 如何從大腦活動中解碼自然語言呢?
如何從大腦活動中解碼自然語言呢?
1 簡介
??語言不僅是人類交流的工具,更是思維和智能的基礎。大腦如何解碼和處理語言信息是揭示人類智能本質的關鍵。隨著腦機接口(BCI)等技術的迅速發展,我們有了從大腦活動中解碼自然語言的可能。這一研究方向不僅對認知科學和神經科學領域的發展至關重要,也為因神經退行性疾病和創傷而失去語言能力的人提供了新的希望。該方向的發展將極大地拓展我們對人類大腦處理語言的理解,并可能開啟全新的溝通方式。
??從大腦活動中解碼自然語言的最大需求出現在那些因錐體束或下運動神經元的急性或退行性損傷而導致運動和語言障礙的患者中。當運動和語言障礙特別嚴重,如在鎖定綜合征(LIS)中,患者可能完全失去運動控制,從而無法獨立發起或維持交流,僅限于用眨眼或眼球運動等輕微動作回答簡單問題。BCI技術提供了大腦與外界之間的橋梁,讀取人腦產生的信號并將它們轉換成所需的認知任務,使得那些由于運動障礙而不能說話的人可以僅通過他們的腦信號進行交流,而無需移動任何身體部分。
??在協助這類患者交流上,很多BCI范式已經取得了重大進展,包括P300、穩態視覺誘發電位(SSVEP)和運動想象(MI)等。P300和SSVEP利用外部刺激,如閃爍的屏幕或聽覺蜂鳴聲,以誘發有區分性的大腦模式。基于運動想象的系統則識別人腦自發的運動意圖,無需外部刺激的輔助。然而,這些范式通常只能通過意念打字的形式輸出文本,無法替代口頭交流的速度和靈活性。在日常對話中,每分鐘交流的平均單詞數通常能達到意念打字速度的7倍。因此,從大腦活動中解碼自然語言,更具體而言是從言語或想象言語時的大腦活動解碼自然語言,相比之前的BCI范式具有明顯的速度優勢,同時也允許患者用更少的努力進行溝通。
2 數據采集
??為獲取大腦在言語或想象言語過程中產生的信號,已經有多種神經影像學方法被應用。這些方法主要包括腦電圖(EEG)、腦磁圖(MEG)、功能性磁共振成像(fMRI)等非侵入性方法,以及皮質腦電圖(ECoG)等侵入性方法。侵入性方法能提供足夠的時空分辨率,同時具有較高的信噪比(SNR),但更高的醫療風險限制了它們在臨床和日常使用中的普及。這使得基于非侵入性方法的大腦活動解碼也得到了關注和廣泛研究。
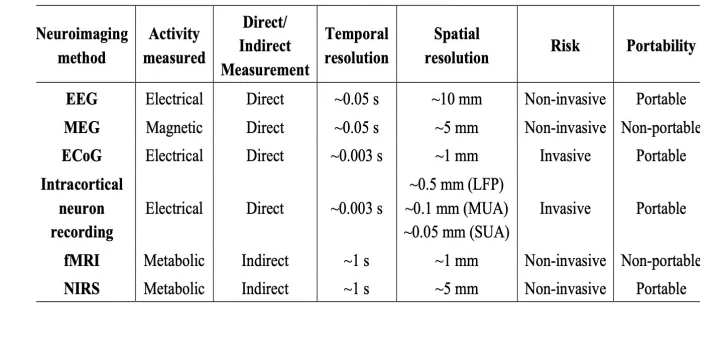
圖1 幾種神經影像學方法的比較
2.1 ECoG
??皮質腦電圖(ECoG)是一種侵入性的神經記錄技術,它通過在大腦硬腦膜下空間植入電極陣列來測量大腦皮層表面的電活動。這些電極通常是由鉑銥制成的圓盤形電極,嵌入在柔軟的硅膠片中。ECoG記錄的信號具有很高的時空分辨率,可以提供關于大腦活動的精確信息。由于其準確性和較高的信噪比,ECoG在臨床神經科學中有著廣泛的應用,特別是識別藥物難治性癲癇患者的癲癇發作源頭,以及確定對大腦功能至關重要的皮質區域,以便在切除手術期間保留這些區域。ECoG的一個主要優點是它能夠在皮層表面覆蓋較廣的區域,同時提供足夠的空間分辨率,這對于研究廣泛分布的神經網絡,如語言和運動控制網絡,具有重要的價值和意義。
2.2 EEG
