") 開源LLM在各種基準(zhǔn)上的代理能力
開源LLM在各種基準(zhǔn)上的代理能力
作者:cola
自2022年底ChatGPT發(fā)布以來(lái),其已經(jīng)在人工智能的整個(gè)領(lǐng)域帶來(lái)了翻天覆地的變化。通過(guò)對(duì)大型語(yǔ)言模型(LLM)進(jìn)行指令微調(diào),并從人類反饋中進(jìn)行監(jiān)督微調(diào)和強(qiáng)化學(xué)習(xí),表明模型可以回答人類問題并在廣泛的任務(wù)中遵循指令。在這一成功之后,對(duì)LLM的研究興趣增強(qiáng)了,新的LLM在學(xué)術(shù)界和工業(yè)界頻繁蓬勃發(fā)展。雖然非開源LLM(例如,OpenAI的GPT, Anthropic的Claude)通常優(yōu)于它們的開源同行,但后者的進(jìn)展很快。這對(duì)研究和商業(yè)都有至關(guān)重要的影響。在ChatGPT成立一周年之際,本文對(duì)這類LLMs進(jìn)行了詳盡的介紹。

就在一年前,OpenAI發(fā)布的ChatGPT席卷了AI社區(qū)和廣泛的世界。這是第一次,基于應(yīng)用程序的人工智能聊天機(jī)器人可以為大多數(shù)問題提供有用的、安全的和詳細(xì)的答案,遵循指示,甚至承認(rèn)和修復(fù)以前的錯(cuò)誤。值得注意的是,它可以執(zhí)行傳統(tǒng)上由預(yù)訓(xùn)練然后定制的微調(diào)語(yǔ)言模型完成的任務(wù),如摘要或問答(QA)。作為同類應(yīng)用中的第一個(gè),ChatGPT吸引了普通大眾的關(guān)注,它在發(fā)布后的兩個(gè)月內(nèi)就達(dá)到了1億用戶,比其他流行應(yīng)用如TikTok或YouTube快得多。它還吸引了巨大的商業(yè)投資,因?yàn)樗哂薪档蛣趧?dòng)力成本、自動(dòng)化工作流程甚至為客戶帶來(lái)新體驗(yàn)的潛力。
由于ChatGPT不是開源的,而且它的訪問權(quán)限是由一家私人公司控制的,所以它的大部分技術(shù)細(xì)節(jié)仍然未知。盡管聲稱它遵循InstructGPT(也稱為GPT-3.5)中介紹的過(guò)程,但其確切的架構(gòu)、預(yù)訓(xùn)練數(shù)據(jù)和微調(diào)數(shù)據(jù)是未知的。這種閉源特性產(chǎn)生了幾個(gè)關(guān)鍵問題。
在不知道預(yù)訓(xùn)練和微調(diào)程序等內(nèi)部細(xì)節(jié)的情況下,很難正確估計(jì)其對(duì)社會(huì)的潛在風(fēng)險(xiǎn),特別是知道LLM可以產(chǎn)生有毒、不道德和不真實(shí)的內(nèi)容。
有報(bào)道稱,ChatGPT的性能隨著時(shí)間的推移而變化,妨礙了可重復(fù)性的結(jié)果。
ChatGPT經(jīng)歷了多次宕機(jī),其中最主要的兩次宕機(jī)發(fā)生在2023年11月,當(dāng)時(shí)對(duì)ChatGPT網(wǎng)站及其API的訪問被完全阻斷。
采用ChatGPT的企業(yè)可能會(huì)擔(dān)心API調(diào)用的巨大成本、服務(wù)中斷、數(shù)據(jù)所有權(quán)和隱私問題,以及其他不可預(yù)測(cè)的事件,如最近關(guān)于董事會(huì)解雇CEO Sam Altman以及最終他回歸的戲劇性事件。
而開源LLM提供了一個(gè)有希望的方向,因?yàn)樗鼈兛梢詽撛诘匦迯?fù)或繞過(guò)上述大多數(shù)問題。因此,研究界一直積極推動(dòng)在開源中維護(hù)高性能的LLM。然而,從今天的情況來(lái)看(截至2023年底),人們普遍認(rèn)為開源LLM,如Llama-2或Falcon,落后于它們的非開源同行,如OpenAI的GPT3.5(ChatGPT)和GPT-4,Anthropic的Claude2或谷歌的Bard3,通常認(rèn)為GPT-4是它們的冠軍。
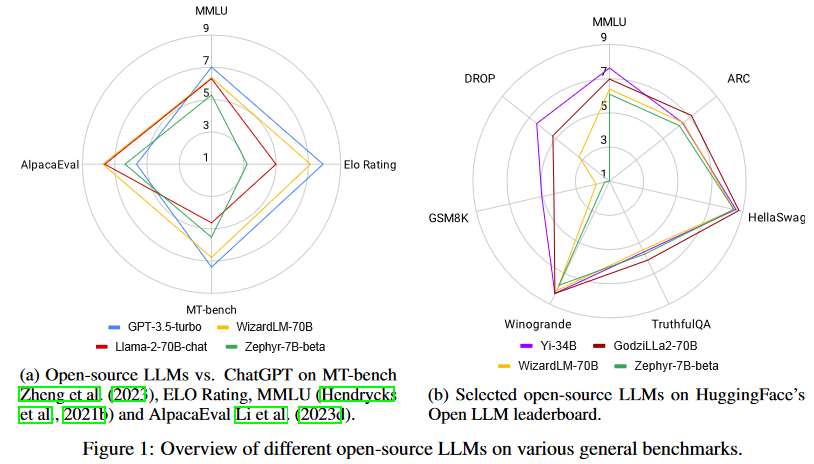
然而,令人鼓舞的是,差距越來(lái)越小,開源LLM正在迅速趕上。事實(shí)上,正如圖1所示,最好的開源LLM在一些標(biāo)準(zhǔn)基準(zhǔn)上的性能已經(jīng)優(yōu)于GPT-3.5-turbo。然而,對(duì)于開源LLM來(lái)說(shuō),這并不是一場(chǎng)簡(jiǎn)單的艱苦戰(zhàn)斗。情況在不斷發(fā)展:非開源LLM通過(guò)定期對(duì)更新的數(shù)據(jù)進(jìn)行再訓(xùn)練來(lái)更新,開源LLM也不斷更新以趕上形勢(shì)變化,并且有無(wú)數(shù)的評(píng)估數(shù)據(jù)集和基準(zhǔn)被用于比較LLM,這使得挑選出一個(gè)最好的LLM特別具有挑戰(zhàn)性。
背景
訓(xùn)練方法
預(yù)訓(xùn)練
所有LLM都依賴于在互聯(lián)網(wǎng)文本數(shù)據(jù)上進(jìn)行大規(guī)模的自監(jiān)督預(yù)訓(xùn)練。僅解碼器的LLM遵循因果語(yǔ)言建模目標(biāo),通過(guò)該目標(biāo),模型學(xué)習(xí)根據(jù)之前的token序列預(yù)測(cè)下一個(gè)token。根據(jù)開源LLM分享的預(yù)訓(xùn)練細(xì)節(jié),文本數(shù)據(jù)的來(lái)源包括CommonCrawl、C4、GitHub、Wikipedia、書籍和在線討論,如Reddit或StackOverFlow。人們普遍認(rèn)為,擴(kuò)展預(yù)訓(xùn)練語(yǔ)料庫(kù)的大小可以提高模型的性能,并與擴(kuò)展模型大小密切相關(guān),這種現(xiàn)象被稱為縮放定律。現(xiàn)代的LLM在數(shù)千億到數(shù)萬(wàn)億token的語(yǔ)料庫(kù)上進(jìn)行預(yù)訓(xùn)練。
微調(diào)
微調(diào)的目的是通過(guò)使用可用的監(jiān)督來(lái)更新權(quán)重,使預(yù)訓(xùn)練的LLM適應(yīng)下游任務(wù),這些監(jiān)督通常時(shí)比預(yù)訓(xùn)練使用的數(shù)據(jù)集小一個(gè)量級(jí)的數(shù)據(jù)集。T5是最早將微調(diào)框架構(gòu)建為文本到文本統(tǒng)一框架的之一,用自然語(yǔ)言指令描述每個(gè)任務(wù)。指令微調(diào)后來(lái)通過(guò)在幾個(gè)任務(wù)上聯(lián)合訓(xùn)練擴(kuò)展了微調(diào),每個(gè)都用自然語(yǔ)言指令進(jìn)行描述。指令微調(diào)迅速流行起來(lái),因?yàn)樗軌虼蠓岣週LM的零樣本性能,包括在unseen任務(wù)上,特別是在更大的模型規(guī)模上。使用多任務(wù)監(jiān)督微調(diào)(通常稱為SFT)的標(biāo)準(zhǔn)指令微調(diào)仍然可以保證模型在安全、道德和無(wú)害的同時(shí)遵循人類意圖,并可以通過(guò)從人類反饋中強(qiáng)化學(xué)習(xí)(RLHF)進(jìn)一步改進(jìn)。
