 計算機視覺迎來GPT時刻!UC伯克利三巨頭祭出首個純CV大模型!
計算機視覺迎來GPT時刻!UC伯克利三巨頭祭出首個純CV大模型!
僅靠視覺(像素)模型能走多遠?UC 伯克利、約翰霍普金斯大學的新論文探討了這一問題,并展示了大型視覺模型(LVM)在多種 CV 任務上的應用潛力。
最近一段時間以來,GPT 和 LLaMA 等大型語言模型 (LLM) 已經風靡全球。
另一個關注度同樣很高的問題是,如果想要構建大型視覺模型 (LVM) ,我們需要的是什么?
LLaVA 等視覺語言模型所提供的思路很有趣,也值得探索,但根據動物界的規律,我們已經知道視覺能力和語言能力二者并不相關。比如許多實驗都表明,非人類靈長類動物的視覺世界與人類的視覺世界非常相似,盡管它們和人類的語言體系「兩模兩樣」。
在最近一篇論文中,UC 伯克利和約翰霍普金斯大學的研究者探討了另一個問題的答案 —— 我們僅靠像素本身能走多遠?

論文地址:https://arxiv.org/abs/2312.00785
項目主頁:https://yutongbai.com/lvm.html
研究者試圖在 LVM 中效仿的 LLM 的關鍵特征:1)根據數據的規模增長進行擴展,2)通過提示(上下文學習)靈活地指定任務。
他們指定了三個主要組件,即數據、架構和損失函數。
