 為什么要優化可泊空間預測算法?泊車Freespace檢測方法如何優化?
為什么要優化可泊空間預測算法?泊車Freespace檢測方法如何優化?
基于視覺的環視可用空間檢測是自動停車輔助(APA)的基本任務之一。任務是根據圖像輸入識別環視自由空間,即 360 度視圖中車輛可行駛而不會發生碰撞的簡單連接的道路區域。盡管激光掃描儀能夠捕獲準確的深度信息而經常用于此任務,但基于視覺的方法由于其顯著的成本優勢而繼續引起人們的興趣。
與行車場景相比,泊車場景中的自由空間檢測提出了對邊界精度的要求。這是因為停車場景中的障礙物顯得更密集,并且更緊密地聚集在車輛周圍。因此,精確定位這樣的邊界可能非常具有挑戰性,特別是對于環視圖像。與分別對每個單一視圖進行檢測并合并結果相比,從環視圖像中進行檢測更有利泊車輔助,其優勢在于它可以一次性提供一整塊可用空間,從而在推理時間上具有優勢。然而,魚眼相機輸入和相應的圖像馬賽克分別接近大規模拉伸扭曲和刺眼陰影,從而使邊界變得模糊。此外,在停車場景中,障礙物往往指的是車輛和行人,它們的大小、方向和位置差異也很大。
在本文中,我們將介紹從多個魚眼相機輸入拼接而成的環視圖像直接預測自由空間(圖1(a)-(b))。
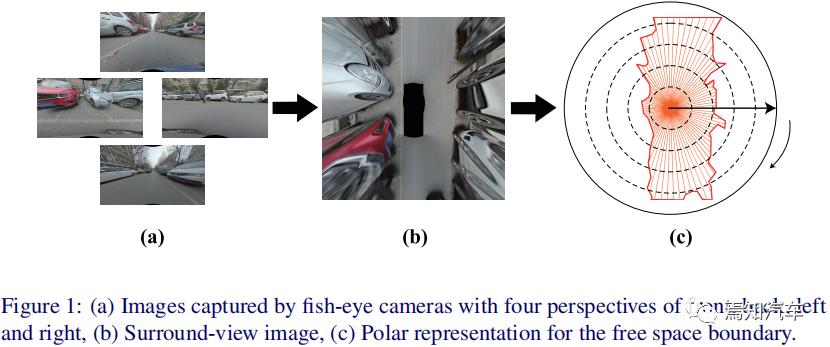
圖1:(a)前、后、左、右四個視角的魚眼相機拍攝的圖像,(b)環視圖像,(c)自由空間邊界的極坐標表示
在上圖1中,驅動車輛(黑色塊)位于圖像的中心,并且始終被自由空間邊界包圍。因此,以圖像中心為原點,每個邊界點由極角和極角點決定。圓弧半徑的邊界點的順序是自然確定的。此外,在特定的極角采樣間隔下,邊界可以采樣到一組點,然后緊湊地表示為極半徑序列。直接序列回歸不僅可以明確關注邊界定位的準確性,而且還可以顯著降低計算成本。
為什么要優化可泊空間預測算法
由于邊界定位的高精度要求,現有的自由空間檢測方法不再適用于我們的任務。最近的方法利用全卷積網絡(FCN),它將自由空間檢測視為二進制分割問題。這種逐像素表示過于復雜且區域化,僅反映整體性能,很少關注邊界定位的精度。這種逐像素表示不僅會淡化邊界定位的重要性,而且還會引入額外的計算成本,因為高維特征圖之后的后續上采樣卷積層。盡管已經有相當多的算法提出了幾種方法來直接使用中心分類和距離回歸來預測邊界,但中心熱圖和距離回歸仍然是逐像素的方式,同時,這些方法也還面臨著昂貴的計算成本。
