 英偉達發布新一代H200,搭載HBM3e,推理速度是H100兩倍!
英偉達發布新一代H200,搭載HBM3e,推理速度是H100兩倍!
電子發燒友網報道(文/李彎彎)日前,英偉達正式宣布,在目前最強AI芯片H100的基礎上進行一次大升級,發布新一代H200芯片。H200擁有141GB的內存、4.8TB/秒的帶寬,并將與H100相互兼容,在推理速度上幾乎達到H100的兩倍。H200預計將于明年二季度開始交付。此外,英偉達還透露,下一代Blackwell B100 GPU也將在2024年推出。
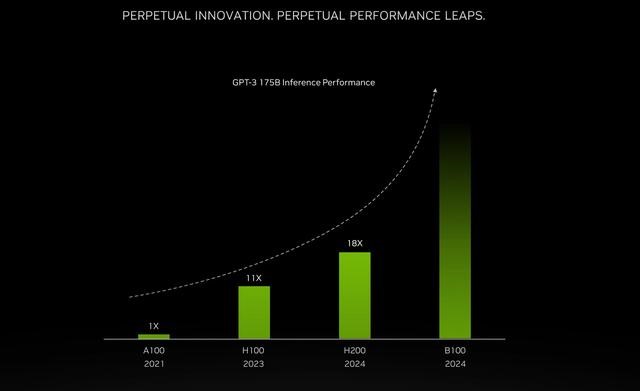
英偉達新發布的H200性能大幅提升(來源:英偉達官網)
首款搭載HBM3e的GPU,推理速度幾乎是H100的兩倍
與A100和H100相比,H200最大的變化就是內存。搭載世界上最快的內存HBM3e技術的H200在性能上得到了直接提升,141GB的內存幾乎是A100和H100最高80GB內存的2倍,4.8TB每秒的帶寬達到A100的2.4倍,顯著高于H100 3.35TB每秒的帶寬。
今年早些時候,就有消息稱,包括英偉達在內,全球多個科技巨頭都在競購SK海力士第五代高帶寬內存HBM3e。 HBM是由AMD和SK海力士發起的基于3D堆棧工藝的高性能DRAM,適用于高存儲器帶寬需求的應用場合。如今HBM已經發展出HBM2、HBM2e以及HBM3,HBM3e是HBM3的新一代產品。英偉達、AMD等企業的高端AI芯片大多搭載HBM。
電子發燒友此前報道過,英偉達歷代主流訓練芯片基本都配置HBM,其2016年發布的首個采用帕斯卡架構的顯卡TeslaP100已搭載了HBM2,隨后TeslaV100也采用了HBM2;2017年初,英偉達發布的Quadro系列專業卡中的旗艦GP100也采用了HBM2;2021年推出的TeslaA100計算卡也搭載了HBM2E,2022年推出了面向大陸地區的A800,同樣也配置HBM2E;2022年推出了市面上最強的面向AI服務器的GPU卡H100,采用的HBM3。
AMD今年6月推出的號稱是最強的AI芯片MI300X,就是搭載由SK海力士及三星電子供應的HBM。AMD稱,MI300X提供的HBM密度最高是英偉達AI芯片H100的2.4倍,其HBM帶寬最高是H100的1.6倍。這意味著,AMD的芯片可以運行比英偉達芯片更大的模型。
如今英偉達新發布的H200搭載HBM3e,可想而知在性能上將會更上一層。H200配備141GB的HBM3e內存,運行速率約為6.25 Gbps,六個HBM3e堆棧為每個GPU帶來4.8 TB/s的總帶寬。原有的H100配備80GB的HBM3,對應的總帶寬為3.35 TB/s,這是一個巨大的進步。相比于H100的SXM版本,H200的SXM版本將內存容量和總帶寬分別提高了76%和43%。
英偉達表示,基于與H100相同的Hopper架構,H200將具有H100的一切功能,例如可以用來加速基于Transformer架構搭建的深度學習模型的Transformer Engine功能。
根據其官網信息,H200在大模型Llama 2、GPT-3.5的輸出速度上分別是H100的1.9倍和1.6倍,在高性能計算HPC方面的速度更是達到了雙核x86 CPU的110倍。
在TF32 Tensor Core(張量核心)中,H200可達到989萬億次浮點運算;INT8張量核心下提供3,958 TFLOPS(每秒3958萬億次的浮點運算)。
不僅如此,基于H200芯片構建的HGX H200加速服務器平臺,擁有 NVLink 和 NVSwitch的高速互連支持。8個HGX H200則提供超過32 petaflops(每秒1000萬億次的浮點運算)的FP8深度學習計算和 1.1TB 聚合高帶寬內存,可為科學研究和 AI 等應用的工作負載提供更高的性能支持,包括超1750億參數的大模型訓練和推理。
