") 聊聊日志即數(shù)據(jù)庫
聊聊日志即數(shù)據(jù)庫
《數(shù)據(jù)庫故障恢復(fù)機(jī)制的前世今生》[1]一文中介紹過,由于磁盤的的順序訪問性能遠(yuǎn)好于隨機(jī)訪問,數(shù)據(jù)庫設(shè)計(jì)中通常都會(huì)采用WAL的方式,將隨機(jī)訪問的數(shù)據(jù)庫請(qǐng)求轉(zhuǎn)換為順序的日志IO,并通過Buffer Pool盡量的合并并推遲真正的數(shù)據(jù)修改落盤。如果發(fā)生故障,可以通過日志的重放恢復(fù)故障發(fā)生前未刷盤的修改信息。也就是說Log中包含數(shù)據(jù)庫恢復(fù)所需要的全部信息。
現(xiàn)代數(shù)據(jù)庫為了追求更高的事務(wù)并發(fā)度,會(huì)顯式地區(qū)分用戶可見的邏輯內(nèi)容和維護(hù)內(nèi)部的物理結(jié)構(gòu),在并發(fā)控制上支持了Lock和Latch的分層,同時(shí)也在故障恢復(fù)上區(qū)分了User Transaction和System Transaction。在這種設(shè)計(jì)下, 保證數(shù)據(jù)庫D(Durable)的Redo Log需要能在Crash Recovery的過程中,在完全不感知用戶事務(wù)的情況下,恢復(fù)未提交的System Transaction。因此,Redo Log的設(shè)計(jì)上天然就是Page Oriented的,也就是說每條Redo Log都被限制在單個(gè)Page中,其重放過程不需要感知用戶事務(wù)的存在,也不需要關(guān)心其他的Page。在《B+樹數(shù)據(jù)庫故障恢復(fù)概述》[2]中詳細(xì)的討論過這個(gè)過程,也提到這樣做的好處使得在Crash Recovery的過程中Page的恢復(fù)過程可以實(shí)現(xiàn)充分的并發(fā)。到這里我們就可以引出本文想要討論的主要內(nèi)容:
已知:
特性1(完備):Log中包含數(shù)據(jù)庫恢復(fù)所需要的全部信息;
特性2(Page Oriented):Page通過Log的恢復(fù)過程只需要關(guān)心當(dāng)前的Page本身;
那么,通過這兩個(gè)特性,數(shù)據(jù)庫設(shè)計(jì)能實(shí)現(xiàn)哪些實(shí)用和有趣的功能呢?
Single Page Recovery
最直接的就是讓Single Page Recovery成為可能,當(dāng)硬件故障導(dǎo)致某些Page的數(shù)據(jù)損壞或錯(cuò)誤時(shí),通常數(shù)據(jù)庫都是將這類Page異常直接當(dāng)做介質(zhì)損壞來處理的,比如需要從最近的備份做還原。這樣會(huì)由于多余的,不必要的數(shù)據(jù)還原導(dǎo)致較長的恢復(fù)時(shí)間和空間開銷。而Single Page Recovery可以更精準(zhǔn)、更快的只恢復(fù)損壞的Page。如果再搭配上一些Page Corruption檢測機(jī)制,比如磁盤、操作系統(tǒng)、DB對(duì)數(shù)據(jù)的Checksum檢查,甚至是一些自檢的數(shù)據(jù)結(jié)構(gòu),就可以實(shí)現(xiàn)更可靠的數(shù)據(jù)庫服務(wù)。
