") 深度學(xué)習(xí)之后為何陷入了困境?
深度學(xué)習(xí)之后為何陷入了困境?
來(lái)源:datasciencecentral 編譯:Min
我們被困住了,或者說(shuō)至少我們已經(jīng)停滯不前了。有誰(shuí)還記得上一次一年沒有在算法、芯片或數(shù)據(jù)處理方面取得重大顯著進(jìn)展是什么時(shí)候?幾周前去參加Strata San Jose會(huì)議,卻沒有看到任何吸引眼球的新進(jìn)展,這太不尋常了。 正如我之前所報(bào)告的那樣,似乎我們已經(jīng)進(jìn)入了成熟期,現(xiàn)在我們的主要工作目標(biāo)是確保我們所有強(qiáng)大的新技術(shù)能夠很好地結(jié)合在一起(融合平臺(tái)),或者從那些大規(guī)模的VC投資中賺取相同的錢。
我不是唯一一個(gè)注意到這些的人。幾位與會(huì)者和參展商都和我說(shuō)了非常類似的話。而就在前幾天,我收到了一個(gè)由知名研究人員組成的團(tuán)隊(duì)的說(shuō)明,他們一直在評(píng)估不同高級(jí)分析平臺(tái)的相對(duì)優(yōu)點(diǎn),并得出結(jié)論:沒有任何值得報(bào)告的差異。
我們?yōu)槭裁春驮谀睦锵萑肜Ь常?/strong>
我們現(xiàn)在所處的位置其實(shí)并不差。我們過(guò)去兩三年的進(jìn)步都是在深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)領(lǐng)域。深度學(xué)習(xí)在處理語(yǔ)音、文本、圖像和視頻方面給我們帶來(lái)了了不起的能力。再加上強(qiáng)化學(xué)習(xí),我們?cè)谟螒颉⒆灾鬈囕v、機(jī)器人等方面都有了很大的進(jìn)步。 我們正處于商業(yè)爆炸的最早階段,基于諸如通過(guò)聊天機(jī)器人與客戶互動(dòng)來(lái)節(jié)省大量資金、個(gè)人助理和Alexa等新的個(gè)人便利應(yīng)用、個(gè)人汽車中的二級(jí)自動(dòng)化,比如自適應(yīng)巡航控制、事故避免制動(dòng)和車道維護(hù)。 Tensorflow、Keras和其他深度學(xué)習(xí)平臺(tái)比以往任何時(shí)候都更容易獲得,而且由于GPU的存在,比以往任何時(shí)候都更高效。 但是,已知的缺陷清單根本沒有解決:
需要太多標(biāo)簽化的訓(xùn)練數(shù)據(jù)。
模型的訓(xùn)練時(shí)間太長(zhǎng)或者需要太多昂貴的資源,而且還可能根本無(wú)法訓(xùn)練。
超參數(shù),尤其是圍繞節(jié)點(diǎn)和層的超參數(shù),仍然是神秘的。自動(dòng)化甚至是公認(rèn)的經(jīng)驗(yàn)法則仍然遙不可及。
遷移學(xué)習(xí),意味著只能從復(fù)雜到簡(jiǎn)單,而不是從一個(gè)邏輯系統(tǒng)到另一個(gè)邏輯系統(tǒng)。
我相信我們可以列一個(gè)更長(zhǎng)的清單。正是在解決這些主要的缺點(diǎn)方面,我們已經(jīng)陷入了困境。
是什么阻止了我們
在深度神經(jīng)網(wǎng)絡(luò)中,目前的傳統(tǒng)觀點(diǎn)是,只要我們不斷地推動(dòng),不斷地投資,那么這些不足就會(huì)被克服。例如,從80年代到00年代,我們知道如何讓深度神經(jīng)網(wǎng)絡(luò)工作,只是我們沒有硬件。一旦趕上了,那么深度神經(jīng)網(wǎng)絡(luò)結(jié)合新的開源精神,就會(huì)打開這個(gè)新的領(lǐng)域。 所有類型的研究都有自己的動(dòng)力。特別是一旦你在一個(gè)特定的方向上投入了大量的時(shí)間和金錢,你就會(huì)一直朝著這個(gè)方向前進(jìn)。如果你已經(jīng)投入了多年的時(shí)間來(lái)發(fā)展這些技能的專業(yè)知識(shí),你就不會(huì)傾向于跳槽。 改變方向,即使你不完全確定應(yīng)該是什么方向。 有時(shí)候我們需要改變方向,即使我們不知道這個(gè)新方向到底是什么。