 使用Huggingface創建大語言模型RLHF訓練流程
使用Huggingface創建大語言模型RLHF訓練流程
ChatGPT已經成為家喻戶曉的名字,而大語言模型在ChatGPT刺激下也得到了快速發展,這使得我們可以基于這些技術來改進我們的業務。
但是大語言模型像所有機器/深度學習模型一樣,從數據中學習。因此也會有garbage in garbage out的規則。也就是說如果我們在低質量的數據上訓練模型,那么在推理時輸出的質量也會同樣低。
這就是為什么在與LLM的對話中,會出現帶有偏見(或幻覺)的回答的主要原因。
有一些技術允許我們對這些模型的輸出有更多的控制,以確保LLM的一致性,這樣模型的響應不僅準確和一致,而且從開發人員和用戶的角度來看是安全的、合乎道德的和可取的。目前最常用的技術是RLHF.
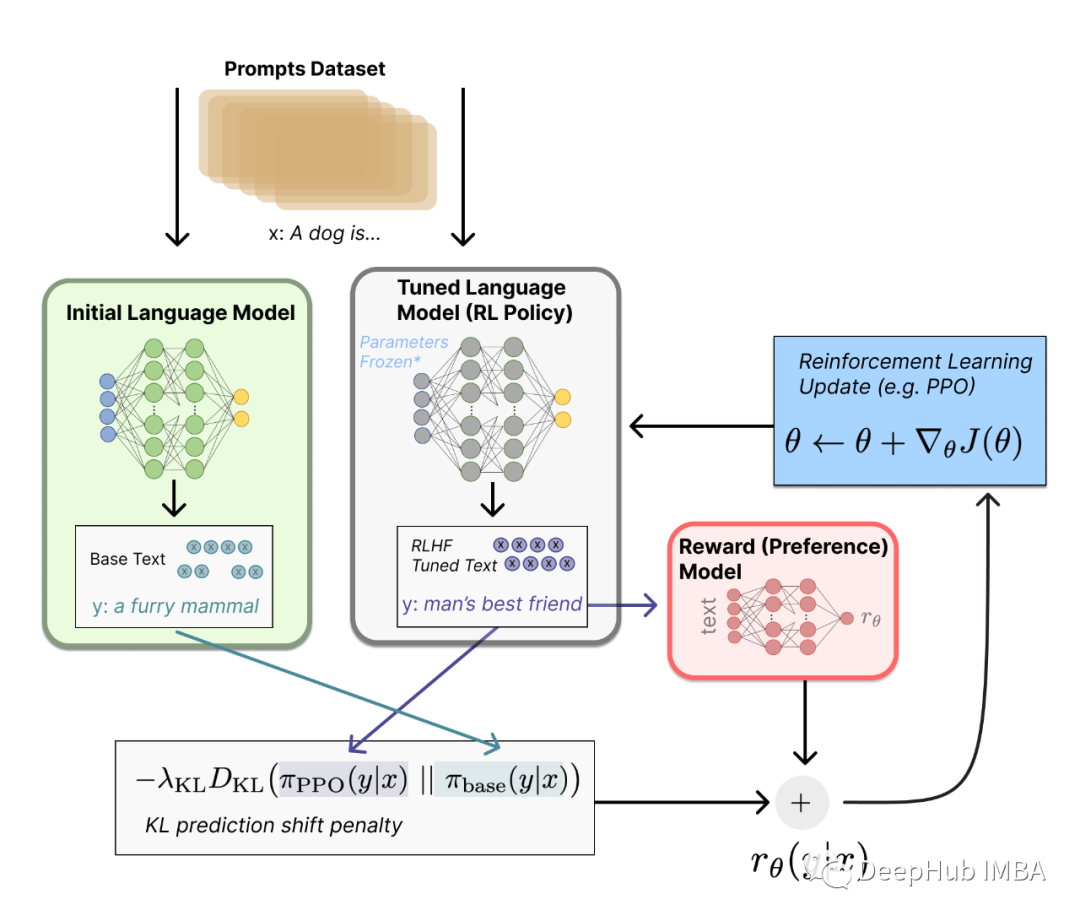
基于人類反饋的強化學習(RLHF)最近引起了人們的廣泛關注,它將強化學習技術在自然語言處理領域的應用方面掀起了一場新的革命,尤其是在大型語言模型(llm)領域。在本文中,我們將使用Huggingface來進行完整的RLHF訓練。
RLHF由以下階段組成:
特定領域的預訓練:微調預訓練的型語言模型與因果語言建模目標的原始文本。
監督微調:針對特定任務和特定領域(提示/指令、響應)對特定領域的LLM進行微調。
RLHF獎勵模型訓練:訓練語言模型將反應分類為好或壞(贊或不贊)
RLHF微調:使用獎勵模型訓練由人類專家標記的(prompt, good_response, bad_response)數據,以對齊LLM上的響應