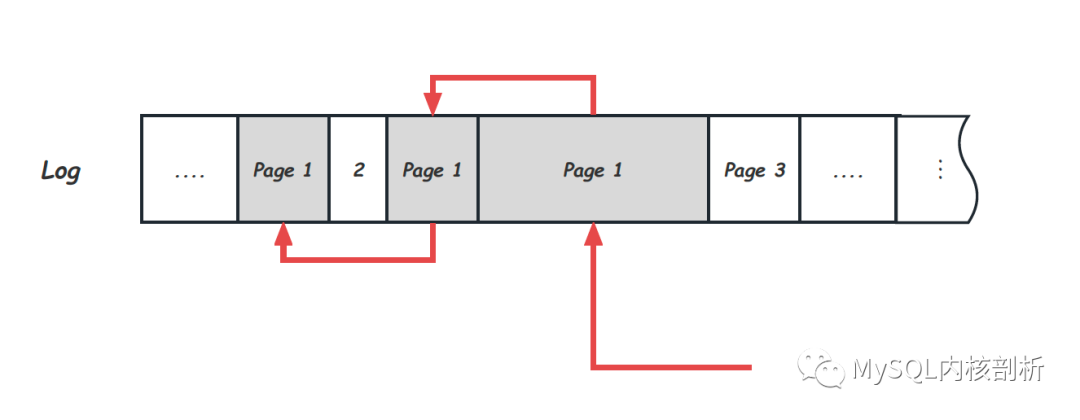
為Log建立按Page索引(Log Index)
發(fā)現(xiàn)損壞的Page后,下一步就是對(duì)該P(yáng)age的恢復(fù),即Single Page Recovery過程本身。這個(gè)時(shí)候最主要的是需要有根據(jù)Page號(hào)查找所有需要的Log的能力。而正常的Log寫入是Append Only的,所有Page的Log會(huì)穿插在一起,因此這里需要Log有按照Page的索引存在。比如,可以通過在Log中添加信息維護(hù)如下Page的Log鏈,當(dāng)需要恢復(fù)Page時(shí),可以沿著這個(gè)Log鏈一路找到所有需要的Log Record:
More Than Single Page Recovery
Single Page Recovery其實(shí)是讓DB擁有了:在任何時(shí)候,通過較老的Page版本及之后的Log,在線獲得Page的最新版本的能力。 那么,利用和這個(gè)能力,DB能做的就不只是單個(gè)Page的故障恢復(fù)。甚至轉(zhuǎn)變一下思路,如果通過主動(dòng)的引入Page故障,并在需要的時(shí)候再做這個(gè)Page的Recovery是否能獲得更多的東西呢?本文將從這個(gè)角度出發(fā)介紹幾個(gè)DB可能的工作,其中很多其實(shí)已經(jīng)在慢慢變成包括PolarDB在內(nèi)的現(xiàn)代數(shù)據(jù)庫的標(biāo)配。
寫省略(Write Elision):
省略部分Page刷盤操作,主動(dòng)讓Page成為“Corrupt Page”, 并在需要的使用再通過Single Page Recovery來拿到需要的Page。
快速重啟(Instant Recovery):
當(dāng)發(fā)生System Failure后,DB重啟過程中,跳過需要的Log應(yīng)用,主動(dòng)保持這些Page的“Corrupt”狀態(tài),在后續(xù)需要訪問的時(shí)候再通過Single Page Recovery恢復(fù)。
快速還原(Instant Restore):
當(dāng)發(fā)生Media Failure后,DB還原的過程中,跳過Page的修復(fù)過程,同樣在后續(xù)需要時(shí)再恢復(fù)。
寫省略(Write Elision)
一次很小的Page修改通常會(huì)對(duì)應(yīng)一條很短的Log Record,但卻會(huì)導(dǎo)致整個(gè)Page在Buffer Pool中變成臟頁,在《庖丁解Innodb之Buffer Pool》[3]中介紹過,Buffer Pool本身大小是受限的,當(dāng)沒有空閑的Page空間時(shí),為了承載新的請(qǐng)求,就需要通過例如LRU算法來選擇Page換出,如果換出的Page本身是臟頁,就需要先將這個(gè)臟頁刷盤,也就是觸發(fā)一次Page大小的寫IO。當(dāng)總數(shù)據(jù)量遠(yuǎn)大于Buffer Pool的場景中,這種現(xiàn)象頻繁的發(fā)生:每個(gè)Page被換入Buffer Pool后做了很少的修改,又很快因?yàn)楸粨Q出而刷盤。很小的修改導(dǎo)致很大的寫IO,而IO的帶寬資源又是很寶貴的,這種場景中很容易就變成了整個(gè)DB的性能瓶頸,這也就是所謂的IO-Bound場景。
