配在棧上,那么當 Foo 函數推出后,ctx 對象的生命周期也就結束了。而 FooCB 中顯然會使用到 ctx 對象。
void HandleRequest(RequestContext* ctx, Callback cb);
void Foo(Reuqest* req) {
auto ctx = new RequestContext(req);
HandleRequest(ctx, FooCB);
}
void FooCB(RequestContext* ctx) {
FinishRequest(ctx);
delete ctx;
}
在這種情況下,如果忘記在 FooCB 中調用 delete ctx,則就會觸發內存泄露。盡管我們可以借助一些靜態檢查工具對代碼進行檢查,但往往異步程序的邏輯是極其復雜的,一個請求的生命周期中,也需要進行大量的內存分配操作,靜態檢查工具往往無法發現所有的內存泄露情況。
那么怎么才能避免這種情況的產生呢?引入智能指針顯然是一種可行的方法,但引入 shared_ptr 往往引入了額外的性能開銷,并不十分理想。
在 SmartX,我們通常采用兩種方法來應對這種情況。
經驗 #2:使用 Arena
Arena 是一種統一化管理內存生命周期的方法。所有需要在堆上分配的內存,不通過 malloc/new,而是通過 Arena 的 CreateObject 接口。同時,不需要手動的執行 free/delete,而是在 Arena 被銷毀的時候,統一釋放所有通過 Arena 對象申請的內存。所以,只需要確保 Arena 對象一定被銷毀就可以了,而不用再關心其他對象是否有漏掉的 free/delete。這樣顯然降低了內存管理的復雜度。
此外,我們還可以將 Arena 的生命周期與 Request 的生命周期綁定,一個 Request 生命周期內的所有內存分配都通過 Arena 完成。這樣的好處是,我們可以在構造 Arena 的時候,大概預估出處理完成這個 Request 會消耗多少內存,并提前將會使用到的內存一次性的申請完成,從而減少了在處理一個請求的過程中,分配和回收內存的次數,從而優化了性能。
我們最早看到 Arena 的思想,是在 LevelDB 的代碼中。這段代碼相當簡單,建議大家直接閱讀。
經驗 #3:使用 Coroutine
Coroutine 相信大家并不陌生,那 Coroutine 的本質是什么?我認為 Coroutine 的本質,是使得一個線程中可以存在多個上下文,并可以由用戶控制在多個上下文之間進行切換。而在上下文中,一個重要的組成部分,就是棧指針。使用 Coroutine,意味著我們在一個線程中,可以創造(或模擬)多個棧。
有了多個棧,意味著當我們要做一個異步處理時,不需要釋放當前棧上的內存,而只需要切換到另一個棧上,就可以繼續做其他的事情了,當異步處理完成時,可以再切換回到這個棧上,將這個請求處理完成。
還是以剛才的代碼為示例:
void Foo(Reuqest* req) {
RequestContext ctx(req);
HandleRequest(&ctx);
}
void HandleRequest(RequestCtx* ctx) {
SubmitAsync(ctx);
Coroutine::Self()- >Yield();
CompleteRequest(ctx);
}
這里的精髓在于,盡管 Coroutine::Self()->Yield() 被調用時,程序可以跳出 HandleRequest 函數去執行其他代碼邏輯,但當前的棧卻被保存了下來,所以 ctx 對象是安全的,并沒有被釋放。
這樣一來,我們就可以完全拋棄在堆上申請內存,只是用棧上的內存,就可以完成請求的處理,完全不用考慮內存泄露的問題。然而這種假設過于理想,由于在棧上申請內存存在一定的限制,例如棧大小的限制,以及需要在編譯是知道分配內存的大小,所以在實際場景中,我們通常會結合使用 Arena 和 Coroutine 兩種技術一起使用。
有人可能會提到,想要多個棧用多個線程不就可以了?然而用多線程實現多個棧的問題在于,線程的創建和銷毀的開銷極大,且線程間切塊,也就是在棧之間進行切換的代銷需要經過操作系統,這個開銷也是極大的。所以想用線程模擬多個棧的想法在實際場景中是走不通的。
關于 Coroutine 有很多開源的實現方式,大家可以在 github 上找到很多,C++20 標準也會包含 Coroutine 的支持。在 SmartX 內部,我們很早就實現了 Coroutine,并對所有異步 IO 操作進行了封裝,示例可參考我們之前的一篇文章 smartx:基于 Coroutine 的異步 RPC 框架示例(C++)
這里需要強調一下,Coroutine 確實會帶來一定的性能開銷,通常 Coroutine 切換的開銷在 20ns 以內,然而我們依然在對性能要求很苛刻的場景使用 Coroutine,一方面是因為 20ns 的性能開銷是相對很小的,另一方面是因為 Coroutine 極大的降低了異步編程的復雜度,降低了內存泄露的可能性,使得編寫異步程序像編寫同步程序一樣簡單,降低了程序員心智的開銷。

