 傳統基于幀的圖像傳感器輸出和基于事件的視覺傳感器輸出對比
傳統基于幀的圖像傳感器輸出和基于事件的視覺傳感器輸出對比
2021年,索尼半導體解決方案公司(Sony Semiconductor Solutions Corporation,以下簡稱“索尼”)發布了兩款堆疊式基于事件(Event-based)的視覺傳感器(EVS)。這兩款專為工業設備設計的傳感器實現了業界最小(相比其它堆疊式基于事件的視覺傳感器)的4.86 μm像素尺寸,并且只有在感知到場景變化時才會進行捕捉記錄。
01
事件相機概述
傳統基于幀的圖像傳感器輸出和基于事件的視覺傳感器輸出對比
基于事件的相機是一種生物啟發的新型視覺傳感器,可實時高效地捕捉場景變化。與基于幀的傳統相機不同,事件相機僅報告觸發的像素級亮度變化(成為事件),并以微秒級分辨率輸出異步事件流。該類視覺傳感器已經逐漸成為圖像處理、計算機視覺、機器人感知與狀態估計、神經形態學等領域的研究熱點。
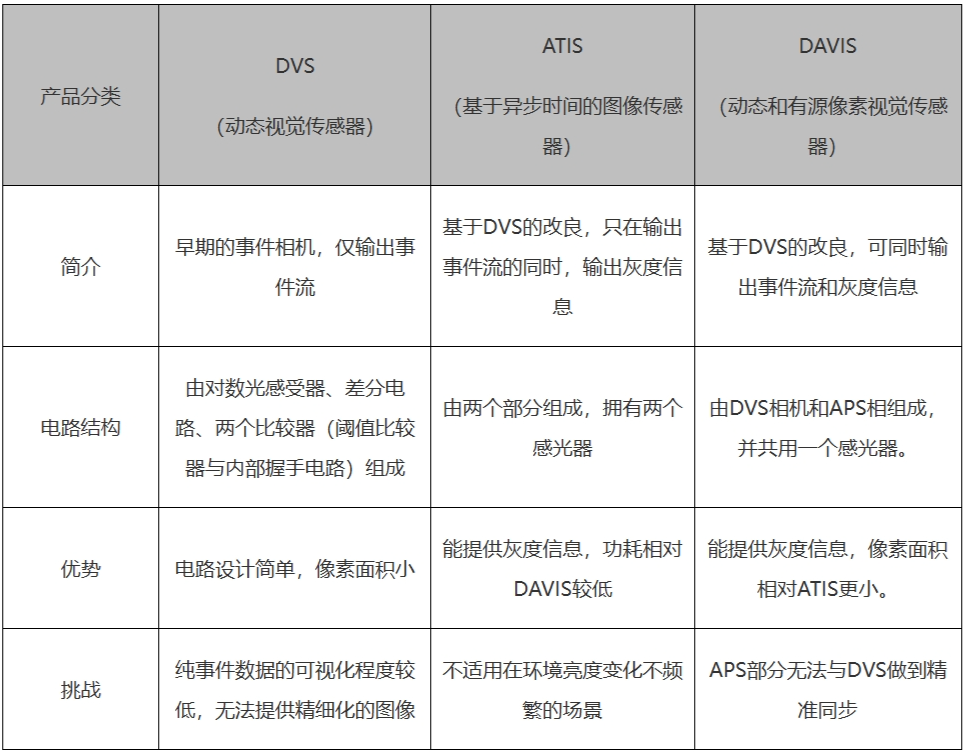
目前被廣泛應用的事件相機可大致分為3類:
①動態視覺傳感器(DVS dynamic vision sensor),是最基本的也是最先發展的一種事件相機。
②基于異步時間的圖像傳感器(ATIS asynchronous time based image sensor),它的像素結構分成兩個部分(A和B),包含兩個感光器,能夠在提供事件信息的同時,還能提供一定灰度信息的需求。
③動態主動像素視覺傳感器(DAVIS dynamic and active pixel vision sensor),它將DVS相機和傳統的有源像素傳感器(APS)相機結合起來,能夠同時輸出場景事件和灰度信息。
傳統相機的缺點
幀率低、運動模糊、動態范圍低。
1、傳統相機,無論是CMOS傳感器,還是CCD傳感器,亦或是RGBD相機,都有一個參數:幀率。它們是以恒定的頻率拍攝獲取圖像。這樣,即使幀率能夠達到1KHz,那也具有1ms的延時。
2、傳統相機需要通過一定時間的曝光,使感光器件積累一定的光子,那么在曝光時間之內如果物體在高速運動,則會產生模糊。
3、傳統相機的動態范圍較低,具體表現為在光線極差或者亮度極高時,相機獲取的信息有限。
以上三點,是由于相機自身硬件的限制,即使高性能相機能夠一定程度減小這些問題,但由于相機原理,這些問題無法避免。這些問題極大地限制了一些應用場景。
事件相機的優點
低延遲、高動態范圍、數據量小、極低功耗。
由于事件相機的成像原理,我們可以發現只要亮度一有變化就會輸出,且僅輸出變化的數據占用了很小的帶寬,同時由于事件相機更擅長捕捉亮度變化,所以在較暗和強光場景下也能輸出有效數據。事件相機具有低延遲(
