") 馬里蘭&NYU合力解剖神經網絡,CLIP模型神經元形似骷髏頭
馬里蘭&NYU合力解剖神經網絡,CLIP模型神經元形似骷髏頭
【導讀】神經網絡黑盒怎么解釋?馬里蘭大學和NYU研究人員開啟了新的嘗試。
AI黑盒如何才能解? 神經網絡模型在訓練的時,會有些ReLU節(jié)點「死亡」,也就是永遠輸出0,不再有用。 它們往往會被被刪除或者忽略。 恰好趕上了模糊了生與死的界限的節(jié)日——萬圣節(jié),所以這是探索那些「死節(jié)點」的好時機。

對于大多數圖像生成模型來說,會輸出正面的圖像。但是優(yōu)化算法,可以讓模型生成更多詭異、恐怖的圖像。 就拿CLIP模型來說,可以衡量一段文本和一張圖片的匹配程度。 給定一段描述怪誕場景的文本,使用優(yōu)化算法通過最小化CLIP的損失,來生成一張與這段文本匹配的、嚇人的圖片。

當你不斷探索損失函數的最深最恐怖的區(qū)域,就像進入了一個瘋狂的狀態(tài)。 就會發(fā)現(xiàn)這些詭異圖片超乎想象。 最重要的是,它們僅僅是通過CLIP模型優(yōu)化生成,并沒有借助其他的模型。

優(yōu)化算法,可以讓我們對神經網絡進行「解剖」,特征可視化(feature visualization)可以找到一個最大激活單個神經元的圖像。 吳恩達和Jeff Dean曾在2012年就ImageNet圖像分類模型上做過這樣的實驗,并發(fā)現(xiàn)了一個對黑色貓有響應的神經元。 對此,來自馬里蘭大學和NYU的研究人員使用「特征可視化」來剖析CLIP模型,發(fā)現(xiàn)了一個非常令人不安的神經元: 完全是一個類似骷髏頭的圖像。

但它真的是「骷髏頭神經元」嗎?顯然不是,實際上它代表的是某種更加神秘、難以解釋的模式。 究竟怎么回事?
模型反轉,卷積網ViT不適用
想要解釋AI生成的圖像,需要用到的一種手段——模型反轉(model inversion)。
「模型反轉」是可視化和解釋神經架構內部行為、理解模型學到的內容,以及解釋模型行為的重要工具。 一般來說,「模型反轉」通常尋找可以激活網絡中某個特征的輸入(即特征可視化),或者產生某個特定類別的高輸出響應(即類別反轉)。 然鵝,神經網絡架構不斷發(fā)展,為現(xiàn)有的「模型反轉」方案帶來了重大挑戰(zhàn)。 卷積網長期以來,一直是CV任務的默認方法,也是模型反轉領域研究的重點。 隨著Vision Transformer(ViT)、MLP-Mixer、ResMLP等其他架構的出現(xiàn),大多數現(xiàn)有的模型反轉方法不能很好地應用到這些新結構上。

總而言之,當前需要研發(fā)可以應用到新結構上的模型反轉方法。 對此,馬里蘭和NYU研究人員將關注點放在了「類反轉」(class inversion)。 目標是,在不知道模型訓練數據的情況下,找到可以最大化某個類別輸出分數的可解釋圖像。 類反轉已在模型解釋、圖像合成等任務中應用,但是存在幾個關鍵缺陷:生成圖像質量對正則化權重高度敏感;需要批標準化參數的方法不適用于新興架構。 研究人員再此提出了基于數據增強的類反轉方法——Plug-In Inversion(PII)。