在數據上,研究者想要利用視覺數據中顯著的多樣性。首先只是未標注的原始圖像和視頻,然后利用過去幾十年產生的各種標注視覺數據源(包括語義分割、深度重建、關鍵點、多視圖 3D 對象等)。他們定義了一種通用格式 —— 「視覺句子」(visual sentence),用它來表征這些不同的注釋,而不需要任何像素以外的元知識。訓練集的總大小為 16.4 億圖像 / 幀。
在架構上,研究者使用大型 transformer 架構(30 億參數),在表示為 token 序列的視覺數據上進行訓練,并使用學得的 tokenizer 將每個圖像映射到 256 個矢量量化的 token 串。
在損失函數上,研究者從自然語言社區汲取靈感,即掩碼 token 建模已經「讓位給了」序列自回歸預測方法。一旦圖像、視頻、標注圖像都可以表示為序列,則訓練的模型可以在預測下一個 token 時最小化交叉熵損失。
通過這一極其簡單的設計,研究者展示了如下一些值得注意的行為:
隨著模型尺寸和數據大小的增加,模型會出現適當的擴展行為;
現在很多不同的視覺任務可以通過在測試時設計合適的 prompt 來解決。雖然不像定制化、專門訓練的模型那樣獲得高性能的結果, 但單一視覺模型能夠解決如此多的任務這一事實非常令人鼓舞;
大量無監督數據對不同標準視覺任務的性能有著顯著的助益;
在處理分布外數據和執行新的任務時,出現了通用視覺推理能力存在的跡象,但仍需進一步研究。
