 1.1TB HBM3e內存!NVIDIA奉上全球第一GPU:可惜無緣中國
1.1TB HBM3e內存!NVIDIA奉上全球第一GPU:可惜無緣中國
NVIDIA GPU已經在AI、HPC領域遙遙領先,但沒有最強,只有更強。
現在,NVIDIA又發布了全新的HGX H200加速器,可處理AIGC、HPC工作負載的海量數據。
NVIDIA H200的一大特點就是首發新一代HBM3e高帶寬內存(疑似來自SK海力士),單顆容量就多達141GB(原始容量144GB但為提高良率屏蔽了一點點),同時帶寬多達4.8TB/s。
對比H100,容量增加了76%,帶寬增加了43%,而對比上代A100,更是容量幾乎翻番,帶寬增加2.4倍。
得益于NVLink、NVSwitch高速互連技術,H200還可以四路、八路并聯,因此單系統的HBM3e內存容量能做到最多1128GB,也就是1.1TB。
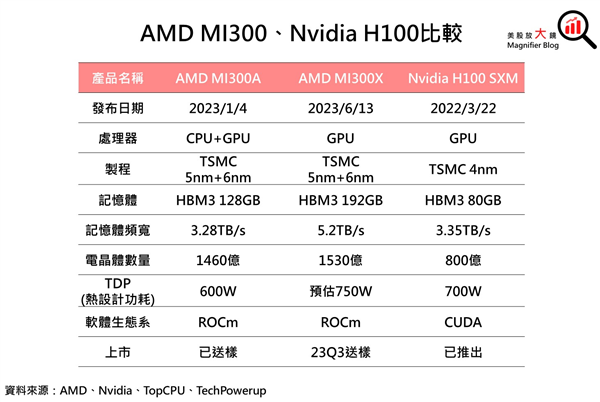
只是相比于AMD Instinct MI300X還差點意思,后者搭載了192GB HBM3,帶寬高達5.2TB/s。

性能方面,H200再一次實現了飛躍,700億參數的Llama2大語言模型推理性能比H100提高了多達90%,1750億參數的GTP-3模型推理性能也提高了60%,而對比前代A100 HPC模擬性能直接翻番。
八路H200系統下,FP8深度學習計算性能可以超過32PFlops,也就是每秒3.2億億次浮點計算,堪比一臺大型超級計算機。
隨著未來軟件的持續升級,H200還有望繼續釋放潛力,實現更大的性能優勢。
此外,H200還可以與采用超高速NVLink-C2C互連技術的NVIDIA Grace CPU處理器搭配使用,就組成了GH200 Grace Hopper超級芯片,專為大型HPC、AI應用而設計的計算模塊。
NVIDIA H200將從2024年第二季度開始通過全球系統制造商、云服務提供商提供。
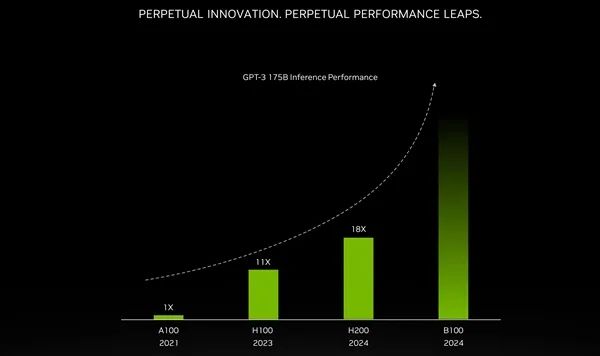
另外,NVIDIA第一次披露了下一代AI/HPC加速器的情況,架構代號Blackwell,核心編號GB200,加速器型號B100。
NVIDIA第一次公開確認,B100將在2024年發布,但未出更具體的時間表。
此前曝料稱,B100原計劃2024年第四季度推出,但因為AI需求太火爆,已經提前到第二季度,現已進入供應鏈認證階段。
NVIDIA表示,B100加速器可以輕松搞定1730億參數的大語言模型,是現在H200的兩倍甚至更多。
雖然這不代表原始計算性能,但也足以令人望而生畏。
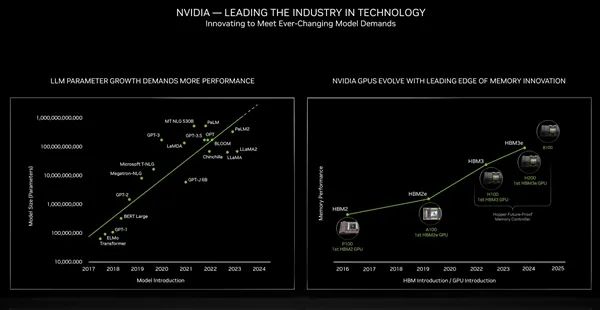
同時,B100還將帶來更高級的HBM高帶寬內存規格。
回顧歷史,Pascal P100、Ampere A100、Hopper H100、H200分別首發應用HBM2、HBM2e、HBM3、HBM3e。
接下來的B100肯定趕不上HBM4(規范還沒定呢),但必然會在堆疊容量、帶寬上繼續突破,大大超越現在的4.8TB/s。
Blackwell架構同時也會用于圖形工作站和桌面游戲,傳聞有GB202、GB203、GB205、GB206、GB207等不同核心,但是對于RTX 50系列,NVIDIA始終三緘其口,幾乎肯定到2025年才會發布。
2024年就將是RTX 40 SUPER系列的天下了,明年初的CES 2025首發三款型號RTX 4080 SUPER、RTX 4070 Ti SUPER、RTX 4070 SUPER。
-
NVIDIA
+關注
關注
14文章
4940瀏覽量
102815 -
gpu
+關注
關注
28文章
4701瀏覽量
128705 -
堆疊
+關注
關注
0文章
33瀏覽量
16578 -
AI
+關注
關注
87文章
30146瀏覽量
268414 -
HBM3
+關注
關注
0文章
74瀏覽量
145 -
HBM3E
+關注
關注
0文章
78瀏覽量
232
原文標題:1.1TB HBM3e內存!NVIDIA奉上全球第一GPU:可惜無緣中國
文章出處:【微信號:hdworld16,微信公眾號:硬件世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
三星電子HBM3E內存獲英偉達認證,加速AI GPU市場布局
SK海力士9月底將量產12層HBM3E高性能內存
中國AI芯片和HBM市場的未來
NVIDIA預定購三星獨家供應的大量12層HBM3E內存
什么是HBM3E內存?Rambus HBM3E/3內存控制器內核
SK海力士HBM3E內存正式量產,AI性能提升30倍,成本能耗降低96%
美光量產行業領先的HBM3E解決方案,加速人工智能發展

美光開始量產行業領先的 HBM3E 解決方案,加速人工智能發展

美光新款高頻寬記憶體HBM3E將被用于英偉達H200
三星發布首款12層堆疊HBM3E DRAM
三星電子成功發布其首款12層堆疊HBM3E DRAM—HBM3E 12H
AMD發布HBM3e AI加速器升級版,2025年推新款Instinct MI
英偉達斥資預購HBM3內存,為H200及超級芯片儲備產能
英偉達大量訂購HBM3E內存,搶占市場先機
英偉達將于Q1完成HBM3e驗證 2026年HBM4將推出






 工商網監
工商網監
評論