RLHF指的是人類標(biāo)注者對(duì)微調(diào)模型的輸出進(jìn)行排序,用于通過(guò)強(qiáng)化學(xué)習(xí)再次微調(diào)。最近的工作表明,人類反饋可以被LLM的反饋取代,這一過(guò)程稱為從人工智能反饋中強(qiáng)化學(xué)習(xí)(RLAIF)。直接偏好優(yōu)化(DPO)繞過(guò)了像RLHF那樣將獎(jiǎng)勵(lì)模型擬合人類偏好的需要,而是用交叉熵目標(biāo)直接微調(diào)策略,實(shí)現(xiàn)了LLM與人類偏好的更有效對(duì)齊。
在構(gòu)建不同任務(wù)的指令微調(diào)數(shù)據(jù)集時(shí),重點(diǎn)是質(zhì)量而不是數(shù)量:Lima僅在1000個(gè)示例上微調(diào)Llama-65B,表現(xiàn)優(yōu)于GPT-3,而Alpagasus通過(guò)將其指令微調(diào)數(shù)據(jù)集從52k清理到9k,對(duì)Alpaca進(jìn)行了改進(jìn)。
再次預(yù)訓(xùn)練
再預(yù)訓(xùn)練包括從預(yù)訓(xùn)練的LLM執(zhí)行另一輪的預(yù)訓(xùn)練,通常比第一階段的數(shù)據(jù)量更少。這樣的過(guò)程可能有助于快速適應(yīng)新領(lǐng)域或在LLM中引出新屬性。例如,對(duì)Lemur進(jìn)行再次預(yù)訓(xùn)練,以提高編碼和推理能力,對(duì)Llama-2-long進(jìn)行擴(kuò)展上下文窗口。
推理
存在幾種使用LLM進(jìn)行自回歸解碼的序列生成的替代方法,它們的區(qū)別在于輸出的隨機(jī)性和多樣性程度。在采樣期間增加溫度使輸出更加多樣化,而將其設(shè)置為0則會(huì)退回到貪婪解碼,這在需要確定性輸出的場(chǎng)景中可能需要。采樣方法top-k和top-p限制了每個(gè)解碼步驟要采樣的token池。
注意力復(fù)雜度是關(guān)于輸入長(zhǎng)度的二次型,因此一些技術(shù)旨在提高推理速度,特別是在較長(zhǎng)的序列長(zhǎng)度時(shí)。FlashAttention優(yōu)化了GPU內(nèi)存級(jí)之間的讀寫,加速了訓(xùn)練和推理。FlashDecoding將注意力機(jī)制中的key-value(KV)緩存加載并行化,產(chǎn)生8倍的端到端加速。推測(cè)解碼使用一個(gè)額外的小型語(yǔ)言模型來(lái)近似來(lái)自LLM的下一個(gè)token分布,這在不損失性能的情況下加速了解碼。vLLM使用PagedAttention加速LLM推理和服務(wù),PagedAttention是一種優(yōu)化注意力鍵和值的內(nèi)存使用的算法。
任務(wù)域和評(píng)估
由于要執(zhí)行的評(píng)估的多樣性和廣度,正確評(píng)估LLM的能力仍然是一個(gè)活躍的研究領(lǐng)域。Question-answering數(shù)據(jù)集是非常流行的評(píng)估基準(zhǔn),但最近也出現(xiàn)了為L(zhǎng)LM評(píng)估量身定制的新基準(zhǔn)。
開源LLMs vs. ChatGPT
綜合能力
基準(zhǔn)
隨著大量LLM的發(fā)布,每個(gè)LLM都聲稱在某些任務(wù)上具有卓越的性能,確定真正的進(jìn)步和領(lǐng)先的模型變得越來(lái)越具有挑戰(zhàn)性。因此,至關(guān)重要的是全面評(píng)估這些模型在廣泛任務(wù)中的性能,以了解它們的一般能力。本節(jié)涵蓋使用基于LLM(如GPT-4)評(píng)估和傳統(tǒng)(如ROUGE和BLEU)評(píng)估指標(biāo)的基準(zhǔn)。
MT-Bench:旨在從八個(gè)角度測(cè)試多輪對(duì)話和指令遵循能力。分別是寫作、角色扮演、信息提取、推理、數(shù)學(xué)、編碼、知識(shí)I (STEM)和知識(shí)II(人文/社會(huì)科學(xué))。
AlpacaEval:是一個(gè)基于AlpacaFarm評(píng)估集的自動(dòng)評(píng)估器,它測(cè)試了模型遵循一般用戶指令的能力。它利用更強(qiáng)的LLM(如GPT-4和Claude)將候選模型與Davinci-003響應(yīng)進(jìn)行基準(zhǔn)測(cè)試,從而生成候選模型的勝率。
開源LLMs榜單:使用語(yǔ)言模型評(píng)估工具在七個(gè)關(guān)鍵基準(zhǔn)上評(píng)估LLM,包括AI2 Reasoning Challenge、HellaSwag、MMLU、TruthfulQA、Winogrande、GSM8K和DROP。該框架在零樣本和少樣本設(shè)置下,對(duì)各種領(lǐng)域的各種推理和一般知識(shí)進(jìn)行評(píng)估。
BIG-bench:是一個(gè)合作基準(zhǔn),旨在探索LLM并推斷其未來(lái)能力。它包括200多個(gè)新穎的語(yǔ)言任務(wù),涵蓋了各種各樣的主題和語(yǔ)言,這些是現(xiàn)有模型無(wú)法完全解決的。
ChatEval:是一個(gè)多智能體辯論框架,它使多智能體裁判團(tuán)隊(duì)能夠自主地討論和評(píng)估不同模型在開放式問題和傳統(tǒng)自然語(yǔ)言生成任務(wù)上生成的響應(yīng)的質(zhì)量。
Fairval-Vicuna:對(duì)來(lái)自Vicuna基準(zhǔn)的80個(gè)問題進(jìn)行了多證據(jù)校準(zhǔn)和平衡位置校準(zhǔn)。其在采用LLM作為評(píng)估的范式中提供了一個(gè)更公正的評(píng)估結(jié)果,與人類的判斷密切一致。
LLMs的性能
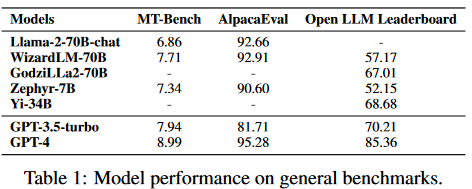