論文共同一作、約翰霍普金斯大學 CS 四年級博士生、伯克利訪問博士生 Yutong Bai 發推宣傳了她們的工作。
圖源:https://twitter.com/YutongBAI1002/status/1731512110247473608
在論文作者中,后三位都是 UC 伯克利在 CV 領域的資深學者。Trevor Darrell 教授是伯克利人工智能研究實驗室 BAIR 創始聯合主任、Jitendra Malik 教授獲得過 2019 年 IEEE 計算機先驅獎、 Alexei A. Efros 教授尤以最近鄰研究而聞名。

從左到右依次為 Trevor Darrell、Jitendra Malik、Alexei A. Efros。
方法介紹
本文采用兩階段方法:1)訓練一個大型視覺 tokenizer(對單個圖像進行操作),可以將每個圖像轉換為一系列視覺 token;2)在視覺句子上訓練自回歸 transformer 模型,每個句子都表示為一系列 token。方法如圖 2 所示:
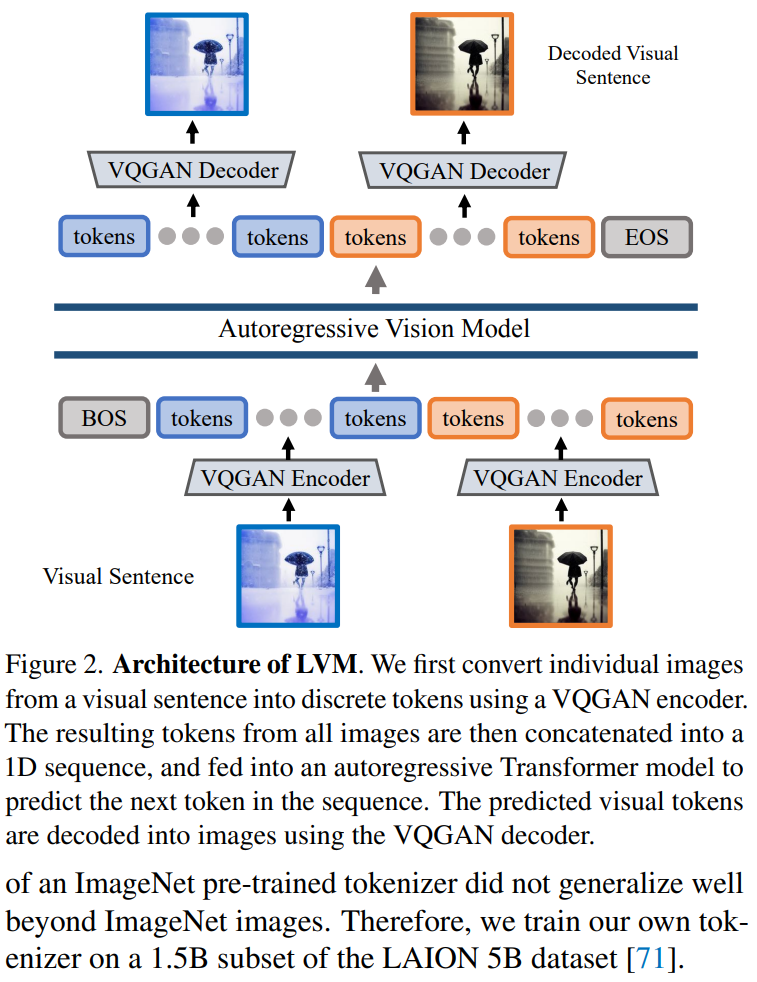
圖像 Token 化
為了將 Transformer 模型應用于圖像,典型的操作包括:將圖像劃分為 patch,并將其視為序列;或者使用預訓練的圖像 tokenizer,例如 VQVAE 或 VQGAN,將圖像特征聚集到離散 token 網格中。本文采用后一種方法,即用 VQGAN 模型生成語義 token。
