 MixFormerV2:基于Transformer的高效跟蹤器
MixFormerV2:基于Transformer的高效跟蹤器
本文介紹我們組在單目標跟蹤任務上的新工作:MixFormerV2: Efficient Fully Transformer Tracking。本工作主要解決了目前基于 transformer 架構的跟蹤模型過于沉重,導致難以在 GPU 和 CPU 等邊緣設備上實時部署的問題。 我們通過簡潔有效的模型結構設計和高效的基于知識蒸餾的模型壓縮,對于現有的 MixFormer 模型進行了大幅度的輕量化提出了 MixFormerV2,同時依舊保持了穩定的跟蹤精度性能。我們分別發布了 GPU 和 CPU 兩個版本的模型,在 LaSOT,TrackingNet,TNL2K 等 benchmark 上,其跟蹤性能和推理速度均能夠大幅度超越目前同量級的 SOTA 模型。
我們的工作已被 NeurIPS 2023 接收,論文、代碼和模型均已開源:

論文地址:
https://arxiv.org/abs/2305.15896
代碼地址:
https://github.com/MCG-NJU/MixFormerV2
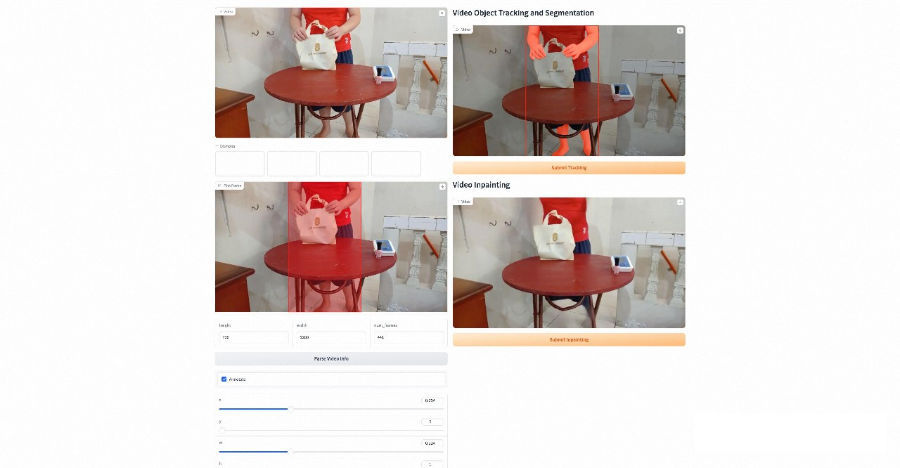
基于 MixFormerV2,結合現有的 SAM,E2FGVI 等方法,我們開發了一個支持 video object tracking, segmentation 以及 inpainting 的 demo,下面是一些 demo 結果和界面演示。
