 淺析tensorrt-llm搭建運行環境以及庫
淺析tensorrt-llm搭建運行環境以及庫
前文
TensorRT-LLM正式出來有半個月了,一直沒有時間玩,周末趁著有時間跑一下。
之前玩內測版的時候就需要cuda-12.x,正式出來仍是需要cuda-12.x,主要是因為tensorr-llm中依賴的CUBIN(二進制代碼)是基于cuda12.x編譯生成的,想要跑只能更新驅動。
I’ve verified with our CUDA team. A CUBIN built with CUDA 12.x will not load in CUDA 11.x. CUDA 12.x is required to use TensorRT-LLM.
因此,想要快速跑TensorRT-LLM,建議直接將nvidia-driver升級到535.xxx,利用docker跑即可,省去自己折騰環境,至于想要自定義修改源碼,也在docker中搞就可以。
理論上替換原始代碼中的該部分就可以使用別的cuda版本了(batch manager只是不開源,和cuda版本應該沒關系,主要是FMA模塊,另外TensorRT-llm依賴的TensorRT有cuda11.x版本,配合inflight_batcher_llm跑的triton-inference-server也和cuda12.x沒有強制依賴關系):
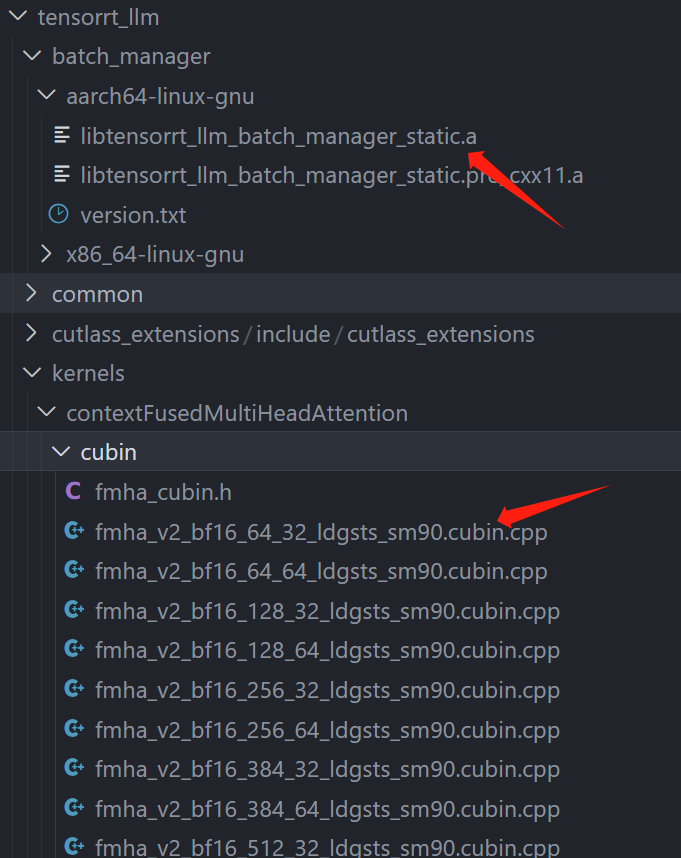
tensorrt-llm中預先編譯好的部分
說完環境要求,開始配環境吧!