最近,領(lǐng)先的加拿大和美國(guó)AI研究人員做到了這一點(diǎn)。他們認(rèn)為他們被誤導(dǎo)了,需要從本質(zhì)上重新開始。 這一見解在去年秋天被Geoffrey Hinton口頭表達(dá)出來(lái),他在80年代末啟動(dòng)神經(jīng)網(wǎng)絡(luò)主旨研究的過(guò)程中功不可沒。Hinton現(xiàn)在是多倫多大學(xué)的名譽(yù)教授,也是谷歌的研究員,他說(shuō)他現(xiàn)在 "深深地懷疑 "反向傳播,這是DNN的核心方法。觀察到人腦并不需要所有這些標(biāo)簽數(shù)據(jù)來(lái)得出結(jié)論,Hinton說(shuō) "我的觀點(diǎn)是把這些數(shù)據(jù)全部扔掉,然后重新開始"。 因此,考慮到這一點(diǎn),這里是一個(gè)簡(jiǎn)短的調(diào)查,這些新方向介于確定可以實(shí)現(xiàn)和幾乎不可能實(shí)現(xiàn)之間,但不是我們所知道的深度神經(jīng)網(wǎng)的增量改進(jìn)。 這些描述有意簡(jiǎn)短,無(wú)疑會(huì)引導(dǎo)你進(jìn)一步閱讀以充分理解它們。
看起來(lái)像DNN卻不是的東西
有一條研究路線與Hinton的反向傳播密切相關(guān),即認(rèn)為節(jié)點(diǎn)和層的基本結(jié)構(gòu)是有用的,但連接和計(jì)算方法需要大幅修改。
我們從Hinton自己目前新的研究方向——CapsNet開始說(shuō)起是很合適的。這與卷積神經(jīng)網(wǎng)絡(luò)的圖像分類有關(guān),問(wèn)題簡(jiǎn)單來(lái)說(shuō),就是卷積神經(jīng)網(wǎng)絡(luò)對(duì)物體的姿勢(shì)不敏感。也就是說(shuō),如果要識(shí)別同一個(gè)物體,在位置、大小、方向、變形、速度、反射率、色調(diào)、紋理等方面存在差異,那么必須針對(duì)這些情況分別添加訓(xùn)練數(shù)據(jù)。 在卷積神經(jīng)網(wǎng)絡(luò)中,通過(guò)大量增加訓(xùn)練數(shù)據(jù)和(或)增加最大池化層來(lái)處理這個(gè)問(wèn)題,這些層可以泛化,但只是損失實(shí)際信息。 下面的描述是眾多優(yōu)秀的CapsNets技術(shù)描述之一,該描述來(lái)自Hackernoon。
Capsule是一組嵌套的神經(jīng)層。在普通的神經(jīng)網(wǎng)絡(luò)中,你會(huì)不斷地添加更多的層。在CapsNet中,你會(huì)在一個(gè)單層內(nèi)增加更多的層。或者換句話說(shuō),把一個(gè)神經(jīng)層嵌套在另一個(gè)神經(jīng)層里面。capsule里面的神經(jīng)元的狀態(tài)就能捕捉到圖像里面一個(gè)實(shí)體的上述屬性。一個(gè)膠囊輸出一個(gè)向量來(lái)代表實(shí)體的存在。向量的方向代表實(shí)體的屬性。該向量被發(fā)送到神經(jīng)網(wǎng)絡(luò)中所有可能的父代。預(yù)測(cè)向量是基于自身權(quán)重和權(quán)重矩陣相乘計(jì)算的。哪個(gè)父代的標(biāo)量預(yù)測(cè)向量乘積最大,哪個(gè)父代就會(huì)增加膠囊的結(jié)合度。其余的父代則降低其結(jié)合度。這種通過(guò)協(xié)議的路由方式優(yōu)于目前的max-pooling等機(jī)制。
CapsNet極大地減少了所需的訓(xùn)練集,并在早期測(cè)試中顯示出卓越的圖像分類性能。
多粒度級(jí)聯(lián)森林
2月份,我們介紹了南京大學(xué)新型軟件技術(shù)國(guó)家重點(diǎn)實(shí)驗(yàn)室的周志華和馮霽的研究,展示了他們稱之為多粒度級(jí)聯(lián)森林的技術(shù)。他們的研究論文顯示,多粒度級(jí)聯(lián)森林在文本和圖像分類上都經(jīng)常擊敗卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)。效益相當(dāng)顯著。