研究動機
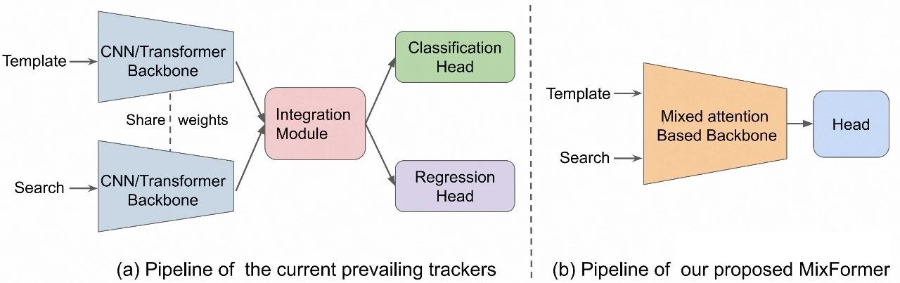
在 MixFormer 被提出之后(詳見我們組的另一篇工作,本作的前身 MixFormer [1]),該全新的跟蹤范式和模型結構的有效性被不斷驗證,基于這種范式的新方法也不斷涌現(如 OSTrack,SimTrack 等),提升了目標跟蹤任務的性能上限。 簡單來說,如圖所示傳統的跟蹤模型呈現雙流三階段的結構,對于模板和當前幀兩個輸入分別進行特征提取、信息交互和定位預測三個模塊,而 MixFormer-style 的模型利用了 transformer 注意力機制的靈活性,整合了前兩個階段,使用一個通常是預訓練好的 ViT backbone,對于兩個輸入同時進行特征提取和融合,形成了目前主流的單流兩階段的跟蹤器范式。 然而,這種單流跟蹤模型的缺點也很明顯,因為使用預訓練的 ViT,同時進行特征提取和融合的建模會使得計算開銷非常大,導致模型的推理速度降低,尤其是在 CPU 設備上,這也使得模型的實際部署成為問題。
性能分析
既然是輕量化的工作,我們有必要對于現有的模型進行一下 profile。以現有的 MixFormer 為例,我們使用在期刊擴展中提出的以 vanilla ViT 為 backbone 版本的 MixViT,我們分別測試了不同模型層數,輸入圖像尺寸以及 MLP 維度比率的在 GPU 和 CPU 上的推理速度,如圖所示。
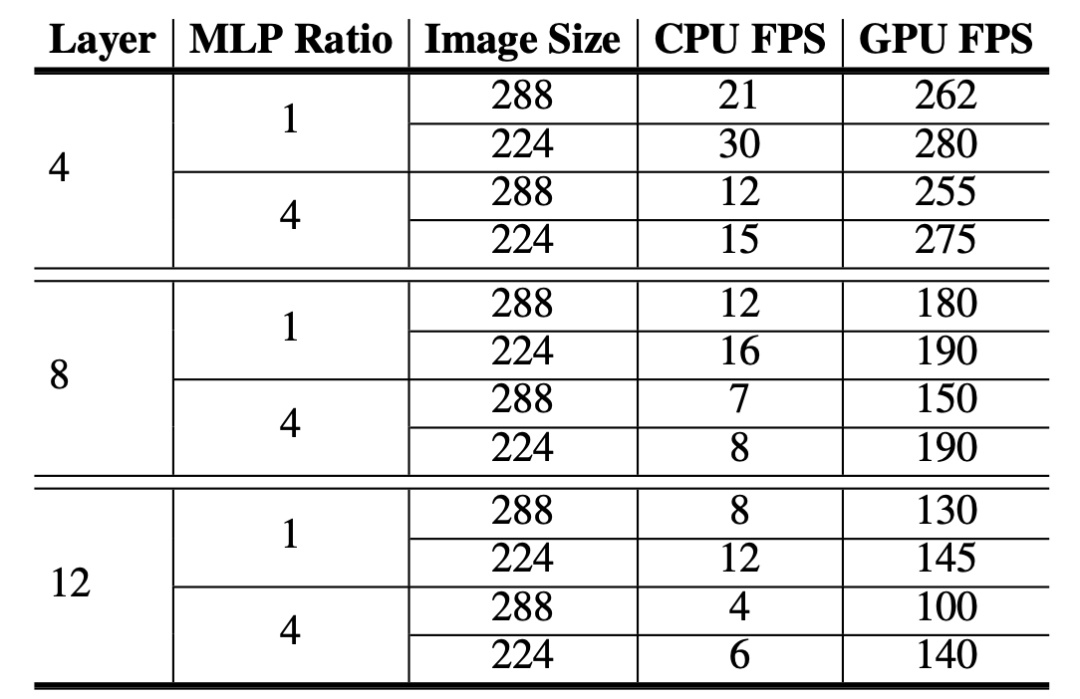
