") 谷歌發(fā)布史上最強(qiáng)大模型Gemini,全方位領(lǐng)先GPT-4,MMLU基準(zhǔn)達(dá)人類專家水平
谷歌發(fā)布史上最強(qiáng)大模型Gemini,全方位領(lǐng)先GPT-4,MMLU基準(zhǔn)達(dá)人類專家水平
電子發(fā)燒友網(wǎng)報(bào)道(文/吳子鵬)美國當(dāng)?shù)貢r(shí)間周三,谷歌發(fā)布了其新一代人工智能模型Gemini(雙子星)。谷歌CEO桑達(dá)爾?皮查伊和Deepmind CEO戴密斯·哈薩比斯在谷歌官網(wǎng)聯(lián)名發(fā)文,官宣了最新多模態(tài)大模型Gemini 1.0版本正式上線。
這次發(fā)布是按照谷歌此前的預(yù)期,但是對(duì)于業(yè)界而言非常突然。因?yàn)榫驮谝恢芮斑€有報(bào)告指出,谷歌原本計(jì)劃本周(當(dāng)時(shí)稱下周)發(fā)布Gemini,但現(xiàn)在已經(jīng)推遲到2024年1月。報(bào)告給出的原因是,谷歌“發(fā)現(xiàn)人工智能不能可靠地處理一些非英語查詢”,該公司認(rèn)為全球語言支持是最重要的,這是谷歌追趕和超越OpenAI GPT-4的關(guān)鍵性能之一。
現(xiàn)在,谷歌還是如期將Gemini 1.0上線了。
史上最強(qiáng)的AI大模型
從定位來看,Gemini 1.0版本是桑達(dá)爾?皮查伊親自督導(dǎo),籌備一年多時(shí)間,并瞄準(zhǔn)OpenAI GPT-4的大模型。很顯然,Gemini 1.0版本的效果是遠(yuǎn)超預(yù)期的,成為目前已經(jīng)上線發(fā)布的最強(qiáng)大的AI大模型,也是有史以來最強(qiáng)大的AI大模型。
據(jù)介紹,Gemini 1.0版本會(huì)有三個(gè)細(xì)分的版本:
·Gemini Ultra:谷歌最大、最強(qiáng)模型,適用于高度復(fù)雜的任務(wù)
·Gemini Pro:可擴(kuò)展至各種任務(wù)的Gemini模型
·Gemini Nano:適用于端側(cè)設(shè)備的高效Gemini版本(1.8B/3.25B)
Gemini 1.0版本是一個(gè)純正的多模態(tài)AI大模型,為什么要這樣說呢?因?yàn)镚emini是以多模態(tài)模型為目標(biāo)重新構(gòu)建的,在復(fù)雜操作以及處理不同類型信息方面,其效率和絲滑度是當(dāng)前其他模型不可比擬的,這些信息包括文本、代碼、音頻、圖像和視頻。所以,Gemini也是迄今為止最靈活的大模型。
