 利用 NVIDIA Isaac Transport for ROS 提升自定義 ROS 圖形性能
利用 NVIDIA Isaac Transport for ROS 提升自定義 ROS 圖形性能
NVIDIA Isaac Transport for ROS(NITROS)是隨 ROS 2 Humble 加入的兩項硬件加速功能——類型適配和類型協商。
類型適配使 ROS 節點能夠使用針對特定硬件加速器優化的數據格式進行工作。經過適配的類型用于處理圖形,以消除 CPU 和內存加速器之間的內存拷貝。
通過類型協商,處理圖中的不同 ROS 節點可以公布其支持的類型,ROS 框架也可以選擇數據格式,從而實現理想的性能。
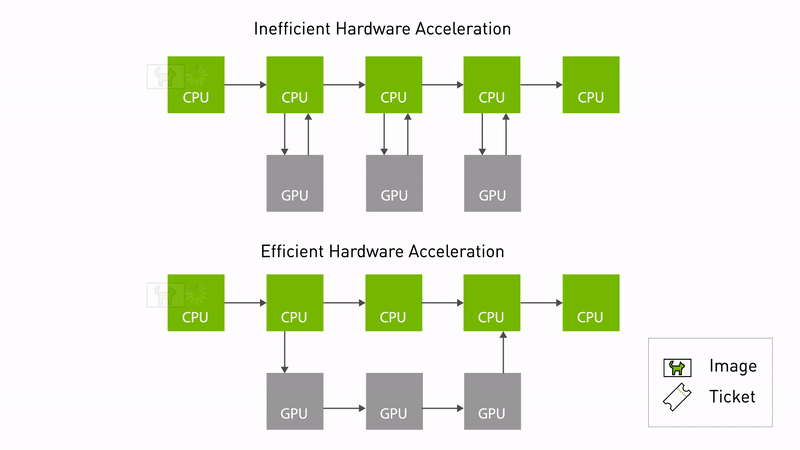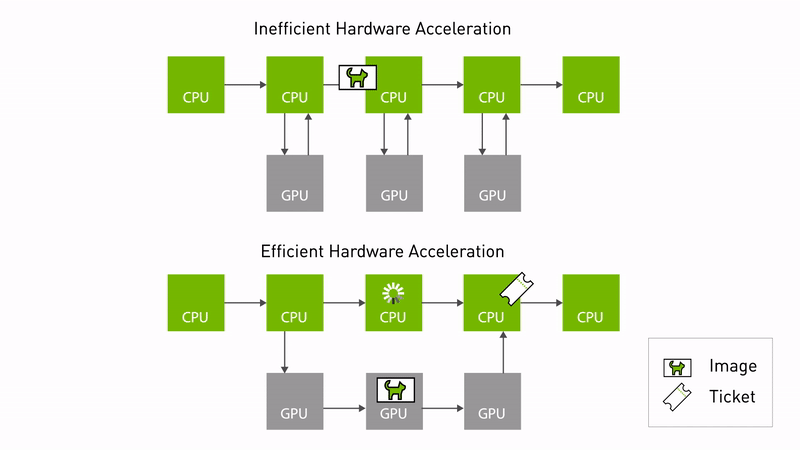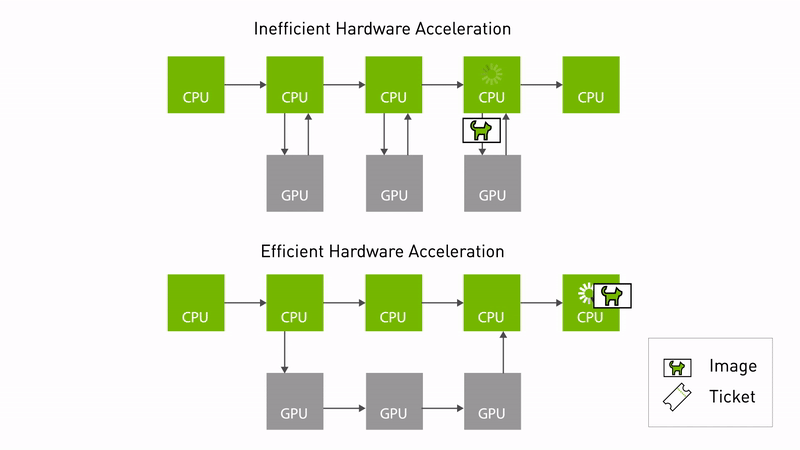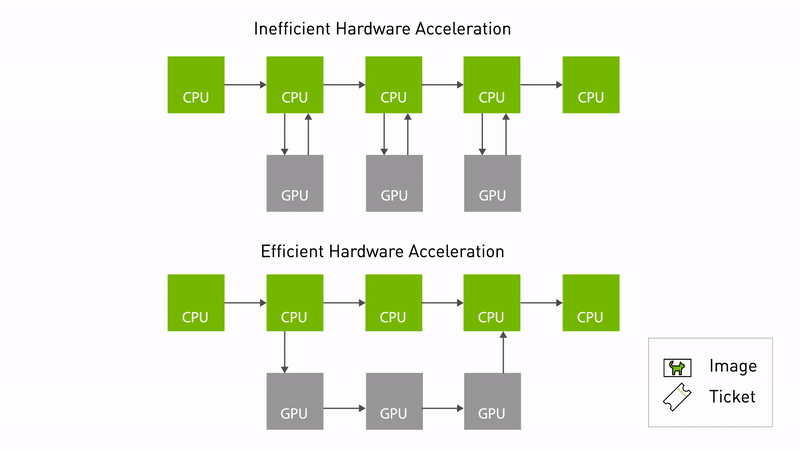
圖 1. NITROS 通過減少 CPU 和
GPU之間的內存拷貝,實現高效加速
當兩個支持 NITROS 的 ROS 節點在圖中相鄰時,它們可以通過類型協商發現對方,然后使用類型適配共享數據。通過消除不必要的內存拷貝,類型適配和類型協商可共同顯著提高基于 ROS 的應用中的 AI 和計算機視覺任務性能。
這不僅減少了 CPU 開銷,還優化了底層硬件的性能。圖 1 顯示了使用 NITROS 的高效硬件加速。數據可以從 GPU 內存中訪問,而不需要頻繁地復制 CPU。
由于 ROS 框架與不支持協商的傳統節點保持兼容,因此可在處理圖中結合使用基于 NITROS 的 Isaac ROS 節點和其他 ROS 節點。支持 NITROS 的節點在與非 NITROS 節點通信時,其功能與典型的 ROS 2 節點相同。大多數 Isaac ROS GEM 都是通過 NITROS 加速的。
請通過NVIDIA NITROS 文檔進一步了解關于 NITROS 和系統假設的更多信息:https://nvidia-isaac-ros.github.io/concepts/nitros/index.html
搭載 NITROS 的 NVIDIA CUDA