Single Page Recovery給了這種場景一種新的選擇,當(dāng)臟頁被換出時(shí),直接跳過刷臟過程,從而完全避免了Page大小的IO。當(dāng)下次該P(yáng)age再次被換入時(shí),這個(gè)Page會(huì)被看做是一個(gè)“Corrupt Page”,通過Log的按Page索引找到需要的Log Record,并完成應(yīng)用。這種實(shí)現(xiàn)由于避免了大量的Page IO,可以顯著的提升這種IO-Bound場景下的DB性能。這種實(shí)現(xiàn)中,可以在寫入過程中,在內(nèi)存中維護(hù)Log的按Page索引。
快速重啟(Instant Recovery)
數(shù)據(jù)庫發(fā)生故障或運(yùn)維操作需要重啟時(shí),中斷服務(wù)的時(shí)間直接影響數(shù)據(jù)庫的可用性,因此這個(gè)階段是希望盡可能短暫的。《數(shù)據(jù)庫故障恢復(fù)機(jī)制的前世今生》[1]中介紹過,ARIES實(shí)現(xiàn)的數(shù)據(jù)庫在恢復(fù)過程中會(huì)經(jīng)歷Log Analysis、Redo Phase以及Undo Phase三個(gè)階段,其中回滾未提交事務(wù)的Undo階段可以在數(shù)據(jù)庫提供服務(wù)之后,在后臺(tái)進(jìn)行。
因此主要影響不可服務(wù)時(shí)間的,就是Log Analysis階段及Redo Phase階段,其中應(yīng)用Log恢復(fù)Page的Redo Phase的時(shí)間占比又顯著高于僅僅掃描Redo的Log Analysis階段。實(shí)踐中,Redo Phase的時(shí)間可能因?yàn)?a target="_blank">Active Redo的量及Buffer Pool的大小限制變得不可接受。Redo Phase主要的任務(wù)是要將所有的未刷盤的Page通過重放Redo恢復(fù)到最新的狀態(tài),如果我們暫時(shí)接受這種未恢復(fù)Page的“Corrupt”狀態(tài),并利用Single Page Recovery的能力,在需要的時(shí)候再在后臺(tái)完成,那么,我們就可以將數(shù)據(jù)庫提供服務(wù)的時(shí)間提前到Redo Phase開始之前,如下圖所示:
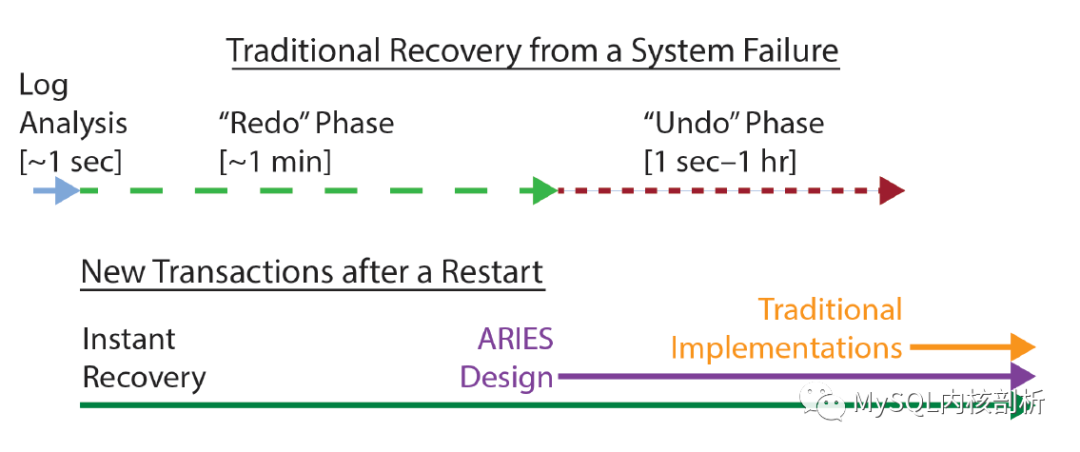
重啟階段
為了實(shí)現(xiàn)快速重啟,在ARIES的基礎(chǔ)上,Log Analysis階段需要額外維護(hù)一些必要的信息,主要包括Register Pages及Log Index。其中Register Pages中記錄所有Checkpoint之后的Active Redo所涉及到的Page,這些是所有需要恢復(fù)的Page。DB提供服務(wù)后,在后臺(tái)異步完成Redo Phase之前,如果有用戶請(qǐng)求訪問到Register Pages中的Page才需要觸發(fā)Single Page Recovery的恢復(fù)流程,并在Page恢復(fù)完成后從Register Pages中刪除。另一個(gè)需要的信息就是Single Page Recovery過程中需要的Log index,參考ARIES中為Undo Phase維護(hù)的Per-Transaction Log鏈,這里也可以維護(hù)出Per-Page Log鏈,如下圖所示:

需要做Recovery的Page可以沿著這個(gè)鏈表,一路找到當(dāng)前Page LSN的位置或者找到Page Initial位置為止,并順序應(yīng)用所有需要的Page。
后臺(tái)Redo Phase
DB完成Log Analysis并開始提供服務(wù)之后,后臺(tái)的Redo Phase會(huì)比之前同步的Redo Phase有更多的選擇。比如,是立刻恢復(fù)所有的Resister Pages,還是等待這些Page真正被用戶請(qǐng)求使用時(shí)再恢復(fù),亦或是二者結(jié)合。又比如,是按照Log中Page的排列順序恢復(fù),還是按照Page的某種優(yōu)先級(jí)恢復(fù)(大/小事務(wù)優(yōu)先、大/小表優(yōu)先,或者某種用戶定義的優(yōu)先級(jí)),亦或是多種策略相結(jié)合。同時(shí)后臺(tái)Redo Phase過程由于Page恢復(fù)之間相互獨(dú)立,也天然更容易實(shí)現(xiàn)并發(fā)。因此,更高的靈活度和可能更高的并發(fā)度,也是Instant Recovery除了快速恢復(fù)服務(wù)之外新增優(yōu)勢(shì)。
不過需要注意的是,由于在恢復(fù)同時(shí)接受用戶新的請(qǐng)求,完整的恢復(fù)過程可能會(huì)拉長,而在這個(gè)過程中,用戶請(qǐng)求的性能也是會(huì)有下降的,如下圖所示是一個(gè)傳統(tǒng)ARIES Restart和Instant Restart的DB可用性及性能效果:
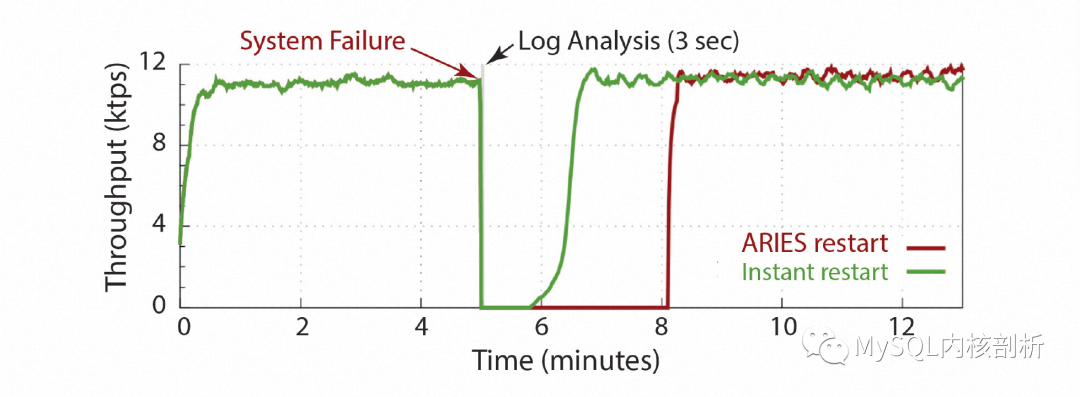
快速還原(Instant Restore)
備份還原通常是數(shù)據(jù)庫應(yīng)對(duì)磁盤故障的保底手段。為了實(shí)現(xiàn)這一點(diǎn),正常運(yùn)行過程中,數(shù)據(jù)庫就需要周期性的對(duì)數(shù)據(jù)和日志進(jìn)行備份,權(quán)衡恢復(fù)時(shí)間和對(duì)正常運(yùn)行的影響,其中數(shù)據(jù)備份又包括全量備份和增量備份。當(dāng)遇到磁盤故障需要做備份還原時(shí),會(huì)先從全量備份和增量備份在新的磁盤上還原一份數(shù)據(jù),之后應(yīng)用備份時(shí)間點(diǎn)之后的日志,全部完成后切換這個(gè)新的數(shù)據(jù)庫實(shí)例提供服務(wù)。整個(gè)過程如下圖所示:
可以看出,備份還原有非常長的周期,包括拷貝全量備份即增量備份的Full Restore及Incremental Restore階段,以及跟重啟類似的Log Analysis、Redo Phase和Undo Pass階段,其恢復(fù)時(shí)間跟數(shù)據(jù)及日志總量相關(guān),并受網(wǎng)絡(luò)帶寬及磁盤IO的限制。因此,盡可能讓DB提前提供服務(wù)是非常必要的,類似于上面講的快速重啟,ARIES通過事務(wù)Lock的方式,讓數(shù)據(jù)庫可以在Undo Phase階段完成前就提供服務(wù)。同樣的,我們可以通過暫時(shí)接受“Corrupt Page”,將真正的Page Recovery推遲到需要的時(shí)候,從而將DB整體提供服務(wù)的時(shí)間提前,如下圖所示:
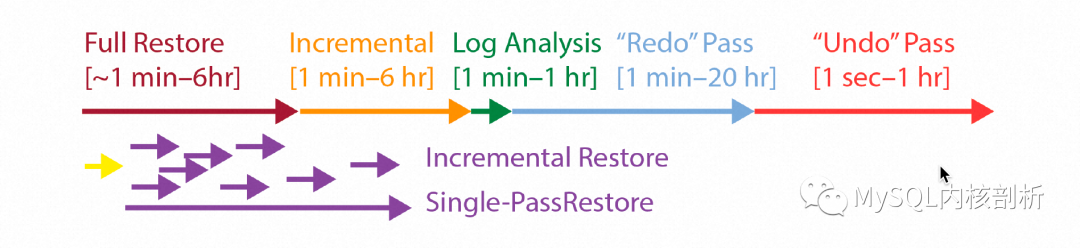
我們甚至可以將這個(gè)時(shí)間點(diǎn)提前到備份還原的一開始。這個(gè)時(shí)候,新的磁盤上甚至還沒有任何Page數(shù)據(jù),當(dāng)一個(gè)Page被訪問的時(shí)候,會(huì)先從最近的全量及增量備份中去找到該P(yáng)age的歷史版本,再從Log備份中找到這個(gè)Page之后的所有Log完成應(yīng)用。因此,能夠快速找到需要Page對(duì)應(yīng)的備份數(shù)據(jù)位置及需要的增量Logs非常重要,也就是在正常的備份過程中,為備份和Log維護(hù)按Page的索引。
為數(shù)據(jù)備份及Log備份建立按Page的索引
正常數(shù)據(jù)庫寫入過程中會(huì)以Append Only的方式寫WAL Log,為可能發(fā)生的Crash做Recovery準(zhǔn)備,這里稱為Recovery Log。隨著Checkpoint的推進(jìn),陳舊的Recovery Log不再被Recovery需要,可以被清理。但為了可能的備份還原,這部分Log還需要被保留,可能是在成本更低的存儲(chǔ)介質(zhì)上,這部分Log這里稱為Archive Log。在轉(zhuǎn)存Archive Log的過程中,便可以為Archive Log建立按Page索引。最理想的情況是需要還原的時(shí)候,有全局的Archive Log索引,但因?yàn)長og本身流式產(chǎn)生的特性,這樣顯然是不可能的。因此,分區(qū)排序的Archive Log就成為非常好的選擇,如下圖所示:
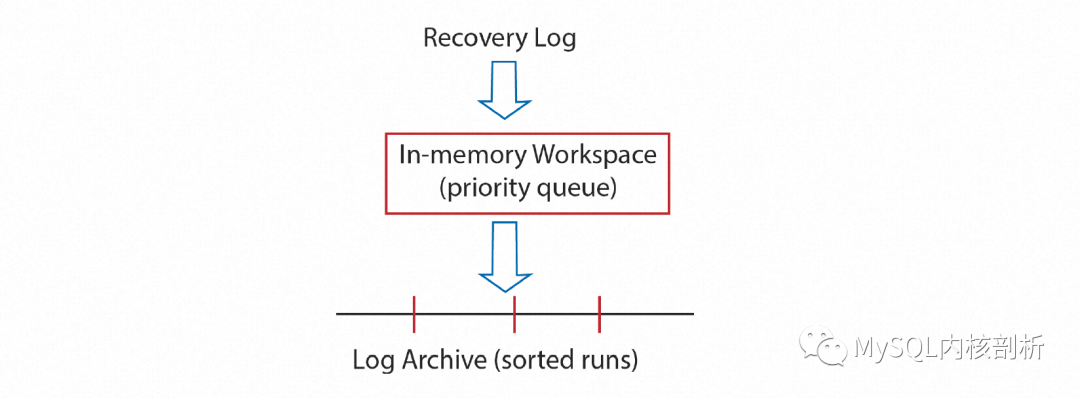
后臺(tái)的Archive任務(wù)會(huì)在內(nèi)存中對(duì)順序生成的Recovery Log中的一段按Page排序,這部分內(nèi)存超過某個(gè)大小時(shí),已經(jīng)排序的部分會(huì)落盤生成一個(gè)按Page號(hào)有序的Archive Log分片。重復(fù)這個(gè)過程就有了許許多多的排序分區(qū)。根據(jù)分片號(hào)及Page號(hào)就可以訪問到需要Page的所有Archive Log。除了Log以外,為了支持Instant Restore的按需Page恢復(fù),全量備份及增量備份也需要按照Page號(hào)建立索引。
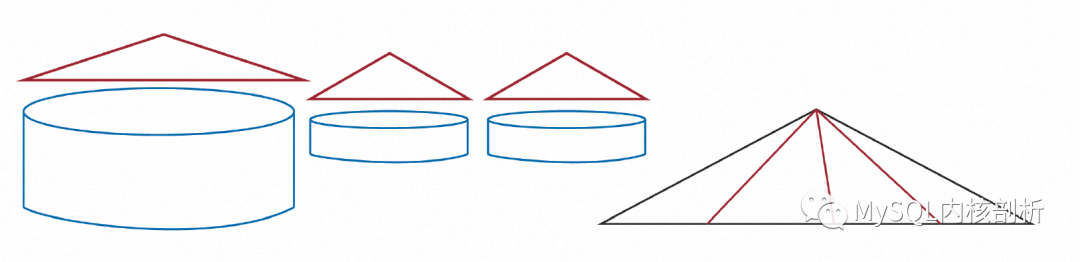
最終,如上圖所示,無論是數(shù)據(jù)備份還是日志部分都存在一個(gè)索引方式可以方便的按照Page號(hào)查找。當(dāng)一個(gè)Page需要真正做Restore時(shí),就可以利用這些索引快速找到其對(duì)應(yīng)的備份Page版本及后續(xù)Log,完成真正的Page重建。
后臺(tái)Restore過程
類似于快速重啟,實(shí)踐上通常也會(huì)搭配一個(gè)后臺(tái)運(yùn)行的Restore任務(wù),即使沒有用戶請(qǐng)求訪問,所有的Page也會(huì)在一個(gè)有限的時(shí)間窗口全部完成Restore。下圖展示的就是從全量備份,增量備份和日志備份中不斷還原Page到目標(biāo)新磁盤的過程。
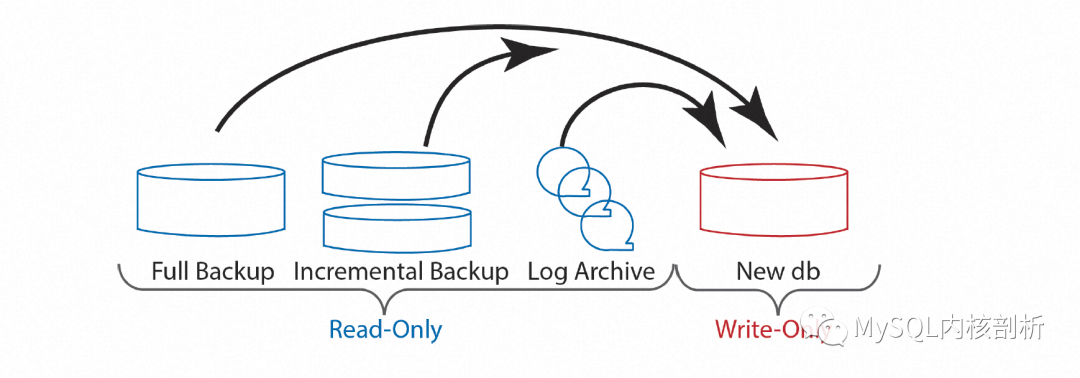