在基礎(chǔ)設(shè)施方面,谷歌使用自研的Tensor處理單元(TPU)v4和v5e對(duì)Gemini 1.0進(jìn)行訓(xùn)練。因此,在Gemini 1.0版本發(fā)布的同時(shí),谷歌也宣布推出迄今為止最強(qiáng)大、最高效、最可擴(kuò)展的TPU系統(tǒng)Cloud TPU v5p,專為訓(xùn)練尖端人工智能模型而設(shè)計(jì)。根據(jù)此前的爆料,Gemini 1.0版本訓(xùn)練需要的算力規(guī)模是GPT-4的5倍。
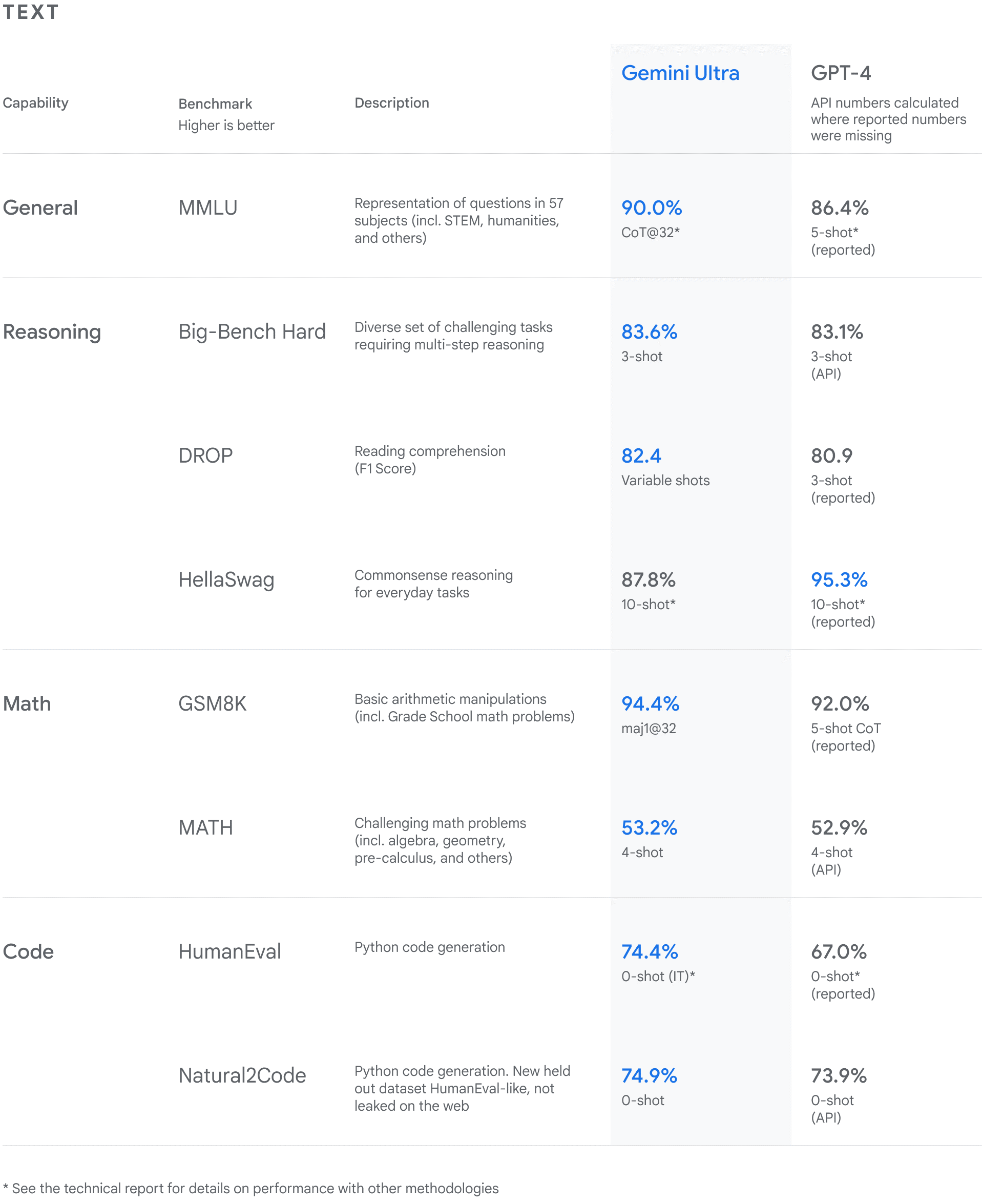
全新的設(shè)計(jì)和強(qiáng)大的算力底座,讓Gemini 1.0版本成了一個(gè)性能怪獸。根據(jù)谷歌發(fā)布的報(bào)告,在32項(xiàng)廣泛使用的基準(zhǔn)測試中,Gemini Ultra獲得了30個(gè)SOTA(State of the art,特指領(lǐng)先水平的大模型)。能夠看出,Gemini 1.0版本在文本、代碼、音頻、圖像和視頻處理能力方面,以及推理、數(shù)學(xué)、代碼等方面的能力均比GPT-4更加出色,可以說是全方位吊打GPT-4。
圖源:谷歌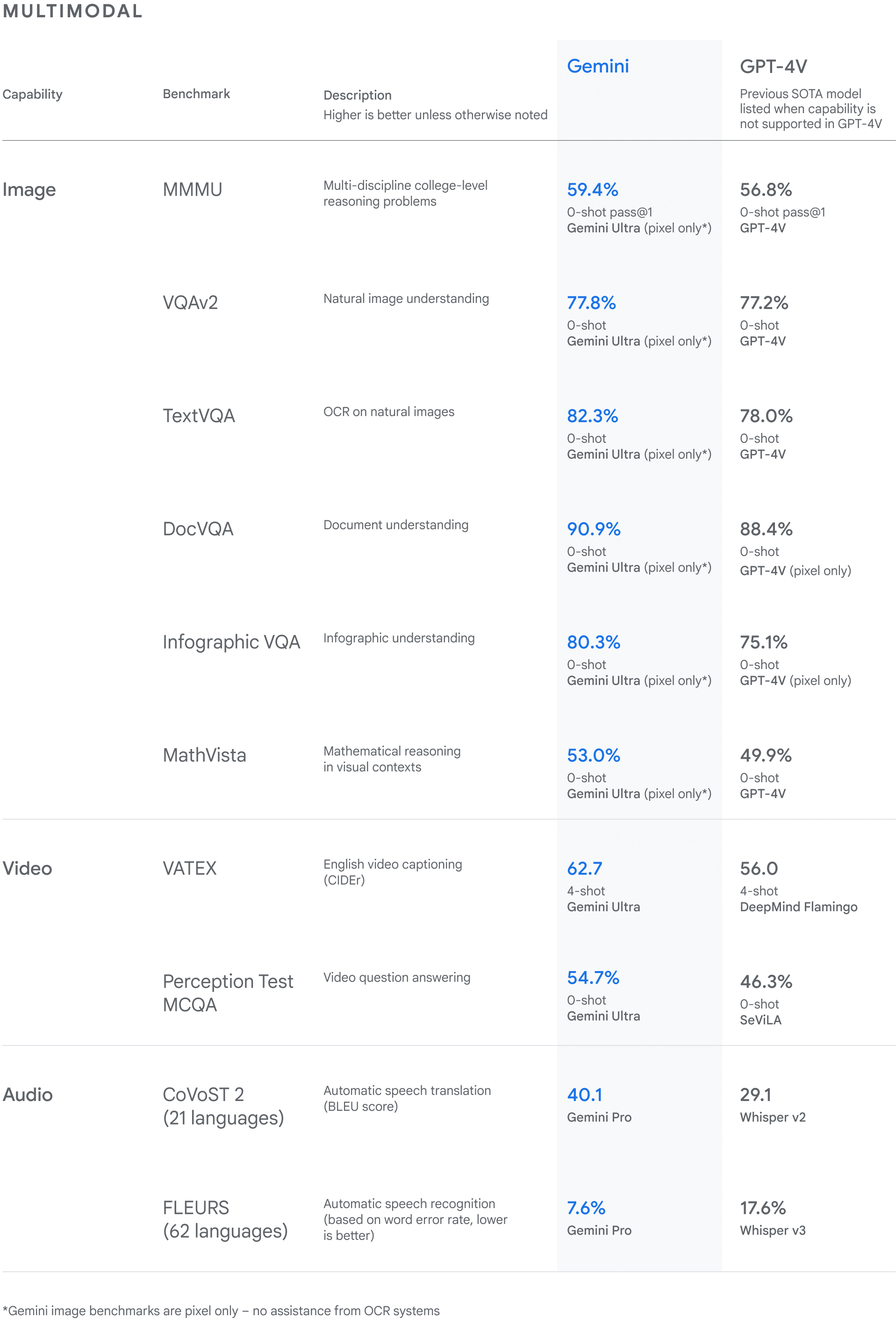
圖源:谷歌
根據(jù)以上兩圖,Gemini在MMLU(大規(guī)模多任務(wù)語言理解數(shù)據(jù)集)和MMMU(基于大學(xué)考試的測試基準(zhǔn))的成績格外值得關(guān)注。其中,Gemini Ultra在MMLU測試中的得分率高達(dá) 90.0%,首次超越了人類專家。MMLU數(shù)據(jù)集包含數(shù)學(xué)、物理、歷史、法律、醫(yī)學(xué)和倫理等 57 個(gè)科目,用于測試大模型的知識(shí)儲(chǔ)備和解決問題能力。
在權(quán)威MMMU測試中,Gemini Ultra也獲得了59.4%的SOTA分?jǐn)?shù)。MMMU由IN.AI Research 等多所機(jī)構(gòu)組成的研究團(tuán)隊(duì)一同推出,可用于評(píng)估AI在大學(xué)水平的多學(xué)科問題上的多模態(tài)理解和推理能力。其中包含的問題來自大學(xué)考試、測驗(yàn)和教科書,涉及六個(gè)常見學(xué)科:藝術(shù)與設(shè)計(jì)、商科、科學(xué)、健康與醫(yī)學(xué)、人文與社會(huì)科學(xué)、技術(shù)與工程。MMMU包含1.15萬個(gè)精心選取的多模態(tài)問題,涵蓋30個(gè)不同的科目和183個(gè)子領(lǐng)域,因此滿足廣度目標(biāo)。谷歌認(rèn)為,在MMMU中取得這樣的分?jǐn)?shù),證明Gemini在更復(fù)雜推理任務(wù)中還有更大的潛力值得挖掘。
