 低比特量化技術如何幫助LLM提升性能
低比特量化技術如何幫助LLM提升性能
作者:楊亦誠
針對大語言模型 (LLM) 在部署過程中的性能需求,低比特量化技術一直是優化效果最佳的方案之一,本文將探討低比特量化技術如何幫助 LLM 提升性能,以及新版 OpenVINO對于低比特量化技術的支持。
大模型性能瓶頸
相比計算量的增加,大模型推理速度更容易受到內存帶寬的影響(memory bound),也就是內存讀寫效率問題,這是因為大模型由于參數量巨大、訪存量遠超內存帶寬容量,意味著模型的權重的讀寫速度跟不上硬件對于算子的計算強度,導致算力資源無法得到充分發揮,進而影響性能。
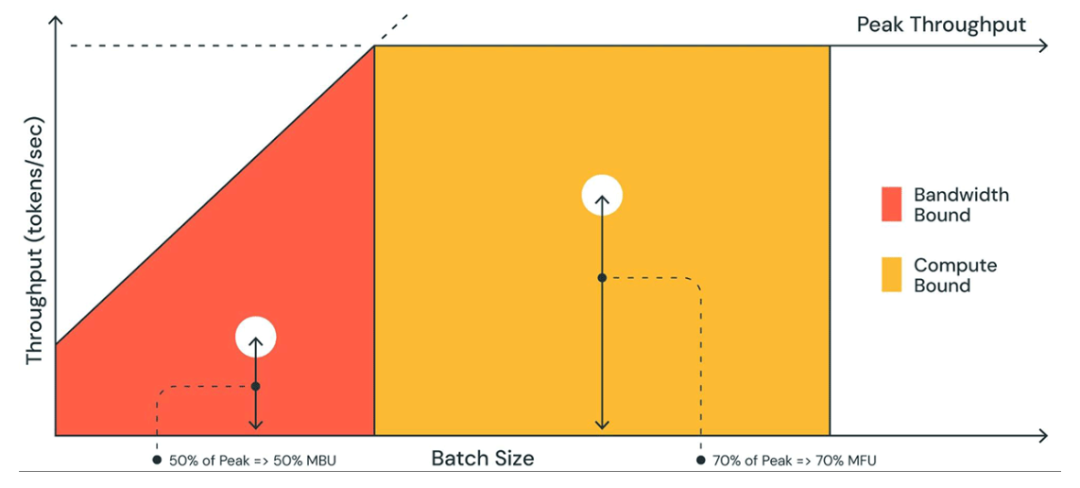
圖:memory bound與compute bound比較
低比特量化技術
低比特量化技術是指將模型參數從 fp32/fp16 壓縮到更低的比特位寬表達,在不影響模型輸出準確性和參數量的情況下,降低模型體積,從而減少緩存對于數據讀寫的壓力,提升推理性能。由于大模型中單個 layer 上的權重體積往往要遠大于該 layer 的輸入數據(activation),因此針對大模型的量化技術往往只會針對關鍵的權重參數進行量化(WeightOnly),而不對輸入數據進行量化,在到達理想的壓縮比的同時,盡可能保證輸出結果,實現最高的量化“性價比”。
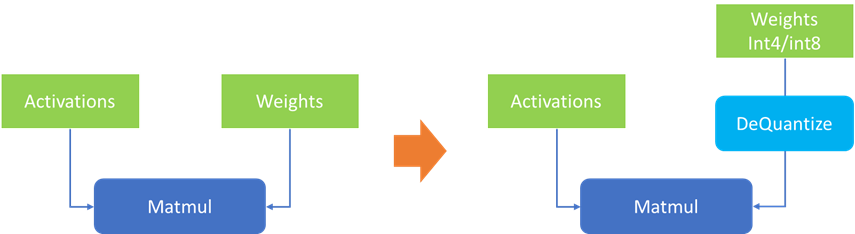
圖:權重壓縮示意
經驗證常規的 int8 權重量化,對大模型準確性的影響極低,而為了引入像 int4,nf4 這樣的更極致的壓縮精度,目前在權重量化算法上也經過了一些探索,其中比較典型的就是 GPTQ 算法,簡單來說,GPTQ 對某個 block 內的所有參數逐個量化,每個參數量化后,需要適當調整這個 block 內其他未量化的參數,以彌補量化造成的精度損失。GPTQ 量化需要準備校準數據集,因此他也是一種 PTQ(Post Training Quantization)量化技術。
OpenVINO 2023.2
對于 int4 模型的支持
OpenVINO 2023.2 相較 2023.1 版本,全面引入對 int4 模型以及量化技術的支持。主要有以下 2 個方面:
01CPU 及 iGPU 支持原生 int4 模型推理
OpenVINO工具目前已經可以直接讀取經 NNCF 量化以后的 int4 模型,或者是將 HuggingFace 中使用 AutoGPTQ 庫量化的模型轉換后,進行讀取及編譯。由于目前的 OpenVINO 后端硬件無法直接支持 int4 數據格式的運算,所以在模型執行過程中,OpenVINO runtime 會把 int4 的權重反量化的到 FP16 或是 BF16 的精度進行運算。簡而言之:模型以 int4 精度存儲,以 fp16 精度計算,用計算成本換取空間及 IO 成本,提升運行效率。這也是因為大模型的性能瓶頸主要來源于 memory bound,用更高的數據讀寫效率,降低對于內存帶寬與內存容量的開銷。