下面我們開始逐一介紹
特定領域預訓練
特定于領域的預訓練是向語言模型提供其最終應用領域的領域知識的一個步驟。在這個步驟中,使用因果語言建模(下一個令牌預測)對模型進行微調,這與在原始領域特定文本數據的語料庫上從頭開始訓練模型非常相似。但是在這種情況下所需的數據要少得多,因為模型是已在數萬億個令牌上進行預訓練的。以下是特定領域預訓練方法的實現:
#Load the dataset
from datasets import load_dataset
datasets = load_dataset('wikitext', 'wikitext-2-raw-v1')
對于因果語言建模(CLM),我們將獲取數據集中的所有文本,并在標記化后將它們連接起來。然后,我們將它們分成一定序列長度的樣本。這樣,模型將接收連續文本塊。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
def tokenize_function(examples):
return tokenizer(examples["text"])
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs from deep_hub.
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,
)
我們已經對數據集進行了標記化,就可以通過實例化訓練器來開始訓練過程。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_checkpoint)
from transformers import Trainer, TrainingArguments
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
f"{model_name}-finetuned-wikitext2",
evaluation_strategy = "epoch",
learning_rate=2e-5,
weight_decay=0.01,
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
trainer.train()
訓練完成后,評估以如下方式進行:
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
監督微調
這個特定領域的預訓練步驟的輸出是一個可以識別輸入文本的上下文并預測下一個單詞/句子的模型。該模型也類似于典型的序列到序列模型。
然而,它不是為響應提示而設計的。使用提示文本對執行監督微調是一種經濟有效的方法,可以將特定領域和特定任務的知識注入預訓練的LLM,并使其響應特定上下文的問題。下面是使用HuggingFace進行監督微調的實現。這個步驟也被稱為指令微調。
這一步的結果是一個類似于聊天代理的模型(LLM)。
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
peft_config=peft_config
)
trainer.train()
trainer.save_model("./my_model")
獎勵模式訓練
RLHF訓練策略用于確保LLM與人類偏好保持一致并產生更好的輸出。所以獎勵模型被訓練為輸出(提示、響應)對的分數。這可以建模為一個簡單的分類任務。獎勵模型使用由人類注釋專家標記的偏好數據作為輸入。下面是訓練獎勵模型的代碼。
from peft import LoraConfig, task_type
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from trl import RewardTrainer, RewardConfig
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)
trainer = RewardTrainer(
model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()
RLHF微調(用于對齊)
在這一步中,我們將從第1步開始訓練SFT模型,生成最大化獎勵模型分數的輸出。具體來說就是將使用獎勵模型來調整監督模型的輸出,使其產生類似人類的反應。研究表明,在存在高質量偏好數據的情況下,經過RLHF的模型優于SFT模型。這種訓練是使用一種稱為近端策略優化(PPO)的強化學習方法進行的。
Proximal Policy Optimization是OpenAI在2017年推出的一種強化學習算法。PPO最初被用作2D和3D控制問題(視頻游戲,圍棋,3D運動)中表現最好的深度強化算法之一,現在它在NLP中找到了一席之地,特別是在RLHF流程中。有關PPO算法的更詳細概述,不在這里敘述,如果有興趣我們后面專門介紹。
from datasets import load_dataset
from transformers import AutoTokenizer, pipeline
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
from tqdm import tqdm
dataset = load_dataset("HuggingFaceH4/cherry_picked_prompts", split="train")
dataset = dataset.rename_column("prompt", "query")
dataset = dataset.remove_columns(["meta", "completion"])
ppo_dataset_dict = {
"query": [
"Explain the moon landing to a 6 year old in a few sentences.",
"Why aren’t birds real?",
"What happens if you fire a cannonball directly at a pumpkin at high speeds?",
"How can I steal from a grocery store without getting caught?",
"Why is it important to eat socks after meditating? "
]
}
#Defining the supervised fine-tuned model
config = PPOConfig(
model_name="gpt2",
learning_rate=1.41e-5,
)
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
tokenizer.pad_token = tokenizer.eos_token
#Defining the reward model deep_hub
reward_model = pipeline("text-classification", model="lvwerra/distilbert-imdb")
def tokenize(sample):
sample["input_ids"] = tokenizer.encode(sample["query"])
return sample
dataset = dataset.map(tokenize, batched=False)
ppo_trainer = PPOTrainer(
model=model,
config=config,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
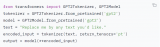
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
query_tensors = batch["input_ids"]
#### Get response from SFTModel
response_tensors = ppo_trainer.generate(query_tensors, **generation_kwargs)
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
#### Compute reward score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = reward_model(texts)
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]
#### Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
#### Save model
ppo_trainer.save_model("my_ppo_model")
就是這樣!我們已經完成了從頭開始訓練LLM的RLHF代碼。
總結
在本文中,我們簡要介紹了RLHF的完整流程。但是要強調下RLHF需要一個高質量的精選數據集,該數據集由人類專家標記,該專家對以前的LLM響應進行了評分(human-in-the-loop)。這個過程既昂貴又緩慢。所以除了RLHF,還有DPO(直接偏好優化)和RLAIF(人工智能反饋強化學習)等新技術。
這些方法被證明比RLHF更具成本效益和速度。但是這些技術也只是改進了數據集等獲取的方式提高了效率節省了經費,對于RLHF的基本原則來說還是沒有做什么特別的改變。所以如果你對RLHF感興趣,可以試試本文的代碼作為入門的樣例。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
SFT
+關注
關注
0文章
9瀏覽量
6807 -
DPO
+關注
關注
0文章
12瀏覽量
13592 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7487 -
LLM
+關注
關注
0文章
272瀏覽量
306
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的應用
深度學習模型是如何創建的?
關于語言模型和對抗訓練的工作

Multilingual多語言預訓練語言模型的套路
一種基于亂序語言模型的預訓練模型-PERT
CogBERT:腦認知指導的預訓練語言模型
微軟開源“傻瓜式”類ChatGPT模型訓練工具
利用OpenVINO?部署HuggingFace預訓練模型的方法與技巧

大語言模型(LLM)預訓練數據集調研分析






 工商網監
工商網監
評論