搭建運行環境以及庫
首先拉取鏡像,宿主機顯卡驅動需要高于等于535:
docker pull nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3
這個鏡像是前幾天剛出的,包含了運行TensorRT-LLM的所有環境(TensorRT、mpi、nvcc、nccl庫等等),省去自己配環境的煩惱。
拉下來鏡像后,啟動鏡像:
dockerrun-it-d--cap-add=SYS_PTRACE--cap-add=SYS_ADMIN--security-optseccomp=unconfined--gpus=all--shm-size=16g--privileged--ulimitmemlock=-1--name=developnvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3bash
接下來的操作全在這個容器里。
編譯tensorrt-llm
首先獲取git倉庫,因為這個鏡像中只有運行需要的lib,模型還是需要自行編譯的(因為依賴的TensorRT,用過trt的都知道需要構建engine),所以首先編譯tensorrRT-LLM:
#TensorRT-LLMusesgit-lfs,whichneedstobeinstalledinadvance. apt-getupdate&&apt-get-yinstallgitgit-lfs gitclonehttps://github.com/NVIDIA/TensorRT-LLM.git cdTensorRT-LLM gitsubmoduleupdate--init--recursive gitlfsinstall gitlfspull
然后進入倉庫進行編譯:
python3./scripts/build_wheel.py--trt_root/usr/local/tensorrt
一般不會有環境問題,這個docekr中已經包含了所有需要的包,執行build_wheel的時候會按照腳本中的步驟pip install一些需要的包,然后運行cmake和make編譯文件:
.. adding'tensorrt_llm/tools/plugin_gen/templates/functional.py.tpl' adding'tensorrt_llm/tools/plugin_gen/templates/plugin.cpp.tpl' adding'tensorrt_llm/tools/plugin_gen/templates/plugin.h.tpl' adding'tensorrt_llm/tools/plugin_gen/templates/plugin_common.cpp' adding'tensorrt_llm/tools/plugin_gen/templates/plugin_common.h' adding'tensorrt_llm/tools/plugin_gen/templates/tritonPlugins.cpp.tpl' adding'tensorrt_llm-0.5.0.dist-info/LICENSE' adding'tensorrt_llm-0.5.0.dist-info/METADATA' adding'tensorrt_llm-0.5.0.dist-info/WHEEL' adding'tensorrt_llm-0.5.0.dist-info/top_level.txt' adding'tensorrt_llm-0.5.0.dist-info/zip-safe' adding'tensorrt_llm-0.5.0.dist-info/RECORD' removingbuild/bdist.linux-x86_64/wheel Successfullybuilttensorrt_llm-0.5.0-py3-none-any.whl
然后pip install tensorrt_llm-0.5.0-py3-none-any.whl即可。
運行
首先編譯模型,因為最近沒有下載新模型,還是拿舊的llama做例子。其實吧,其他llm也一樣(chatglm、qwen等等),只要trt-llm支持,編譯運行方法都一樣的,在hugging face下載好要測試的模型即可。
這里我執行:
python/work/code/TensorRT-LLM/examples/llama/build.py
--model_dir/work/models/GPT/LLAMA/llama-7b-hf#可以替換為你自己的llm模型 --dtypefloat16 --remove_input_padding --use_gpt_attention_pluginfloat16 --enable_context_fmha --use_gemm_pluginfloat16 --use_inflight_batching#開啟inflightbatching --output_dir/work/trtModel/llama/1-gpu
然后就是TensorRT的編譯、構建engine的過程(因為使用了plugin,編譯挺快的,這里我只用了一張A4000,所以沒有設置world_size,默認為1),這里有很多細節,后續會聊。
編譯好engine后,會生成/work/trtModel/llama/1-gpu,后續會用到。
然后克隆https://github.com/triton-inference-server/tensorrtllm_backend:
執行以下命令:
cdtensorrtllm_backend mkdirtriton_model_repo #拷貝出來模板模型文件夾 cp-rall_models/inflight_batcher_llm/*triton_model_repo/ #將剛才生成好的`/work/trtModel/llama/1-gpu`移動到模板模型文件夾中 cp/work/trtModel/llama/1-gpu/*triton_model_repo/tensorrt_llm/1
然后修改triton_model_repo/中的config:
triton_model_repo/preprocessing/config.pbtxt
| Name | Description |
|---|---|
| tokenizer_dir | The path to the tokenizer for the model.這里我改成/work/models/GPT/LLAMA/llama-7b-hf |
| tokenizer_type | The type of the tokenizer for the model, t5, auto and llama are supported. 這里我設置為'llama' |
triton_model_repo/tensorrt_llm/config.pbtxt
| Name | Description |
|---|---|