Llama-270B是來(lái)自meta的著名開源LLM,已經(jīng)在2萬(wàn)億token的大規(guī)模數(shù)據(jù)集上進(jìn)行了預(yù)訓(xùn)練。它在各種通用基準(zhǔn)上展示了顯著的結(jié)果。當(dāng)與指令數(shù)據(jù)進(jìn)一步微調(diào)時(shí),Llama2-chat-70B變體在一般會(huì)話任務(wù)中表現(xiàn)出增強(qiáng)的能力。其中,Llama-2-chat-70B在AlpacaEval中取得了92.66%的勝率,將GPT-3.5-turbo的性能提升了10.95%。盡管如此,GPT-4仍然是所有LLM中表現(xiàn)最好的,勝率為95.28%。
另一個(gè)較小的模型Zephyr-7B使用蒸餾進(jìn)行優(yōu)化,在AlpacaEval上取得了與70B LLMs相當(dāng)?shù)慕Y(jié)果,勝率為90.6%。它甚至超過(guò)了Llama-2-chat-70B。此外,WizardLM-70B已經(jīng)使用大量具有不同復(fù)雜度的指令數(shù)據(jù)進(jìn)行了指令微調(diào)。它以7.71的分?jǐn)?shù)脫穎而出,成為MT-Bench上得分最高的開源LLM。然而,這仍然略低于GPT-3.5turbo(7.94)和GPT-4(8.99)。盡管Zephyr-7B在MT-Bench中表現(xiàn)最好,但它在Open LLM排行榜中不出色,得分僅為52.15%。另一方面,GodziLLa2-70B,將Maya Philippines 6和Guanaco Llama 2 1K數(shù)據(jù)集中的各種專有LoRAs與Llama-2-70b相結(jié)合,在Open LLM排行榜上取得了更有競(jìng)爭(zhēng)力的67.01%的分?jǐn)?shù)。Yi-34B從一開始就由開發(fā)人員進(jìn)行了預(yù)訓(xùn)練。AI 7,以68.68%的顯著分?jǐn)?shù)在所有開源LLM中脫穎而出。該性能與GPT-3.5-turbo的70.21%相當(dāng)。然而,兩者仍然明顯落后于GPT-4,后者以85.36%的高分領(lǐng)先。UltraLlama利用了增強(qiáng)多樣性和質(zhì)量的微調(diào)數(shù)據(jù)。它在其建議的基準(zhǔn)中與GPT-3.5-turbo的性能相匹配,同時(shí)在世界和專業(yè)知識(shí)領(lǐng)域超過(guò)了它。
代理能力
基準(zhǔn)
隨著模型規(guī)模的不斷擴(kuò)大,基于LLM的智能體(也稱為語(yǔ)言智能體)引起了NLP社區(qū)的廣泛關(guān)注。鑒于此,本文研究了開源LLM在各種基準(zhǔn)上的代理能力。根據(jù)所需的技能,現(xiàn)有的基準(zhǔn)主要可以分為四類。
使用工具:已經(jīng)提出了一些基準(zhǔn)來(lái)評(píng)估LLM的工具使用能力。
API-Bank是專門為工具增強(qiáng)的LLM設(shè)計(jì)的。
ToolBench 是一個(gè)工具操作基準(zhǔn),包括用于現(xiàn)實(shí)世界任務(wù)的各種軟件工具。
APIBench由HuggingFace、TorchHub和TensorHub的API組成。
ToolAlpaca通過(guò)多智能體仿真環(huán)境開發(fā)了多樣化和全面的工具使用數(shù)據(jù)集。
MINT可以評(píng)估使用工具解決需要多輪交互的任務(wù)的熟練程度。
自調(diào)試(self-debugging):有幾個(gè)數(shù)據(jù)集可用于評(píng)估LLM的自調(diào)試能力。
InterCode-Bash
InterCode-SQL
MINT-MBPP
MINT-HumanEval
RoboCodeGen。
遵循自然語(yǔ)言反饋:
MINT通過(guò)使用GPT-4來(lái)模擬人類用戶,也可用于測(cè)量LLM利用自然語(yǔ)言反饋的能力。
探索環(huán)境:評(píng)估基于LLMs的智能體是否能夠從環(huán)境中收集信息并做出決策。
ALFWorld
InterCode-CTF
WebArena。
LLMs的性能
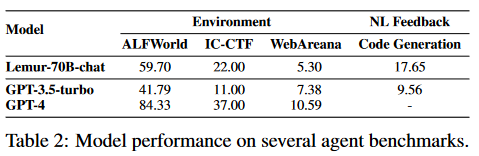
通過(guò)使用包含90B標(biāo)記的代碼密集型語(yǔ)料庫(kù)對(duì)Llama-2進(jìn)行預(yù)訓(xùn)練,并對(duì)包括文本和代碼在內(nèi)的300K示例進(jìn)行指令微調(diào),Lemur-70B-chat在探索環(huán)境或遵循編碼任務(wù)的自然語(yǔ)言反饋時(shí)超過(guò)了GPT-3.5-turbo的性能。AgentTuning使用Llama-2對(duì)其構(gòu)建的AgentInstruct數(shù)據(jù)集和通用域指令進(jìn)行指令調(diào)整,產(chǎn)生AgentLlama。值得注意的是,AgentLlama-70B在未見過(guò)的代理任務(wù)上實(shí)現(xiàn)了與GPT-3.5-turbo相當(dāng)?shù)男阅堋Mㄟ^(guò)在ToolBench上對(duì)Llama-2-7B進(jìn)行微調(diào),ToolLLaMA在工具使用評(píng)估中展示了與GPT3.5-turbo相當(dāng)?shù)男阅堋ireAct,它可以對(duì)Llama-2-13B進(jìn)行微調(diào),以在HotpotQA上超越提示GPT-3.5-turbo。此外,從Llama-7B進(jìn)行微調(diào)的Gorilla在編寫API調(diào)用方面優(yōu)于GPT-4。
邏輯推理能力
基準(zhǔn)
邏輯推理是高級(jí)技能的基本能力,如程序設(shè)計(jì)、定理證明、算術(shù)推理等。我們將介紹以下基準(zhǔn):
GSM8K:由人類問題作者創(chuàng)造的8.5K個(gè)高質(zhì)量的小學(xué)數(shù)學(xué)問題組成。解決這些問題需要2到8步,解決這些問題主要涉及使用基本算術(shù)運(yùn)算以得到最終答案。
MATH:是一個(gè)包含12,500個(gè)具有挑戰(zhàn)性的數(shù)學(xué)競(jìng)賽問題的數(shù)據(jù)集。數(shù)學(xué)中的每個(gè)問題都有一個(gè)完整的分步解決方案,可用于教模型生成答案的推導(dǎo)和解釋。
TheoremQA:是一個(gè)定理驅(qū)動(dòng)的問答數(shù)據(jù)集,旨在評(píng)估人工智能模型應(yīng)用定理解決挑戰(zhàn)性科學(xué)問題的能力。TheoremQA由領(lǐng)域?qū)<也邉潱?00個(gè)高質(zhì)量的問題,涵蓋了數(shù)學(xué)、物理、EE&CS和金融的350個(gè)定理。
HumanEval:是一組164個(gè)手寫編程問題。每個(gè)問題包括一個(gè)函數(shù)簽名、文檔字符串、函數(shù)體和幾個(gè)單元測(cè)試,平均每個(gè)問題7.7個(gè)測(cè)試。