NVIDIA CUDA是一種并行計算編程模型,可大幅提高搭載 GPU 的機器人系統的運行速度。自定義 ROS 2 節點可通過代管式 NITROS 發布器和代管式 NITROS 訂閱器,使用搭載 NITROS 的 CUDA。
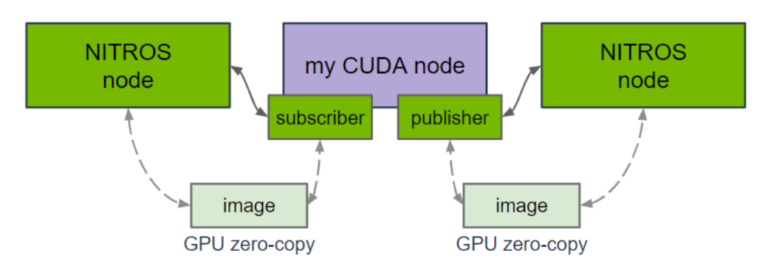
圖 2. 搭載 NITROS 的 CUDA 概覽
ROS 節點中的 CUDA 代碼可以使用代管式 NITROS 發布器,并與支持 NITROS 的 Isaac ROS 節點共享 GPU 內存中的輸出緩沖區。這樣就省去了昂貴的 CPU 內存拷貝步驟,從而提高了性能。NITROS 還能通過發布與普通 ROS 2 消息相同的數據,來保持與非 NITROS 節點的兼容性。
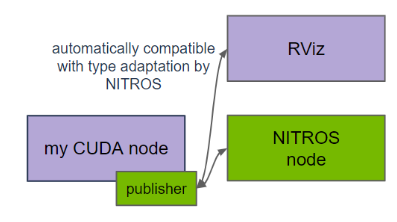
圖 3. ROS 2 節點中的 NITROS 發布器
在訂閱器方面,ROS 節點中的 CUDA 代碼可以使用代管式 NITROS 訂閱器來接收 GPU 內存中的輸入。輸入既可以來自于支持 NITROS 的 Isaac ROS 節點,也可以來自于使用 NITROS 發布器的其他支持 CUDA 的 ROS 節點。與代管式 NITROS 發布器一樣,這也能通過增加 GPU 和 CPU 之間的并行計算來提高性能。
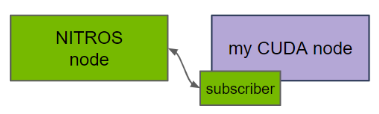
圖 4.ROS 2 節點中的 NITROS 訂閱器
為了更好地理解這一點,讓我們來看一個基于 DNN 的點云分割示例圖。總的來說,有三個主要的組件使用搭載 NITROS 的 CUDA:
-
搭載代管式 NITROS 發布器的編碼器節點:可將 sensor_msgs/PointCloud2 消息轉換為 NitrosTensorList
-
Isaac ROS TensorRT 節點:可執行 DNN 推理,接收輸入 NitrosTensorList 并生成輸出 NitrosTensorList
-
搭載代管式 NITROS 訂閱器的解碼器節點:可將輸出的 NitrosTensorList 轉換為分段的 sensor_msgs/PointCloud2 消息