很自然的,當模型深度越小時,模型的推理速度幾乎以線性提高。尤其的,MLP ratio 成為制約 CPU 速度的一個重要瓶頸,因為 GPU 的并行度非常高,所以簡單地增加維度并不會大幅度明顯地降低運行效率,但是對于 CPU 卻會影響非常大。所以為了實現 CPU 上的實時運行,MLP 的隱藏層維度需要從常規的 x4 降低到 x1。
然后我們測試了 MixViT 的兩個預測頭,一個密集 pyramid 卷積定位頭,和一個基于 attention 的質量分數預測頭對于速度的影響,在 8 層的 backbone 基礎上,我們發現兩個預測模塊的計算開銷也是不能忽略的。當將兩個預測頭都替換成我們提出的基于 token 的非常輕量的預測頭(兩個簡單的 MLP)時,GPU 上的推理速度能夠提升 84.4%。而當 backbone 部分被進一步壓縮時,預測頭的替換所帶來性能提升的比重將會更大。

所以通過各個模塊分析,模型壓縮的思路已經很自然了,首先我們需要想辦法將兩個笨重的預測頭替換為更加輕量的實現,然后將標準的 ViT backbone 從深度和寬度上都進行減小。
方法
基于預測token的模型結構
我們的 MixFormerV2 是一個完全基于 transformer 的跟蹤架構,沒有任何的卷積操作和復雜的分數預測模塊,跟蹤框和置信度的預測都通過一個簡單的 MLP 實現,整個模型非常得簡潔統一,如圖所示。這得益于我們的核心設計——四個特殊預測 token。
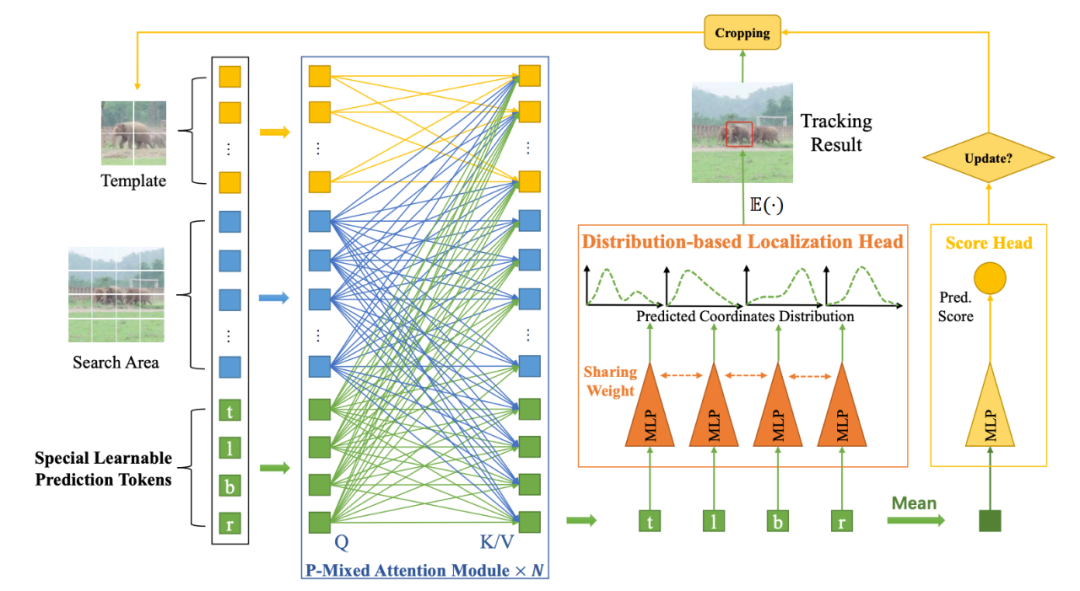