LVM 框架包括編碼和解碼機制,還具有量化層,其中編碼器和解碼器是用卷積層構建的。編碼器配備了多個下采樣模塊來收縮輸入的空間維度,而解碼器配備了一系列等效的上采樣模塊以將圖像恢復到其初始大小。對于給定的圖像,VQGAN tokenizer 會生成 256 個離散 token。
實現細節。本文采用 Chang 等人提出的 VQGAN 架構,并遵循 Chang 等人使用的設置,在此設置下,下采樣因子 f=16,碼本大小 8192。這意味著對于大小為 256 × 256 的圖像,VQGAN tokenizer 會生成 16 × 16 = 256 個 token,其中每個 token 可以采用 8192 個不同的值。此外,本文在 LAION 5B 數據集的 1.5B 子集上訓練 tokenizer。
視覺句子序列建模
使用 VQGAN 將圖像轉換為離散 token 后,本文通過將多個圖像中的離散 token 連接成一維序列,并將視覺句子視為統一序列。重要的是,所有視覺句子都沒有進行特殊處理 —— 即不使用任何特殊的 token 來指示特定的任務或格式。

視覺句子允許將不同的視覺數據格式化成統一的圖像序列結構。
實現細節。在將視覺句子中的每個圖像 token 化為 256 個 token 后,本文將它們連接起來形成一個 1D token 序列。在視覺 token 序列上,本文的 Transformer 模型實際上與自回歸語言模型相同,因此他們采用 LLaMA 的 Transformer 架構。