代管式 NITROS 發布器和訂閱器提供了一個可與標準的 rclcpp::Publisher 和 rclcpp::Subscriber API 相媲美的熟悉界面,使與現有 ROS 2 節點的集成更加直觀。搭載 NITROS 的 CUDA 還能實現更加模塊化的軟件設計。借助代管式 NITROS 發布器和訂閱器,CUDA 節點可以在圖中的任何位置與 Isaac ROS 節點和其他 CUDA 節點一起使用,從而在每個節點上獲得加速計算的優勢。
再深入一點來看,NITROS 是基于 NVIDIA 圖執行框架(GXF)開發的,它是一個用于構建高性能計算圖的可擴展框架。NITROS 利用 GXF 實現了高效的 ROS 應用圖。通過搭載 NITROS 的 CUDA,開發者無需了解使其節點支持 NITROS 的前提條件——GXF 的底層工作原理。GXF 層已被抽象化,用戶只需進行簡單的調整就能啟用 NITROS,從而像往常一樣輕松、快速地編寫 ROS 2 節點。
訪問網址進一步了解搭載 NITROS 的 CUDA 的核心概念:https://nvidia-isaac-ros.github.io/concepts/nitros/cuda_with_nitros.html#core-concepts
目前,代管式 NITROS 發布器和訂閱器僅與 Isaac ROS NitrosTensorList 消息類型兼容。請訪問isaac_ros_nitros_type,查看完整的 NITROS 數據類型列表:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_nitros/tree/main/isaac_ros_nitros_type
使用搭載 NITROS 的 CUDA
和 YOLOv8 進行對象檢測
Isaac ROS 提供了一個YOLOv8 示例:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_object_detection/tree/main/isaac_ros_yolov8,展示了如何使用代管式 NITROS 實用程序和自定義 ROS 解碼器來充分運用 NITROS。該示例使用來自 Isaac ROS DNN Inference 的軟件包,通過 YOLOv8 來執行 TensorRT 加速的對象檢測。代管式 NITROS 發布器和訂閱器使用 NITROS 類型的消息,目前只與 Isaac ROS NitrosTensorList 消息類型兼容。這種消息類型用于在節點和 Isaac ROS DNN Inference 節點之間共享張量。