MBPP:(主要基礎(chǔ)編程問題)數(shù)據(jù)集包含974個(gè)短Python程序,這些程序是通過(guò)具有基本Python知識(shí)的內(nèi)部眾包人員構(gòu)建而成。每個(gè)問題都分配了一個(gè)獨(dú)立的Python函數(shù)來(lái)解決指定的問題,以及三個(gè)測(cè)試用例來(lái)檢查函數(shù)的語(yǔ)義正確性。
APPs:是代碼生成的基準(zhǔn),衡量模型采用任意自然語(yǔ)言規(guī)范并生成令人滿意的Python代碼的能力。該基準(zhǔn)包括10,000個(gè)問題,從簡(jiǎn)單的單行解決方案到巨大的算法挑戰(zhàn)。
增強(qiáng)指令微調(diào)
與傳統(tǒng)的基于知識(shí)蒸餾的指令微調(diào)不同,通過(guò)構(gòu)建特定于任務(wù)的高質(zhì)量指令微調(diào)數(shù)據(jù)集,其中種子指令已經(jīng)進(jìn)化到在知識(shí)邊界或任務(wù)復(fù)雜度深度上擴(kuò)展的指令。此外,研究人員還納入了PPO算法,以進(jìn)一步提高生成的指令和答案的質(zhì)量。在獲得擴(kuò)展的指令池之后,通過(guò)收集另一個(gè)LLM(如GPT-3.5-turbo)的響應(yīng)來(lái)生成新的指令微調(diào)數(shù)據(jù)集。得益于改進(jìn)的查詢深度和寬度,微調(diào)后的模型取得了比GPT-3.5-turbo更好的性能。例如,WizardCoder在HumanEval上的性能優(yōu)于GPT3.5-turbo,有19.1%的改進(jìn)。與GPT-3.5-turbo相比,WizardMath在GSM8K上也獲得了42.9%的改進(jìn)。
在具有更高質(zhì)量的數(shù)據(jù)上進(jìn)行預(yù)訓(xùn)練
Lemur驗(yàn)證了自然語(yǔ)言數(shù)據(jù)和代碼能更好的融合,并證實(shí)在函數(shù)調(diào)用、自動(dòng)編程和代理能力方面具有更強(qiáng)能力。Lemur-70B-chat在HumanEval和GSM8K上都比GPT-3.5-turbo取得了顯著的改進(jìn),而無(wú)需特定任務(wù)的微調(diào)。Phi-1和Phi-1.5走了一條不同的道路,將教科書作為預(yù)訓(xùn)練的主要語(yǔ)料庫(kù),這使得在更小的語(yǔ)言模型上可以觀察到強(qiáng)大的能力。
上下文建模能力
基準(zhǔn)
處理長(zhǎng)序列仍然是LLM的關(guān)鍵技術(shù)瓶頸之一,因?yàn)樗心P投际艿接邢薜淖畲笊舷挛拇翱诘南拗疲ǔ?k到8k token長(zhǎng)度。對(duì)LLM的上下文能力進(jìn)行基準(zhǔn)測(cè)試涉及對(duì)幾個(gè)自然具有長(zhǎng)上下文的任務(wù)進(jìn)行評(píng)估,如抽象摘要或多文檔QA。以下基準(zhǔn)已被提出用于LLMs的長(zhǎng)上下文評(píng)估:
SCROLLS:是一個(gè)流行的評(píng)估基準(zhǔn),由7個(gè)具有自然長(zhǎng)輸入的數(shù)據(jù)集組成。任務(wù)涵蓋摘要、問答和自然語(yǔ)言推理。
ZeroSCROLLS:建立在SCROLLS上(丟棄ContractNLI,重用6個(gè)其他數(shù)據(jù)集,并添加4個(gè)數(shù)據(jù)集),并且只考慮零樣本設(shè)置。
LongBench:在6個(gè)任務(wù)中設(shè)置了21個(gè)數(shù)據(jù)集的英漢雙語(yǔ)長(zhǎng)上下文基準(zhǔn)。
L-Eval:重用了16個(gè)現(xiàn)有的數(shù)據(jù)集,并從頭創(chuàng)建了4個(gè)數(shù)據(jù)集,以創(chuàng)建一個(gè)多樣化的長(zhǎng)上下文基準(zhǔn),每個(gè)任務(wù)的平均長(zhǎng)度超過(guò)4k token。作者主張使用LLM進(jìn)行評(píng)估(特別是GPT-4),而不是N-gram進(jìn)行長(zhǎng)上下文評(píng)估。
BAMBOO:創(chuàng)建了一個(gè)長(zhǎng)上下文LLM評(píng)估基準(zhǔn),通過(guò)僅收集評(píng)估數(shù)據(jù)集中的最新數(shù)據(jù),專注于消除預(yù)訓(xùn)練數(shù)據(jù)污染。
M4LE:引入了一個(gè)廣泛的基準(zhǔn),將36個(gè)數(shù)據(jù)集劃分為5種理解能力:顯式single-span、語(yǔ)義single-span、顯式multiple-span、語(yǔ)義multiple-span和全局理解。
模型
在LongBench、L-Eval、BAMBOO和M4LE基準(zhǔn)上,GPT-3.5-turbo或其16k版本的性能基本上超過(guò)了所有開源LLM,這表明提高開源LLM在長(zhǎng)輸入任務(wù)上的性能并非易事。Llama-2-long使用16k上下文窗口(從Llama-2的4k增加到400B token)繼續(xù)對(duì)Llama-2進(jìn)行預(yù)訓(xùn)練。由此產(chǎn)生的Llama-2-long-chat-70B在ZeroSCROLLS上的性能比GPT-3.5-turbo-16k高出37.7到36.7。解決長(zhǎng)上下文任務(wù)的方法包括使用位置插值的上下文窗口擴(kuò)展,這涉及另一輪微調(diào)與較長(zhǎng)的上下文窗口,以及檢索增強(qiáng)。研究人員結(jié)合了這兩種看似相反的技術(shù),在7個(gè)長(zhǎng)上下文任務(wù)(包括來(lái)自ZeroSCROLLS的4個(gè)數(shù)據(jù)集)中,平均推動(dòng)Llama-2-70B超過(guò)GPT-3.5-turbo-16k。
特定應(yīng)用能力
面向查詢摘要
基準(zhǔn):聚焦查詢或基于方面的摘要需要生成關(guān)于細(xì)粒度問題或方面類別的摘要。面向查詢的數(shù)據(jù)集包括AQualMuse、QMSum和SQuALITY,而基于方面的數(shù)據(jù)集包括CovidET、NEWTS、WikiAsp等。
模型:與ChatGPT相比,訓(xùn)練數(shù)據(jù)上的標(biāo)準(zhǔn)微調(diào)在性能上仍然更好,比CovidET、NEWTS、QMSum和SQuALITY平均提高了2點(diǎn)ROUGE-1。
開放式QA