為了捕獲預測中的非局部依賴性,使用Transformer網絡來集成障礙物信息并建模全局上下文。Transformer 廣泛應用于計算機視覺領域,在捕獲全局上下文和建模非局部依賴關系方面表現了出非凡的性能,這就很自然的想到利用Transformer來解決大規模扭曲和全局穩定性問題。該網絡將環視圖像作為輸入,并端到端地回歸極半徑序列。
此外,在訓練過程中,利用T-IoU(Triangle-IoU,交并比Intersection-over-Union)損失來表示相鄰點的關系并整體優化邊界的匹配過程也是本文介紹的方法之一。
自由空間檢測的傳統算法范圍從像素級算法升級到占用網格。近年來,研究人員將全卷積網絡FCNs應用于自由空間檢測。標準全卷積網絡 FCN 模型由編碼器到解碼器架構組成,該架構在編碼器中提取高級特征表示,并在解碼器中將表示上采樣為全分辨率分割。盡管 FCN 在自由空間檢測中實現了出色的精度,但它們本質上是為每像素分類而設計的。
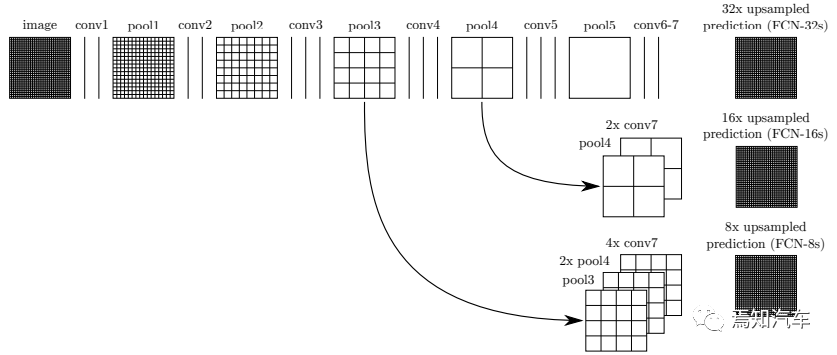
圖2:FCN網絡基本檢測邏輯
此外,一些方法預測每個圖像列的垂直坐標以直接表示自由空間邊界。然而,這些方法不適用于環視圖像,因為環視邊界不沿著行,導致每列上邊界點的數量和順序關系不明確。這點上,極坐標系在旋轉和方向相關問題上具有先天的優勢。這種方法利用一個中心點、一個極半徑和兩個極角來表示遙感圖像中的邊界框。在對象檢測和實例分割領域提出了類似的解決方案,可以概括為兩個并行任務:中心預測和距離回歸。然而,它們更像是逐像素預測方式,并且需要 NMS(非極大值抑制的方法)作為后處理。相比之下,本文所介紹的方法在極坐標中對自由空間邊界進行建模,并端到端地預測極半徑,它放棄了逐像素方式,并且不需要后處理。
在本文中,我們將介紹自由空間重新構建為自由空間邊界的極坐標表示,并利用轉換器框架來進行端到端地回歸表示。為了限制自由空間的整體形狀,我們引入了Triangle-IoU損失函數,使網絡能夠將邊界視為一個整體。
泊車Freespace檢測方法到底如何優化?