| decoupled | Controls streaming. Decoupled mode must be set to True if using the streaming option from the client.這里我設置為 true |
| gpt_model_type | Set to inflight_fused_batching when enabling in-flight batching support. To disable in-flight batching, set to V1 這里保持默認不變 |
| gpt_model_path | Path to the TensorRT-LLM engines for deployment. In this example, the path should be set to /tensorrtllm_backend/triton_model_repo/tensorrt_llm/1 as the tensorrtllm_backend directory will be mounted to /tensorrtllm_backend within the container 這里改成 triton_model_repo/tensorrt_llm/1 |
triton_model_repo/postprocessing/config.pbtxt
| Name | Description |
|---|---|
| tokenizer_dir | The path to the tokenizer for the model. In this example, the path should be set to /tensorrtllm_backend/tensorrt_llm/examples/gpt/gpt2 as the tensorrtllm_backend directory will be mounted to /tensorrtllm_backend within the container 這里改成/work/models/GPT/LLAMA/llama-7b-hf |
| tokenizer_type | The type of the tokenizer for the model, t5, auto and llama are supported. In this example, the type should be set to auto 這里我是llama |
設置好之后進入tensorrtllm_backend執行:
python3scripts/launch_triton_server.py--world_size=1--model_repo=triton_model_repo
順利的話就會輸出:
root@6aaab84e59c0:/work/code/tensorrtllm_backend#I11051458.2868362561098pinned_memory_manager.cc:241]Pinnedmemorypooliscreatedat'0x7ffb76000000'withsize268435456 I11051458.2869732561098cuda_memory_manager.cc:107]CUDAmemorypooliscreatedondevice0withsize67108864 I11051458.2881202561098model_lifecycle.cc:461]loading:tensorrt_llm:1 I11051458.2881352561098model_lifecycle.cc:461]loading:preprocessing:1 I11051458.2881422561098model_lifecycle.cc:461]loading:postprocessing:1 [TensorRT-LLM][WARNING]max_tokens_in_paged_kv_cacheisnotspecified,willusedefaultvalue [TensorRT-LLM][WARNING]batch_scheduler_policyparameterwasnotfoundorisinvalid(mustbemax_utilizationorguaranteed_no_evict) [TensorRT-LLM][WARNING]kv_cache_free_gpu_mem_fractionisnotspecified,willusedefaultvalueof0.85ormax_tokens_in_paged_kv_cache [TensorRT-LLM][WARNING]max_num_sequencesisnotspecified,willbesettotheTRTenginemax_batch_size [TensorRT-LLM][WARNING]enable_trt_overlapisnotspecified,willbesettotrue [TensorRT-LLM][WARNING][json.exception.type_error.302]typemustbenumber,butisnull [TensorRT-LLM][WARNING]Optionalvalueforparametermax_num_tokenswillnotbeset. [TensorRT-LLM][INFO]InitializingMPIwiththreadmode1 I11051458.3929152561098python_be.cc:2199]TRITONBACKEND_ModelInstanceInitialize:postprocessing_0_0(CPUdevice0) I11051458.3929792561098python_be.cc:2199]TRITONBACKEND_ModelInstanceInitialize:preprocessing_0_0(CPUdevice0) [TensorRT-LLM][INFO]MPIsize:1,rank:0 I11051458.7321652561098model_lifecycle.cc:818]successfullyloaded'postprocessing' I11051459.3832552561098model_lifecycle.cc:818]successfullyloaded'preprocessing' [TensorRT-LLM][INFO]TRTGptModelmaxNumSequences:16 [TensorRT-LLM][INFO]TRTGptModelmaxBatchSize:8 [TensorRT-LLM][INFO]TRTGptModelenableTrtOverlap:1 [TensorRT-LLM][INFO]Loadedenginesize:12856MiB [TensorRT-LLM][INFO][MemUsageChange]InitcuBLAS/cuBLASLt:CPU+0,GPU+8,now:CPU13144,GPU13111(MiB) [TensorRT-LLM][INFO][MemUsageChange]InitcuDNN:CPU+2,GPU+10,now:CPU13146,GPU13121(MiB) [TensorRT-LLM][INFO][MemUsageChange]TensorRT-managedallocationinenginedeserialization:CPU+0,GPU+12852,now:CPU0,GPU12852(MiB) [TensorRT-LLM][INFO][MemUsageChange]InitcuBLAS/cuBLASLt:CPU+0,GPU+8,now:CPU13164,GPU14363(MiB) [TensorRT-LLM][INFO][MemUsageChange]InitcuDNN:CPU+0,GPU+8,now:CPU13164,GPU14371(MiB) [TensorRT-LLM][INFO][MemUsageChange]TensorRT-managedallocationinIExecutionContextcreation:CPU+0,GPU+0,now:CPU0,GPU12852(MiB) [TensorRT-LLM][INFO][MemUsageChange]InitcuBLAS/cuBLASLt:CPU+0,GPU+8,now:CPU13198,GPU14391(MiB) [TensorRT-LLM][INFO][MemUsageChange]InitcuDNN:CPU+0,GPU+10,now:CPU13198,GPU14401(MiB) [TensorRT-LLM][INFO][MemUsageChange]TensorRT-managedallocationinIExecutionContextcreation:CPU+0,GPU+0,now:CPU0,GPU12852(MiB) [TensorRT-LLM][INFO]Using2878tokensinpagedKVcache. I11051417.2992932561098model_lifecycle.cc:818]successfullyloaded'tensorrt_llm' I11051417.3036612561098model_lifecycle.cc:461]loading:ensemble:1 I11051417.3058972561098model_lifecycle.cc:818]successfullyloaded'ensemble' I11051417.3060512561098server.cc:592] +------------------+------+ |RepositoryAgent|Path| +------------------+------+ +------------------+------+ I11051417.3064012561098server.cc:619] +-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ |Backend|Path|Config| +-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ |tensorrtllm|/opt/tritonserver/backends/tensorrtllm/libtriton_tensorrtllm.so|{"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-com| |||pute-capability":"6.000000","default-max-batch-size":"4"}}| |python|/opt/tritonserver/backends/python/libtriton_python.so|{"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-com| |||pute-capability":"6.000000","shm-region-prefix-name":"prefix0_","default-max-batch-size":"4"}}| +-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ I11051417.3070532561098server.cc:662] +----------------+---------+--------+ |Model|Version|Status| +----------------+---------+--------+ |ensemble|1|READY| |postprocessing|1|READY| |preprocessing|1|READY| |tensorrt_llm|1|READY| +----------------+---------+--------+ I11051417.3933182561098metrics.cc:817]CollectingmetricsforGPU0:NVIDIARTXA4000 I11051417.3935342561098metrics.cc:710]CollectingCPUmetrics I11051417.3945502561098tritonserver.cc:2458] +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ |Option|Value| +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ |server_id|triton| |server_version|2.39.0| |server_extensions|classificationsequencemodel_repositorymodel_repository(unload_dependents)schedule_policymodel_configurationsystem_shared_memorycuda_shared_| ||memorybinary_tensor_dataparametersstatisticstracelogging| |model_repository_path[0]|/work/triton_models/inflight_batcher_llm| |model_control_mode|MODE_NONE| |strict_model_config|1| |rate_limit|OFF| |pinned_memory_pool_byte_size|268435456| |cuda_memory_pool_byte_size{0}|67108864| |min_supported_compute_capability|6.0| |strict_readiness|1| |exit_timeout|30| |cache_enabled|0| +----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+ I11051417.4234792561098grpc_server.cc:2513]StartedGRPCInferenceServiceat0.0.0.0:8001 I11051417.4244182561098http_server.cc:4497]StartedHTTPServiceat0.0.0.0:8000 I11051417.4663782561098http_server.cc:270]StartedMetricsServiceat0.0.0.0:8002