??腦電圖(EEG)是一種廣泛使用的非侵入性神經記錄技術,通過在頭皮上放置電極來測量大腦活動產生的電信號。EEG主要用于監測和研究大腦的電生理活動,特別是用于診斷和研究癲癇、睡眠障礙、大腦損傷以及各種神經系統疾病。作為一種非侵入性方法,EEG有著較高的時間分辨率,能夠捕捉大腦電活動的快速變化,提供亞毫秒級的時間信息,這對于研究大腦如何在短時間內處理信息非常有用。然而EEG的空間分辨率相對較低,難以精確定位大腦內特定區域的電活動,限制了其在精確腦映射方面的應用。EEG的另一個局限性在于信噪比(SNR)較低。信號中的目標成分難以從背景活動中識別出來,這些背景活動可能來自于肌肉或器官活動、眼球運動或眨眼。盡管存在上述問題,鑒于EEG的非侵入性、便攜性和低成本,EEG仍然是神經科學、臨床神經學和腦機接口研究中極其重要的工具。
圖3 EEG示意圖
2.3 MEG
??腦磁圖(MEG)是一種非侵入性神經成像技術,通過記錄大腦神經元活動引發的磁場變化來測量大腦活動。在細胞層面上,大腦中的單個神經元具有電化學特性,導致帶電離子通過細胞流動。這種緩慢的離子電流流動的凈效果會產生電磁場。雖然單個神經元產生的場強度可以忽略不計,但特定區域內大量神經元共同激活時,會在頭部外產生可測量的磁場。大腦產生的這些神經磁信號非常微弱,因此MEG掃描儀需要使用超導傳感器,并置于磁屏蔽室中進行測量。MEG能夠提供精度達到亞毫秒級的大腦活動時序特征,并提供比EEG更準確的神經活動空間定位。盡管MEG的使用條件相對嚴格,但其時空分辨率上的優勢使其成為了神經科學和臨床研究領域中極為重要的技術手段。
圖4 MEG示意圖
2.4 fMRI
??fMRI(功能磁共振成像)的原理是利用BOLD(血氧水平依賴性)對比來檢測大腦中的活動變化。BOLD對比利用了血液中氧合血紅蛋白和脫氧血紅蛋白在磁性質上的差異。當大腦的某一部分活躍時,它需要更多的氧來支持其功能。為了滿足這一需求,血流會增加以帶來更多的氧合血紅蛋白。氧合血紅蛋白和脫氧血紅蛋白在磁性上有所不同:氧合血紅蛋白是磁性中性的,而脫氧血紅蛋白是磁性的。因此,當一個區域的血流增加時,該區域的BOLD信號也會增加。
??fMRI具有較高的空間分辨率和較低的時間分辨率。fMRI一次掃描可以測量約100,000個體素,而MEG的傳感器通常在300個以下。然而,一個神經活動的脈沖可能導致BOLD在大約10秒內上升和下降;對于自然說出的英語,每次掃描采集的大腦圖像可能受到超過20個單詞的影響。這意味著大腦活動的解碼是一個不適定問題。盡管這為解碼連續語言提出了挑戰,仍然有一些工作在該方向做出了探索和嘗試。
3 前沿工作
??下面將介紹幾篇最近幾年從大腦活動中解碼自然語言的相關工作。目前比較主流的方法是從大腦活動端到端地解碼文本。這些工作通常采用編碼器—解碼器的模型結構,將腦信號映射到連續文本。隨著預訓練語言模型的出現,前沿工作逐漸將其應用于大腦活動解碼,通常作為解碼器,和隨機初始化的編碼器共同訓練。也有工作嘗試使用非端到端的方式對大腦活動進行解碼。在解碼文本之外,還有工作研究將腦信號對齊到預訓練模型生成的高質量表征,從而將腦信號映射到預訓練模型輸出構成的良好向量空間中。
3.1 端到端的解碼