1、自由空間邊界的極坐標表示
為了在極坐標系中建模環視自由空間邊界,我們首先將圖像中心c=(xc,yc)設置為極坐標系的原點,水平向右方向為極軸正方向,順時針方向為極角的正方向(以弧度為單位)。為了形成閉合曲線,極角限制在[0,2π)范圍內變化。以相同的極角采樣間隔Δθ=2Nπ采樣N個邊界點,第i個采樣點可以用(ρi,θi)表示,其中極半徑ρi由到 c的距離和極角θi=i·Δθ確定,其中i∈{0,1,2,...,N ?1}。
至此,在極坐標系下,環視自由空間邊界ψ可依次表示為:
ψ={(ρ0,θ0),ρ1,θ1),...,(ρN?1,θN?1)} 。已知θi 時,需要預測的元素僅為極半徑,而ψ可以進一步簡化為:ρ={ρ0,ρ1,...,ρN?1}。
為了定性評估自由空間邊界的精度,我們將極點轉換為笛卡爾點。笛卡爾點 (xi , yi) 可以從 (ρi,θi)表示如下:
xi = xc +ρi·cos(θi),yi = yc +ρi·sin(θi)。(1)
最后,用直線將相鄰的點按順序連接起來,形成一條閉合曲線,代表自由空間的邊界,這個邊界包圍的區域被視為自由空間。對自由空間邊界的極坐標表示只是一個包含 N 個元素的序列,這是參數的顯著簡化。
2、邊界檢測模型
圖 3 說明了整個模型的整體流程。給定一個環視圖像 I 作為輸入,網絡輸出一個端到端的序列?ρ,包含一組極半徑。
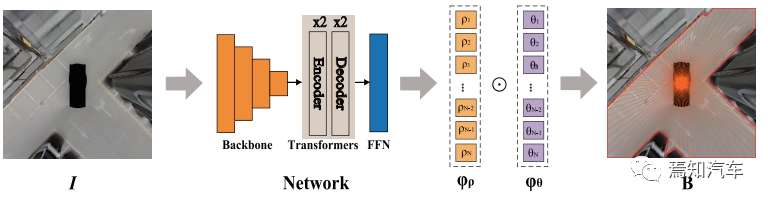
圖 3:管道。給定環視圖像 I 作為輸入,網絡輸出極半徑的序列 ?ρ,可泊空間表示將極半徑與極角配對得到采樣點,通過連接采樣點生成自由空間邊界B。
通過分配預定的極角序列ψθ,得到一組采樣邊界點。將這些點依次用直線連接起來,就可以得到預測的邊界B和相應的自由空間Freespace。
該網絡通過主干網、Transformer和用于序列預測的前饋網絡(FFN)組成。在主干中,應用ResNet18來提取低分辨率圖像特征。Transformer編碼器和Transformer解碼器都由兩個相同的層堆疊而成。每個編碼器主要由多頭自注意力模塊組成,通過并行注意力操作對圖像特征關系進行建模,以生成圖像嵌入。每個解碼器在自注意力模塊之后都有一個額外的多頭交叉注意力模塊,用于計算與圖像嵌入和序列的交互。最后,FFN 通過 3 層感知器將Transformer的輸出投影為 ?ρ。
3、三角形IoU損失(T-IoU損失)
為了限制邊界點的位置,一個不太成熟的處理方式是利用l1損失來監督預測序列。然而,l1損失是為了單點的精度而設計的,因此,這種方式忽略了相鄰點之間的關系和邊界的整體形狀,從而導致不夠平滑和局部模糊。相反,IoU 在目標檢測、語義分割中用于判斷兩個圖片或者框的重合程度這方面得到了廣泛的應用,他的計算過程是將自由空間視為一個整體,并期望邊界在形狀和大小方面表現合理。