基準(zhǔn):開放式QA有兩個(gè)子類:答案要么是短形式,要么是長(zhǎng)形式。短格式數(shù)據(jù)集包括SQuAD 1.1、NewsQA、TriviaQA、SQuAD 2.0、NarrativeQA、Natural Question (NQ)、Quoref和DROP。長(zhǎng)格式數(shù)據(jù)集包括ELI5和doc2dial。對(duì)于短文和長(zhǎng)篇數(shù)據(jù)集,評(píng)估指標(biāo)都是答案中單詞的精確匹配(EM)和F1。回答開放式QA要求模型理解提供的上下文,或者在沒有提供上下文的情況下檢索相關(guān)知識(shí)。
模型:InstructRetro在NQ、TriviaQA、SQuAD 2.0和DROP上比GPT-3有很大的改進(jìn),同時(shí)在一系列長(zhǎng)短開放式QA數(shù)據(jù)集上,與類似大小的專有GPTinstruct模型相比,有7-10%的改進(jìn)。InstructRetro從預(yù)訓(xùn)練的GPT模型初始化,通過(guò)檢索繼續(xù)預(yù)訓(xùn)練,然后進(jìn)行指令微調(diào)。
醫(yī)學(xué)領(lǐng)域
基準(zhǔn):對(duì)于心理健康,IMHI基準(zhǔn)使用10個(gè)現(xiàn)有的心理健康分析數(shù)據(jù)集構(gòu)建,包括心理健康檢測(cè):DR、CLP、Dreaddit、loneliness、SWMH和T-SID;心理健康原因檢測(cè):SAD、CAMS;心理風(fēng)險(xiǎn)因素檢測(cè):MultiWD、IRF。對(duì)于放射學(xué),OpenI數(shù)據(jù)集和MIMIC-CXR數(shù)據(jù)集都包含有發(fā)現(xiàn)和印象文本的放射學(xué)報(bào)告。
模型:為了心理健康,MentalLlama-chat-13B在IMHI訓(xùn)練集上對(duì)Llama-chat-13B模型進(jìn)行了微調(diào)。零樣本提示的MentalLlama-chat-13B模型在IMHI的10個(gè)任務(wù)中有9個(gè)表現(xiàn)優(yōu)于少樣本提示或零樣本提示的ChatGPT。還有研究人員對(duì)Llama檢查點(diǎn)進(jìn)行微調(diào),以根據(jù)放射學(xué)報(bào)告發(fā)現(xiàn)生成印象文本。由此產(chǎn)生的Radiology-Llama-2模型在MIMIC-CXR和OpenI數(shù)據(jù)集上都以很大的優(yōu)勢(shì)優(yōu)于ChatGPT和GPT-4。
生成結(jié)構(gòu)化響應(yīng)
基準(zhǔn):Rotowire包含NBA比賽摘要和相應(yīng)的得分表。Struc-Bench介紹了兩個(gè)數(shù)據(jù)集:Struc-Bench-Latex,其中輸出為L(zhǎng)atex格式的表格,Struc-Bench-HTML輸出為HTML格式的表格。
模型:Struc-Bench在結(jié)構(gòu)化生成數(shù)據(jù)上微調(diào)Llama-7B模型。微調(diào)后的7B模型在上述所有基準(zhǔn)上的表現(xiàn)都優(yōu)于ChatGPT。
生成評(píng)論
基準(zhǔn):LLM的一個(gè)有趣的能力是對(duì)問題的回答提供反饋或批評(píng)。為了對(duì)這種能力進(jìn)行基準(zhǔn)測(cè)試,人們可以使用人工標(biāo)注者或GPT-4作為評(píng)估者,直接對(duì)評(píng)論進(jìn)行評(píng)分。原始問題可以來(lái)自上述任何具有其他功能的數(shù)據(jù)集。
模型:Shepherd是一個(gè)從Llama-7B初始化的7B模型,并在社區(qū)收集的批判數(shù)據(jù)和1,317個(gè)高質(zhì)量人工標(biāo)注數(shù)據(jù)示例上進(jìn)行訓(xùn)練。Shepherd在一系列不同的NLP數(shù)據(jù)集上生成評(píng)論:AlpacaFarm、FairEval、CosmosQA、OBQA、PIQA、TruthfulQA和CritiqueEval。使用GPT-4作為評(píng)估器,Shepherd在60%以上的情況下會(huì)贏或等于ChatGPT。在人工評(píng)估方面,Shepherd幾乎可以與ChatGPT相提并論。
走向值得信賴的AI
為了確保LLM在現(xiàn)實(shí)世界的應(yīng)用中可以被人類信任,一個(gè)重要的考慮因素是它們的可靠性。例如,幻覺和安全性可能會(huì)惡化用戶對(duì)LLM的信任,并在高影響的應(yīng)用中導(dǎo)致風(fēng)險(xiǎn)。
幻覺
基準(zhǔn):為了更好地評(píng)估LLM中的幻覺,人們提出了各種基準(zhǔn)。具體來(lái)說(shuō),它們由大規(guī)模數(shù)據(jù)集、自動(dòng)化指標(biāo)和評(píng)估模型組成。
TruthfulQA:是一個(gè)基準(zhǔn)問答(QA)數(shù)據(jù)集,由跨越38個(gè)類別的問題組成。這些問題被精心設(shè)計(jì),以至于一些人類也會(huì)由于誤解而錯(cuò)誤地回答它們。
FactualityPrompts:是一個(gè)為開放式一代測(cè)量幻覺的數(shù)據(jù)集。它由事實(shí)提示和非事實(shí)提示組成,以研究提示對(duì)LLM的持續(xù)影響。
HaluEval:是一個(gè)由生成的和人工標(biāo)注的幻覺樣本組成的大型數(shù)據(jù)集。它跨越了三個(gè)任務(wù):問答、以知識(shí)為基礎(chǔ)的對(duì)話和文本摘要。
FACTOR:提出了一種可擴(kuò)展的語(yǔ)言模型真實(shí)性評(píng)估方法,它自動(dòng)將事實(shí)語(yǔ)料庫(kù)轉(zhuǎn)換為忠實(shí)度評(píng)估基準(zhǔn)。該框架用于創(chuàng)建Wiki-FACTOR和News-FACTOR基準(zhǔn)。
KoLA:構(gòu)建了一個(gè)面向知識(shí)的LLM評(píng)估基準(zhǔn)(KoLA),具有三個(gè)關(guān)鍵因素分別是,模仿人類認(rèn)知進(jìn)行能力建模,使用維基百科進(jìn)行數(shù)據(jù)收集,以及設(shè)計(jì)用于自動(dòng)幻覺評(píng)估的對(duì)比指標(biāo)。
FActScore:提出了一種新的評(píng)估方法,首先將LLM的生成分解為一系列原子事實(shí),然后計(jì)算可靠知識(shí)源支持的原子事實(shí)的百分比。
Vectara’s Hallucination Evaluation Model:是一個(gè)小型的語(yǔ)言模型,它被微調(diào)為二進(jìn)制分類器,以將摘要分類為與源文檔事實(shí)一致(或不一致)。然后,用它來(lái)評(píng)估和基準(zhǔn)各種LLM生成摘要的幻覺。