英偉達副總裁Ian Buck表示,為了訓練生成式AI和高性能計算應用,必須使用高性能GPU。有了H200,行業領先的AI超級計算平臺可以更快地解決一些世界上最重要的挑戰。
目前,英偉達的全球合作伙伴服務器制造商生態系統包括華擎 Rack、華碩、戴爾科技、Eviden、技嘉、慧與、英格拉科技、聯想、QCT、Supermicro、緯創資通和緯穎科技等,可以直接使用H200更新其現有系統。除了英偉達自己投資的CoreWeave、Lambda和 Vultr之外,亞馬遜網絡服務、谷歌云、微軟Azure 和甲骨文云等云服務提供商將從明年開始首批部署H200。
如果沒有獲得出口許可,新H200不會銷往中國
這款H200能否對華出口也是大家關心的問題。對此,英偉達表示,如果沒有出口許可,新的H200將不會銷往中國。去年9月,英偉達高端GPU對中國出口就受到限制,當時英偉達表示,美國通過公司向中國出口A100和H100芯片將需要新的許可證要求,同時DGX或任何其他包含A100或H100芯片的產品,以及未來性能高于A100的芯片都將受到新規管制。
根據美國商務部的法規,其主要限制的是算力和帶寬,算力上線是4800 TOPS,帶寬上線是600 GB/s。為了應對這個問題,英偉達后來向中國企業提供了替代版本A800和H800。A800的帶寬為400GB/s,低于A100的600GB/s,H800據透露約為H100的一半。這意味著A800、H800在進行AI模型訓練的時候,需要耗費更長的時間。
然而美國政府認為,H800在某些情況下算力仍然不亞于H100。為了進一步加強對AI芯片的出口管制,美國計劃用多項新的標準來替換掉之前針對“帶寬參數”。今年10月,美國商務部工業與安全局(BIS)發布更新針對AI芯片的出口管制規定,根據新規定,美國商務部計劃引入一項被稱為“性能密度”的參數,來防止企業尋找到變通的方案,修訂后的出口管制措施將禁止美國企業向中國出售運行速度達到300teraflops(即每秒可計算 3億次運算)及以上的數據中心芯片。根據這樣的規定,在沒有獲得許可的情況下,英偉達新發布的H200必然是沒有辦法向中國企業出售。
事實上,在美國政府今年10月發布的新規下,英偉達不少產品都在限制范圍內,包括但并不限于A100、A800、H100、H800、L40、L40 以及RTX 4090。任何集成了一個或多個以上芯片的系統,包括但不限于英偉達DGX、HGX系統,也在新規涵蓋范圍之內。
針對此情況,有消息稱,本月初英偉達已經向經銷商公布“中國特供版”HGX H20、L20 PCle、L2 PCle產品信息,分別針對訓練、推理和邊緣場景,最快將于11月16日公布,量產時間為2023年12月至2024年1月。其中,HGX H20在帶寬、計算速度等方面均有所限制,理論綜合算力要比英偉達H100降80%左右。
此外,據英特爾供應鏈透露,英特爾也已經針對最新發布的Gaudi2推出降規版出貨,預計將不受新禁令影響。不過無論是英偉達,還是英特爾針對中國市場推出的特供版,可想而知性能必然是會大打折扣的,而且從美國政府的舉措來看,特供版是否能夠長久供應也是未知數。
總結
可以看到,英偉達此次發布的H100,是全球首款搭載HBM3e的GPU,擁有141GB的內存、4.8TB/秒的帶寬,推理速度幾乎達到H100的兩倍。可想而知,有了H200,當前備受關注的AI大模型的訓練和部署應用將會得到更快速地發展。
-
英偉達
+關注
關注
22文章
3743瀏覽量
90830 -
HBM3
+關注
關注
0文章
74瀏覽量
144 -
HBM3E
+關注
關注
0文章
78瀏覽量
228
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論