為了發揮IoU的優勢,我們首先在groundtruth邊界上以極角2Nπ的采樣間隔進行均勻采樣,以獲得N個真值GroundTruth極半徑的離散序列。同時,將地面真值序列表示為 ??ρ 。Polar IoU提到自由空間的面積可以用無限組扇形區域來表示。然而,在有限的采樣角度下,僅利用一個半徑的扇形區域無法擬合復雜的形狀。由于預測點是用直線連接的,因此采樣自由空間由具有共享中心點的三角形聚集。在這種情況下,將 Polar IoU 中的扇形區域替換為利用兩個相鄰極半徑的三角形區域。
根據三角形面積SΔ=1/2*sinΔθ·ρ1ρ2的計算公式,可以計算出三角形IoU(T-IoU):
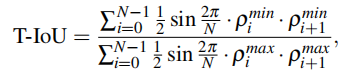
其中,ρN = ρ0 且 ?ρN = ?ρ0。ρi max 表示max(ρi ,?ρi),ρimin表示min(ρi ,?ρi )。T-IoU不僅比Polar IoU在有限采樣角度下對自由空間有更精確的表示,而且通過學習相鄰關系可以更好地適應細長障礙物中極半徑的快速變化。 由于T-IoU的范圍為[0, 1],最優值為1,因此T-IoU損失可以表示為T-IoU的二元交叉熵。省略常數項 1/2sin 2N/π,T-IoU 損失可以簡化如下:
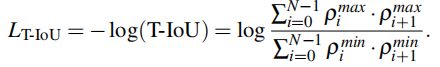
分割網SegNet用于魚眼相機自由空間檢測。對于實際應用,可以選擇SegNet作為基本版本。為了分析分割方法中的邊界精度,本文對分割圖進行后處理:獲取最大連通區域的外邊界并將其作為預測。因此,本文介紹的方法與以前的自由空間檢測方法進行比較,后者可以說是將自由空間視為二進制分割的問題。

圖 4:紅線代表自由空間邊界。細長的、大型的障礙物都包含有各種照明和停車場景
與邊界檢測方法的比較。PolarMask提出通過中心分類和距離回歸來預測實例分割中的邊界。由于不需要中心分類,這就可以刪除PolarMask 中的中心頭和分類頭,只級聯一個平均池化層,然后是回歸頭。由此,就計算成本而言,與常規的方法比較而言,這里提出的方法只有9.7個GMAC,比其他方法要小,差異主要來自處理提取特征的模塊。
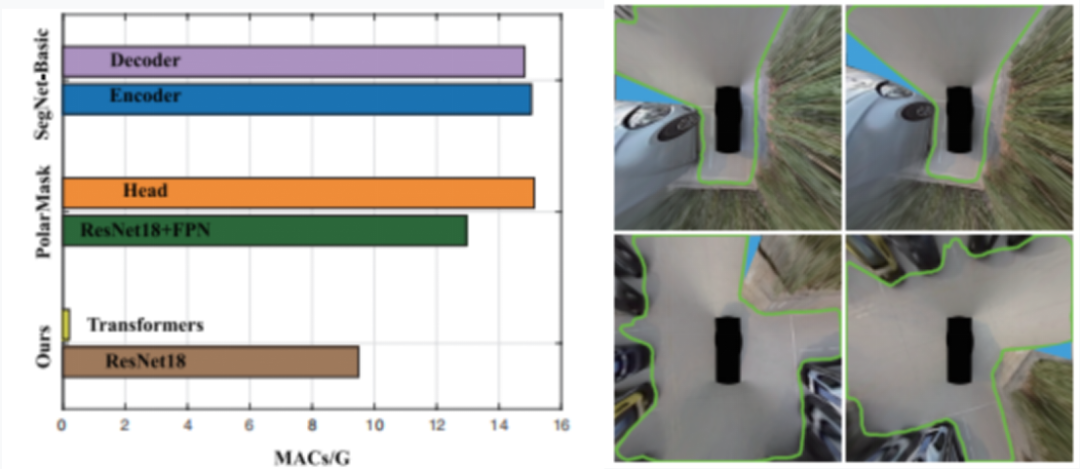
圖 5:(a)計算成本比較。(b)失敗案例
如上右圖所示,SegNet-Basic的解碼器需要14.8個GMAC,由于一系列上采樣操作而導致大量冗余。PolarMask 的頭部也采用了 15.1 個 GMAC 和一系列卷積層。相反,Transformer 僅需要 0.2 GMAC 來預測邊界點,這顯著簡化了過程。
那么T-IoU 損失如何影響學習呢?T-IoU損失在BAE中達到6.94像素。相比之下,l1 損失達到 7.84 BAE,領先 0.90 個像素。邊際表明,使用邊界的整體形狀進行訓練比僅關注孤立點更有效。此外,T-IoU 損失在 BAE 中比 Polar IoU 損失高出 0.42 個像素。我們將這種改進歸因于更好的邊界表示以及對相鄰點之間關系的考慮。
可泊空間預測過程中還有哪些需要深入考慮的問題?
