 哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型
哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型
一句話總結
通過應用視覺專家進行工業異常檢測,以實現明確的異常檢測和高質量的異常描述,還可進行多輪對話,性能表現出色!優于AnomalyGPT等網絡,代碼即將開源!
Myriad

Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection
單位:哈工大(左旺孟團隊), 琶洲實驗室
論文:https://arxiv.org/abs/2310.19070
代碼:https://github.com/tzjtatata/Myriad
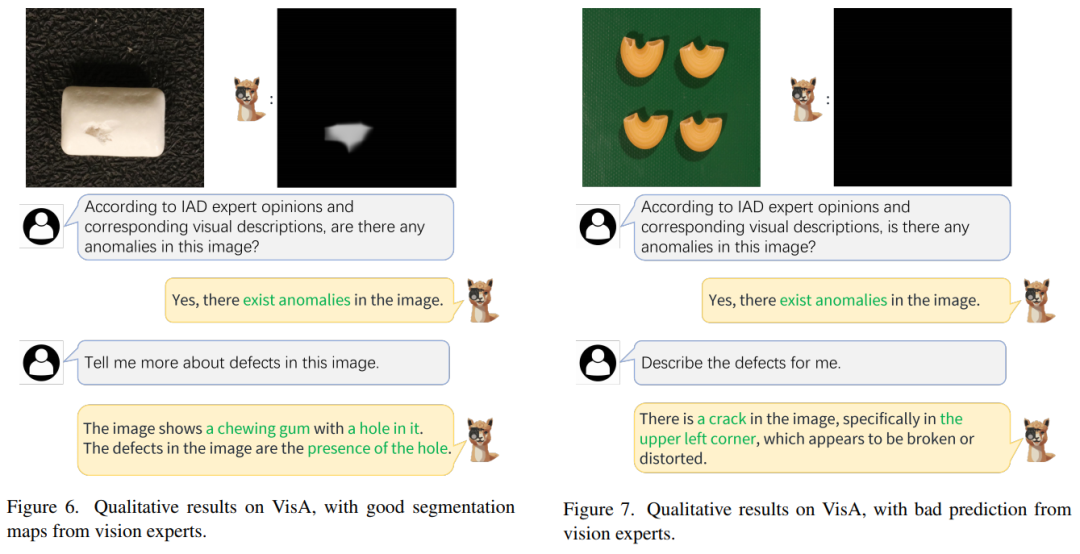
現有的工業異常檢測(IAD)方法可以預測異常檢測和定位的異常分數。然而,它們很難對異常區域進行多輪對話和詳細描述,例如工業異常的顏色、形狀和類別。
最近,大型多模態(即視覺和語言)模型(LMM)在圖像描述、視覺理解、視覺推理等多種視覺任務上表現出了卓越的感知能力,使其成為更易于理解的異常檢測的有競爭力的潛在選擇。然而,現有的通用 LMM 中缺乏有關異常檢測的知識,而訓練特定的 LMM 進行異常檢測需要大量的注釋數據和大量的計算資源。