這時也就啟動了triton-inference-server,后端就是TensorRT-LLM。
可以看到LLAMA-7B-FP16精度版本,占用顯存為:
+---------------------------------------------------------------------------------------+ SunNov514462023 +---------------------------------------------------------------------------------------+ |NVIDIA-SMI535.113.01DriverVersion:535.113.01CUDAVersion:12.2| |-----------------------------------------+----------------------+----------------------+ |GPUNamePersistence-M|Bus-IdDisp.A|VolatileUncorr.ECC| |FanTempPerfPwr:Usage/Cap|Memory-Usage|GPU-UtilComputeM.| |||MIGM.| |=========================================+======================+======================| |0NVIDIARTXA4000Off|0000000000.0Off|Off| |41%34CP816W/140W|15855MiB/16376MiB|0%Default| |||N/A| +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ |Processes:| |GPUGICIPIDTypeProcessnameGPUMemory| |IDIDUsage| |=======================================================================================| +---------------------------------------------------------------------------------------+
客戶端
然后我們請求一下吧,先走http接口:
#執行
curl-XPOSTlocalhost:8000/v2/models/ensemble/generate-d'{"text_input":"Whatismachinelearning?","max_tokens":20,"bad_words":"","stop_words":""}'
#得到返回結果
{"model_name":"ensemble","model_version":"1","sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":"?Whatismachinelearning?Machinelearningisasubfieldofcomputersciencethatfocusesonthedevelopmentofalgorithmsthatcanlearn"}
triton目前不支持SSE方法,想stream可以使用grpc協議,官方也提供了grpc的方法,首先安裝triton客戶端:
pipinstalltritonclient[all]
然后執行:
python3inflight_batcher_llm/client/inflight_batcher_llm_client.py--request-output-len200--tokenizer_dir/work/models/GPT/LLAMA/llama-7b-hf--tokenizer_typellama--streaming
請求后可以看到是一個token一個token返回的,也就是我們使用chatgpt3.5時,一個字一個字蹦的意思:
... [29953] [29941] [511] [450] [315] [4664] [457] [310] output_ids=[[0,19298,297,6641,29899,23027,3444,29892,1105,7598,16370,408,263,14547,297,3681,1434,8401,304,4517,297,29871,29896,29947,29946,29955,29889,940,3796,472,278,23933,5977,322,278,7021,16923,297,29258,265,1434,8718,670,1914,27144,297,29871,29896,29947,29945,29896,29889,940,471,263,29323,261,310,278,671,310,21837,7984,292,322,471,278,937,304,671,263,10489,380,994,29889,940,471,884,263,410,29880,928,9227,322,670,8277,5134,450,315,4664,457,310,3444,313,29896,29947,29945,29896,511,450,315,4664,457,310,12730,313,29896,29947,29945,29946,511,450,315,4664,457,310,13616,313,29896,29947,29945,29945,511,450,315,4664,457,310,9556,313,29896,29947,29945,29955,511,450,315,4664,457,310,17362,313,29896,29947,29945,29947,511,450,315,4664,457,310,12710,313,29896,29947,29945,29929,511,450,315,4664,457,310,14198,653,313,29896,29947,29953,29900,511,450,315,4664,457,310,28806,313,29896,29947,29953,29896,511,450,315,4664,457,310,27440,313,29896,29947,29953,29906,511,450,315,4664,457,310,24506,313,29896,29947,29953,29941,511,450,315,4664,457,310]] Input:Borninnorth-eastFrance,Soyertrainedasa