當然,由于傳感器遮擋也可能導致預測失敗。如上右圖,本文提出的極坐標表示方式也無法通過從圖像中心發出的光線覆蓋藍色區域。
同時,由于離散采樣,對自由空間邊界的極坐標表示丟失了部分細節。地面實況極半徑 ?ψρ 可以聚合到采樣地面實況邊界 ?Bs 。為了定量分析損失,我們計算真實邊界 ?B 和采樣真實邊界之間的 BAE 分數邊界 ^Bs ,這是理想的上限。
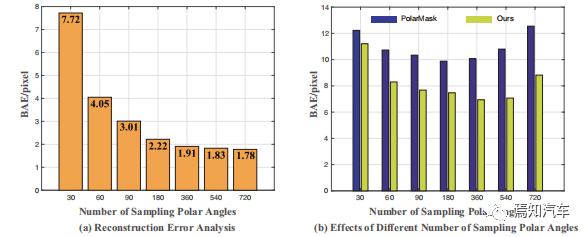
圖 6:(a) 重建誤差分析 ;(b) 不同采樣極角數量的影響
從上圖6(a)中我們觀察到采樣更多的極角可以實現更高的上限并恢復更精細的結構。當采樣極角數量超過 360 時,上限的改進也會變得微不足道。在圖6(b)中,我們對30到720個采樣極角的數量進行了實驗,發現具有360個采樣極角的輸出表現最好。隨著采樣極角數量的增加,模型將接收到更精確的結構信息,并預測更詳細的邊界。然而,當采樣極角的數量太大時,邊界表現得過于離散,模型的能力在編碼如此繁瑣的序列時將受到挑戰,導致平滑度降低。

圖7:解碼器交叉注意力模塊中的注意力圖
如上圖7 顯示了 Transformer 解碼器的交叉注意力模塊中的注意力圖。可以看到,對于序列中的特定極半徑,圖像嵌入與自由空間邊界附近的可能區域有效性相關。角度信息也是通過位置嵌入隱式學習的。
總結
基于視覺的環視可用空間檢測對于自動泊車輔助至關重要。在這項任務中,精確的邊界定位是最受關注的問題。本文提出的方法可概括如下:
通過建議將自由空間重新構建為自由空間邊界的極坐標表示,明顯簡化表示并增強對邊界定位的關注。
利用變壓器框架來解決長序列預測問題。此外,提出了 T-IoU 損失來提高相鄰預測的相關性。
在停車場景中引入了一個大規模數據集,帶有邊界注釋和評估邊界質量的有效指標。本文介紹的方法在大規模數據集上具有良好的性能,并且對新的停車場景表現出很強的泛化能力。
在本文中,我們介紹一種將自由空間重新構建為自由空間邊界的極坐標表示,并利用轉換器框架來端到端地回歸極坐標表示。基于環視自由空間是一個簡單連通區域并且可以在給定邊界的情況下輕松還原對應的聯通部分,這里主張將自由空間檢測轉換為邊界點預測問題。為了有效地對這些點進行建模,我們利用極坐標表示,這在曲線描述中具有固有的優勢。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1131瀏覽量
40676 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45927 -
FCN
+關注
關注
0文章
9瀏覽量
8753 -
ADAS系統
+關注
關注
4文章
226瀏覽量
25678 -
卷積網絡
+關注
關注
0文章
42瀏覽量
2158
原文標題:ADAS系統中的可行使區域Freespace到底如何檢測?---泊車篇
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人臉檢測算法及新的快速算法
雷達目標檢測算法研究及優化
雷達目標檢測算法研究及優化
分享一款高速人臉檢測算法
嵌入式軟件算法優化的原則及其方法
基于YOLOX目標檢測算法的改進
基于閾值優化的圖像模糊邊緣檢測算法
基于空間剖分的碰撞檢測算法
基于概率圖模型的時空異常事件檢測算法
將置信規則庫分級優化的網絡安全態勢預測方法

基于改進的蝗蟲優化算法的LSTM預測方法
基于粒子群算法的車聯網交通流量預測算法






 工商網監
工商網監
評論