相較于傳統相機,事件相機是基于神經形態視覺,其基本理念是受生物系統工作方式的啟發,檢測場景動態的變化,而不是連續分析整個場景。這意味著讓單個像素決定它們是否看到了相關的東西。與固定頻率的系統采集相比,這種基于事件的方法可以節省大量的功耗,并減少延遲。
02
神經形態視覺傳感器發展歷程
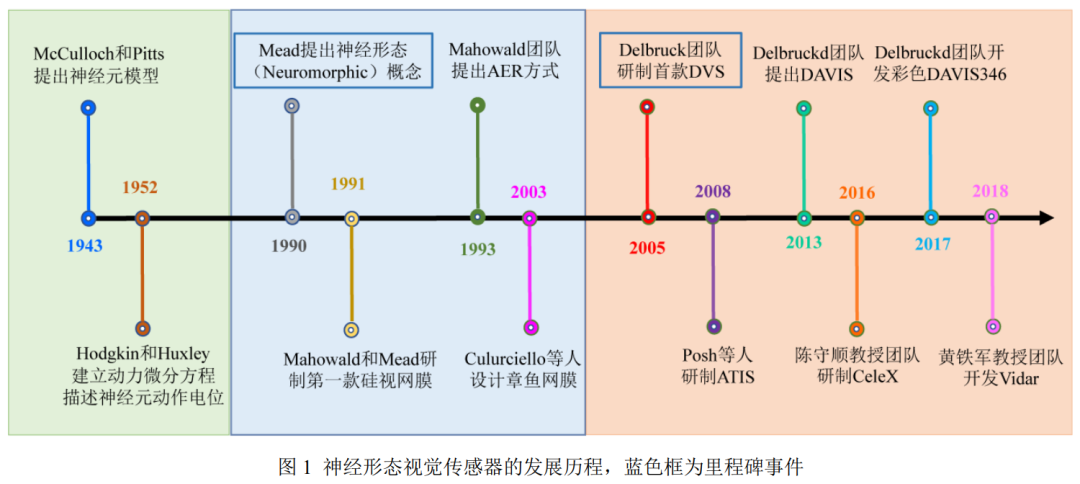
1943 年提出一種具有計算能力的神經元模型,1952年對神經元建立動力學微分方程描述神經元動作電位的產生與傳遞過程,這個動作電位就叫做脈沖。
1990 年首次在提出神經形態(Neuromorphic)的概念,利用大規模集成電路來模擬生物神經系統,1991 年第一款硅視網膜的誕生,其模擬了視網膜上一些細胞的生物功能,1993 年 提出了一種新型的集成電路通信協議,名叫地址事件協議(Address-Event Representation, AER ), 實現了事件的異步讀出。2003 年有團隊設計了一種 AER方式的積分發放的脈沖模型,將像素光強編碼為頻率或脈沖間隔, 稱為章魚視網膜( Octopus Retina)。
2005 年研制出動態視覺傳感器(Dynamic Vision Sensor, DVS),以時空異步稀疏的事件(Event)表示像素光強變化,2008年提出了一種基于異步視覺的圖像傳感器(Asynchronous Time-based Image Sensor, ATIS),引入了基于事件觸發的光強測量電路來重構變化處的像素灰度。
2013年開發了動態有源像素視覺傳感器 ( Dynamic and Active Pixel Vision Sensor, DAVIS),這是一種雙模的技術路線,增加額外獨立的傳統圖像采樣電路彌補 DVS 紋理成像的缺陷,隨后在2017年又將其擴展為彩色。
2016年采用了增加事件的位寬,讓事件攜帶像素光強信息輸出以恢復場景紋理。2018年有團隊采用了章魚視網膜的光強積分發放采樣原理,用脈沖平面傳輸替換 AER 方式以節約傳輸帶寬,驗證了積分型采樣原理可高速重構場景紋理細節,也稱 Vidar。
03
DVS的工作原理
發明DVS/EVS的靈感來源于對人眼視網膜細胞的解讀。
如下圖所示,簡而言之,人眼視網膜主要由三層細胞構成:感光細胞層主要負責感光/色。而雙極細胞則負責感光細胞的控制和"選擇性"讀取。輸出的信號沒什么特別的地方,和我們熟知的CIS系統沒有區別,但是CIS研發人員從這個“選擇性"讀取開始做文章,發現了有些不一樣的東西。由于視網膜上的細胞間信號是以"放電”的方式(具體細節請參考神經學等醫學書籍對神經元信號傳遞方式的描述)進行傳輸,因此與傳統CIS的4-APS像素不同,人眼視網膜玩的是電流,而非電壓。
