 SoC常見問題 - axi deadlock
SoC常見問題 - axi deadlock
最近多個項目并行,實在是沒有時間分享了,今天在評論區看到了一個非常有意義的問題,同樣也是社招,校招最常見的問題。那就是AXI協議怎么避免死鎖呢?
兩種死鎖場景分別是亂序讀和寫交織,有的人更熟悉英文,那就是out of order和interleaving。下面我們分析原因。
亂序讀:我們知道AXI協議支持亂序讀,那么為什么能實現呢?這也是常見面試題目,那就是因為AXI(現在單指AXI3)每個通路都有相應的ID,通過請求和響應ID的一致來將打亂的順序恢復。
現在假設M1發給S1的請求ID可以是1,2,3,M1發給S2的ID可以是3,4,5。現在M1分別發起了兩組outstanding傳輸給S1和S2,RID是隨機的,也就是ARID_S1和ARID_S2存在都是3的可能。并且如圖,S1/S2響應的時間是不同的,所以也就存在S1和S2 RID=3的響應順序是不確定的,例如M1>S2先發出ID=3的請求,長度為16,又發出M1>S1的ID=3的請求,長度為8,但是由于S2響應慢,M1會先拿到S1的響應,那么M1收到ID為3的響應時該怎么區分呢?答案是無法區分,所以這種場景會造成M1工作異常(接到全部數據的時候沒有rlast信號,此時正處于S2響應的中間,并沒有RLAST會導致M1認為傳輸錯誤)。具體解決方案是per slave per id,M0發起訪問時,會判斷已經發出去的ID,保證每個slave收到的ID是唯一的,所以我們設計axi master時也要這樣,當然,我們也可以投機取巧,固定值。
想必一定有熟悉coreconsulatant和ARM NIC的同學,配置的時候有兩個參數,那就是每組outstanding可以使用的ID個數,以及每個ID對應的指令個數,兩者相乘就是outstanding能力,所以為了避免死鎖我們會將ID個數配置為1(當然僅限第一級矩陣,也就是和自研AXI_M連接的地方,這樣太暴力),這樣Master就很容易區分不同slave設備的響應了,但是缺點也很明顯,那就是會降低性能,不同ID的請求會被矩陣master反壓,所以我們設置的需要合理。怎么算合理呢?首先如果大家看過cpu文檔,會發現ID個數以及不同ID的含義是有明確定義的,所以我們配置時要考慮master的ID個數,但是master cpu訪問我們時限制不了的,所以我們會在那里下手呢?那就是矩陣,需要做remap,NIC和NOC都有這種設計,實時保證ID的唯一性。
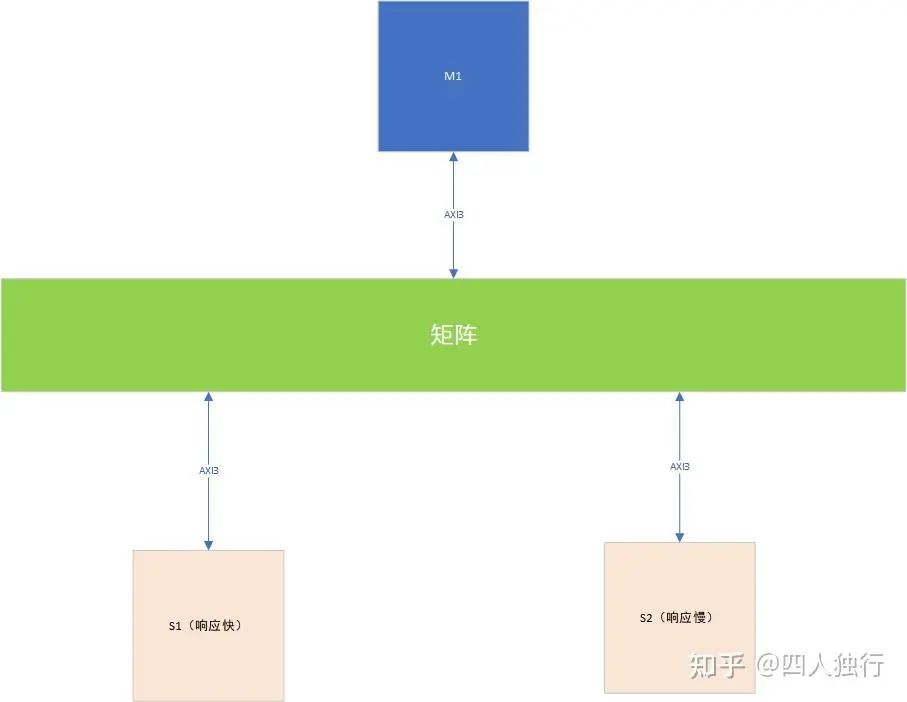