Machine translation of corticalcactivity to text with an encoder-decoder framework(Nature neuroscience 2020)
??在這篇工作之前,大多數從大腦活動中解碼自然語言的工作通常局限于孤立的音素或單音節詞。解碼連續文本的工作相對較少,且效果不佳。文章將問題建模為機器翻譯問題,腦信號視為源語言,對應的連續文本視作目標語言,從而將機器翻譯領域的模型方法遷移到大腦活動解碼這一任務上。
??文章設計了一個簡單的編碼器—解碼器結構的神經網絡,以從ECoG信號中解碼連續文本。如下圖所示,對于輸入的原始ECoG信號,模型首先在時間維進行跨步卷積,以提取時序特征并下采樣到16HZ,然后輸入編碼器—解碼器結構的LSTM網絡以解碼得到連續文本。為了引導編碼器編碼有意義的信息,除了端到端地訓練模型從ECoG信號中解碼連續文本,文章在訓練階段還額外添加了一個輔助損失,強迫模型基于編碼器每個時間步的隱藏層表征準確預測對應時刻語音的音頻表征。(這里采用音頻的梅爾頻率倒譜系數MFCC作為音頻的低階表征)
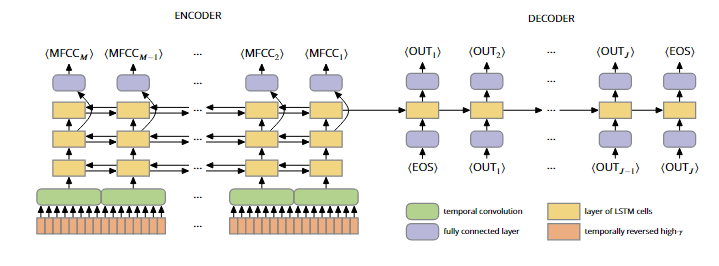
圖6 文章提出的編碼器—解碼器框架
??文章從每位受試者收集了30至50個句子的重復口述,以及同一時間大腦臨側裂區大約250個電極記錄下的ECoG信號。文章提出的方法在準確性方面相較以往研究有著顯著提升,其中一部分參與者的平均詞錯誤率(WER)降至了7%,這一成果顯著優于以往研究中超過60%的錯誤率,為未來的研究提供了重要的參考意義。
??在神經科學和腦機接口領域,大腦活動數據的采集通常面臨一系列挑戰,最終導致采集的數據集規模通常較小,成為相關研究和應用發展的重要限制。由于缺乏訓練數據,傳統的從大腦活動中解碼自然語言的工作通常局限在小而封閉的詞表上,且難以泛化到訓練集之外的單詞和句子上。這篇工作首次使用預訓練語言模型(文章使用BART)進行EEG信號的連續文本解碼。借助預訓練語言模型在理解句法特征、語義特征以及長距離依賴方面的能力,這篇工作得以將詞表擴展到約50000的規模(即BART的詞表大小),同時在數據稀缺的條件下保持較好的泛化能力。
??文章將人腦視作一種特殊的文本編碼器,并提出了一個稱作BrainBART的新穎框架。該框架將EEG特征序列視為編碼的連續文本,并通過額外的編碼器將輸入的EEG特征序列映射到BART的嵌入層表征,如下圖所示。訓練期間的目標是最小化文本重建的交叉熵損失。此外,文章還提出了一個零樣本情感分類方法,該方法首先將EEG特征序列轉換為文本,然后通過文本分類器預測情感標簽。
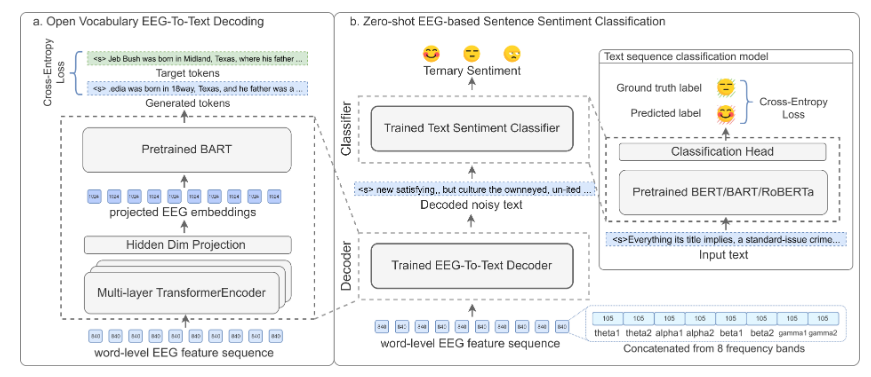
圖7 BrainBART框架
??這篇工作使用了ZuCo數據集,其中包含被試者進行自然閱讀任務時記錄的EEG和眼動追蹤數據。BrainBART在連續文本解碼上達到了40.1%的BLEU-1分數,并在零樣本的三元情感分類上達到了55.6%的F1分數,顯著優于有監督的基線。