本文使用的上下文長度為 4096 個 token,與語言模型類似,本文在每個視覺句子的開頭添加一個 [BOS](begin of sentence)token,在末尾添加一個 [EOS](end of sentence)token,并在訓練期間使用序列拼接提高效率。
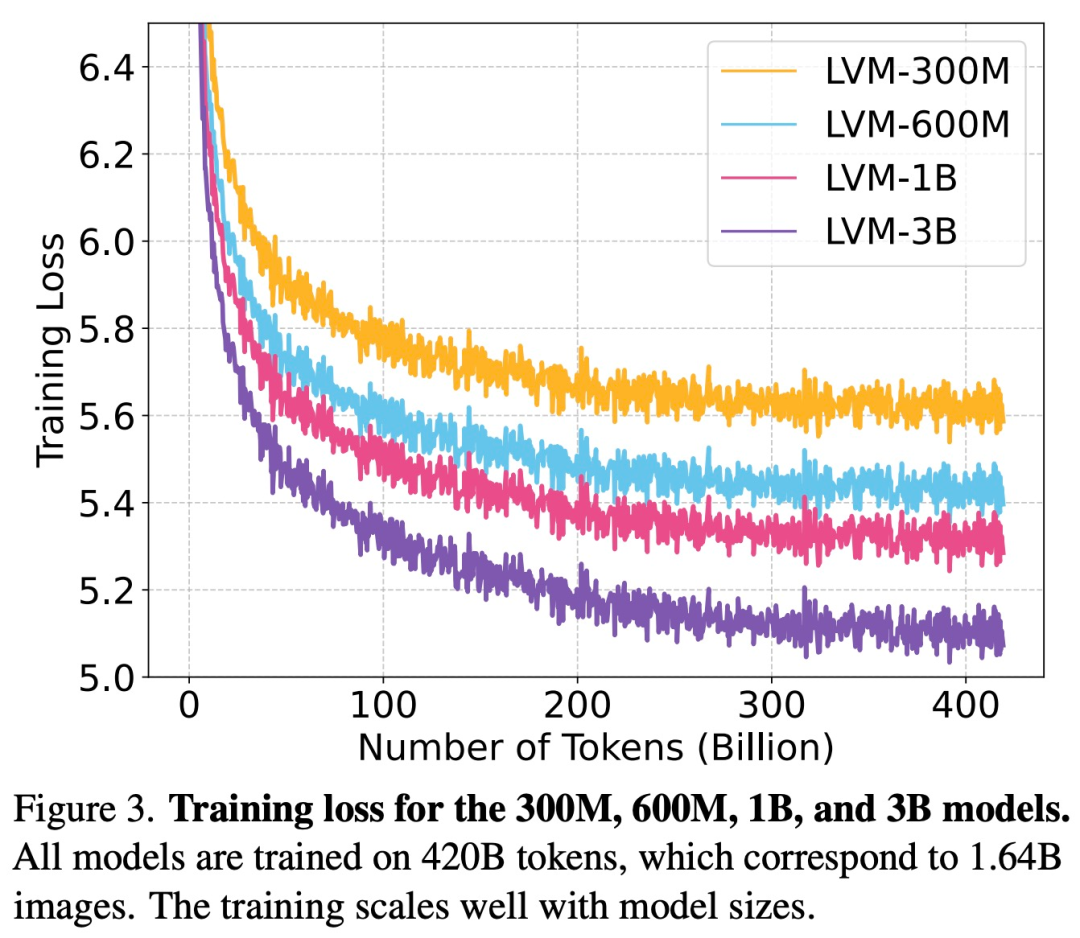
本文在整個 UVDv1 數據集(4200 億個 token)上訓練模型,總共訓練了 4 個具有不同參數數量的模型:3 億、6 億、10 億和 30 億。
實驗結果
該研究進行實驗評估了模型的擴展能力,以及理解和回答各種任務的能力。
擴展
如下圖 3 所示,該研究首先檢查了不同大小的 LVM 的訓練損失。
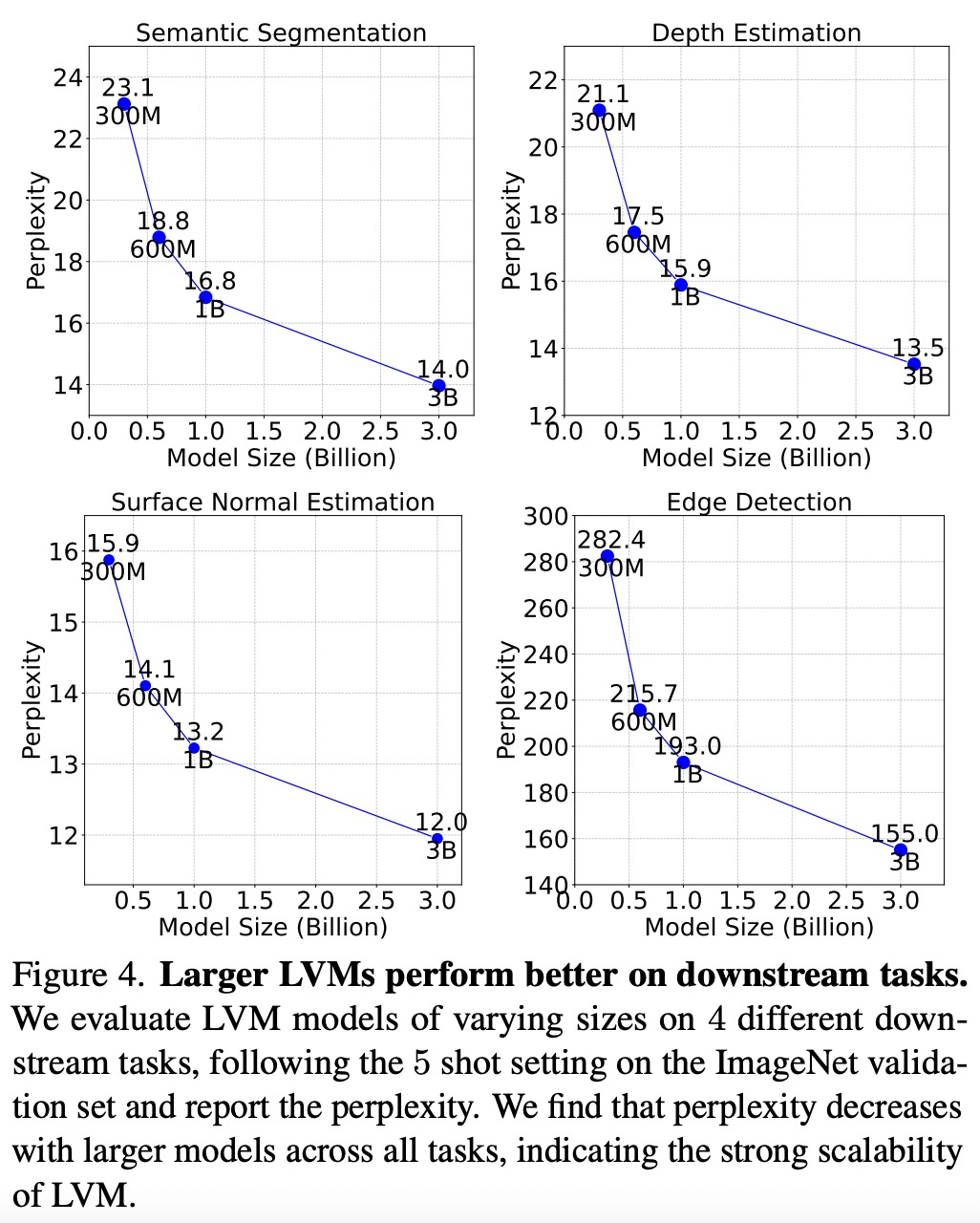
如下圖 4 所示,較大的模型在所有任務中復雜度都是較低的,這表明模型的整體性能可以遷移到一系列下游任務上。
如下圖 5 所示,每個數據組件對下游任務都有重要作用。LVM 不僅會受益于更大的數據,而且還隨著數據集的多樣性而改進。

序列 prompt