有了上面所說的數(shù)據(jù)備份及日志備份的按Page索引,后臺(tái)的這個(gè)Restore過程也可以拋棄之前按Log順序進(jìn)行的限制,有了更多的選擇和靈活性。舉個(gè)很實(shí)用的例子,Backup相對(duì)于最新的DB位置,受Backup周期及寫入壓力的影響,中間的日志量可能非常多,而這些日志通常又會(huì)反復(fù)修改同一個(gè)Page,按照Log順序的還原策略,會(huì)導(dǎo)致同一個(gè)Page可能會(huì)不斷的讀寫,造成很大的IO浪費(fèi),也因此受到IO帶寬限制。而采用Single Page Recovery方式的后臺(tái)Restore過程,天然的可以按照Page的順序進(jìn)行還原,每個(gè)Page的一次讀寫都可以完成全部的日志應(yīng)用,這樣就可能很大程度的提升Page的IO效率和還原的速度。
應(yīng)用 - Aurora
Aurora作為共享存儲(chǔ)數(shù)據(jù)庫的佼佼者,其設(shè)計(jì)和實(shí)現(xiàn)中大量的利用了日志即數(shù)據(jù)庫的思路。Aurora認(rèn)為計(jì)算節(jié)點(diǎn)與存儲(chǔ)節(jié)點(diǎn)分離后,整個(gè)DB系統(tǒng)的IO瓶頸會(huì)轉(zhuǎn)移到計(jì)算節(jié)點(diǎn)與存儲(chǔ)節(jié)點(diǎn)及存儲(chǔ)節(jié)點(diǎn)副本間的網(wǎng)絡(luò)上,為此Aurora的設(shè)計(jì)中,計(jì)算節(jié)點(diǎn)和存儲(chǔ)節(jié)點(diǎn),及存儲(chǔ)節(jié)點(diǎn)之間只傳遞日志,如下圖所示:
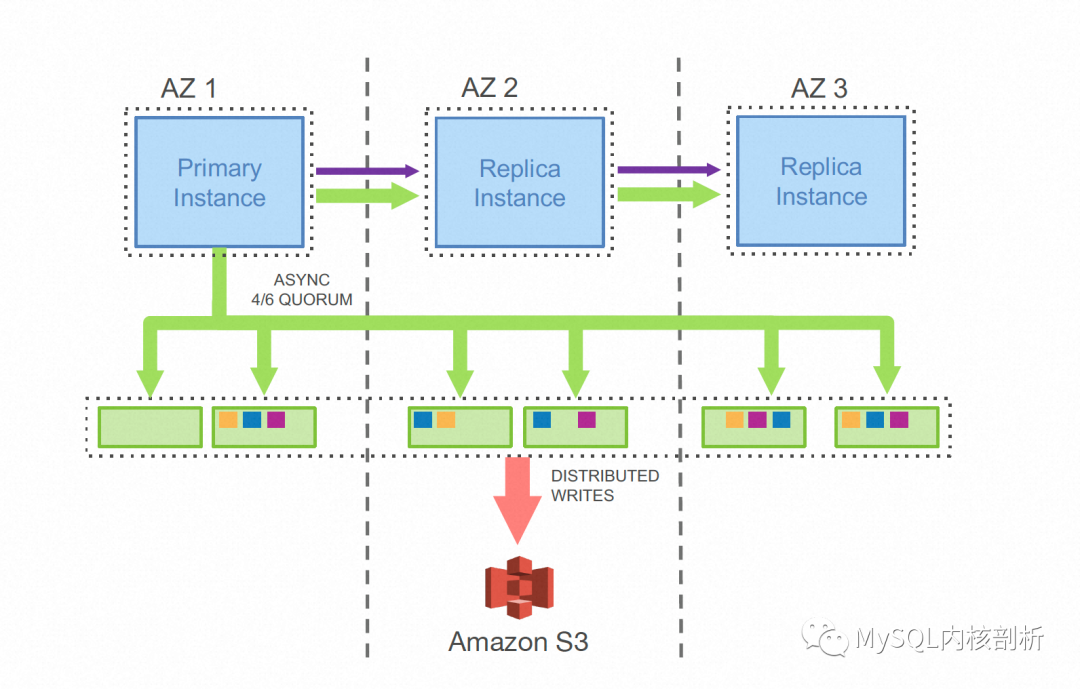
Aurora也把這種設(shè)計(jì)設(shè)計(jì)稱為日志即數(shù)據(jù)(The Log is The Database)[4] 。這種實(shí)現(xiàn)會(huì)在日志量遠(yuǎn)小于Page修改量的場景下非常的有效,可以看出網(wǎng)絡(luò)上傳遞的只有Log而沒有任何Page數(shù)據(jù)。每個(gè)存儲(chǔ)節(jié)點(diǎn)在收到流式的Log之后,會(huì)獨(dú)立完成一遍Page的修改過程。下圖所示的是其存儲(chǔ)節(jié)點(diǎn)的工作流程:
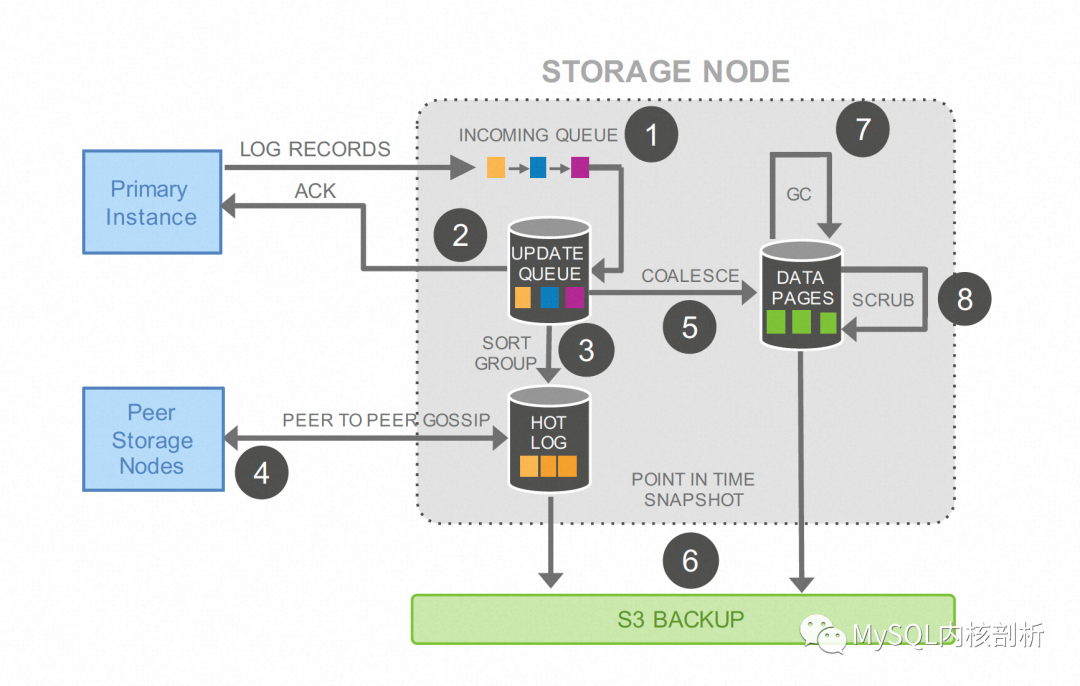
存儲(chǔ)節(jié)點(diǎn)不斷的從計(jì)算節(jié)點(diǎn)接受Log寫入并持久化90(1),完成日志在Update Queue中的持久化,并返回計(jì)算節(jié)點(diǎn)確認(rèn)(2),同其他存儲(chǔ)節(jié)點(diǎn)通信補(bǔ)全Log(3),當(dāng)某些Page收到的連續(xù)日志量超過某個(gè)閾值,或者整體的Update Queue中的日志量達(dá)到某個(gè)閾值后,這些Page會(huì)在后臺(tái)周期性的應(yīng)用Page的修改并寫入Data Pages,這個(gè)過程稱為日志到Page的合并(COALESCE)(5)。最后歷史的日志和數(shù)據(jù)會(huì)備份到S3為后續(xù)可能的按時(shí)間點(diǎn)還原做準(zhǔn)備。