Output:chefinParisbeforemovingtoLondonin1847.HeworkedattheReformClubandtheRoyalHotelinBrightonbeforeopeninghisownrestaurantin1851.Hewasapioneeroftheuseofsteamcookingandwasthefirsttouseagasstove.HewasalsoaprolificwriterandhisbooksincludedTheCuisineofFrance(1851),TheCuisineofItaly(1854),TheCuisineofSpain(1855),TheCuisineofGermany(1857),TheCuisineofAustria(1858),TheCuisineofRussia(1859),TheCuisineofHungary(1860),TheCuisineofSwitzerland(1861),TheCuisineofNorway(1862),TheCuisineofSweden(1863),TheCuisineof
因為開了inflight batching,其實可以同時多個請求打過來,修改request_id不要一樣就可以:
#user1 python3inflight_batcher_llm/client/inflight_batcher_llm_client.py--request-output-len200--tokenizer_dir/work/models/GPT/LLAMA/llama-7b-hf--tokenizer_typellama--streaming--request_id1 #user2 python3inflight_batcher_llm/client/inflight_batcher_llm_client.py--request-output-len200--tokenizer_dir/work/models/GPT/LLAMA/llama-7b-hf--tokenizer_typellama--streaming--request_id2
至此就快速過完整個TensorRT-LLM的運行流程。
使用建議
非常建議使用docker,人生苦短。
在我們實際使用中,vllm在batch較大的場景并不慢,利用率也能打滿。TensorRT-LLM和vllm的速度在某些模型上快某些模型上慢,各有優劣。
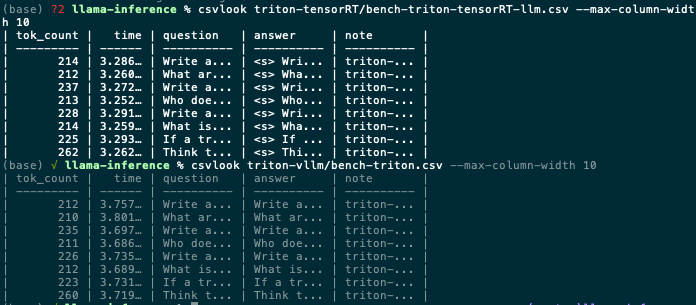
tensorrt-llm vs vllm
The most fundamental technical difference is that TensorRT-LLM relies on TensorRT ; which is a graph compiler that can produce optimised kernels for your graph. As we continue to improve TensorRT, there will be less and less needs for "manual" interventions to optimise new networks (in terms of kernels as well as taking advantage of numerical optimizations like INT4, INT8 or FP8). I hope it helps a bit.
TensorRT-LLM的特點就是借助TensorRT,TensorRT后續更新越快,支持特性越牛逼,TensorRT-LLM也就越牛逼。靈活性上,我感覺vllm和TensorRT-LLM不分上下,加上大模型的結構其實都差不多,甚至TensorRT-LLM都沒有上onnx-parser,在后續更新模型上,python快速搭建模型效率也都差不了多少。
先說這么多,后續會更新些關于TensorRT-LLM和triton相關的文章。
參考
https://github.com/NVIDIA/TensorRT-LLM/issues/45
https://github.com/NVIDIA/TensorRT-LLM/tree/main
https://github.com/NVIDIA/TensorRT-LLM/issues/83
https://github.com/triton-inference-server/tensorrtllm_backend#option-2-launch-triton-server-within-the-triton-container-built-via-buildpy-script
編輯:黃飛
-
容器
+關注
關注
0文章
494瀏覽量
22044 -
客戶端
+關注
關注
1文章
290瀏覽量
16662 -
python
+關注
關注
56文章
4782瀏覽量
84453 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7495
原文標題:參考
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
redhat搭建PHP運行環境LAMP的詳細資料說明

基于TensorRT完成NanoDet模型部署

干貨 | 虹科KPA MoDK運行環境與搭建步驟(1)——運行環境簡介

干貨|虹科KPA MoDK運行環境與搭建步驟(2)——MoDK運行環境搭建
阿里云 & NVIDIA TensorRT Hackathon 2023 決賽圓滿收官,26 支 AI 團隊嶄露頭角

周四研討會預告 | 注冊報名 NVIDIA AI Inference Day - 大模型推理線上研討會
現已公開發布!歡迎使用 NVIDIA TensorRT-LLM 優化大語言模型推理

點亮未來:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驅動的 Windows PC 上運行新模型
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

TensorRT-LLM低精度推理優化






 工商網監
工商網監
評論