FacTool:是一個(gè)任務(wù)和領(lǐng)域無(wú)關(guān)的框架,用于檢測(cè)LLM生成的文本的事實(shí)錯(cuò)誤。
除了新引入的幻覺基準(zhǔn),之前基于現(xiàn)實(shí)世界知識(shí)的QA數(shù)據(jù)集也被廣泛用于測(cè)量忠實(shí)度,如HotpotQA、OpenBookQA、MedMC-QA 和TriviaQA。除了數(shù)據(jù)集和自動(dòng)化指標(biāo),人工評(píng)估也被廣泛采用作為忠實(shí)度的可靠度量。
模型:超越當(dāng)前GPT-3.5-turbo性能的方法可以在微調(diào)期間納入,也可以只在推理時(shí)納入。所選性能指標(biāo)如表3所示。在微調(diào)過(guò)程中,提高數(shù)據(jù)質(zhì)量的正確性和相關(guān)性,可以減少模型的幻覺。研究人員策劃了一個(gè)內(nèi)容過(guò)濾、指令微調(diào)的數(shù)據(jù)集,重點(diǎn)關(guān)注STEM領(lǐng)域的高質(zhì)量數(shù)據(jù)。一個(gè)LLM族在這個(gè)過(guò)濾后的數(shù)據(jù)集上進(jìn)行微調(diào)并合并,由此產(chǎn)生的家族,名為Platypus,與GPT-3.5-turbo相比,在TruthfulQA上有了實(shí)質(zhì)性的改進(jìn)(約20%)。
在推理過(guò)程中,現(xiàn)有技術(shù)包括特定的解碼策略、外部知識(shí)增強(qiáng)和多智能體對(duì)話。對(duì)于解碼有Chain-of-Verification(CoVe),其中LLM起草驗(yàn)證問題并自驗(yàn)證響應(yīng)。CoVe使FactScore比GPT-3.5-turbo有了實(shí)質(zhì)性的改進(jìn)。
對(duì)于外部知識(shí)擴(kuò)充,各種框架結(jié)合了不同的搜索和提示技術(shù),以提高當(dāng)前GPT-3.5-turbo的性能。Chain-ofKnowledge(CoK)在回答問題之前從異構(gòu)的知識(shí)源中檢索。LLM-AUGMENTER用一組即插即用模塊增強(qiáng)LLM,并迭代修訂LLM提示,以使用效用函數(shù)生成的反饋改善模型響應(yīng)。Knowledge Solver (KSL)試圖通過(guò)利用自身強(qiáng)大的通用性,教會(huì)LLM從外部知識(shí)庫(kù)中搜索基本知識(shí)。CRITIC允許LLM以類似于人類與工具交互的方式驗(yàn)證和逐步修正自己的輸出。Parametric Knowledge Guiding(PKG)框架為L(zhǎng)LM配備了一個(gè)知識(shí)指導(dǎo)模塊,以在不改變參數(shù)的情況下訪問相關(guān)知識(shí)。與使用GPT-3.5-turbo的樸素提示策略相比,這些推理技術(shù)提高了答案的準(zhǔn)確性。目前,GPT-3.5-turbo還包含了一個(gè)檢索插件,可以訪問外部知識(shí)以減少幻覺。
對(duì)于多智能體對(duì)話,研究人員促進(jìn)了生成聲明的考生LLM和引入問題以發(fā)現(xiàn)不一致的另一個(gè)考官LLM之間的多輪交互。通過(guò)交叉檢查過(guò)程,各種QA任務(wù)的性能得到了提高。另外的方法要求多個(gè)語(yǔ)言模型實(shí)例在多輪中提出并辯論各自的響應(yīng)和推理過(guò)程,以得出共同的最終答案,這在多個(gè)基準(zhǔn)上都有所提高。

安全性
基準(zhǔn):LLM中的安全問題主要可以分為三個(gè)方面:社會(huì)偏見、模型魯棒性和中毒問題。為了收集更好地評(píng)估上述方面的數(shù)據(jù)集,人們提出了幾個(gè)基準(zhǔn):
SafetyBench:是一個(gè)由11435個(gè)不同的選擇題組成的數(shù)據(jù)集,涵蓋7個(gè)不同的安全問題類別。
Latent Jailbreak:引入了一個(gè)評(píng)估LLM安全性和魯棒性的基準(zhǔn),強(qiáng)調(diào)了平衡方法的必要性。
XSTEST:是一個(gè)測(cè)試套件,系統(tǒng)地識(shí)別夸張的安全行為,例如拒絕安全提示。
RED-EVAL:是一個(gè)基準(zhǔn),用于執(zhí)行red-teaming以使用基于Chain of Utterances(CoU)的提示對(duì)LLM進(jìn)行安全評(píng)估。
除了自動(dòng)化基準(zhǔn)之外,安全性的一個(gè)重要衡量標(biāo)準(zhǔn)是人工評(píng)估。一些研究也試圖從GPT-4中收集此類標(biāo)簽。
模型:基于當(dāng)前評(píng)估,GPT-3.5-turbo和GPT-4模型在安全性評(píng)估方面仍然處于領(lǐng)先地位。這在很大程度上歸因于人類反饋強(qiáng)化學(xué)習(xí)(RLHF)。RLHF首先收集人類對(duì)響應(yīng)的偏好數(shù)據(jù)集,然后訓(xùn)練一個(gè)獎(jiǎng)勵(lì)模型來(lái)模仿人類的偏好,最后使用RL訓(xùn)練LLM來(lái)對(duì)齊人類的偏好。在這個(gè)過(guò)程中,LLM學(xué)習(xí)展示所需的行為,并排除有害的反應(yīng),如不禮貌或有偏見的答案。然而,RLHF過(guò)程需要收集大量昂貴的人工注釋,這阻礙了它用于開源LLM。為推動(dòng)LLM安全對(duì)齊的努力,研究人員收集了一個(gè)人類偏好數(shù)據(jù)集,以從人類偏好得分中分離出無(wú)害和有用性,從而為兩個(gè)指標(biāo)提供了單獨(dú)的排名數(shù)據(jù)。另有研究人員試圖通過(guò)人工智能反饋(RLAIF)來(lái)提高RL的安全性,其中使用LLM生成的自我批評(píng)和修正來(lái)訓(xùn)練偏好模型。直接偏好優(yōu)化減少了學(xué)習(xí)獎(jiǎng)勵(lì)模型的需要,并通過(guò)簡(jiǎn)單的交叉熵?fù)p失直接從偏好中學(xué)習(xí),這可以在很大程度上降低RLHF的成本。結(jié)合和改進(jìn)這些方法可能會(huì)導(dǎo)致開源LLM安全性的潛在改進(jìn)。
討論
LLMs的發(fā)展趨勢(shì)
自從研究人員證明了凍結(jié)的GPT-3模型可以在各種任務(wù)上實(shí)現(xiàn)令人印象深刻的零樣本和少樣本性能以來(lái),人們?yōu)橥七M(jìn)LLM的發(fā)展做出了許多努力。研究重點(diǎn)是擴(kuò)大模型參數(shù),包括Gopher、GLaM、LaMDA、MT-NLG和PaLM,最終達(dá)到540B參數(shù)。盡管這些模型表現(xiàn)出了非凡的能力,但閉源的性質(zhì)限制了它們廣泛應(yīng)用,從而導(dǎo)致人們對(duì)開發(fā)開源LLM的興趣日益濃厚。