只需要訓(xùn)練數(shù)據(jù)的一小部分。
在您的桌面CPU設(shè)備上運(yùn)行,無(wú)需GPU。
訓(xùn)練速度一樣快,在許多情況下甚至更快,適合分布式處理。
超參數(shù)少得多,在默認(rèn)設(shè)置下表現(xiàn)良好。
依靠容易理解的隨機(jī)森林,而不是完全不透明的深度神經(jīng)網(wǎng)。
簡(jiǎn)而言之,gcForest(多粒度級(jí)聯(lián)森林)是一種決策樹集合方法,其中保留了深網(wǎng)的級(jí)聯(lián)結(jié)構(gòu),但不透明的邊緣和節(jié)點(diǎn)神經(jīng)元被隨機(jī)森林組與完全隨機(jī)的樹林配對(duì)取代。在我們的原文中閱讀更多關(guān)于gcForest的內(nèi)容。
Pyro and Edward
Pyro和Edward是兩種新的編程語(yǔ)言,它們?nèi)诤狭松疃葘W(xué)習(xí)框架和概率編程。Pyro是Uber和Google的作品,而Edward則來(lái)自哥倫比亞大學(xué),由DARPA提供資金。其結(jié)果是一個(gè)框架,允許深度學(xué)習(xí)系統(tǒng)衡量他們對(duì)預(yù)測(cè)或決策的信心。 在經(jīng)典的預(yù)測(cè)分析中,我們可能會(huì)通過(guò)使用對(duì)數(shù)損失作為健身函數(shù)來(lái)處理這個(gè)問(wèn)題,懲罰有信心但錯(cuò)誤的預(yù)測(cè)(假陽(yáng)性)。到目前為止,還沒有用于深度學(xué)習(xí)的必然結(jié)果。 例如,這有望使用的地方是在自動(dòng)駕駛汽車或飛機(jī)中,允許控制在做出關(guān)鍵或致命的災(zāi)難性決定之前有一些信心或懷疑感。這當(dāng)然是你希望你的自主Uber在你上車之前就知道的事情。 Pyro和Edward都處于開發(fā)的早期階段。
不像深網(wǎng)的方法
我經(jīng)常會(huì)遇到一些小公司,他們的平臺(tái)核心是非常不尋常的算法。在我追問(wèn)的大多數(shù)案例中,他們都不愿意提供足夠的細(xì)節(jié),甚至讓我為你描述里面的情況。這種保密并不能使他們的效用失效,但是在他們提供一些基準(zhǔn)和一些細(xì)節(jié)之前,我無(wú)法真正告訴你里面發(fā)生了什么。當(dāng)他們最終揭開面紗的時(shí)候,就把這些當(dāng)作我們未來(lái)的工作臺(tái)吧。 目前,我所調(diào)查的最先進(jìn)的非DNN算法和平臺(tái)是這樣的。
層次時(shí)間記憶(HTM)
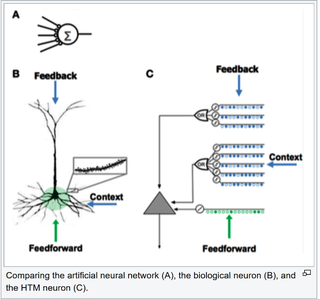
層次時(shí)間記憶(HTM)使用稀疏分布式表示法(SDR)對(duì)大腦中的神經(jīng)元進(jìn)行建模,并進(jìn)行計(jì)算,在標(biāo)量預(yù)測(cè)(商品、能源或股票價(jià)格等未來(lái)值)和異常檢測(cè)方面優(yōu)于CNN和RNN。 這是Palm Pilot名宿Jeff Hawkins在其公司Numenta的奉獻(xiàn)作品。霍金斯在對(duì)大腦功能進(jìn)行基礎(chǔ)研究的基礎(chǔ)上,追求的是一種強(qiáng)大的人工智能模型,而不是像DNN那樣用層和節(jié)點(diǎn)來(lái)結(jié)構(gòu)。 HTM的特點(diǎn)是,它發(fā)現(xiàn)模式的速度非常快,只需1,000次觀測(cè)。這與訓(xùn)練CNN或RNN所需的幾十萬(wàn)或幾百萬(wàn)次的觀測(cè)相比,簡(jiǎn)直是天壤之別。 此外,模式識(shí)別是無(wú)監(jiān)督的,并且可以根據(jù)輸入的變化來(lái)識(shí)別和概括模式的變化。這使得系統(tǒng)不僅訓(xùn)練速度非常快,而且具有自學(xué)習(xí)、自適應(yīng)性,不會(huì)被數(shù)據(jù)變化或噪聲所迷惑。
一些值得注意的漸進(jìn)式改進(jìn)