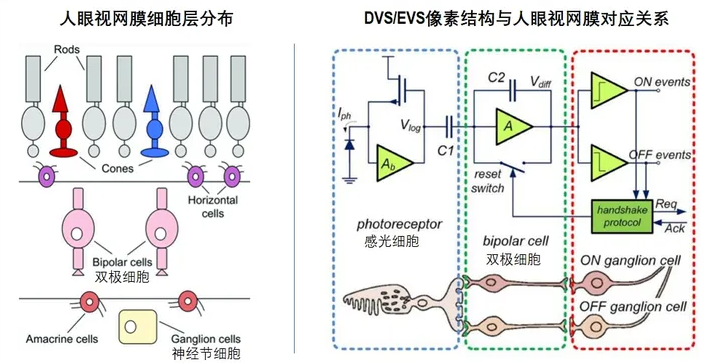
受此啟發,CIS研發人員對視網膜細胞間工作原理做了個等效的電路對應。感光細胞對應的是以電流作為感應輸出的Log像素電路。雙極細胞則為一個積分放大器對像素輸出的信號“極化"。之后神經元細胞對應的決斷電路對"極化”后信號進行“二進制"化,其決斷電路簡單來說就是1bit的ADC。

整個鏈路工作效果如下圖簡述:當光線被PPD感應后,偏置的PPD產生電流。電流的大小隨著光的強度變化而變化。值得一說的是,這個變化可不是線性變化,而是由電路設計呈Log函數曲線變化。光強變化越大,電流的增長量反而越小。因此鏈路中后面的一堆電路主要干的事情就是對電流變化跨過特定的閾值來進行決斷。在電流上升時,跨過某個閾值則決斷輸出+1信號。在電流下降時,則決斷輸出-1信號。閾值的單位大小可以調整,且跨過閾值這個動作叫做"事件"(Event)。簡單來說,就是感應電流變化大小。電流值每跨過一個單位閾值則決斷輸出一個事件信號,電流變化越大,則輸出的事件信號就越多。通過等效電路轉換等一連串操作,一個新的對光強變化進行感應的仿生CIS系統誕生,起名為DVS/EVS。
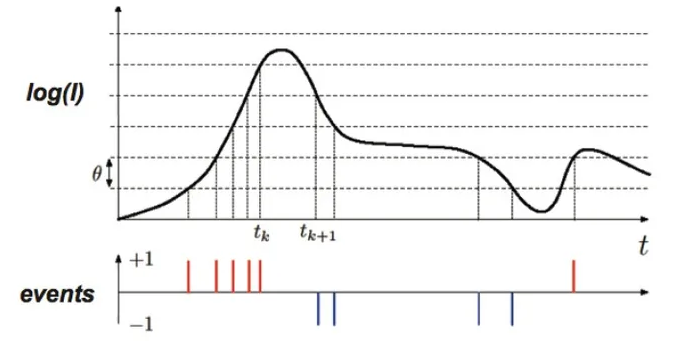
既然這種Sensor是對光強變化進行感應,那如果沒有光強變化或者光強變化很弱的話會怎么樣呢?答案很簡單,就是啥也不輸出。沒有光強變化或者變化太弱了,DVS/EVS就成了瞎子。
04
應用
事件相機可應用于特征跟蹤、SLAM、捕獵機器人,包括物聯網(超低功耗監控和智慧城市)、自動駕駛(車輛測距、SLAM和乘員監控)、機器人技術(場景理解與定位)、工業視覺(過程監控和基礎設施檢測)等。
事件相機在自動駕駛領域的應用
事件相機具備極快的響應速度、減少無效信息、降低算力和功耗、高動態范圍等優勢,可以幫助自動駕駛車輛降低信息處理的復雜度、提高車輛的行駛安全,并能夠在極亮或者極暗環境下正常工作。
適合落地的場景:
第一,城區場景中的鬼探頭。傳統幀相機在面對橫向的鬼探頭場景時,無法快速做出反應,而事件相機可以更快的感知到危險信號。
第二,高速場景下的避障。比如車輛在高速路上快速行駛時,遇到前方路面有一個輪胎,幀相機不能及時做出反應,而事件相機可以依靠它的低時延性優勢,快速識別出前方的輪胎,并及時做出避障動作。
第三,光線過亮或者過暗的場景。比如在深夜的環境下,幀相機由于周圍極暗的光線而無法識別周圍事物,而事件相機依然可以有效的識別周圍事物。
