 目標檢測算法YOLO的發展史和原理
目標檢測算法YOLO的發展史和原理
01YOLO發展史
大家或許知道,首字母縮寫YOLO在英文語境下較為流行的含義,即You Only Live Once,你只能活一次。我們今天要介紹的YOLO卻有著與前者不一樣的含義。在算法的世界中,YOLO寓意You Only Look Once,你只需要看一眼——這不失為一種來自開發者的羅曼蒂克。
在講解YOLO的算法原理之前,先簡要介紹YOLO的發展史。YOLO開創了一階段檢測算法的先河。它將目標分類和定位用一個神經網絡統一起來,實現了端到端的目標檢測。
YOLO檢測系統
YOLO最初于2016年由華盛頓大學的博士研究生Joseph Redmon提出。Joseph Redmon的這篇提出YOLO的論文You Only Look Once: Unified, Real-Time Object Detection也發表在了CVPR 2016上,并獲得了CVPR 2016的最佳人氣獎。自此,Joseph Redmon開始不斷推出YOLO的新版本,YOLO也在不斷的迭代中越來越強。
2017年,Joseph Redmon與導師合著發表了論文YOLO9000: Better, Faster, Stronger,這篇論文也標志著YOLO v2的誕生。該論文獲得了CVPR 2017最佳論文榮譽提名獎。YOLO v2能夠檢測9000中不同的對象,因此也被稱為YOLO9000。
2018年,Joseph Redmon又提出了YOLO新版本YOLO v3,這一版本的YOLO在保持原有算法的速度優勢的同時,提升了模型的精度,補齊了小目標檢測以及重疊遮擋目標識別的短板。雖然,Joseph Redmon在2020年出于個人對職業倫理恪守的原因終止了CV研究,但之后便出現新的YOLO維護者繼續接手YOLO的進一步研發項目。
02YOLO算法原理
YOLO的核心理念是:把目標檢測問題轉換為直接從圖像中提取邊界框和類別概率的單回歸問題,即一次就可檢測出目標的類別和位置。正因如此,YOLO模型的運行速度非常快 ,從而可以滿足實時性應用要求。
YOLO模型做統一檢測(unified detection)的流程為:
YOLO模型
首先,把輸入圖像分成S×S個小格子。每個格子預測N個邊界框,每個邊界框用五個預測值表示:x,y,w,h和confidence(置信度)。其中,(x,y)是邊界框的中心坐標,w和h是邊界框的寬度和高度,這四個值都被歸一化到[0,1]區間以便于訓練。
置信度會對當前邊界框中存在目標的可能性Pr(Object)以及預測框與真實框的交并比進行綜合考慮,即