谷歌認(rèn)為,Gemini作為一個(gè)原生的多模態(tài)大模型,和單獨(dú)訓(xùn)練拼接而成的多模態(tài)大模型有很大的不同,帶來了巨大的性能提升,并通過多模式級(jí)聯(lián)的數(shù)據(jù)進(jìn)行了調(diào)優(yōu),以進(jìn)一步完善其有效性。這就是為什么,Gemini幾乎在任何領(lǐng)域都是最領(lǐng)先的。
在谷歌發(fā)布的報(bào)告中,該公司基于Gemini進(jìn)行了復(fù)雜推理的顯示,比如Gemini可以非常高效地從數(shù)十萬份文件中獲取對(duì)科學(xué)家有用的數(shù)據(jù),并創(chuàng)建數(shù)據(jù)集。你甚至可以讓它幫你給這些有價(jià)值的數(shù)據(jù)做進(jìn)一步的標(biāo)注。
在另一個(gè)案例中,Gemini可以在世界上最受歡迎的編程語言(如Python、Java、C++和Go)中理解、解釋和生成高質(zhì)量的代碼。由于對(duì)全球語言都有很好的支持,Gemini可以跨語言工作并對(duì)復(fù)雜信息進(jìn)行推理,使其成為世界上領(lǐng)先的編碼的基礎(chǔ)模型之一。基于Gemini,谷歌創(chuàng)建了一個(gè)更先進(jìn)的代碼生成系統(tǒng)AlphaCode 2,該系統(tǒng)擅長解決超越編碼的競爭性編程問題,涉及復(fù)雜的數(shù)學(xué)和理論計(jì)算機(jī)科學(xué)。
憑借GPT大模型,OpenAI這幾年的風(fēng)頭蓋過了谷歌,現(xiàn)在憑借Gemini,谷歌打了一個(gè)漂亮的翻身仗。不過,桑達(dá)爾?皮查伊在接受采訪時(shí)表示,Gemini只是領(lǐng)先GPT-4一點(diǎn)點(diǎn),“想想看,向人工智能的轉(zhuǎn)變是多么深刻,我們還處于早期階段,前方的世界充滿機(jī)遇。”
谷歌表示,Gemini將通過谷歌產(chǎn)品推向數(shù)十億用戶。從12月13日開始,開發(fā)者和企業(yè)客戶可以通過Google AI Studio或Google Cloud Vertex AI中的Gemini API訪問Gemini Pro。2024年初,谷歌還將推出Bard Advanced,這是一種新的頂級(jí)人工智能體驗(yàn),讓用戶從Gemini Ultra開始訪問谷歌最好的模型和功能。
更強(qiáng)的功能與更大的擔(dān)憂
在Gemini的介紹報(bào)告中,谷歌花費(fèi)很大篇幅來闡述責(zé)任和安全。在報(bào)告中谷歌提到,“在谷歌,我們致力于在我們所做的一切工作中推進(jìn)大膽和負(fù)責(zé)任的人工智能。基于谷歌的人工智能原則和我們產(chǎn)品的強(qiáng)大安全政策,我們正在添加新的保護(hù)措施來保證Gemini的多模式聯(lián)運(yùn)能力。在開發(fā)的每個(gè)階段,我們都在考慮潛在風(fēng)險(xiǎn),并努力測試和減輕它們。”
