") 用來計算EVM的包絡仿真器到底是什么
用來計算EVM的包絡仿真器到底是什么
我最近在看射頻層面的EVM仿真,用的是包絡仿真器,即envelope。做個記錄吧,還沒搞懂,我說到,我看了help文件中的包絡仿真的理論,但是沒有看懂。
在一位號友的指導下,我現(xiàn)在好像是懂了。
(1)先來說說,為啥會使用包絡仿真。
一般來說,帶有調制的射頻信號,如果又想仿真出射頻載波,又想仿真出調制特性,是一件很耗費時間的事情。
為什么呢?
射頻載波,頻率比較高,為了鑒別出射頻頻率,就需要Tstep足夠的小。調制包絡,頻率又比較低,為了能夠仿真出頻率包絡,tstop又必須足夠大。
而采樣的點數(shù),則是tstop/Tstep,所以這一大一小,使得數(shù)據(jù)量特別大,數(shù)據(jù)量一大,時間就長。
所以,包絡仿真的優(yōu)勢就體現(xiàn)出來了。
它把射頻和調制分開來計算,這樣時間上來說,大大縮減,同時也能保證精確度。
(2)那包絡仿真是怎么做到的呢?

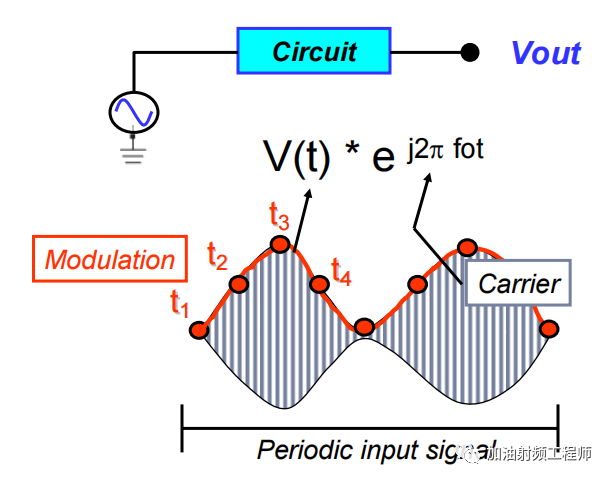
在ADS的help文件中,講Envelope仿真理論的時候,有這樣兩段話,如上圖所示。
這段話,講出了Envelope的大概的做法。
包絡仿真器,集合了時域仿真和頻域仿真,所以快并且準的分析出復雜信號的特性,比如說數(shù)字調制的RF信號
仿真器,允許用頻域來仿真RF載波,然后用時域來仿真調制包絡。
總的來說,可以這樣理解。當用Envelope來仿真帶有調制的RF信號時,仿真器把信號分成兩部分來看待,一部分是射頻載波信號,在頻域上進行仿真;另一部分是調制包絡,在時域上進行仿真。
用一幅圖來說明一下,就是這樣。
(3)上面的內容,在上一次看help文件時,其實就能搞懂了。
但是總體來說,我還是沒能看懂。
當時發(fā)完文后,號友還發(fā)消息過來,問我,還有哪里不懂啊!
當時,覺得整篇help,除了第一二段,也就是上面講的那兩段文字能看懂,下面的,發(fā)現(xiàn)都是云里霧里的。
就應了,那句很流行的話,“字都認識,但是看不懂”。
所以,我壓根不知道從哪里問起,因為感覺啥啥都是不懂點。
(4)事情的轉機發(fā)生在我再次找envelope的資料,看到資料上有這樣五點。如下圖所示。