為了測試 LVM 對各種 prompt 的理解能力,該研究首先在序列推理任務上對 LVM 進行評估實驗。其中,prompt 非常簡單:向模型提供 7 張圖像的序列,要求它預測下一張圖像,實驗結果如下圖 6 所示:

該研究還將給定類別的項目列表視為一個序列,讓 LVM 預測同一類的圖像,實驗結果如下圖 15 所示:

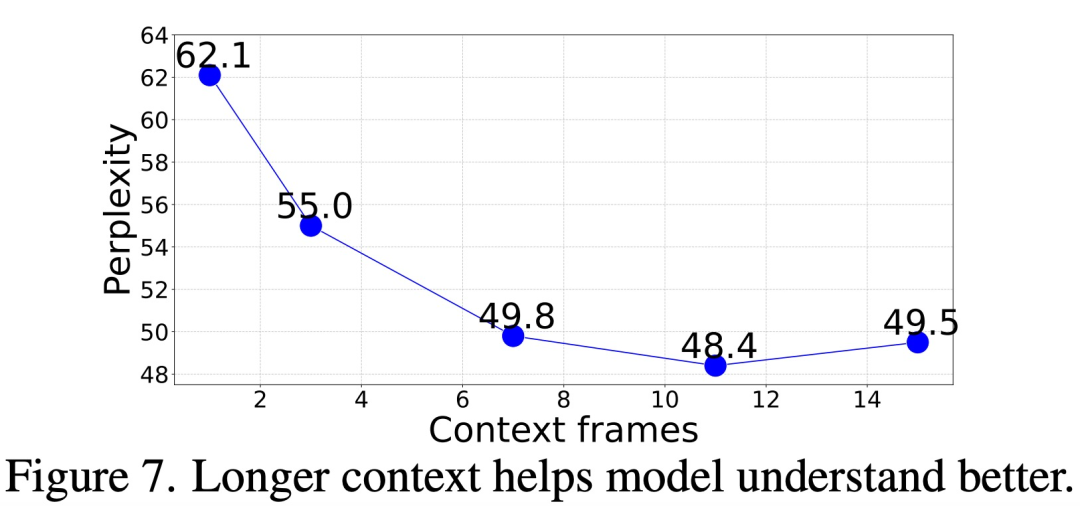
那么,需要多少上下文(context)才能準確預測后續幀?
該研究在給出不同長度(1 到 15 幀)的上下文 prompt 情況下,評估了模型的幀生成困惑度,結果如下圖 7 所示,困惑度從 1 幀到 11 幀有明顯改善,之后趨于穩定(62.1 → 48.4)。
Analogy Prompt
該研究還評估了更復雜的 prompt 結構 ——Analogy Prompt,來測試 LVM 的高級解釋能力。
下圖 8 顯示了對許多任務進行 Analogy Prompt 的定性結果:

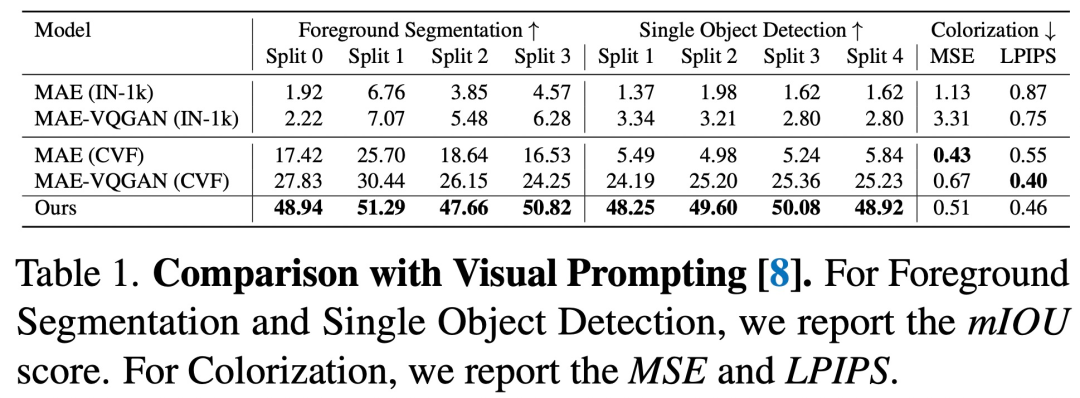
與視覺 Prompting 的比較如下所示, 序列 LVM 在幾乎所有任務上都優于以前的方法。
合成任務。圖 9 展示了使用單個 prompt 組合多個任務的結果。

其他 prompt
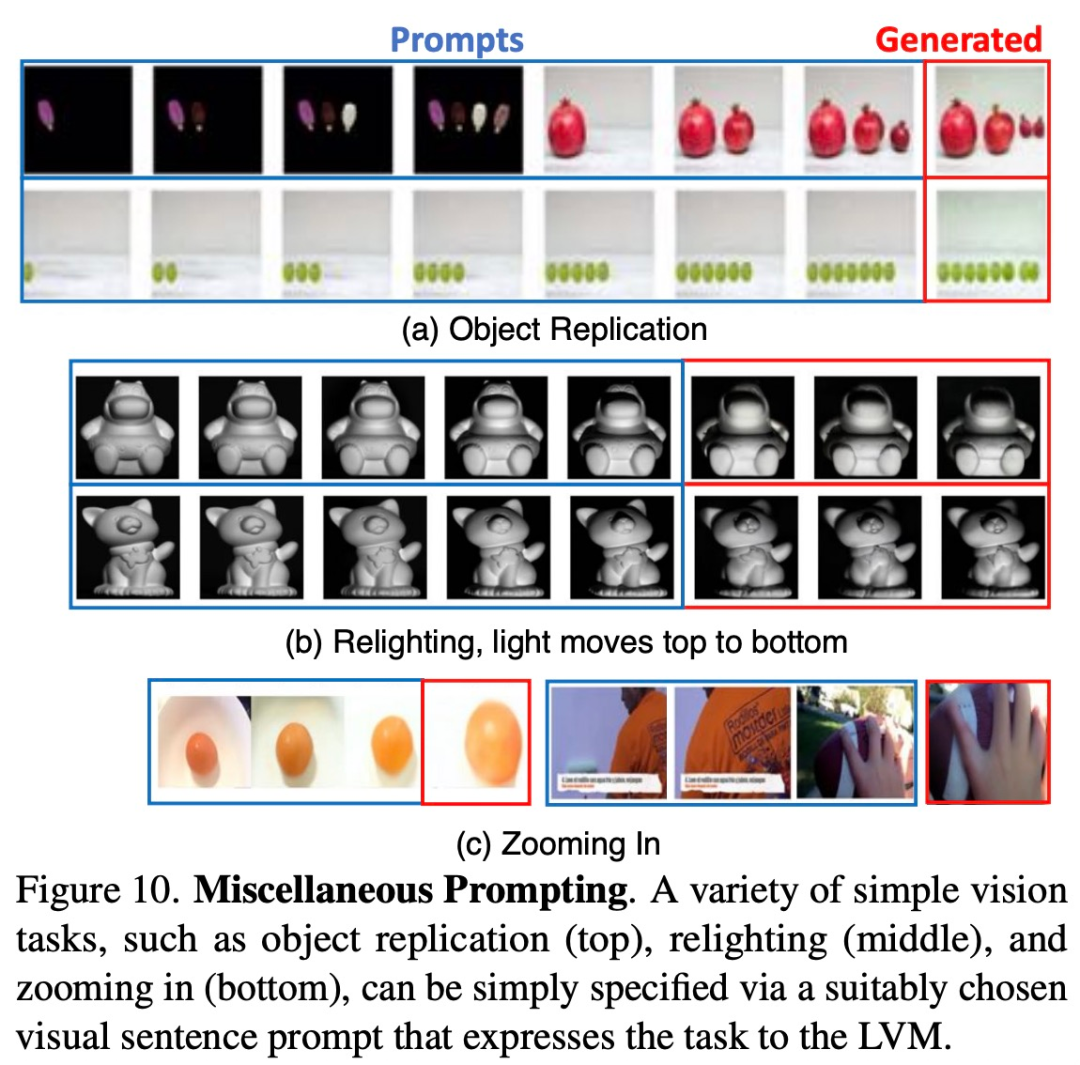