“我們對(duì)迄今為止的任何谷歌人工智能模型進(jìn)行了最全面的安全評(píng)估,包括偏見和數(shù)據(jù)毒性。我們對(duì)網(wǎng)絡(luò)犯罪、說服和自主意識(shí)等潛在風(fēng)險(xiǎn)領(lǐng)域進(jìn)行了新的研究,并應(yīng)用了谷歌一流的對(duì)抗性測試技術(shù),以幫助在Gemini部署之前識(shí)別關(guān)鍵安全問題。”
同時(shí),為了減少測試的盲點(diǎn),谷歌也在與外部專家和合作伙伴一起進(jìn)行壓力測試。然而,就像桑達(dá)爾?皮查伊提到,很多基準(zhǔn)測試還在逐步完善一樣,實(shí)際上對(duì)于AI大模型的安全測試也是如此,很多方面的測試都還是空白,人們在使用一些對(duì)付傳統(tǒng)人工智能的手段來對(duì)AI大模型進(jìn)行壓力測試,但這顯然是不夠的。
目前,行業(yè)將AI大模型的安全風(fēng)險(xiǎn)分為三個(gè)方向,分別是訓(xùn)練數(shù)據(jù)、模型本身和使用場景。在訓(xùn)練數(shù)據(jù)方面,數(shù)據(jù)采集不當(dāng)、存在偏見或標(biāo)簽錯(cuò)誤、數(shù)據(jù)被投毒等都被視為安全風(fēng)險(xiǎn);在模型本身,模型的可靠性、穩(wěn)定性、魯棒性等都是測試項(xiàng),同時(shí)企業(yè)也在關(guān)注模型被誤導(dǎo)性;然后在使用階段,主要防范欺詐、歧視、政治傾向等風(fēng)險(xiǎn)內(nèi)容,以及用戶數(shù)據(jù)的保護(hù)。
表面上看,好像已經(jīng)能夠覆蓋大模型各方面的風(fēng)險(xiǎn),但是在目前的方案中,企業(yè)發(fā)現(xiàn)由于大模型處于野蠻生長的階段,很多問題都是未知的。于是乎,ChatGPT被發(fā)現(xiàn)存在大量具有攻擊性的行為。行業(yè)想到的辦法是用魔法打敗魔法——以AI對(duì)抗AI。
然而,魔高一尺還是道高一丈,這實(shí)際上也是不可控的。
今年3月份,一封千位大佬的聯(lián)名信呼吁,應(yīng)該立即停止訓(xùn)練比GPT-4更強(qiáng)大的AI系統(tǒng),暫停期至少6個(gè)月。簽名的有圖靈獎(jiǎng)得主Yoshua Bengio、Stability AI首席執(zhí)行官Emad Mostaque、蘋果聯(lián)合創(chuàng)始人Steve Wozniak、紐約大學(xué)教授馬庫斯、馬斯克,以及《人類簡史》作者Yuval Noah Harari等。但此事似乎并沒有什么結(jié)論。