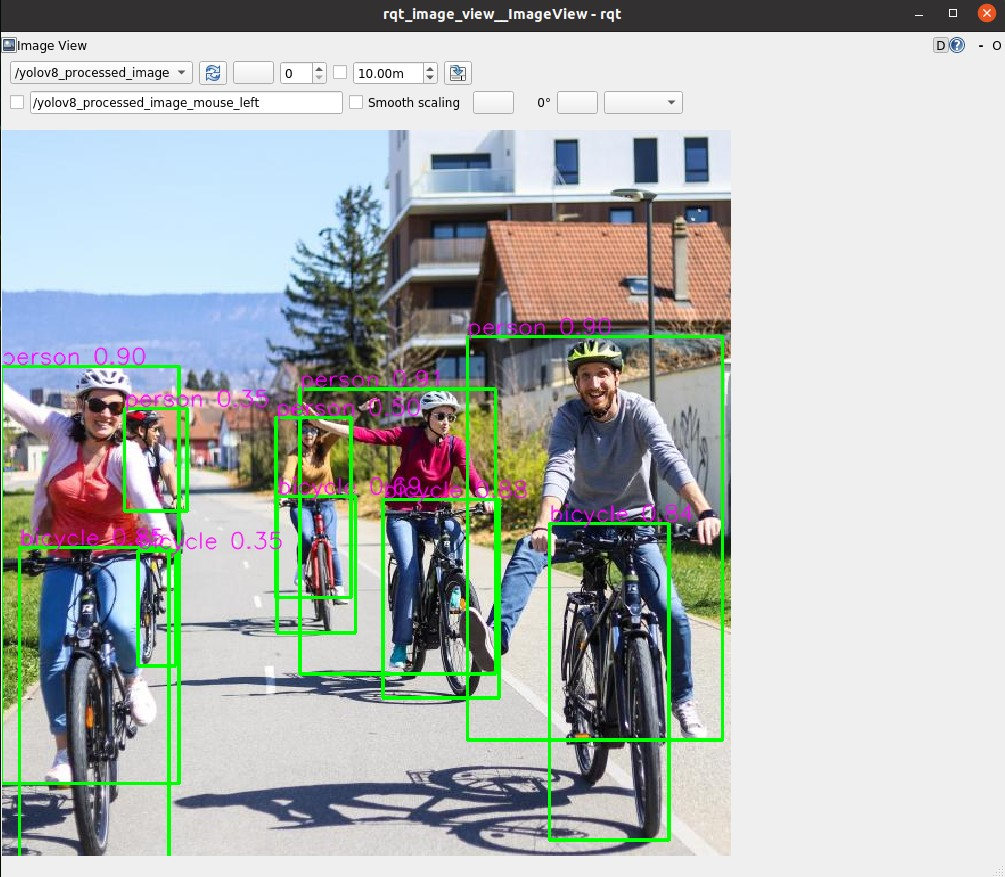
圖 5. 使用 Isaac ROS DNN Inference
檢測 YOLOv8 對象
假設您想使用由 Isaac ROS DNN Inference 和 CUDA NITROS 加速的自定義對象檢測模型,檢測流程涉及輸入圖像編碼、DNN 推理以及輸出解碼三個主要步驟。Isaac ROS DNN Inference 實現了前兩個步驟。
在解碼步驟中,必須從推理結果(即張量)中提取相關信息。對于像 2D 物體檢測這樣的任務,相關信息包括邊界框以及圖像中每個檢測到的輸出的類別得分。
下面讓我們來詳細了解各個步驟。
第 1 步:編碼
在輸入方面,Isaac ROS 提供了一個由 NITROS 加速的 DNN 圖像編碼器。它會對輸入圖像進行預處理,并將其轉換為張量,然后通過 isaac_ros_tensor_list 類型將張量傳遞給 TensorRT 或 Triton 節點進行推理。
您可以為各種預處理功能(如調整大小等)指定圖像大小和網絡期望的輸入大小等參數。請注意,根據任務的不同,您需要使用不同的編碼器。例如,由于網絡期望的輸入編碼不同,您不能在語言模型中使用這種圖像編碼器。
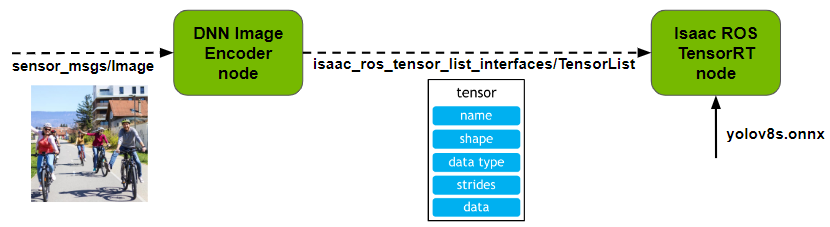
圖 6. Isaac ROS DNN 圖像編碼器節點概覽
第 2 步:推理
Isaac ROS 為 DNN 推理提供兩個 ROS 節點——TensorRT 節點和 Triton 節點。YOLOv8 樣本目前使用其中的 TensorRT 節點。將訓練好的模型提供給 TensorRT 節點,它就能執行推理并輸出包含檢測結果的張量。
輸出的張量列表將傳遞給解碼器節點。您可以指定網絡所期望的維度和張量名稱等參數,并且可以使用 Netron 等工具在 ONNX 模型中輕松找到這些信息。
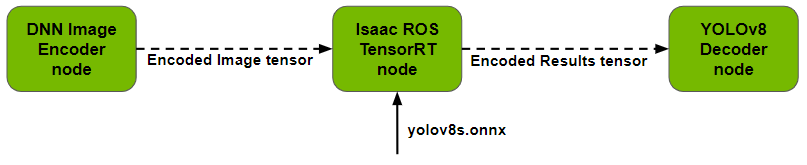
圖 7. Isaac ROS TensorRT 推理節點概覽
第 3 步:解碼
從 TensorRT 或 Triton 節點推理出的輸出張量必須解析為所需的邊界框和類信息。比方說,您把模型的解碼器寫成了 ROS 2 節點(而且還不支持 NITROS)。