本文提出了一種新穎的大型多模態模型,通過應用視覺專家進行工業異常檢測(稱為Myriad),從而實現明確的異常檢測和高質量的異常描述。
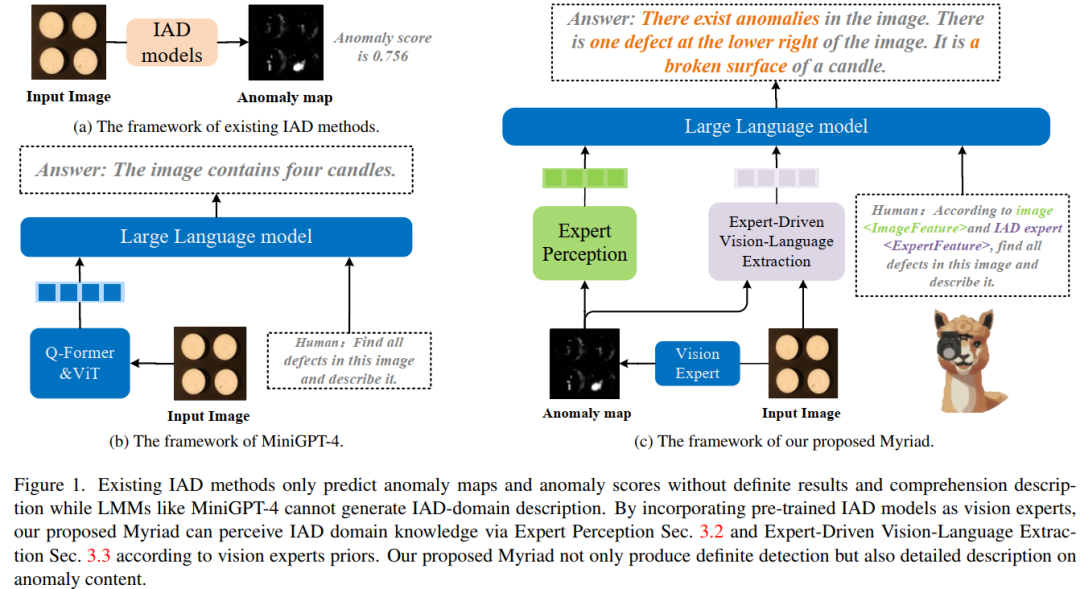
具體來說,采用 MiniGPT-4 作為基礎 LMM,并設計一個專家感知模塊,將視覺專家的先驗知識嵌入到大型語言模型(LLM)可以理解的標記中。
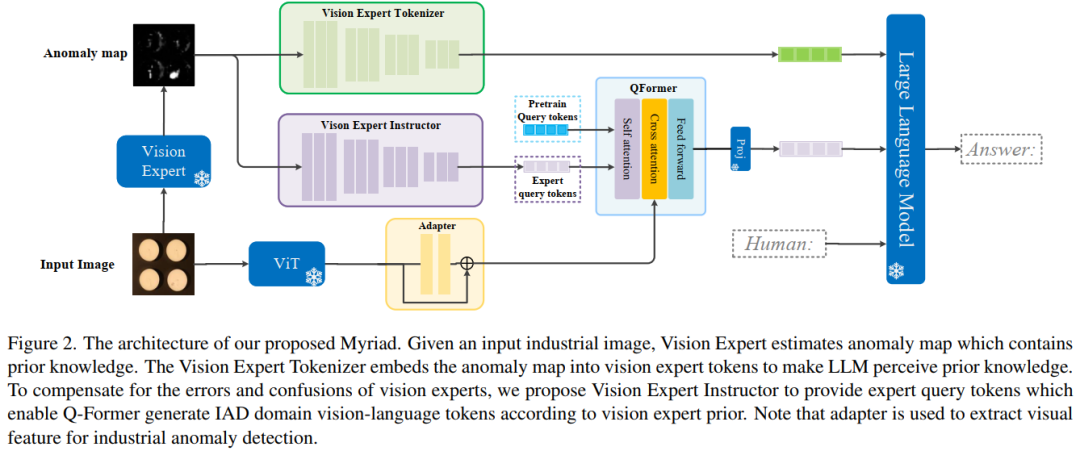
為了彌補視覺專家的錯誤和困惑,引入了域適配器來彌合通用圖像和工業圖像之間的視覺表示差距。此外,提出了一個視覺專家講師,它使 Q-Former 能夠根據視覺專家先驗生成 IAD 領域視覺語言標記。
實驗結果
在MVTec-AD 和 VisA 基準上的大量實驗表明,本文提出的方法不僅在 1-class 和少樣本設置下比最先進的方法表現更好,而且還提供了明確的異常預測以及 IAD 中的詳細描述領域。
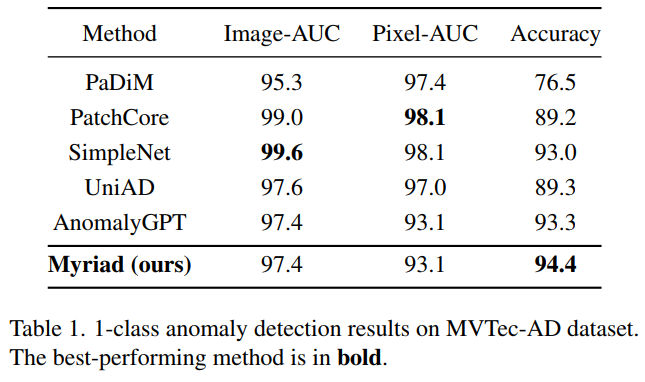
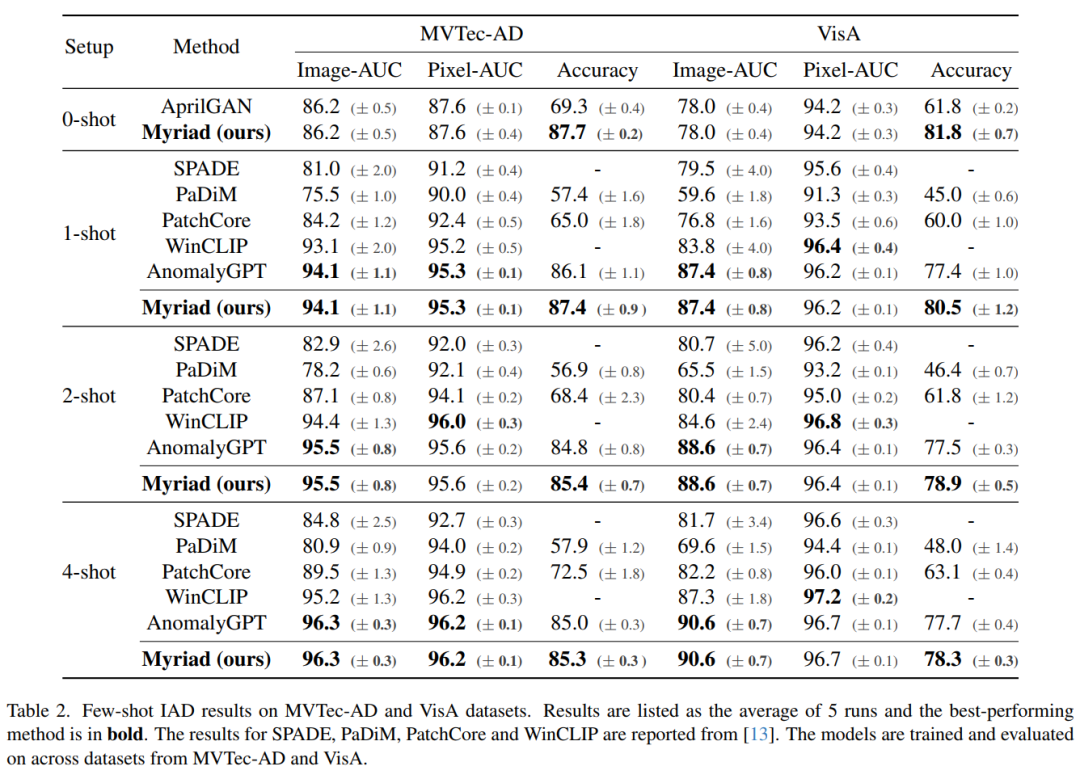