亂序讀死鎖常見結構
交織寫:AXI3協議支持交織寫,原因就是容易造成總線死鎖,其實并不是交織寫容易造成死鎖,而是某些場景容易出現(矩陣配置不合理,或者不同路徑delay分析不正確)。我們分析一下原因。
如下圖,假設M1對S1地址發起多次burst傳輸,并且因為矩陣支持交織寫,會把M1訪問的順序打亂(原因是master的數據也是由上級傳遞過來的,順序可能不同)。如果不好理解的話,可以抽象將M1和M2認為是一個master,都在訪問S1,矩陣的interleaving深度是>1的,也就是S1出口會將寫的順序打亂,導致waddr和wdata的順序改變,那么結果是什么呢?那就是驢頭不對馬嘴,想寫A1,但是數據卻寫到了A2地址,但是控制通路已經規定了burst長度,如果wlast出現的時候數據不夠,或者多了,當然會讓slave出現問題嘍。
這也是為什么AXI4取消了WID的主要原因。
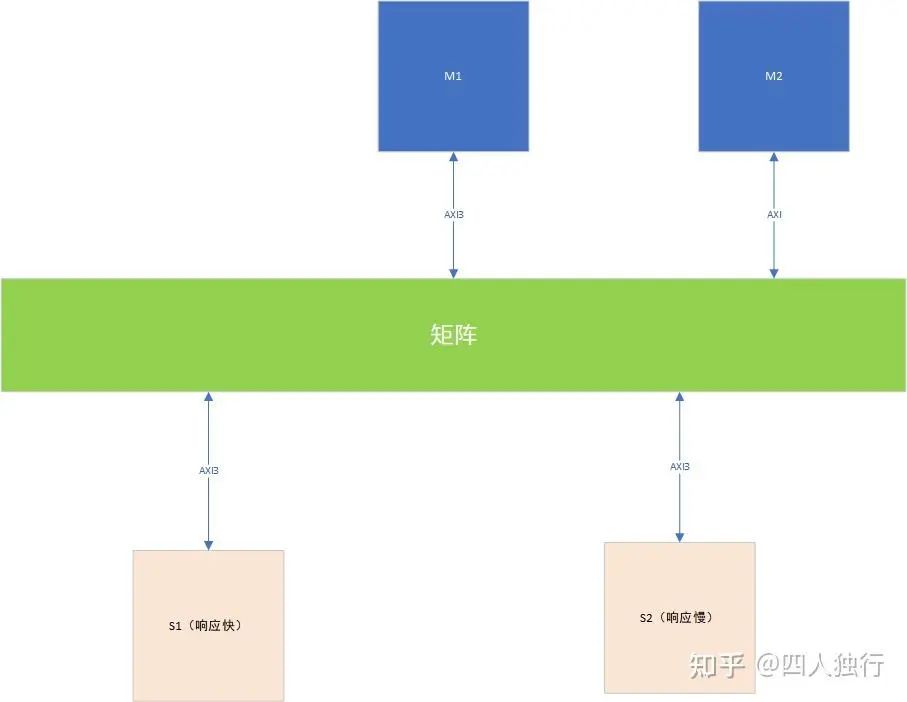
交織寫死鎖常見結構
交織讀為什么不容易死鎖呢?
如果是M1訪問S1,根本不會出現交織,這個場景安全。
如果M1同時訪問S1和S2,因為矩陣延遲的不同,很有可能發生交織,但是由于ARID和RID不同,也不會造成死鎖。也是安全的。
但是當然存在不安全的場景,那就是master不支持交織,矩陣支持交織,同樣會導致總線異常,所以我們配置矩陣IP時,一定要充分了解所有的master設備和slave設備。主要參數如下:outstanding能力,read interleaving深度,master id寬度,master個數,slave id寬度(矩陣slave口ID寬度會受master個數影響,id一定不能截位,但是可以remap)等。
-
soc
+關注
關注
38文章
4124瀏覽量
217966 -
MASTER
+關注
關注
0文章
103瀏覽量
11266 -
AXI
+關注
關注
1文章
127瀏覽量
16598
原文標題:SoC常見問題 - axi deadlock
文章出處:【微信號:IP與SoC設計,微信公眾號:IP與SoC設計】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
soc開發流程常見問題及解決方案
KeyStone設備的PCI Express (PCle)常見問題

PCB設計中的常見問題有哪些?

SoC設計中總線協議AXI4與AXI3的主要區別詳解

步進電機常見問題及維護






 工商網監
工商網監
評論