預測token參與的混合注意力機制
和原始的 MixViT 中的混合注意力模塊(Mixed Attention Module, MAM)不同,我們引入了四個特殊預測 token,用來在 backbone 中捕獲目標模板和搜索區域之間的相關性。這些 token 可以在網絡每層中逐步地壓縮目標信息,形成緊湊且稀疏的表征,用于之后的分類和回歸任務。 具體來說,模板、搜索區域的圖像特征 token 以及四個預定義的可學習 prediction token,會輸入到我們提出的預測 token 參與的混合注意力模塊(Prediction-Token-Invoked Mixed Attention, P-MAM)。下標 t, s, e 分別表示模板,搜索區域以及 prediction token,P-MAM 的操作定義為:
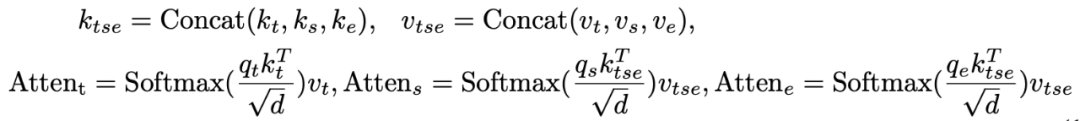
和原始的 MixFormer 相同,我們會使用不對稱混合注意力機制來提高推理時效率。我們引入的四個可學習 token 和標準 ViT 中的 CLS token 實際上非常類似,它們會在跟蹤數據集上自動地學習來壓縮目標和搜索區域的信息并建模其交互關系。
基于token的直接預測
在有了已經收集到豐富的模板和搜索區域信息的預測 token 之后,我們就可以直接使用這些 token 來進行目標定位和質量分數的預測了,并且通過幾個簡單統一的 MLP 就可以實現。 