-
模型
+關注
關注
1文章
3178瀏覽量
48731 -
視覺
+關注
關注
1文章
146瀏覽量
23896 -
大模型
+關注
關注
2文章
2339瀏覽量
2501
原文標題:工業異常檢測大模型來了!哈工大提出Myriad:利用視覺專家進行工業異常檢測的大型多模態模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用OpenVINO部署Qwen2多模態模型
華工科技聯合哈工大實現國內首臺激光智能除草機器人落地
云知聲推出山海多模態大模型
聆思CSK6視覺語音大模型AI開發板入門資源合集(硬件資料、大模型語音/多模態交互/英語評測SDK合集)
智譜AI發布全新多模態開源模型GLM-4-9B
商湯科技發布5.0多模態大模型,綜合能力全面對標GPT-4 Turbo
李未可科技正式推出WAKE-AI多模態AI大模型

蘋果發布300億參數MM1多模態大模型
螞蟻推出20億參數多模態遙感模型SkySense
韓國Kakao宣布開發多模態大語言模型“蜜蜂”
機器人基于開源的多模態語言視覺大模型

基于DiAD擴散模型的多類異常檢測工作

自動駕駛和多模態大語言模型的發展歷程

從Google多模態大模型看后續大模型應該具備哪些能力
大模型+多模態的3種實現方法






 工商網監
工商網監
評論