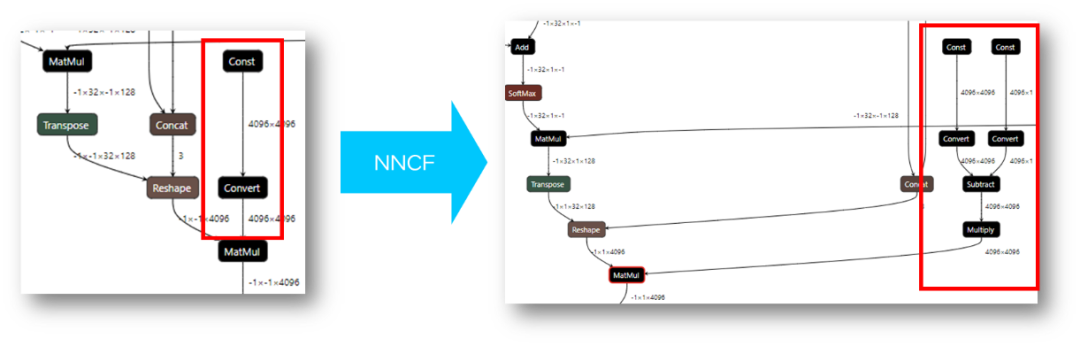
圖:經 NNCF 權重壓縮后的模型結構
02NNCF 工具支持 int4 的混合精度量化策略(Weights Compression)
剛提到的 GPTQ 是一種 data-based 的量化方案,需要提前準備校驗數據集,借助 HuggingFace 的 Transformers 和 AutoGPTQ 庫可以完成這一操作。而為了幫助開發者縮短 LLM 模型的壓縮時間,降低量化門檻,NNCF 工具在 2.7.0 版本中引入了針對 int4 以及 nf4 精度的權重壓縮模式,這是一種 data-free 的混合精度量化算法,無需準備校驗數據集,僅對 LLM 中的 Linear 和 Embedding layers 展開權重壓縮。整個過程僅用一行代碼就可以完成:
compressed_model = compress_weights(model, mode=CompressWeightsMode.NF4, group_size=64, ratio=0.9)
左滑查看更多
其中model為 PyTorch 或 OpenVINO 的模型對象;mode代表量化模式,這里可以選擇CompressWeightsMode.NF4,或是CompressWeightsMode.INT4_ASYM/INT4_SYM等不同模式;為了提升量化效率,Weights Compression 使用的是分組量化的策略(grouped quantization),因此需要通過group_size配置組大小,例如 group_size=64 意味 64 個 channel 的參數將共享同一組量化參數(zero point, scale value);此外鑒于 data-free 的 int4 量化策略是比帶來一定的準確度損失,為了平衡模型體積和準確度,Weights Compression 還支持混合精度的策略,通過定義ratio值,我們可以將一部分對準確度敏感的權重用 int8 表示,例如在 ratio=0.9 的情況下,90% 的權重用 int4 表示,10% 用 int8 表示,開發者可以根據量化后模型的輸出結果調整這個參數。
在量化過程中,NNCF 會通過搜索的方式,逐層比較偽量化后的權重和原始浮點權重的差異,衡量量化操作對每個 layer 可能帶來的誤差損失,并根據排序結果以及用戶定義的 ratio 值,將損失相對較低的權重壓縮到 int4 位寬。