經驗 #4:善用 RAII
盡管在有些場景使用了 Coroutine,但還是可能會有在堆上申請內存的需要,而此時有可能 Arena 也并不適用。在這種情況下,善用 RAII(Resource Acquisition Is Initialization)思想會幫助我們解決很多問題。
簡單來說,RAII 可以幫助我們將管理堆上的內存,簡化為管理棧上的內存,從而達到利用編譯器自動解決內存回收問題的效果。此外,RAII 可以簡化的還不僅僅是內存管理,還可以簡化對資源的管理,例如 fd,鎖,引用計數等等。
當我們需要在堆上分配內存時,我們可以同時在棧上面分配一個對象,讓棧上面的對象對堆上面的對象進行封裝,用時通過在棧對象的析構函數中釋放堆內存的方式,將棧對象的生命周期和堆內存進行綁定。
unique_ptr 就是一種很典型的例子。然而 unique_ptr 管理的對象類型只能是指針,對于其他的資源,例如 fd,我們可以通過將 fd 封裝成另外一個 FileHandle 對象的方式管理,也可以采用一些更通用的方式。例如,在我們內部的 C++ 基礎庫中實現了 Defer 類,想法類似于 Go 中 defer。
void Foo() {
int fd = open();
Defer d = [=]() { close(fd); }
// do something with fd
}
經驗 #5:便于 Debug
在特定的情況下,我們難免還是要手動管理堆上的內存。然而當我們面臨一個正在發生內存泄露線上程序時,我們應該怎么處理呢?
當然不是簡單的『重啟大法好』,畢竟重啟后還是可能會產生泄露,而且最寶貴的現場也被破壞了。最佳的方式,還是利用現場進行 Debug,這就要求程序具有便于 Debug 的能力。
這里不得不提到一個經典而強大的工具 gperftools。gperftools 是 google 開源的一個工具集,包含了 tcmalloc,heap profiler,heap checker,cpu profiler 等等。gperftools 的作者之一,就是大名鼎鼎的 Sanjay Ghemawat,沒錯,就是與 Jeff Dean 齊名,并和他一起寫 MapReduce 的那個 Sanjay。
gperftools 的一些經典用法,我們就不在這里進行介紹了,大家可以自行查看文檔。而使用 gperftools 可以在不重啟程序的情況下,進行內存泄露檢查,這個恐怕是很少有人了解。
實際上我們 Release 版本的 C++ 程序可執行文件在編譯時全部都鏈接了 gperftools。在 gperftools 的 heap profiler 中,提供了 HeapProfilerStart 和 HeapProfilerStop 的接口,使得我們可以在運行時啟動和停止 heap profiler。同時,我們每個程序都暴露了 RPC 接口,用于接收控制命令和調試命令。在調試命令中,我們就增加了調用 HeapProfilerStart 和 HeapProfilerStop 的命令。由于鏈接了 tcmalloc,所以 tcmalloc 可以獲取所有內存分配和回收的信息。當 heap profiler 啟動后,就會定期的將程序內存分配和回收的行為 dump 到一個臨時文件中。
當程序運行一段時間后,你將得到一組 heap profile 文件
profile.0001.heap
profile.0002.heap
...
profile.0100.heap
每個 profile 文件中都包含了一段時間內,程序中內存分配和回收的記錄。如果想要找到內存泄露的線索,可以通過使用
pprof --base=profile.0001.heap /usr/bin/xxx profile.0100.heap --text
來進行查看,也可以生成 pdf 文件,會更直觀一些。

這樣一來,我們就可以很方便的對線上程序的內存泄露進行 Debug 了。
寫在最后
C++ 可謂是最復雜、最靈活的語言,也最容易給大家帶來困擾。如果想要用好 C++,團隊必須保持比較成熟的心態,團隊成員必須愿意按照一定的規則來使用 C++,而不是任性的隨意發揮。這樣大家才能把更多精力放在業務本身,而不是編程語言的特性上。
-
內存
+關注
關注
8文章
2999瀏覽量
73882 -
程序
+關注
關注
116文章
3776瀏覽量
80848 -
C++
+關注
關注
22文章
2104瀏覽量
73489 -
線程
+關注
關注
0文章
504瀏覽量
19651
發布評論請先 登錄
相關推薦
關于labview中的內存泄露
內存泄露和內存溢出是什么意思
怎么去解決paho mqtt和mymqtt的內存泄露問題呢?
請教一下大神ec200x內存泄露是何原因呢?
全志R128內存泄露調試案例
記一次調試python內存泄露的問題解決方案分享

記錄單片機使用malloc產生內存泄露的問題及解決方法



如何使用valgrind對代碼進行內存泄露檢測
mtrace分析內存泄露





 工商網監
工商網監
評論