解碼器節點并不支持 NITROS 類型的信息,而是期望從推理節點獲得典型的 ROS 2 信息。由于 NITROS 保持了與非 NITROS 節點的兼容性,因此這種方法仍然有效。
不過在這種情況下,推理節點(位于 GPU 內存中)輸出的 NITROS 類型消息會被轉換成 ROS 2 消息,并被傳送到 CPU 內存中供解碼器使用。這將帶來一些開銷,因為數據現在位于 CPU 內存中,導致在與下游 ROS 節點協同工作時需要復制 CPU 內存。
現在,假設您想升級解碼器,以便通過 NITROS 與推理節點(以及其他 NITROS 加速節點)進行通信,而不需要承擔 CPU 內存復制的成本。在這種情況下,所有數據都會保留在 GPU 內存中。
在解碼器節點中使用代管式 NITROS 訂閱器就能輕松實現這一需求。該訂閱器能夠訂閱來自推理節點的 NITROS 類型輸出消息,并使用 NITROS 視圖獲取包含檢測輸出的 CUDA 緩沖區。然后,您就可以對這些數據執行解碼邏輯,并通過適當的 ROS 消息類型發布結果。
YOLOv8 解碼器可設置 NMS 閾值和置信閾值等參數以過濾候選檢測結果。可使用一個簡單的可視化節點訂閱產生的 ROS 消息,并在輸入圖像上繪制邊界框。請注意,代管式 NITROS 只能與 CPP ROS 2 節點集成。
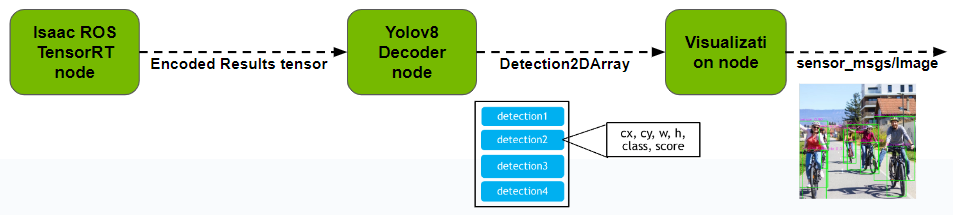
圖 8. YOLOv8 解碼器節點概覽
Isaac ROS NITROS 橋接器
如果您的機器人應用目前基于 ROS 1,仍可以使用新發布的 Isaac ROS NITROS 橋接器來獲得加速計算的紅利。這對使用 ROS 2 版本(Humble 之前的版本)的開發者來說也很有幫助,因為 ROS 2 版本不提供類型適配和協商功能。
NITROS 橋接器在 ROS 1 Noetic 和 NITROS 軟件包之間傳輸 1080p 圖像的速度比 ROS 1 橋接器快 2.5 倍,充分凸顯了所實現的提速效果。
ROS 橋接器會產生基于 CPU 的內存復制成本,而 Isaac ROS NITROS 橋接器通過將數據從 CPU 轉移到 GPU 消除了這一成本。這些數據可以在 GPU 內存中就地使用。
NITROS 橋接器由兩個轉換器節點組成。一個用于 ROS(例如 Noetic)一側,另一個用于 ROS 2(例如 Humble)一側。在不使用 NITROS 轉換器的情況下,使用 ROS 橋接器會導致圖像從 Noetic 發送到 Humble,然后再通過 CPU 內存中的 ROS 進程副本發送回來,從而增加延遲。這個問題在發送大量數據(如分割點云)的節點之間尤為明顯。