寫省略(Write Elision)
可以看出,當(dāng)某個(gè)Page的收到的日志量比較少的情況下,Aurora的存儲(chǔ)節(jié)點(diǎn)并不基于將其真正的修改到Data Pages中,這個(gè)時(shí)候,如果計(jì)算節(jié)點(diǎn)需要讀這個(gè)Page,存儲(chǔ)節(jié)點(diǎn)會(huì)應(yīng)用Update Queue中的Log到需要的Page上并返回用戶。這個(gè)熟悉的過程其實(shí)就是本文提到的寫省略(WRITE ELISION)。理想情況下,一個(gè)Page的多次修改對(duì)應(yīng)的Log會(huì)一直積累在Update Queue中而沒有真正產(chǎn)生Page,直到足夠的Log量觸發(fā)Page 的COALESCE。
快速重啟(Instant Recovery)
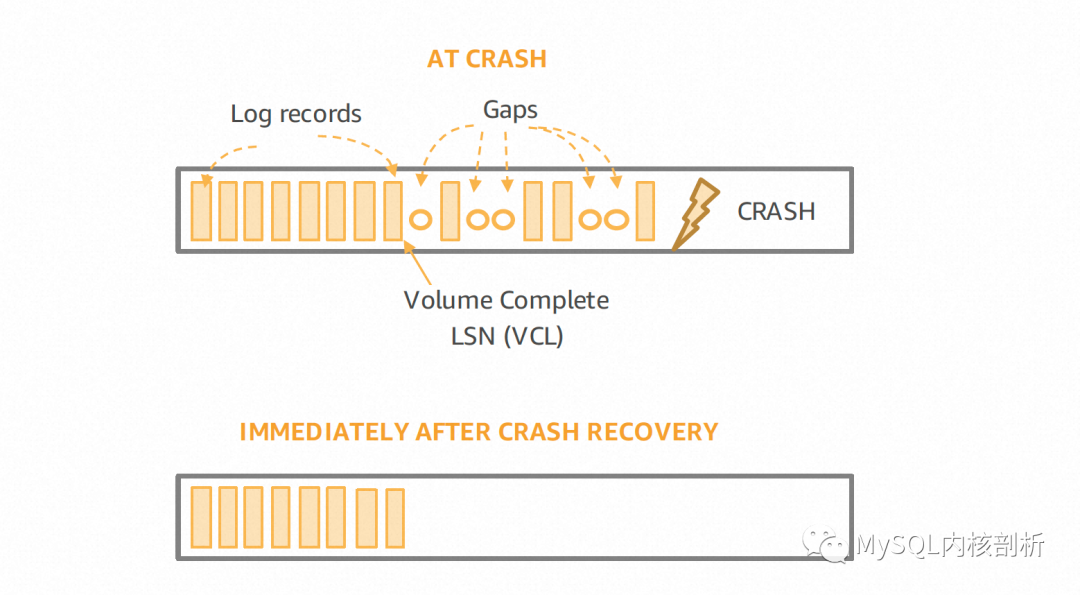
由于Aurora的計(jì)算節(jié)點(diǎn)不維護(hù)Log也不負(fù)責(zé)Page的更新,其重啟過程可以非常迅速,不需要傳統(tǒng)數(shù)據(jù)庫的Log Analysis,Redo Phase及Undo Phase,而這部分需求其實(shí)是下放到了存儲(chǔ)節(jié)點(diǎn)上的。Aurora存儲(chǔ)節(jié)點(diǎn)的重啟恢復(fù)過程,第一步要確定VDL or the Volume Durable LSN[5],這個(gè)位置可以認(rèn)為對(duì)應(yīng)單機(jī)數(shù)據(jù)庫的有效Log結(jié)尾,之后這個(gè)存儲(chǔ)節(jié)點(diǎn)就可以恢復(fù)向計(jì)算節(jié)點(diǎn)提供服務(wù)。這其實(shí)就是天然的Instant Restart實(shí)現(xiàn),真正的Page Apply被推遲到用戶請(qǐng)求,或收到更多的Log出發(fā)Page的Coalesce。
快速還原(Instant Restore)
云數(shù)據(jù)庫通常都會(huì)會(huì)提供諸如按時(shí)間點(diǎn)還原的功能,來還原一個(gè)新的指定歷史時(shí)間點(diǎn)的實(shí)例。這個(gè)過程其實(shí)就是典型的備份還原場景,需要結(jié)合歷史的Page版本和后續(xù)增量Log完成。除此之外,Aurora還提供了Backtrack的能力,可以讓當(dāng)前實(shí)例分鐘級(jí)的快速還原到Backtrack Window內(nèi)的任意時(shí)間點(diǎn),并且這個(gè)動(dòng)作還可以向前向后反復(fù)重復(fù)執(zhí)行。這部分的具體實(shí)現(xiàn)細(xì)節(jié)沒有太多的公開資料,不過測試中Aurora在這些功能良好的表現(xiàn)以及合理的實(shí)現(xiàn)推測,也讓我們相信其受益于其日志即數(shù)據(jù)庫的設(shè)計(jì)。
總結(jié)