第四,光強突變較為明顯的場景。比如車輛從隧道出來后,面對高曝光的場景,幀相機會受到高爆光的影響,從而產生失效的工況,而事件相機不會受到影響。
不適合落地的場景:
主要是在城區場景的某些工況下,比如車輛前方有無數行人在穿插過馬路。再或者一些惡劣天氣環境下,比如大雨、大雪、沙塵等。
以上兩種場景下,前方的目標物都存在數量多且無規律運動的特點,這會對事件相機產生很多無效的噪點。
05
挑戰
技術層面
1)無法識別具體目標物:幀相機輸出的是幀圖像,并且已擁有了成熟的應用和標定數據庫;而事件相機只能給出比較原始的數據信息,比如目標物的外部輪廓,并且也沒有一個自己獨立的數據庫來匹配這些輪廓信息。若想要得到更深層次的信息,仍需要幀相機作為輔助,比如先從事件相機識別出前方雪糕筒的形狀,而后在經過神經網絡算法的訓練后,發現該形狀與之前的雪糕筒相似,從而判斷出前方物體具體是什么。
2)缺少合適的芯片和算法:當前事件相機使用的是原來幀相機的一整套架構體系(比如所使用的芯片類型、算法模型等),但基于幀圖像的架構并不能完全處理好事件流,而現有的大部分事件相機產品只是做了簡單的架構平移。但兩者的工作原理完全不同,若只是簡單的架構平移,就如同將一臺普通的轎車引擎裝在一輛超跑上。
工程層面
1)閾值設定難度高:閾值是衡量事件輸出的標準,當目標物的光強變化量(亮度由低到高或者由高到低)超過預設的閾值就會產生事件。其基本的原理是:通過調整閾值可以改變相機對噪點的敏感度,當閾值越大時,相機對噪點越不敏感,能捕捉到的事件也會越少;當閾值越小時,能捕捉到的事件也會越多。在自動駕駛領域,具體如何設定閾值也是一個難題:一方面,車在行駛過程中,與周圍的事物始終保持著相對運動,隨著物體表面光強亮度的變化就會一直有事件產生,此時閾值應該越大,從而減少噪點;另一方面,事件數據的特點是具有稀疏性(比如一個靜止的物體,事件相機只會在t0時刻產生事件,之后就不會有新的事件產生),從冗余安全的角度來看,為了降低數據過少的風險,閾值應該越小
2)數據處理效率低:幀相機處理數據的原理,是在等整張圖像處理完了后才能做出決策;而事件相機的數據處理原理是出現一個事件就處理掉一個事件,然后快速地做出決策。但當前的商業應用中,市場上還沒有針對事件數據處理的成熟方法,所以已有的事件相機產品都是采用幀相機的數據處理方式來處理事件數據。舉例來說,若一個事件相機在60秒內,只有在第60秒才產生一個事件。此時,我們按照30幀的幀率去處理事件數據,就需要將60秒的數據切割成每30秒一組數據,然后在傳統的神經網絡算法模型下進行運算,可以發現,前一組30秒數據并沒有事件產生,但在傳統網絡模型下前一組數據也必須要進行運算,這就違背了事件相機的處理數據原理,讓其喪失了低時延的優勢。