圖 9. 不使用 NITROS 轉換器情況下的 ROS 橋接器
NITROS 橋接器的設計目標是減少跨 ROS 版本的端到端延遲。請看同一個例子,這次使用的是 NITROS 轉換器。Noetic 一側的轉換器(圖 10)將圖像移至 GPU 內存,避免了通過橋接器復制 CPU 內存。Humble 側的轉換器(圖 10)將 GPU 內存中的圖像轉換為 NITROS 圖像類型,該類型與其他 NITROS 加速節點兼容。
反之亦然——圖像數據作為 NITROS 圖像通過兩側中任何一側的轉換器從 Humble 發送到位于 Noetic 的 CPU 可訪問內存中的圖像。
更多關于性能提升的信息,請訪問NITROS 橋接器:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_benchmark/blob/main/scripts/isaac_ros_nitros_bridge.py和 ros1 橋接器的Isaac ROS 基準:https://nvidia-isaac-ros.github.io/repositories_and_packages/isaac_ros_benchmark/index.html。請注意,Isaac ROS NITROS 橋接器尚不支持 NVIDIA Jetson 平臺。
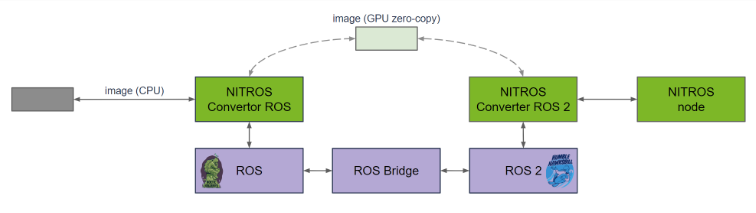
圖 10. NITROS 橋接器概覽
將 ROS 2 節點與 NITROS 集成的益處
下面總結了將 ROS 2 節點與 NITROS 集成的諸多益處:
-
通過減少 CPU 內存拷貝以提高性能。
-
與 RViz 等其他非 NITROS ROS 節點兼容。
-
通過代管式 NITROS 發布器和訂閱器,可輕松將自定義的 ROS 2 節點與硬件加速的 Isaac ROS 節點集成。
-
使用搭載 NITROS 的 CUDA 進行模塊化軟件設計
-
使用 NITROS 橋接器提高基于早期 ROS 版本的應用程序的性能。
嘗試使用 Isaac ROS NITROS 和 YOLOv8 對象檢測樣本,加速您的 ROS 節點吧!