本文從AIRES及現(xiàn)代數(shù)據(jù)庫的邏輯、物理分層實(shí)現(xiàn),推導(dǎo)出數(shù)據(jù)庫的Redo Log會(huì)具有,完備及Page Oriented兩個(gè)特性,有了這兩個(gè)特性,就可以很好的支持精準(zhǔn)的Single Page Recovery。而更廣泛一點(diǎn)的是讓數(shù)據(jù)庫擁有了:按需在線恢復(fù)單個(gè)Page的能力。而利用這個(gè)能力并主動(dòng)引入”Page Corrupt”就可以實(shí)現(xiàn)更廣義上的Single Page Recovery。本文從 寫省略(Write Elision)、快速重啟(Instant Recovery)以及快速還原(Instant Restore)三個(gè)方向介紹了利用Single Page Recovery可以讓數(shù)據(jù)庫獲得的如性能提升、可用性提高、靈活性提高等優(yōu)勢(shì)。最后,通過介紹Amazon的共享存儲(chǔ)數(shù)據(jù)庫Aurora是如何在設(shè)計(jì)中應(yīng)用這些優(yōu)化的。最后的最后,同樣作為共享存儲(chǔ)數(shù)據(jù)庫,后起之秀PolarDB與他的前輩Aurora有很多相似的地方,但也有著大不相同的硬件環(huán)境和架構(gòu)設(shè)計(jì),后續(xù)有機(jī)會(huì)會(huì)詳細(xì)介紹PolarDB中是如何利用Single Page Recovery能力獲得這些優(yōu)勢(shì)的。
審核編輯:湯梓紅
-
內(nèi)核
+關(guān)注
關(guān)注
3文章
1366瀏覽量
40234 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3767瀏覽量
64279 -
日志
+關(guān)注
關(guān)注
0文章
138瀏覽量
10633
原文標(biāo)題:參考
文章出處:【微信號(hào):inf_storage,微信公眾號(hào):數(shù)據(jù)庫和存儲(chǔ)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
提高Oracle的數(shù)據(jù)庫性能
基于數(shù)據(jù)庫日志復(fù)制和故障恢復(fù)

數(shù)據(jù)庫教程之如何進(jìn)行數(shù)據(jù)庫設(shè)計(jì)
數(shù)據(jù)庫教程之SQL Server數(shù)據(jù)庫管理的詳細(xì)資料說明
詳談MySQL數(shù)據(jù)庫的不同日志和源碼
盡可能限制NVM寫操作的數(shù)據(jù)庫日志方案NVRC

sql server 數(shù)據(jù)庫顯示正在恢復(fù)怎么辦?
華為云數(shù)據(jù)庫穩(wěn)定可靠-即開即用
【數(shù)據(jù)庫數(shù)據(jù)恢復(fù)】SQL server數(shù)據(jù)庫被加密的數(shù)據(jù)恢復(fù)方案
數(shù)據(jù)庫建立|數(shù)據(jù)庫創(chuàng)建的方法?
python讀取數(shù)據(jù)庫數(shù)據(jù) python查詢數(shù)據(jù)庫 python數(shù)據(jù)庫連接
數(shù)據(jù)庫優(yōu)化那些事
SQL Server數(shù)據(jù)庫備份方法
oracle數(shù)據(jù)庫alert日志作用
Oracle數(shù)據(jù)恢復(fù)—異常斷電后Oracle數(shù)據(jù)庫啟庫報(bào)錯(cuò)的數(shù)據(jù)恢復(fù)案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論