研究者試圖通過向模型提供它以往未見過的各種 prompt,來觀察模型的擴展能力到底怎樣。下圖 10 展示了一些運行良好的此類 prompt。
下圖 11 展示了一些用文字難以描述的 prompt,這些任務上 LVM 最終可能會勝過 LLM。
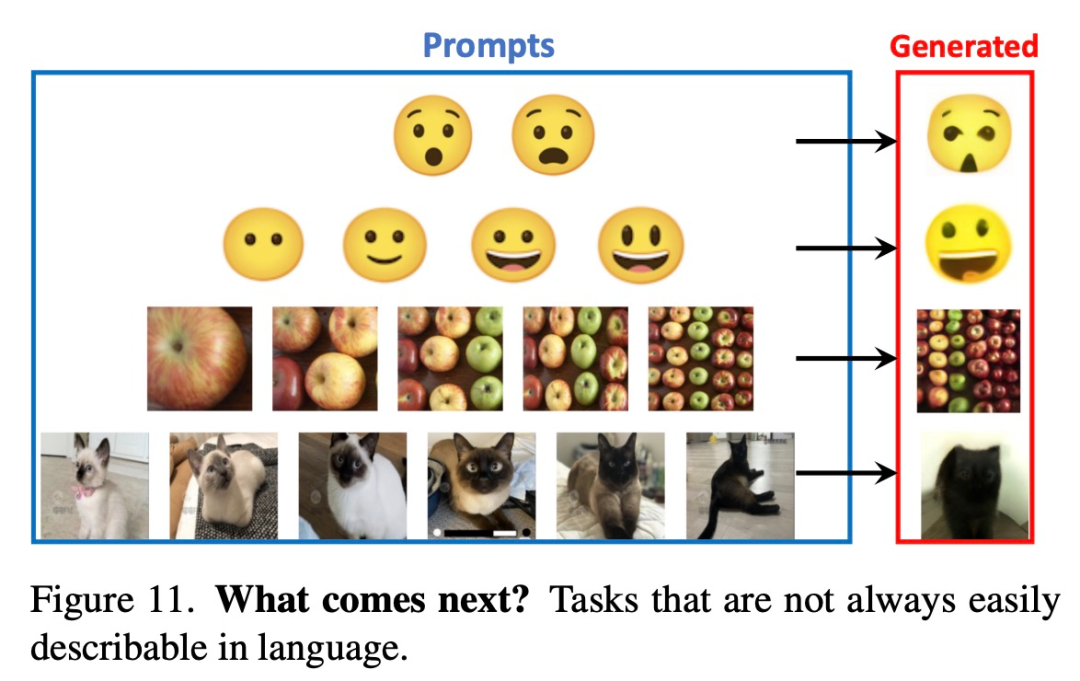
圖 13 顯示了在非語言人類 IQ 測試中發現的典型視覺推理問題的初步定性結果。

-
圖像
+關注
關注
2文章
1083瀏覽量
40420 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
語言模型
+關注
關注
0文章
508瀏覽量
10247
原文標題:計算機視覺迎來GPT時刻!UC伯克利三巨頭祭出首個純CV大模型!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
UC伯克利教授Stuart Russell:人工智能基礎概念與34個誤區

華為投入1百萬美元和伯克利合作推進 AI 技術
USNews發布了最新的大學計算機科學排名
推特公開宣布了伯克利機器人學習實驗室最新開發的機器人BLUE
UC伯克利新機器人成果:靈活自由地使用工具
加州大學伯克利分校研發可以操控的機器人
美國伯克利市考慮2027年出臺汽油車禁售令
用語言建模世界:UC伯克利多模態世界模型利用語言預測未來






 工商網監
工商網監
評論