另一項(xiàng)研究沒有擴(kuò)大模型大小,而是探索了預(yù)訓(xùn)練較小模型的更好策略或目標(biāo),如Chinchilla和UL2。除了預(yù)訓(xùn)練之外,還將相當(dāng)大的精力用于研究語(yǔ)言模型的指令微調(diào),例如FLAN、T0和FLAN-T5。
一年前OpenAI的ChatGPT的出現(xiàn)極大地改變了NLP社區(qū)的研究重點(diǎn)。為了趕上OpenAI,谷歌和Anthropic分別引入了Bard和Claude。雖然它們?cè)谠S多任務(wù)上表現(xiàn)出與ChatGPT相當(dāng)?shù)男阅埽c最新的OpenAI模型GPT-4之間仍然存在性能差距。由于這些模型的成功主要?dú)w功于從人工反饋中強(qiáng)化學(xué)習(xí)(RLHF),研究人員探索了各種改進(jìn)RLHF的方法。
為了促進(jìn)開源LLM的研究,Meta發(fā)布了Llama系列模型。從那時(shí)起,基于Llama的開源模型開始爆炸式地出現(xiàn)。一個(gè)有代表性的研究方向是利用指令數(shù)據(jù)對(duì)Llama進(jìn)行微調(diào),包括Alpaca、Vicuna、Lima和WizardLM。正在進(jìn)行的研究還探索了改進(jìn)代理、邏輯推理和長(zhǎng)上下文建模等能力。此外,許多工作都致力于從頭開始訓(xùn)練強(qiáng)大的LLM,而不是基于Llama開發(fā),例如MPT、Falcon、XGen、Phi、Baichuan、Mistral、Grok和Yi。我們相信,開發(fā)更強(qiáng)大、更高效的開源LLM,使閉源LLM的能力民主化,應(yīng)該是一個(gè)非常有前途的未來(lái)方向。
結(jié)果總結(jié)
對(duì)于一般功能,Llama-2-chat-70B在一些基準(zhǔn)中顯示了比GPT3.5-turbo的改進(jìn),但仍然落后于大多數(shù)其他測(cè)試。Zephir-7B 通過(guò)蒸餾直接偏好優(yōu)化接近70B LLMs。WizardLM70B和GodziLLa-70B可以實(shí)現(xiàn)與GPT-3.5-turbo相當(dāng)?shù)男阅埽@表明了一條有前途的道路。
開源的LLM能夠通過(guò)更廣泛和特定任務(wù)的預(yù)訓(xùn)練和微調(diào)超越GPT-3.5-turbo。例如,Lemur-70B-chat在探索環(huán)境和跟蹤編碼任務(wù)的反饋方面表現(xiàn)更好。AgentTuning改進(jìn)了未見過(guò)的代理任務(wù)。ToolLLama可以更好地掌握工具的使用。Gorilla在編寫API調(diào)用方面優(yōu)于GPT-4。對(duì)于邏輯推理,WizardCoder和WizardMath通過(guò)增強(qiáng)的指令微調(diào)來(lái)提高推理能力。Lemur和Phi通過(guò)對(duì)更高質(zhì)量的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,實(shí)現(xiàn)了更強(qiáng)的能力。對(duì)于長(zhǎng)上下文建模,Llama-2-long可以通過(guò)使用更長(zhǎng)的token和更大的上下文窗口進(jìn)行預(yù)訓(xùn)練來(lái)提高選定的基準(zhǔn)。對(duì)于特定應(yīng)用的能力,InstructRetro通過(guò)檢索和指令微調(diào)的預(yù)訓(xùn)練,改進(jìn)了開放式QA。通過(guò)特定任務(wù)的微調(diào),MentaLlama-chat13B在心理健康分析數(shù)據(jù)集上的表現(xiàn)優(yōu)于GPT-3.5-turbo。RadiologyLlama2可以提高放射學(xué)報(bào)告的性能。只有7B參數(shù)的Shepherd在生成模型反饋和批評(píng)方面可以實(shí)現(xiàn)與GPT-3.5-turbo相當(dāng)或更好的性能。對(duì)于可信的人工智能,可以通過(guò)對(duì)更高質(zhì)量的數(shù)據(jù)進(jìn)行微調(diào)、上下文感知解碼技術(shù)、外部知識(shí)增強(qiáng)來(lái)減少幻覺。
還有一些領(lǐng)域GPT-3.5-turbo和GPT-4仍然是不可戰(zhàn)勝的,例如人工智能安全。由于GPT模型涉及大規(guī)模的RLHF,它們被認(rèn)為表現(xiàn)出更安全、更符合道德的行為,這可能是商業(yè)LLM比開源LLM更重要的考慮因素。然而,隨著最近對(duì)RLHF進(jìn)程民主化的努力,我期待看到開源LLM在安全性方面的更多性能改進(jìn)。
最佳的開源LLMs配方
訓(xùn)練LLM涉及復(fù)雜和資源密集的實(shí)踐,包括數(shù)據(jù)收集和預(yù)處理,模型設(shè)計(jì)和訓(xùn)練過(guò)程。雖然定期發(fā)布開源LLM的趨勢(shì)越來(lái)越大,但遺憾的是,主要模型的詳細(xì)實(shí)現(xiàn)細(xì)節(jié)往往保密。下面我們列出了一些社區(qū)廣泛認(rèn)可的最佳實(shí)現(xiàn)要點(diǎn)。
數(shù)據(jù)
預(yù)訓(xùn)練涉及使用數(shù)萬(wàn)億的數(shù)據(jù)tokens,這些tokens通常是公開。從倫理上講,至關(guān)重要的是排除任何包括私人信息的數(shù)據(jù)。與預(yù)訓(xùn)練數(shù)據(jù)不同,微調(diào)數(shù)據(jù)的數(shù)量更少,但質(zhì)量更高。具有高質(zhì)量數(shù)據(jù)的微調(diào)LLM表現(xiàn)出了更好的性能,特別是在特定領(lǐng)域。
模型結(jié)構(gòu)
雖然大多數(shù)LLM利用只有解碼器的Transformer架構(gòu),但模型中采用了不同的技術(shù)來(lái)優(yōu)化效率。Llama-2實(shí)現(xiàn)了Ghost注意力以改進(jìn)多輪對(duì)話控制。Mistral利用滑動(dòng)窗口注意力來(lái)處理擴(kuò)展的上下文長(zhǎng)度。
訓(xùn)練