訪問NVIDIA Isaac ROS 文檔頁面了解有關我們硬件加速軟件包的更多信息:https://nvidia-isaac-ros.github.io/index.html
您還可以登陸開發者論壇,了解更多有關 Isaac ROS 的最新信息:https://forums.developer.nvidia.com/c/agx-autonomous-machines/isaac/isaac-ros/600
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標題:利用 NVIDIA Isaac Transport for ROS 提升自定義 ROS 圖形性能
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3743瀏覽量
90830
原文標題:利用 NVIDIA Isaac Transport for ROS 提升自定義 ROS 圖形性能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

TSMaster 自定義 LIN 調度表編程指導

鴻蒙ArkUI實例:【自定義組件】
系統鏡像Ubuntu_ROS2中ROS2是什么意思,帶有ROS2開發環境嗎?
ros怎么設置環境變量
使用 NVIDIA Isaac 仿真并定位 Husky 機器人
在TogetherROS中如何安裝ROS2功能包
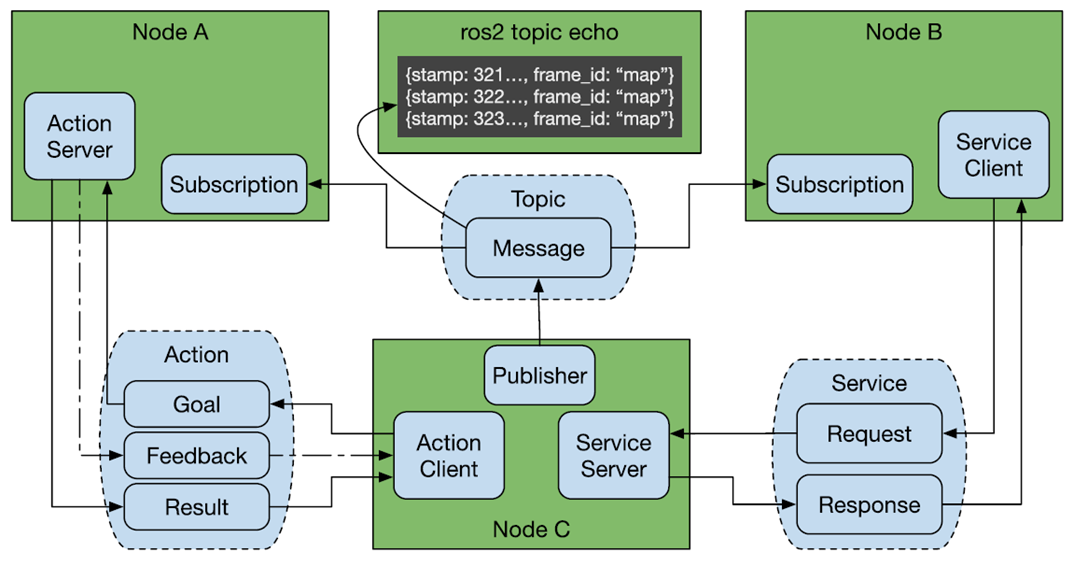
ROS通信接口機制介紹
ROS系統是什么?ROS系統主要特點有哪些?創龍RK3568J+Debian的ROS2系統案例

ROS2中自帶例程測試
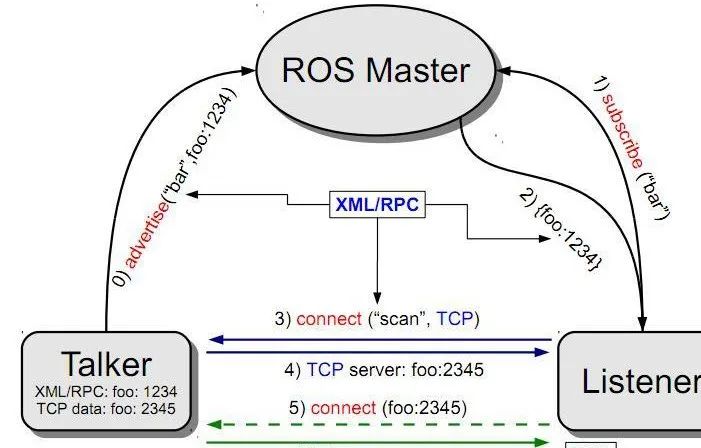
ros1和ros2的通信模型
ros的基本概念是什么
如何創建新的ROS工作空間





 工商網監
工商網監
評論