其中

根據以上定義,若一個框內沒有物體,則confidence = 0,反之則confidence等于交并比。我們在訓練時可以計算出每一個框的置信度。
其次,我們要預測每個格子分別屬于每種目標類別的條件概率(|),其中 = 0,1,…,C,其中C是數據集中目標類別的數量。
在測試時,屬于某個格子的N個邊界框共享C個類別的條件概率,則每個邊界框屬于某個目標類別的置信度(類別置信度)為
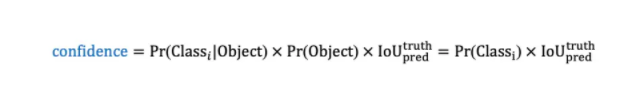
最后,我們會輸出一個維度為S×S×(N×5+C) 的張量(tensor)。在此需要提示的是,5代表的是在第一步中對應的五個預測值,且因為每個格子的N個邊界框是共享C個類別的條件概率的,因此在張量維度大小的計算公式中,我們在N×5與C之間采用的運算是加法而非乘法。
YOLO使用PASCALVOC檢測數據集。YOLO將圖像分為7×7=49個小格子,其中,每個格子里有兩個邊界框,即S=7,N=2。因為VOC數據集中有20種類別,因此C=20。最終的預測結果是一個7×7×30的張量。
YOLO借鑒了GoogLeNet的設計思想,其網絡結構中包括24個卷積層和2個全連接層。YOLO沒有使用Inception模塊,而是直接用1×1卷積層及隨后的3×3卷積層。YOLO的最終輸出是7×7×30的張量。
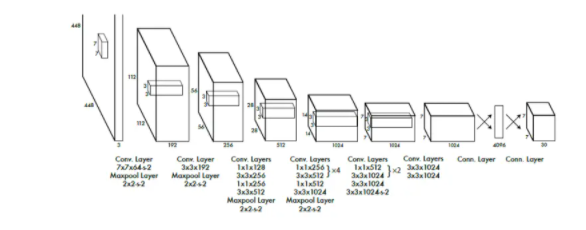
YOLO網絡結構
需要強調的是,上圖中出現在數字右下角的“-s-2”的下標代表該卷積層或池化層的stride(步距)為2。
此外,YOLO使用Leaky ReLU作為激活函數,即
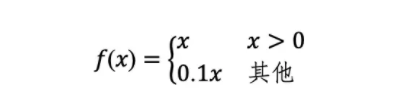
總言之,YOLO算法通過把“統一檢測候選框與類別概率”的思想和 “用一個卷積神經網絡來實現”的操作結合,從而開創了一階段目標檢測算法。
03YOLO算法的閃光點與局限性
相對于傳統目標檢測算法而言, 使用統一檢測模型的YOLO的閃光點在于:
其一,檢測速度非常快。YOLO將目標檢測重建為單一回歸問題從而對輸入圖像直接處理。此外,還同時輸出邊界框坐標和分類概率,而且每張圖像只預測98個邊界框。因此,YOLO的檢測速度非常快。其中,YOLO在Titan X GPU上的檢測速度能達到45幀/秒,Fast YOLO的檢測速度則可以達到155幀/秒。
其二,背景誤判少。以往基于滑動窗口或候選區域提取的目標檢測算法只能看到圖像的局部信息,因此會把圖像背景誤認為檢測目標。而YOLO在訓練和測試時每個格子都可以看到全局信息,因此不容易把圖像背景預測為目標。
其三,泛化性更好。YOLO能夠學習到目標的泛化表示,從而能夠遷移到其他領域。在泛化能力上,YOLO的性能遠優于DPM、R-CNN等。
但除了以上閃光點外,YOLO也存在著局限性。雖然YOLO的目標檢測速度很快,但其預測精度不是很高。究其原因,主要是由于——
其一,YOLO的每個格子只能預測兩個邊界框和一種目標的分類。YOLO將一張圖像均分為49個格子,若在同一單元格內存在多個物體的中心,那么該單元格內只能預測出一個類別的物體,并丟掉其他的物體,從而降低了預測精度。
其二,損失函數的設計過于簡單。雖然邊界框的坐標和分類表征的內容不同,但YOLO都用其均方誤差作為損失函數。
其三,YOLO直接預測邊界框的坐標位置,這會導致模型不易訓練。
不過,以上在YOLO原版中出現的問題在后來的YOLO v2、YOLO v3等版本中都逐步得到了改進。
來源:新機器視覺
審核編輯:湯梓紅
-
檢測系統
+關注
關注
3文章
947瀏覽量
43014 -
檢測算法
+關注
關注
0文章
119瀏覽量
25212 -
目標檢測
+關注
關注
0文章
204瀏覽量
15590 -
數據集
+關注
關注
4文章
1205瀏覽量
24641
原文標題:【光電智造】目標檢測算法YOLO的發展史及優勢
文章出處:【微信號:今日光電,微信公眾號:今日光電】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
恒壓變壓器的發展史
PowerPC小目標檢測算法怎么實現?
【大聯大世平Intel?神經計算棒NCS2試用申請】基于RK3399+Intel NCS2加速YOLO4目標檢測算法加速方案
5G的發展史

基于yolo算法進行改進的高效衛星圖像目標檢測算法
淺談紅外弱小目標檢測算法
基于Transformer的目標檢測算法






 工商網監
工商網監
評論