也就在日前,OpenAI公布了該公司在安全方面的舉措,實(shí)際上和谷歌等公司都是大同小異,且都說明對(duì)于AI大模型的防護(hù)也是需要不斷完善,通過實(shí)踐和研究來解決安全問題。
不難預(yù)見,新一輪AI大模型“競賽”開始了,安全和責(zé)任制措施當(dāng)然也會(huì)升級(jí),但模型和防護(hù)誰發(fā)展更快,相信更多人都傾向于相信前者發(fā)展更加野蠻。
結(jié)語
Gemini模型的發(fā)布標(biāo)志著,全球AI大模型發(fā)展正式進(jìn)入原生多模態(tài)時(shí)代,模型的各項(xiàng)性能和數(shù)據(jù)融合能力將顯著增強(qiáng)。在更廣泛的領(lǐng)域,AI大模型將取代人工,且比人工更加出色。不過,安全問題似乎并沒有被妥善解決,新一輪AI大模型競賽就直接開始了。
-
谷歌
+關(guān)注
關(guān)注
27文章
6142瀏覽量
105114 -
Gemini
+關(guān)注
關(guān)注
0文章
51瀏覽量
7583
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
谷歌計(jì)劃12月發(fā)布Gemini 2.0模型
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯(cuò)
GPT-4人工智能模型預(yù)測公司未來盈利勝過人類分析師
商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對(duì)標(biāo)GPT-4 Turbo
微軟Copilot全面更新為OpenAI的GPT-4 Turbo模型
新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

全球最強(qiáng)大模型易主,GPT-4被超越
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標(biāo)桿
全球最強(qiáng)大模型易主:GPT-4被超越,Claude 3系列嶄露頭角
Gemini和ChatGPT有什么不同,Gemini將超越ChatGPT?

谷歌推出Gemini 希望擊敗GPT-4
ChatGPT plus有什么功能?OpenAI 發(fā)布 GPT-4 Turbo 目前我們所知道的功能

成都匯陽投資關(guān)于谷歌攜 Gemini 王者歸來,AI 算力和應(yīng)用值得期待
新火種AI|谷歌深夜發(fā)布復(fù)仇神器Gemini,原生多模態(tài)碾壓GPT-4?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論