??盡管EEG信號的連續文本解碼已取得一定成功,但從fMRI信號生成連續文本的研究相對較少,這主要是因為fMRI的低時間分辨率。之前的fMRI信號解碼方法通常依賴于對預定義的感興趣區(ROI)進行特征提取,未能有效利用時間序列信息,且通常忽略高效編碼的重要性。為解決這些問題,并避免使用單獨的復雜流程從特定模態的腦信號解碼語言,文章提出了一個通用的腦信號解碼框架,稱作UniCoRN(統一認知信號重構),可應用于各種模態腦信號的解碼。UniCoRN采用編碼器—解碼器框架,利用了預訓練語言模型的強大解碼能力,并通過快照和序列重建構建了一個有效的編碼器,使模型能夠分析單個快照及快照序列之間的時間依賴性,從而最大化地提取腦信號中的信息。
??下面以fMRI信號解碼為例介紹模型的整體框架。UniCoRN包含兩個階段:腦信號重建,以針對特定模態的腦信號訓練編碼器;以及腦信號解碼,即將第一階段中腦信號的表征轉換為自然語言。文章這里的深層思想是將腦信號的每個快照(如單個fMRI幀)視為“人腦所說語言”的單詞級表征,并通過編碼器獲得這種語言的詞嵌入,最終像傳統的機器翻譯任務一樣,將其轉換為真實的人類語言。腦信號重建階段可細分為快照重建和序列重建兩個子階段,以訓練編碼器整合每個快照的內部特征和時間序列中快照間的時間關系。如圖所示,快照重建階段(phase 1)通過快照編碼器分別編碼每個fMRI幀,并以重建原始的fMRI幀作為訓練目標;序列重建階段(phase 2)將連續fMRI幀的編碼表征輸入序列編碼器以生成序列化表征,并使用和上一階段相同的目標繼續訓練。在腦信號重建階段之后,之前用于重建原始fMRI幀的解碼器被替換為文本解碼器,以進行最終的文本生成(phase 3)。文章在這里選擇BART作為文本解碼器,并使用交叉熵損失進行訓練。
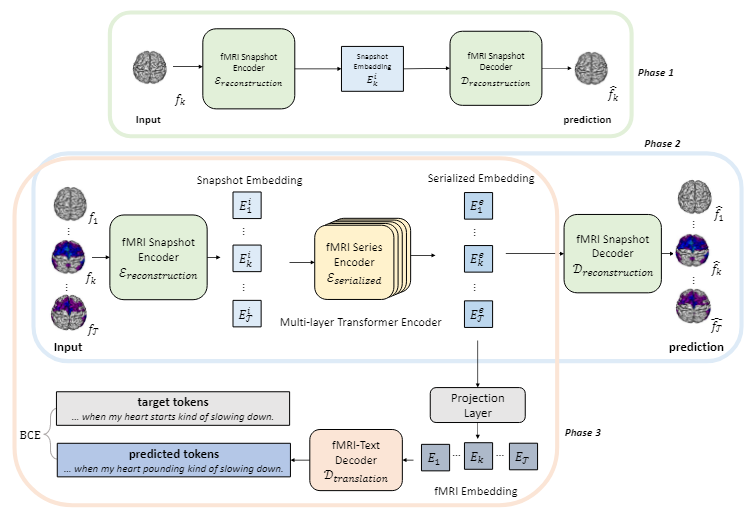
圖8 UniCoRN框架
??UniCoRN在fMRI信號的連續文本解碼任務上(Narratives數據集)達到了34.77%的BLEU-4分數,并在EEG的連續文本解碼任務上(ZuCo數據集)達到了62.90%的BLEU-4分數,從而超越了之前的基線。實驗結果表明從fMRI信號中解碼語言是可行的,并且使用統一結構解碼不同模態的腦信號是有效的。
3.2 非端到端解碼
??這篇工作提出了一種方法,從fMRI信號重建受試者正在聽到或想象的聽覺刺激(以自然語言的形式)。實現這一點需要克服fMRI的低時間分辨率。為解決這一問題,文章提出的解碼器并未采用端到端的解碼方式,而是通過猜測候選單詞序列,評估每個候選項引發當前測得的大腦反應的可能性,然后選擇最佳候選項來實現解碼。
??方法的框架如下圖所示。三名受試者聽了16小時的敘事故事,并記錄了基于血氧水平依賴(BOLD)的功能磁共振成像(fMRI)反應。文章針對每位受試者訓練了一個編碼模型,以從文本刺激的語義表征預測對應的大腦反應。為了從大腦活動中重建語言,文章采用beam search算法以逐詞生成候選序列。文章提出的方法維持著若干個最可能的候選序列,當通過大腦聽覺和語言區域的活動檢測到新詞時,使用語言模型為每個候選序列生成最可能的若干延續。然后,使用之前訓練的編碼模型對每個延續引發當前測得的大腦反應的可能性進行評分,并保留最可能的延續。實驗結果表明,方法的識別準確度明顯高于偶然預期,證明了方法的有效性。