使用指令微調(diào)數(shù)據(jù)進(jìn)行監(jiān)督式微調(diào)(SFT)的過(guò)程至關(guān)重要。對(duì)于高質(zhì)量的結(jié)果,數(shù)萬(wàn)個(gè)SFT注釋就足夠了,Llama-2使用的27540個(gè)注釋就證明了這一點(diǎn)。在RLHF階段,近端策略優(yōu)化(PPO)通常是首選的算法,以更好地使模型的行為與人類偏好和指令遵循相一致,在增強(qiáng)LLM安全性方面發(fā)揮著關(guān)鍵作用。PPO的另一種選擇是直接偏好優(yōu)化(DPO)。例如,Zephyr-7B采用了蒸餾的DPO,并在各種通用基準(zhǔn)上顯示了與70B-LLMs相當(dāng)?shù)慕Y(jié)果,甚至超過(guò)了AlpacaEval上的GPT-3.5-turbo。
潛在問題
預(yù)訓(xùn)練期間的數(shù)據(jù)污染
隨著基礎(chǔ)模型的發(fā)布,數(shù)據(jù)污染的問題變得越來(lái)越明顯,這些模型模糊了其預(yù)訓(xùn)練語(yǔ)料庫(kù)的來(lái)源。這種透明度的缺乏可能會(huì)導(dǎo)致人們對(duì)LLM的真正泛化能力的偏見。忽略基準(zhǔn)數(shù)據(jù)通過(guò)人類專家的注釋或更大的模型手動(dòng)集成到訓(xùn)練集的情況,數(shù)據(jù)污染問題的根源在于基準(zhǔn)數(shù)據(jù)的收集來(lái)源已經(jīng)包含在預(yù)訓(xùn)練語(yǔ)料庫(kù)中。雖然這些模型不是故意使用監(jiān)督數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,但它們?nèi)匀豢梢垣@得準(zhǔn)確的知識(shí)。因此,解決檢測(cè)LLM的預(yù)訓(xùn)練語(yǔ)料的挑戰(zhàn)至關(guān)重要,需要探索現(xiàn)有基準(zhǔn)和廣泛使用的預(yù)訓(xùn)練語(yǔ)料之間的重疊,以及評(píng)估對(duì)基準(zhǔn)的過(guò)擬合。這些努力對(duì)于提高LLM的忠實(shí)度和可靠性至關(guān)重要。
對(duì)齊
基于RLHF在利用一般偏好數(shù)據(jù)進(jìn)行對(duì)齊方面的應(yīng)用受到了越來(lái)越多的關(guān)注。然而,只有有限數(shù)量的開源LLM使用RLHF進(jìn)行對(duì)齊,這主要是由于高質(zhì)量的、公開可用的偏好數(shù)據(jù)集和預(yù)訓(xùn)練獎(jiǎng)勵(lì)模型的稀缺。一些研究人員試圖為開源社區(qū)做出貢獻(xiàn)。然而,在復(fù)雜的推理、編程和安全場(chǎng)景中,仍然面臨缺乏多樣化、高質(zhì)量和可擴(kuò)展的偏好數(shù)據(jù)的挑戰(zhàn)。
難以持續(xù)提高基本能力
回顧本文概述的基本能力的突破,揭示了一些具有挑戰(zhàn)性的場(chǎng)景:
在預(yù)訓(xùn)練期間,在探索改進(jìn)的數(shù)據(jù)混合方面投入了大量努力,以增強(qiáng)構(gòu)建更有效的基礎(chǔ)模型的平衡性和魯棒性。然而,相關(guān)的勘探成本往往使這種方法不切實(shí)際。
超越GPT-3.5-turbo或GPT-4的模型主要是基于從閉源模型中提取的知識(shí)和額外的專家注釋。雖然效率很高,但在擴(kuò)展到教師模型時(shí),對(duì)知識(shí)蒸餾的嚴(yán)重依賴可能會(huì)掩蓋所提出方法的有效性的潛在問題。LLM被期望充當(dāng)代理并提供合理的解釋以支持決策,而注釋代理風(fēng)格的數(shù)據(jù)以使LLM適用于現(xiàn)實(shí)世界的場(chǎng)景也是昂貴和耗時(shí)的。本質(zhì)上,僅通過(guò)知識(shí)蒸餾或?qū)<易⑨尩膬?yōu)化無(wú)法實(shí)現(xiàn)持續(xù)改進(jìn),可能會(huì)接近一個(gè)上限。未來(lái)的研究方向可能涉及探索新的方法,如無(wú)監(jiān)督或自監(jiān)督學(xué)習(xí)范式,以實(shí)現(xiàn)基本LLM能力的持續(xù)進(jìn)步,同時(shí)減輕相關(guān)的挑戰(zhàn)和成本。
總結(jié)
主要貢獻(xiàn):
整合了對(duì)開源LLM的各種評(píng)估基準(zhǔn),提供開源LLM與ChatGPT的公正和全面的看法。
系統(tǒng)地回顧了在各種任務(wù)中性能與ChatGPT相當(dāng)或超過(guò)ChatGPT的開源LLM并進(jìn)行分析。我們還維護(hù)了一個(gè)實(shí)時(shí)網(wǎng)頁(yè)來(lái)跟蹤最新的更新:https://github.com/ntunlp/OpenSource-LLMs-better-than-OpenAI/tree/main
介紹了對(duì)開源LLM發(fā)展趨勢(shì)的見解,訓(xùn)練開源LLM的最佳方法和開源LLM的潛在問題。
審核編輯:黃飛
-
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237664 -
OpenAI
+關(guān)注
關(guān)注
9文章
1045瀏覽量
6411 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1549瀏覽量
7507 -
LLM
+關(guān)注
關(guān)注
0文章
276瀏覽量
306
原文標(biāo)題:ChatGPT一周歲啦!開源LLMs正在緊緊追趕嗎?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
對(duì)比解碼在LLM上的應(yīng)用
使用開源的麥克風(fēng)陣列的喚醒識(shí)別能力和拾音能力,是否能夠在硬件和軟件上對(duì)當(dāng)前開源的代碼進(jìn)行分離?
邱錫鵬團(tuán)隊(duì)提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向

LLM在各種情感分析任務(wù)中的表現(xiàn)如何

Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態(tài)語(yǔ)言建模
基準(zhǔn)數(shù)據(jù)集(CORR2CAUSE)如何測(cè)試大語(yǔ)言模型(LLM)的純因果推理能力
適用于各種NLP任務(wù)的開源LLM的finetune教程~

Nvidia 通過(guò)開源庫(kù)提升 LLM 推理性能
深度解讀各種人工智能加速器和GPU上的LLM性能特征

Ambarella展示了在其CV3-AD芯片上運(yùn)行LLM的能力
100%在樹莓派上執(zhí)行的LLM項(xiàng)目






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論