中文大語言模型實踐
隨著 OpenVINO2023.2 的發布,大語言模型的 int4 壓縮示例也被添加到了openvino_notebooks 倉庫中,這次特別新增了針對中文 LLM 的示例,包括目前熱門模型ChatGLM2和Qwen。在這個 notebook 中,開發者可以體驗如何從 HuggingFace 的倉庫中導出一個 OpenVINO IR 格式的模型,并通過 NNCF 工具進行低比特量化,最終完成一個聊天機器人的構建。
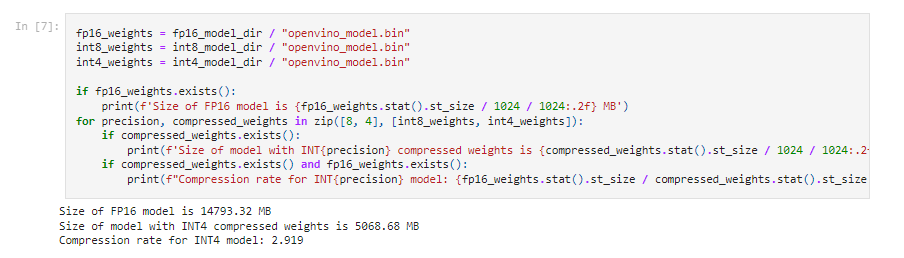
圖:fp16 與 int4 模型空間占用比較
通過以上這個截圖可以看到,qwen-7b-chat 經過 NNCF 的 int4 量化后,可以將體積壓縮到原本 fp16 模型的 1/3,這樣使得一臺 16GB 內存的筆記本,就可以流暢運行壓縮以后的 ChatGLM2 模型。此外我們還可以通過將 LLM 模型部署在酷睿 CPU 中的集成顯卡上,在提升性能的同時,減輕 CPU 側的任務負載。
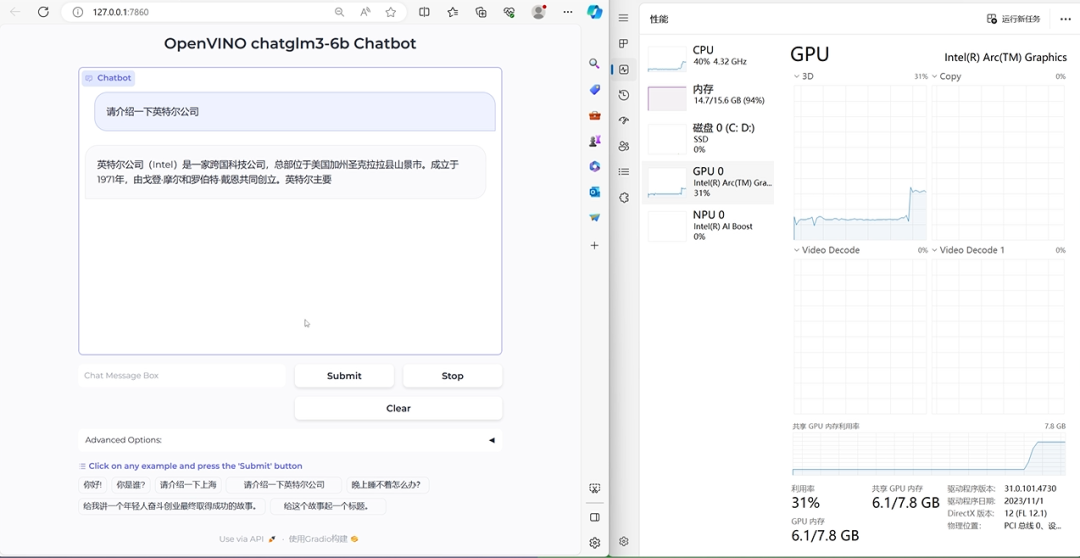
圖:Notebook 運行效果
總結
OpenVINO 2023.2 中對 int4 權重量化的支持,可以全面提升大模型在英特爾平臺上的運行性能,同時降低對于存儲和內存的容量需求,降低開發者在部署大模型時的門檻,讓本地化的大語言模型應用在普通 PC 上落地成為可能。
審核編輯:湯梓紅
-
輕量化技術
+關注
關注
0文章
6瀏覽量
2219 -
大模型
+關注
關注
2文章
2136瀏覽量
1980 -
LLM
+關注
關注
0文章
247瀏覽量
279 -
OpenVINO
+關注
關注
0文章
73瀏覽量
139
原文標題:如何利用低比特量化技術在 iGPU 上進一步提升大模型推理性能|開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【比特熊充電棧】實戰演練構建LLM對話引擎

最新可用隔離元件的性能提升如何幫助替代架構在不影響安全性的前提下提升系統性能
多核和多線程技術怎么提升Android網頁瀏覽性能?
求一種采用分段量化和比特滑動技術的流水并行式模數轉換電路?
量化算法介紹及其特點分析
如何將抖動添加到信號以通過消除量化誤差和失真來提高模數轉換系統的性能
LLM性能的主要因素

LLaMa量化部署

基于MacroBenchmark的性能測試量化指標方案
Nvidia 通過開源庫提升 LLM 推理性能
什么是LLM?LLM的工作原理和結構
大模型LLM與ChatGPT的技術原理
深度學習模型量化方法






 工商網監
工商網監
評論