具體來說,對于定位回歸任務,每個預測 token 分別用來建模目標框的一條邊,輸入一個共享參數的 MLP 進行包圍框坐標的回歸預測;對于置信度分類任務,我們首先要將四個 token 的信息進行整合,在這里我們簡單地將四個 token 取均值就可以達到不錯的效果,然后輸入一個 MLP 輸出一個預測的置信度分數。 值得一提的是,對于回歸任務,我們并不是直接去回歸包圍框的絕對坐標,而是預測包圍框邊界的概率分布,這在實驗中被驗證能夠有效地提升模型精度,并且非常有利于下面會介紹的知識蒸餾過程。 這些基于 token 的預測頭對于分類和回歸任務都大大降低了計算復雜度,相比原始 MixViT 中密集卷積定位頭和使用 attention 的分數模塊,形成了簡單統一并且 Fully Transformer 的模型架構。
基于知識蒸餾的模型壓縮
為了進一步提升模型的效率,我們提出了一種基于知識蒸餾的模型壓縮范式,包括兩個階段,第一階段密集到稀疏(dense-to-sparse)蒸餾,來使得原始的教師模型更好地傳遞知識到我們基于 token 的預測模型;第二階段從深層到淺層(deep-to-shallow)蒸餾,來進行高效的模型剪枝。
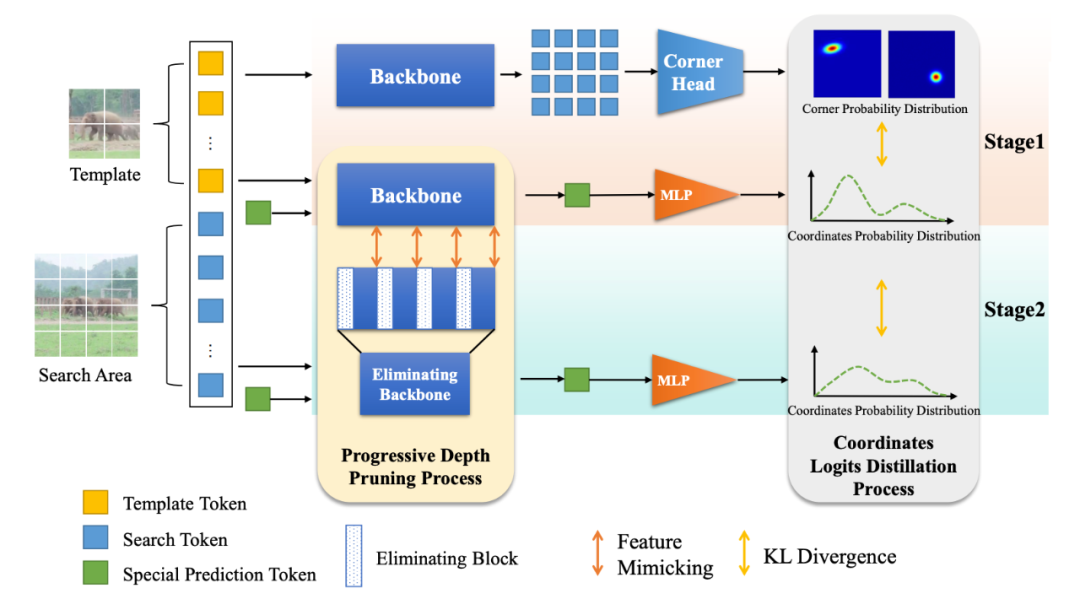
Dense-to-Sparse Distillation
我們選取現有的 SOTA 模型 MixViT 作為我們的教師模型,但是存在的問題是,如何將教師模型的知識傳遞給學生 MixFormerV2?因為教師和學生模型的輸出結構是不一樣,原始 MixViT 使用的卷積定位頭會預測目標框角點的二維分布,而我們的 MixFormerV2 的四個 MLP 預測頭會回歸預測四個邊界的坐標,這時候就體現出我們上面提到的預測目標邊界的概率分布而不是絕對坐標值的優勢了。 