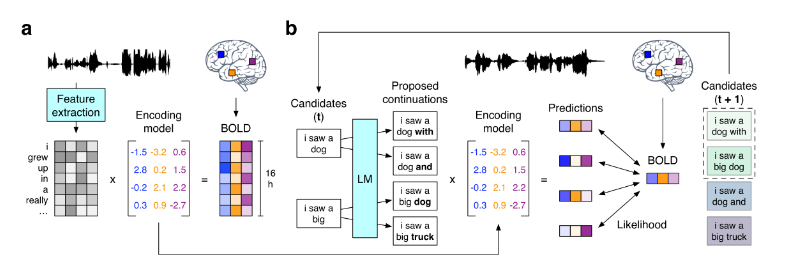
圖9 文章提出的fMRI信號解碼方法
3.3 信號對齊研究
??這篇工作提出了一種使用單一架構的數據驅動方法,從MEG或EEG信號中解碼自然語言。文章引入了一個卷積神經網絡作為腦信號的編碼器,并使用對比目標進行訓練,以對齊預訓練語音自監督模型wav2vec-2.0生成的深層音頻表征。
??理論上,可以通過回歸損失訓練腦信號編碼器,預測對應音頻的梅爾頻率倒譜系數,并將編碼器的輸出作為腦信號的一種表征。然而在實踐中,文章觀察到這種直接回歸方法生成的表征通常由不可區分的寬帶成分主導。對于這一問題,文章首先推斷回歸可能是一種無效的損失,并將其替換為了CLIP模型的對比損失,該損失最初被設計用于匹配對齊文本和圖像兩種模態的深層表征。文章進一步判斷梅爾頻率倒譜系數不太可能與豐富的大腦活動相匹配,因為其僅包含聲音的低階表征。文章在這里將梅爾頻率倒譜系數替換為wav2vec-2.0的輸出表征,該模型有效地編碼了多層次的語言特征,且有研究表明其與大腦的激活之間存在線性關系。最后,文章提出了一個考慮被試者差異的CNN網絡,作為大腦活動的編碼器。
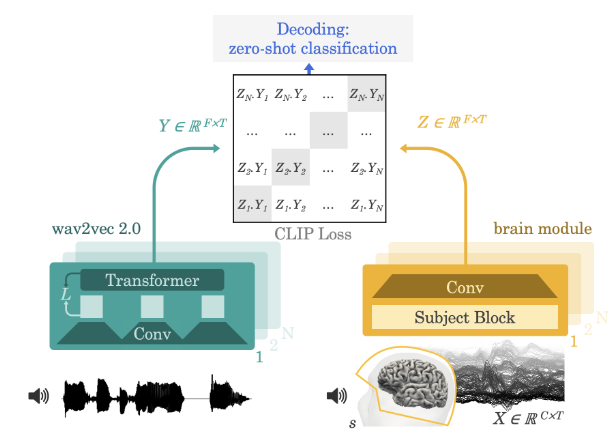
圖10 文章提出的腦信號對齊方法
??文章在四個公開的MEG/EEG數據集上進行了驗證,模型能夠用3秒的MEG/EEG信號,識別匹配的音頻片段(即零樣本解碼),在MEG上達到最高72.5%TOP-10準確率,在EEG上達到最高19.1%的TOP-10準確率。盡管文章中的實驗僅限于音頻片段和單個詞的解碼,但其方法和思想可以作為后續工作的基礎,有效地遷移到包括連續文本解碼在內的諸多任務上。
4 總結
??本文回顧了從大腦活動中解碼自然語言這一任務及前沿方法。前沿方法的不斷發展不僅加深了我們對語言和大腦交互的理解,也為發展先進的腦機接口技術打下了堅實的基礎。盡管已取得顯著進展,但這一領域仍面臨著缺少大腦活動數據,非侵入性方法信噪比低等問題,限制了方法在實際應用中的可用性。對于未來工作,一方面需要獲取更高質量和更大規模的大腦活動數據,另一方面也需要算法和模型的創新,以最大限度利用有限的數據。最后,跨學科的合作,如神經科學、語言學、計算機科學的結合,將為理解大腦處理語言的復雜機制提供新的視角,推動該領域朝著更加精確和實用的方向發展。
審核編輯:劉清
-
傳感器
+關注
關注
2548文章
50678瀏覽量
752014 -
信噪比
+關注
關注
3文章
253瀏覽量
28592 -
SNR
+關注
關注
3文章
195瀏覽量
24371 -
磁共振成像
+關注
關注
0文章
20瀏覽量
8588 -
電信號
+關注
關注
1文章
790瀏覽量
20537
原文標題:從大腦活動中解碼自然語言:任務與前沿方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論