 邁向更高效的圖像分類:解析DeiT模型的移植和適配
邁向更高效的圖像分類:解析DeiT模型的移植和適配
1. DeiT概述
1.1 項目簡介
Deit(Data-efficient image Transformers)是由Facebook與索邦大學的Matthieu Cord教授合作開發的圖像分類模型。作為一種基于Transformer架構的深度學習模型,DeiT在保持高性能的同時,能夠大大提高數據效率,為圖像識別領域帶來了顛覆性的變化。
與傳統的CNN不同,DeiT模型采用了Transformer的自注意力機制,將圖像分割成若干個固定大小的塊,并對每個塊進行編碼,捕捉圖像中的長程依賴關系。
本文將為大家介紹如何將DeiT移植到算能BM1684X平臺上。
1.2 模型介紹
DeiT目前有3個版本的模型(tiny, small, base),均由12個Attention結構組成,模型區別在于輸入的header個數及embed_dim不同。
Attention結構如下圖所示:
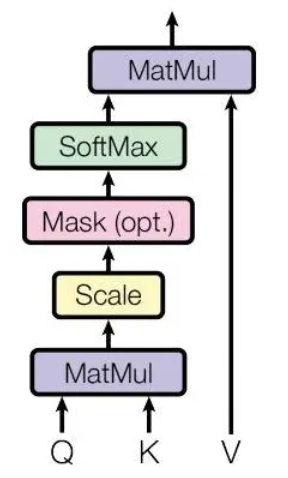 attention
attention
不同版本的模型具體參數區別如下表:
 version
version
2. 模型移植
以下部分介紹如何將DeiT移植到算能BM1684X平臺上。
2.1 模型trace
原始DeiT模型基于Pytorch框架訓練及推理。算能TPU-MLIR工具鏈可以編譯通過jit trace過的靜態模型。
首先進行模型trace,命令如下,需要修改原推理代碼。
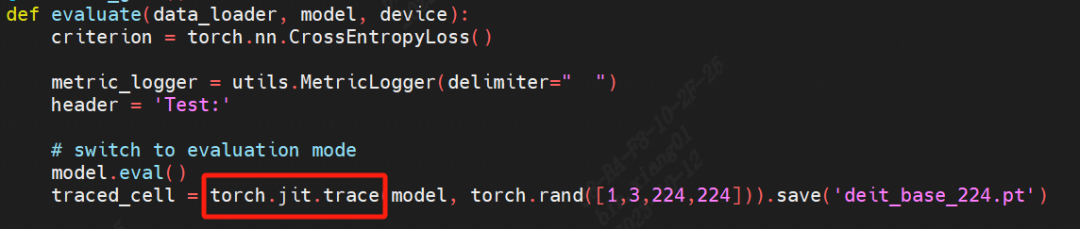 trace
trace
2.2 模型編譯
以下介紹如何使用算能TPU-MLIR工具鏈將上一步trace過的模型編譯成可以在算能BM1684X上推理的bmodel。在模型移植過程中遇到一些算子邊界的處理問題,均已修復。
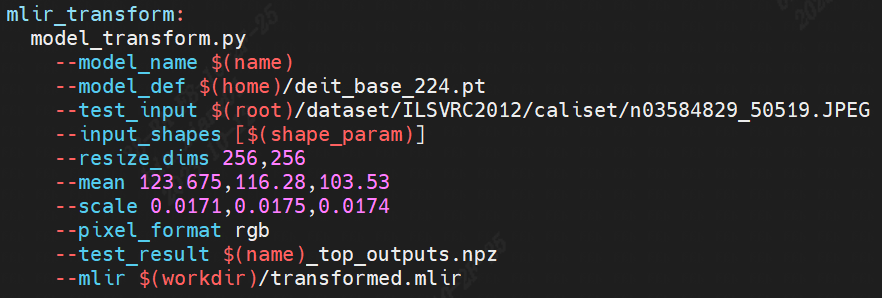 transform
transform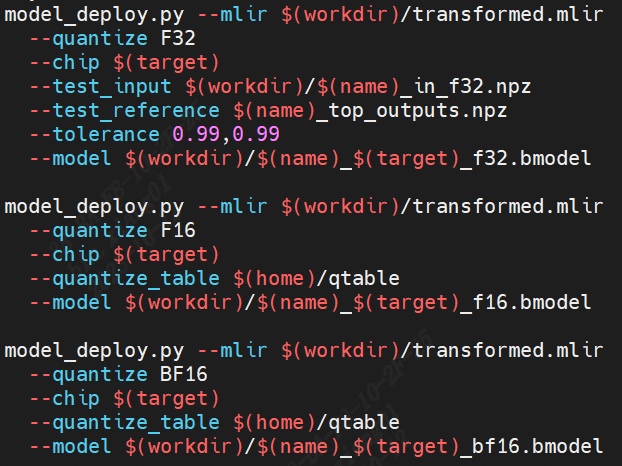 deploy
deploy
2.3 精度測試
DeiT為分類模型,精度測試采用topk來進行。
精度測試及性能測試結果如下:
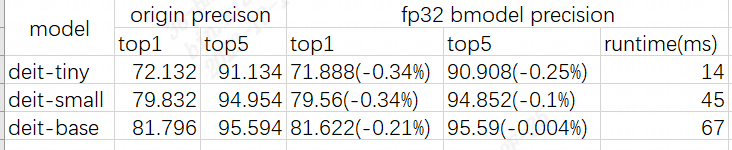 precision
precision
3 小結
總體看移植過程相對順利,在解決了部分算子邊界問題之后可以成功編譯出bmodel。F32精度基本可與原始框架對齊。由于第一個Conv stride > 15,在進行F16/BF16轉換時遇到比對問題,這部分代碼目前仍在重構,生成bmodel過程中這部分采用F32混精度處理。
-
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
模型
+關注
關注
1文章
3178瀏覽量
48731 -
深度學習
+關注
關注
73文章
5493瀏覽量
120999
發布評論請先 登錄
相關推薦
高通AI Hub:輕松實現Android圖像分類

使用卷積神經網絡進行圖像分類的步驟
高效大模型的推理綜述

主動學習在圖像分類技術中的應用:當前狀態與未來展望

字節發布SeedEdit圖像編輯模型
AI大模型在圖像識別中的優勢
浪潮信息源2.0大模型與百度PaddleNLP全面適配

計算機視覺怎么給圖像分類
如何使用PyTorch構建更高效的人工智能
鴻蒙應用模型:【應用模型】解析

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
搭載星火認知大模型的AI鼠標:一鍵呼出AI助手,辦公更高效

自動駕駛和多模態大語言模型的發展歷程

CNN圖像分類策略





 工商網監
工商網監
評論