具體來說,我們將目標的上下左右邊界建模為四個隨機變量 ,而我們的 就是用來預測該隨機變量的概率分布:
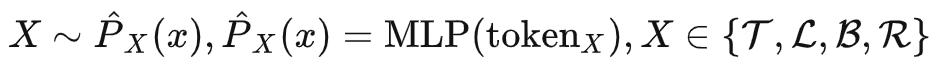
最終的預測結果可以表示為該概率分布的數學期望:
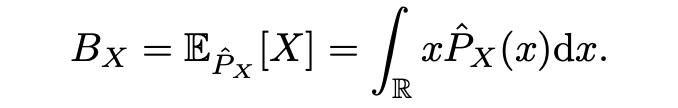
而對于 MixViT 來說,其預測角點輸出本質上是左上和右下坐標的二維聯合概率分布,這種建模方式使得教師模型的密集預測頭輸出和學生模型的基于稀疏 token 的輸出就可以通過邊緣分布非常自然地聯系起來:
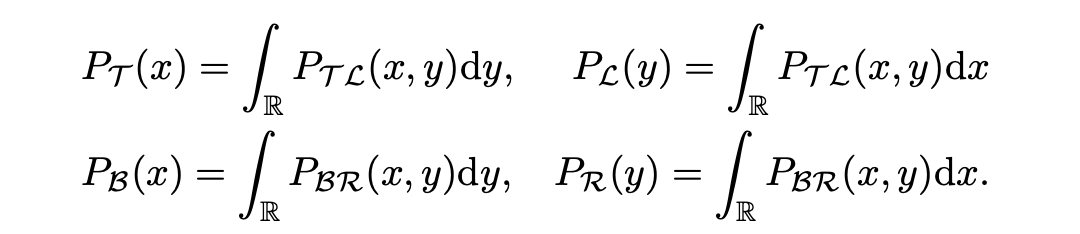
這時,使用 KL 散度損失函數,教師模型的輸出就可以作為軟標簽來監督學生模型,完成 dense-to-sparse 蒸餾階段的知識傳遞,如圖中 stage 1 所示。Deep-to-Shallow DistillationBackbone 始終是計算開銷的大頭,所以必須對 backbone 進行壓縮,所以我們提出了一種基于 feature mimicking 和 logits distillation 的由深到淺的壓縮方式,如圖中 stage 2 所示。 對于 logits distillation 我們施加 KL 散度即可,對于 feature mimicking,記 分別為學生和教師模型的特征圖,下標表示層數的索引,施加 損失:,其中為師生匹配監督的層數對。