論文地址:https://arxiv.org/pdf/2201.12961.pdf PII的好處在于不需要明確的正則化,因此不需要為每個模型或圖像實例調節(jié)超參數。 實驗結果證明,PII可以使用相同的架構無關方法和超參數反轉CNN、ViT和MLP架構。
全新類反轉——PII
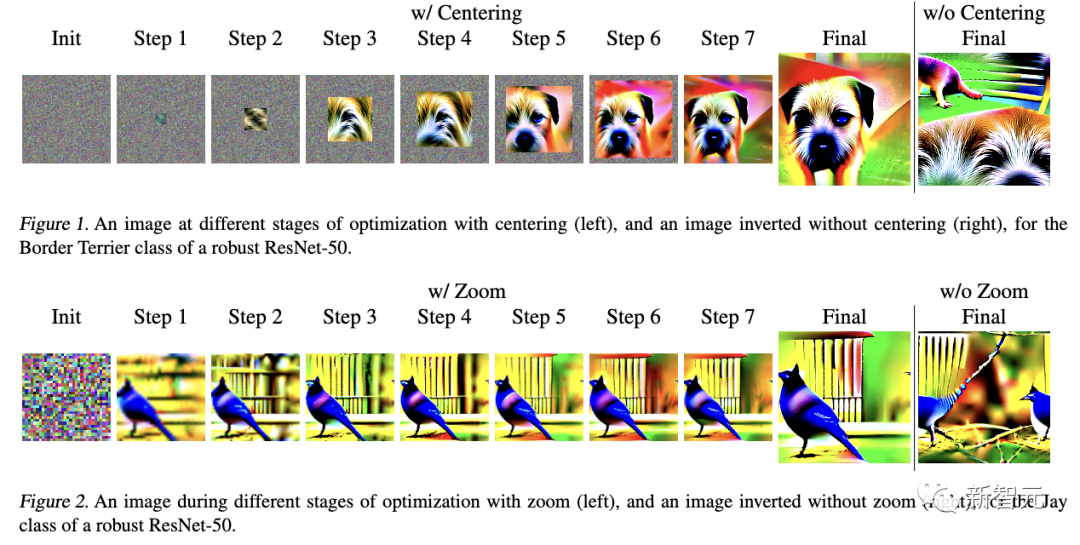
此前,關于類反轉的研究,常常使用抖動之類的增強功能。 它會在水平和垂直方向上隨機移動圖像,以及水平Ips來提高反轉圖像的質量。 在最新研究中,作者探討了有利于反轉的其他增強,然后再描述如何將它們組合起來形成PII算法。限制搜索空間作者考慮2種增強方法來提高倒置圖像的空間質量——居中(Centering)和縮放(Zoom)。 這些方法的設計基于這樣的假設:限制輸入優(yōu)化空間,可以得到更好的特征布局。 兩種方法都從小尺寸開始,逐步擴大空間,迫使放置語義內容在中心,目的是生成更具解釋性和可識別性的反轉圖像。 圖1和圖2分別顯示了,居中和縮放過程中每個步驟測圖像狀態(tài)。
ColorShift增強之前展示的反轉圖像,顏色看起來很不自然。 這是由于研究人員現(xiàn)在提出的一種全新增強方法——ColorShift造成的。 ColorShift是隨機擾動每個顏色通道的平均值和方差,改變圖像顏色,目的是生成更豐富多樣的反轉圖像顏色。 下圖,作者可視化了ColorShift的穩(wěn)定效果。

集成集成是一種成熟的工具,經常用于從增強推理到數據集安全等應用程序。 研究人員發(fā)現(xiàn),優(yōu)化由同一圖像的不同ColorShift組成的整體,可以同時提高反轉方法的性能。 圖4顯示了與ColorShift一起應用集成的結果。 可以觀察,到較大的集成似乎給出了輕微的改進,但即使是大小為1或2的集成,也能產生令人滿意的結果。 這對于像ViT這樣的模型很重要,因為可用的GPU內存限制了該集合的可能大小。

到這里,你就明白什么是PII了,即結合了抖動、集成、ColorShift、居中和縮放技術,并將結果命名為「插件反轉」。 它可以應用到任何可微分模型(包括ViT和MLP),只需要一組固定超參數。
多種網絡架構適用
那么,PII效果究竟如何? 實驗結果發(fā)現(xiàn),PII可以應用于不同的模型。需要強調是的是,研究者在所有情況下都對PII參數使用相同的設置。 圖6中,描繪了通過反轉各種架構的Volcano類生成的圖像,包括CNN、ViT和MLP的示例。

雖然不同神經網絡的圖像質量有所不同,但它們都包含可區(qū)分,且位置恰當的視覺信息。 在圖7中,研究人員還顯示了PII從幾個任意ImageNet類的每種主要架構類型的代表生成的圖像。 可以看到,每行有獨特視覺風格,說明模型反轉可以用來理解不同模型的學習信息。

在圖8中,作者使用PII來反轉在ImageNet上訓練,并在CIFAR-100上進行微調的ViT模型。

圖9顯示了在CIFAR-10上微調的模型的反轉結果。

為了定量評估全新方法,作者反轉預訓練的ViT模型和預訓練的ResMLP模型,使用PII為每個類生成一張圖像,并使用DeepDream執(zhí)行相同的操作。 然后使用各種預訓練的模型對這些圖像進行分類。 表1包含這些模型的平均top-1和top-5分類精度,以及每種方法生成的圖像的初始分數。

圖10顯示了PII和DeepInversion生成的一些任意類別的圖像。

-
神經網絡
+關注
關注
42文章
4764瀏覽量
100542 -
AI
+關注
關注
87文章
30172瀏覽量
268431 -
模型
+關注
關注
1文章
3174瀏覽量
48718 -
Clip
+關注
關注
0文章
31瀏覽量
6651
原文標題:AI生圖太詭異?馬里蘭&NYU合力解剖神經網絡,CLIP模型神經元形似骷髏頭
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
人工神經網絡算法的學習方法與應用實例(pdf彩版)
【PYNQ-Z2試用體驗】神經網絡基礎知識
【案例分享】基于BP算法的前饋神經網絡
【案例分享】ART神經網絡與SOM神經網絡
有關脈沖神經網絡的基本知識
基于BP神經網絡的PID控制
卷積神經網絡模型發(fā)展及應用
神經網絡與神經網絡控制的學習課件免費下載





 工商網監(jiān)
工商網監(jiān)
評論