3)與其他傳感器融合的挑戰:由于事件相機無法單獨提供深層次的數據,比如測距、測速、表面具體顏色等,只能獲取到物體的輪廓,所以單純地使用一個事件相機是無法給到自動駕駛車輛足夠的冗余安全,與其他傳感器的融合才是更好的感知方案。在與其它傳感器融合時,需要把事件流與其它傳感器的信號進行同步匹配。以事件相機與激光雷達的融合為例,事件相機與激光雷達都有幀的概念,激光雷達也是以某一恒定幀率發射點云。若想要把這兩個傳感器同步起來,就需要做到兩個方面:一方面,時間戳的一一對應;另一方面,需要在做好標定的基礎上,將事件相機的像素點云映射到激光雷達的點云上。
商業層面
1)應用場景仍較少:在現有相機體系越來越成熟的趨勢下,當前事件相機能給自動駕駛能帶來的增量價值過小,并且它只能通過與其它傳感器融合使用才能發揮更大的價值,但作為新型傳感器在進入市場前,事件相機需要經歷漫長的場景功能開發,從而慢慢挖掘出一些它的潛在價值。
2)供應鏈體系不成熟:供應鏈體系不成熟。事件相機處在早期發展階段,產品的標準化程度較低,在推廣過程中不得不提供一整套解決方案,導致產品的成本較高。以事件相機的算法開發供應商為例,某自動駕駛公司傳感器專家提到,現有的事件相機相關的算法開發商,主要是以demo為主,沒有針對特定場景去做配套算法的開發。
06
展望
因為找的一些詳細講事件相機的文獻、資料大多數是兩三年前的了,所以隨著時間推移,人們對于它的探索和發展也有了進一步提升。
在時間域上取值是連續的,但在值域的取值是離散的,這一點也有別于常見的數字信號。這樣的數據在處理時已經完全不能用傳統RGB相機的方法處理了。但是它仍然能夠完成傳統相機所能完成的任務,如光流估計、特征提取、三維重建、模式識別、SLAM等。
未來一定是將兩種相機各取其長,發揮最大價值。
審核編輯:彭菁
-
圖像傳感器
+關注
關注
68文章
1886瀏覽量
129464 -
感光器
+關注
關注
0文章
6瀏覽量
7642 -
視覺傳感器
+關注
關注
3文章
248瀏覽量
22857
原文標題:事件相機綜述
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

賽普拉斯具有13.2Gbps數據吞吐能力的CMOS圖像傳感器
賽普拉斯面向機器視覺市場的高靈敏度高速CMOS圖像傳感器
全幀讀出型面陣CCD光電傳感器在圖像采集中的應用
數字傳感器輸出信號_數字傳感器輸出方式
PWM輸出傳感器如何工作 模擬輸出傳感器如何工作

視覺傳感器在智能網聯汽車中應用 如何選擇視覺傳感器

如何選擇機器視覺傳感器






 工商網監
工商網監
評論