因為直接移除模型中的部分層會導致不連續和不一致的問題,所以我們探索了一種漸進式的深度剪枝方法。 具體來說,不是直接使用教師模型從頭監督一個更小的學生模型,我們讓學生模型初始化為一個和教師模型相同的副本,然后逐漸地撤除學生模型中的部分層,讓剩余的層在訓練中擬合教師模型的表征,這個設計讓學生和教師模型的初始表征分布盡可能得一致,提供了一種更加平滑的遷移策略并降低了 feature mimicking 的難度。 形式地,令 為 MixFormerV2 第 層的輸出,一個注意力塊的計算可以表示為(為了簡便表示公式中忽略了 LN 操作):
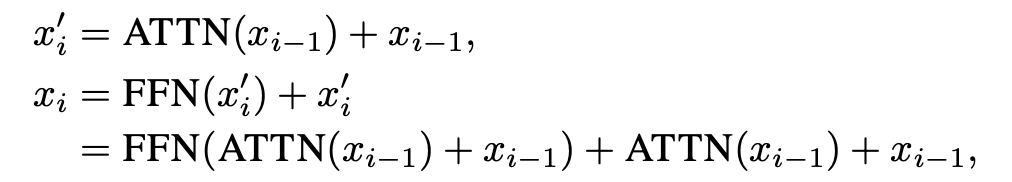
讓 為需要被刪除的層數的集合,我們會在這些層上施加一個衰退系數 :
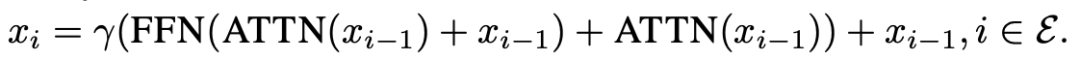
在訓練的前 個 epoch, 會以余弦函數的方式衰減,這意味著這些層在從模型中逐漸撤除并最終成為一個恒等變換,壓縮后的模型可以直接將剩余層堆疊在一起得到。
實驗
SOTA對比
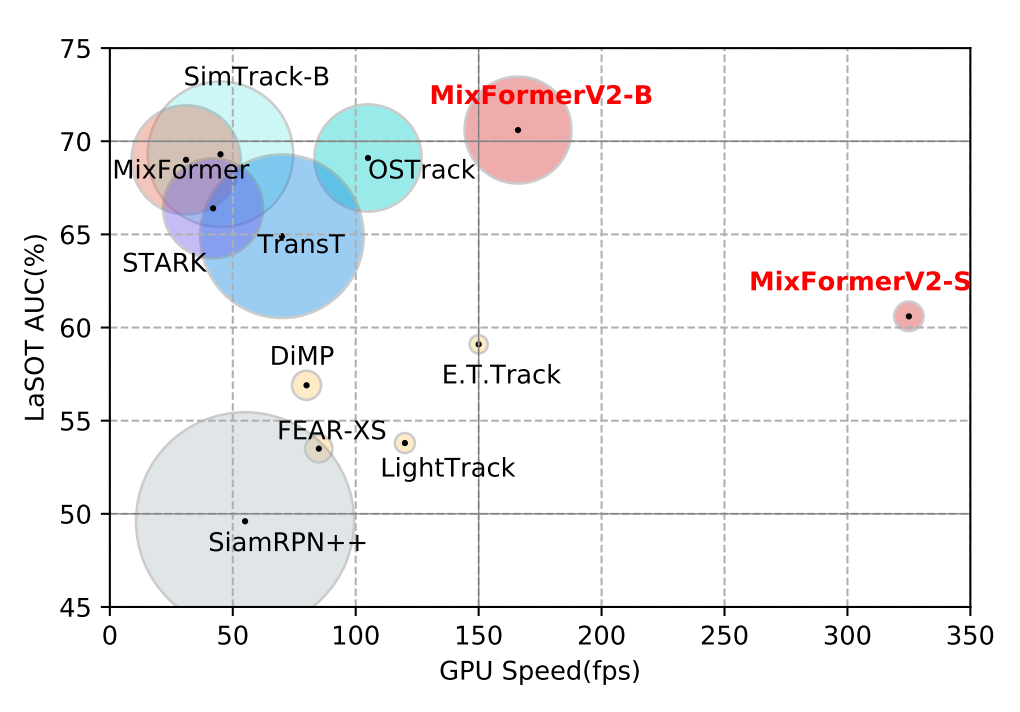
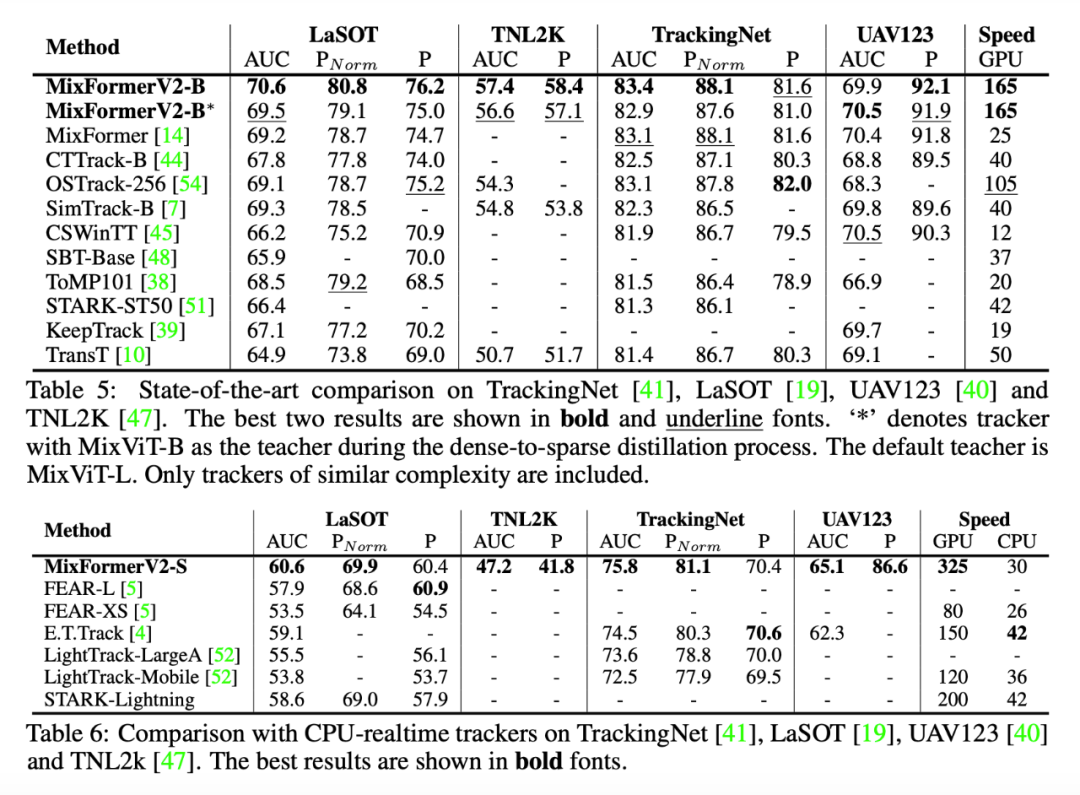
我們實例化了 GPU 和 CPU 兩個版本的模型,分別為 MixFormerV2-B 和 MixFormerV2-S,可以看出,在保持強勁的性能指標基礎上,我們的 MixFormerV2 在推理速度上都大幅超過了目前的主流跟蹤模型。