看到第二點的時候,我突然了解到,我的不懂點是在哪里了。
雖然這句話,在ADS的help文件中,也出現(xiàn)過。但是夾在那么多不懂的內容中,絲毫沒有引起我的注意。
但是當它單獨以一行出現(xiàn)的時候,在我的腦海中激起了波瀾。
我看不懂的根本原因,就在這句話里。Compute the spectrum at each time sample,在每個時間采樣點計算頻譜,我就很疑惑,每個時間采樣點,不就一個點么,怎么能計算出頻譜呢。
然后我就又去問號友了。
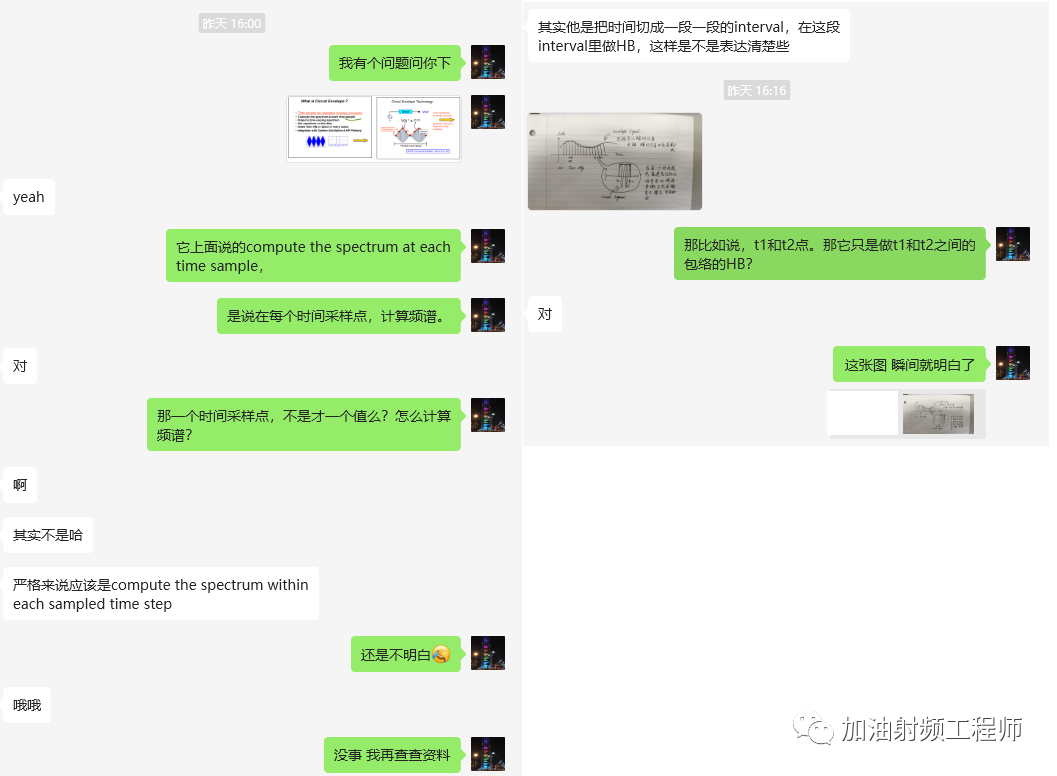
然后號友就發(fā)來了一副他的手繪圖,給我一下子砸明白了。
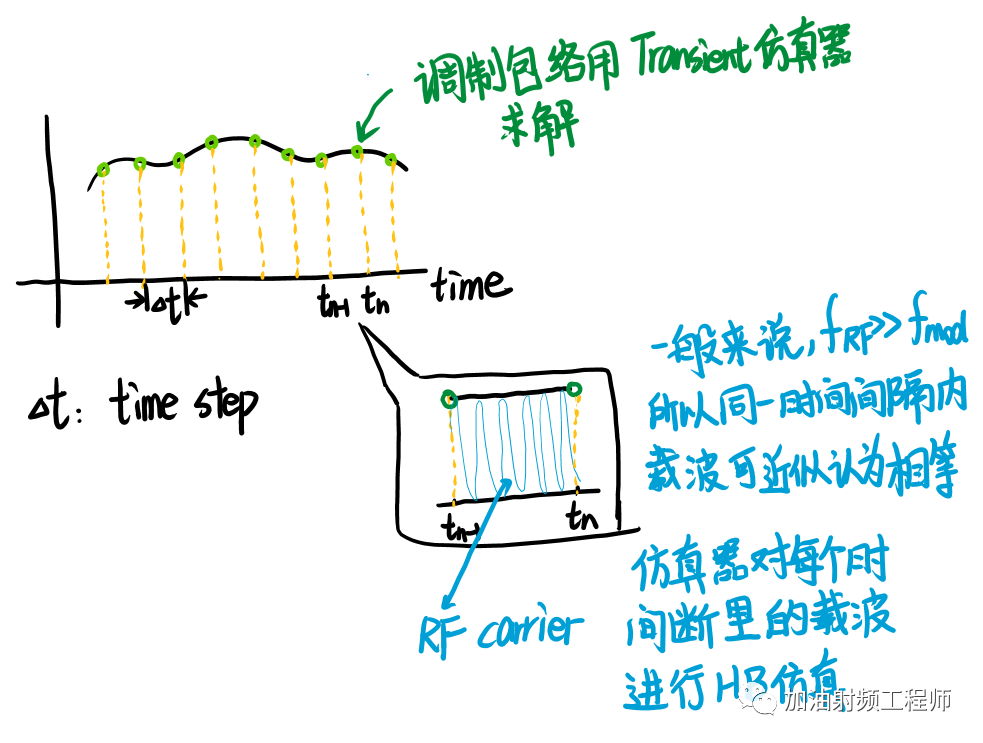
我把號友的圖,重新又畫了一遍,順便增加點印象。
(5) 在進行Envelope仿真的時候,tstep的設置會比較講究。
因為是對包絡進行采樣,既然提到采樣,就會想到采樣定理。是的,這里tstep的設置,也需要滿足這個要求。
比如說,你數(shù)字信號的Symbolrate,那Symbolrate代表的就是符號變化率,也就是代表包絡的變化率,那你想把那個變化的包絡采出來,你就得把tstep,也就是采樣率,設置到2*Symbolrate以上。
而這個tstep,又和envelope計算出來的頻寬相關,頻寬是等于±0.5*tstep。
所以,這個tstep設置的越小,所計算出來的頻寬也就越寬。
如果想和我進一步交流的話,歡迎關注個人微信號,注明:公司(如方便的話)+工作性質(如研發(fā),調試,銷售等)。
審核編輯:湯梓紅
-
射頻
+關注
關注
102文章
5468瀏覽量
166926 -
仿真器
+關注
關注
14文章
1008瀏覽量
83436 -
EVM
+關注
關注
3文章
242瀏覽量
40806 -
射頻載波
+關注
關注
0文章
6瀏覽量
5840
原文標題:用來計算EVM的包絡仿真器,到底是個啥子?
文章出處:【微信號:加油射頻工程師,微信公眾號:加油射頻工程師】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
仿真器究竟是什么?
32仿真器問題
keil識別不出DAP仿真器是什么原因?
XDS560 60pin仿真器問題
為什么處理器連不上仿真器
購買C6455的DSK套件里面好像沒有仿真器,難道仿真器還要單獨購買嗎?
使用仿真器的熱插拔功能進行調試
什么是單片機仿真器_單片機仿真器有什么用_單片機仿真器怎么用
仿真器是什么
仿真器原理、功能、特性介紹
ADI公司基于USB的仿真器和基于USB的高性能仿真器產(chǎn)品亮點

STM32-DAP仿真器的使用(1)
單片機仿真器是什么?有什么作用?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論