我們開始關(guān)注真正的游戲改變者,但至少有兩個(gè)漸進(jìn)式改進(jìn)的例子值得一提。這些顯然仍然是經(jīng)典的CNN和RNNs,具有反向支撐的元素,但它們工作得更好
使用Google Cloud AutoML進(jìn)行網(wǎng)絡(luò)修剪 谷歌和Nvidia的研究人員使用了一種名為網(wǎng)絡(luò)修剪的過(guò)程,通過(guò)去除對(duì)輸出沒有直接貢獻(xiàn)的神經(jīng)元,讓神經(jīng)網(wǎng)絡(luò)變得更小,運(yùn)行效率更高。這一進(jìn)步最近被推出,作為谷歌新的AutoML平臺(tái)性能的重大改進(jìn)。
Transformer
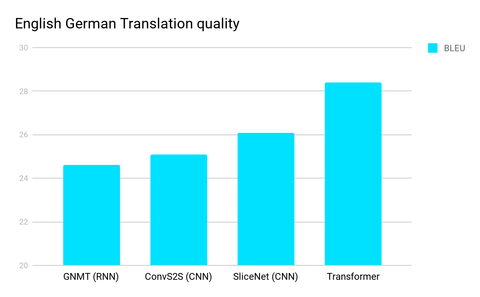
Transformer是一種新穎的方法,最初在語(yǔ)言處理中很有用,比如語(yǔ)言到語(yǔ)言的翻譯,這一直是CNNs、RNNs和LSTMs的領(lǐng)域。去年夏末由谷歌大腦和多倫多大學(xué)的研究人員發(fā)布,它在各種測(cè)試中都表現(xiàn)出了顯著的準(zhǔn)確性改進(jìn),包括這個(gè)英語(yǔ)/德語(yǔ)翻譯測(cè)試。 RNNs的順序性使其更難充分利用現(xiàn)代快速計(jì)算設(shè)備(如GPU),因?yàn)镚PU擅長(zhǎng)的是并行而非順序處理。CNN比RNN的順序性要差得多,但在CNN架構(gòu)中,隨著距離的增加,將輸入的遠(yuǎn)端部分的信息組合起來(lái)所需的步驟數(shù)仍然會(huì)增加。 準(zhǔn)確率的突破來(lái)自于 "自注意功能 "的開發(fā),它將步驟大幅減少到一個(gè)小的、恒定的步驟數(shù)。在每一個(gè)步驟中,它都應(yīng)用了一種自我關(guān)注機(jī)制,直接對(duì)一句話中所有詞之間的關(guān)系進(jìn)行建模,而不管它們各自的位置如何。 就像VC說(shuō)的那樣,也許是時(shí)候該換換口味了。
編輯:黃飛
-
cpu
+關(guān)注
關(guān)注
68文章
10829瀏覽量
211183 -
gpu
+關(guān)注
關(guān)注
28文章
4703瀏覽量
128725 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22176 -
隨機(jī)森林
+關(guān)注
關(guān)注
1文章
22瀏覽量
4262
原文標(biāo)題:深度學(xué)習(xí)之后會(huì)是啥?
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NPU在深度學(xué)習(xí)中的應(yīng)用
GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
深度學(xué)習(xí)中的時(shí)間序列分類方法
深度學(xué)習(xí)中的無(wú)監(jiān)督學(xué)習(xí)方法綜述
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度學(xué)習(xí)中的模型權(quán)重
深度學(xué)習(xí)常用的Python庫(kù)
深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)的對(duì)比
深度解析深度學(xué)習(xí)下的語(yǔ)義SLAM

人才流失,被迫站隊(duì),韓國(guó)半導(dǎo)體產(chǎn)業(yè)陷入困境
為什么深度學(xué)習(xí)的效果更好?

TLE9879 blinky的測(cè)試程序陷入了無(wú)法初始化BOARD1的循環(huán)中怎么解決?
什么是深度學(xué)習(xí)?機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的主要差異

GPU在深度學(xué)習(xí)中的應(yīng)用與優(yōu)勢(shì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論