消融實驗
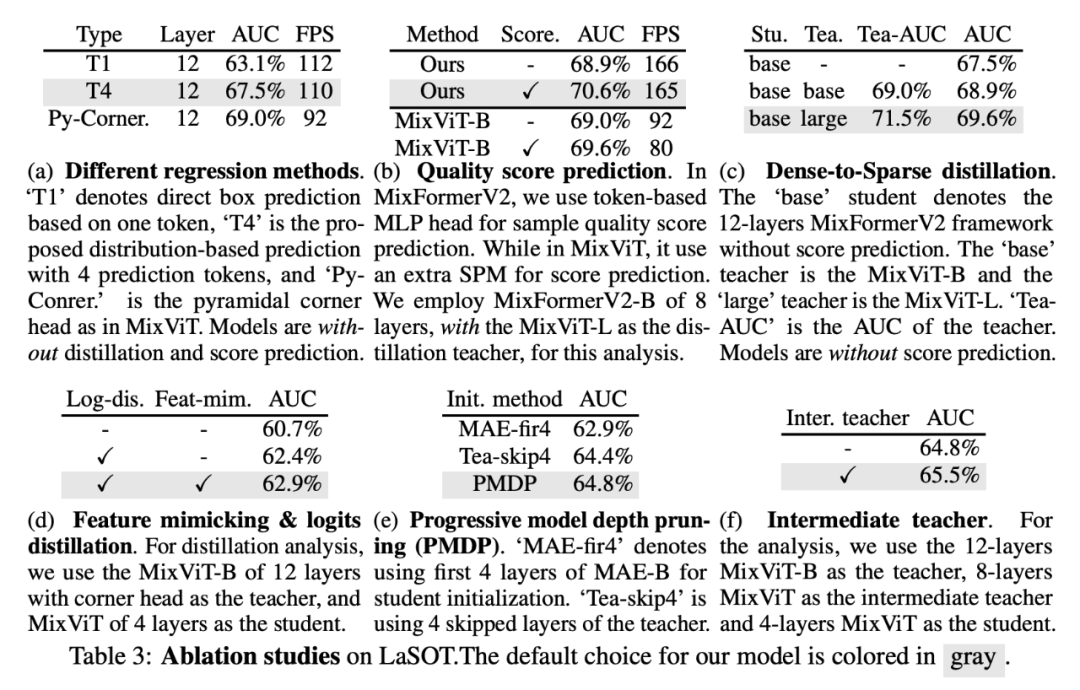
針對我們的框架中的各個組件設計,我們都進行了詳細的探究實驗驗證其有效性。
可視化
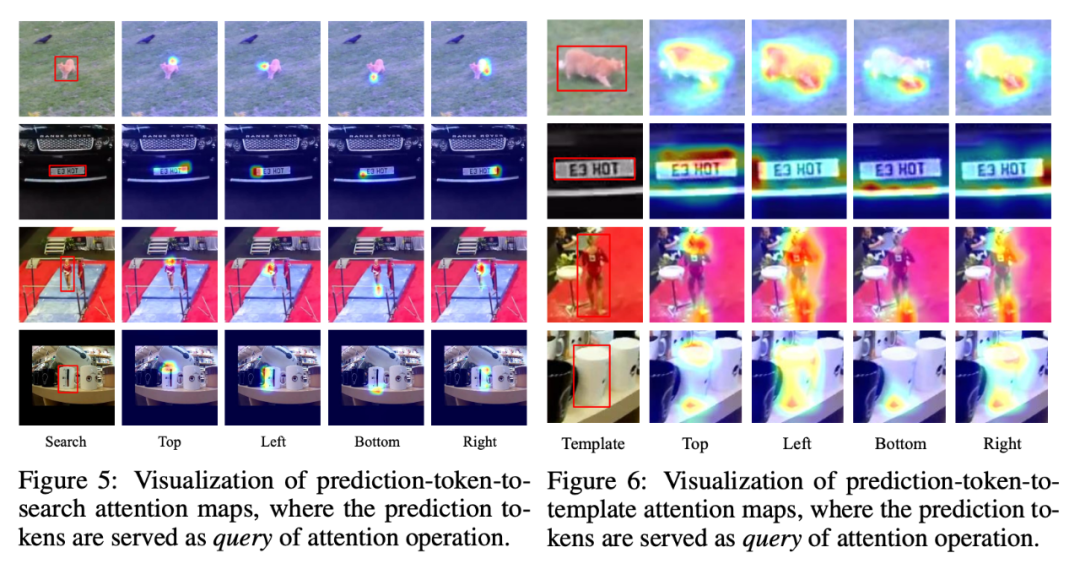
值得一提的是,我們對 MixFormerV2 的 prediction token 的 attention map 進行了可視化,我們能夠發現四個 token 確實是在關注建模目標的四個邊界,這也證明我們的方法的可靠性和可解釋性。
總結
我們的工作 MixFormerV2 基于現有的 sota 跟蹤模型 MixViT,改進設計了簡潔的模型架構和高效的壓縮方法,在多種硬件設備上實現了跟蹤模型性能精度和推理速度良好的平衡。我們希望 MixFormerV2 能夠有助于模型的實際落地應用,并促進高效跟蹤模型的發展。
-
gpu
+關注
關注
28文章
4703瀏覽量
128725 -
模型
+關注
關注
1文章
3178瀏覽量
48730 -
跟蹤器
+關注
關注
0文章
131瀏覽量
20016
原文標題:NeurIPS 2023 | MixFormerV2:基于Transformer的高效跟蹤器
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

秀秀我做的GPS跟蹤器

跟蹤器原理

光學跟蹤器信號源手機怎么設置
深入解析激光焊縫跟蹤器的工作原理與應用優勢






 工商網監
工商網監
評論