 SuperPoint語義 SLAM深度學習用于特征提取
SuperPoint語義 SLAM深度學習用于特征提取
1. 概況
作者的寫作思路很清晰,把各個技術點這么做的原因寫的很清楚,全文共三篇,可以看清作者在使用深度學習進行位姿估計這一方法上的思路演變過程,為了把這一脈絡理清楚,我們按照時間順序對這三篇文章分別解讀,分別是:
1)Deep Image Homography Estimation
2)Toward Geometric Deep SLAM
3)SuperPoint: Self-Supervised Interest Point Detection and Description
本期,我們首先對Deep Image Homography Estimation進行解讀。
2. 第一篇
Deep Image Homography Estimation
礦視成果
參考R TALK |圖像對齊及其應用(https://zhuanlan.zhihu.com/p/99758095Deep)
1.1. 概述
Deep Image Homography Estimation 是通過端到端的方式估計一對圖像的單應矩陣。訓練數據集是從MS-COCO上選取圖片,然后把這張圖片進行單應性變換得到圖象對的方式生成的。為了得到矩陣變換的置信度(比如slam中設置方差需要這些東西),作者把網絡分成兩部分,分別對應兩種輸出,一種輸出單一變換結果,另一種輸出多個可能的變換結果,并給出每種變換結果的置信度,實際使用時,選擇置信度最高的那個。
1.2. 算法流程
1.2.1 基礎知識
本篇文章所提出的方法輸出的是單應性矩陣,所謂單應性矩陣,就是圖象中的目標點認為是在一個平面上,相應的,如果不在一個平面上則被成為基礎矩陣。
在實際的slam應用中,單應矩陣在以下這三種情況時需要用到:
相機只有旋轉而無平移的時候,兩視圖的對極約束不成立,基礎矩陣F為零矩陣,這時候需要使用單應矩陣H場景中的點都在同一個平面上,可以使用單應矩陣計算像點的匹配點。
相機的平移距離相對于場景的深度較小的時候,也可以使用單應矩陣H。
在大家熟悉的ORB-SLAM中初始化的時候,就是單應矩陣和基礎矩陣同時估計,然后根據兩種方法估計出的結果計算重投影誤差,選擇重投影誤差最小的那個作為初始化結果。
1.2.2 建立模型
一個單應矩陣其實就是一個3X3的矩陣,通過這個矩陣,可以把圖像中的一個點,投影到對應的圖像對上去,對應的公式為
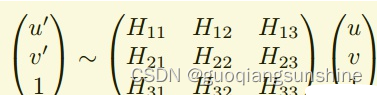
在這篇文章中,作者為了更好的訓練模型和評估算法效果,采用了另外一種模型,來等效代替上面的公式。我們知道,一張圖片進行單應性變換的時候,圖像上的點的坐標會根據變換矩陣發生變化(如上式),那么反過來,如果我知道n個變換前后的點的坐標,那么這兩張圖片之間的變換矩陣便可以得到,在平面關系中,n為4,即至少知道四個點就可以。因此作者用四個點對應的變化量來建立一個新的模型,如下式所示
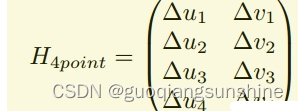
它和單應性矩陣具有一一對應的關系
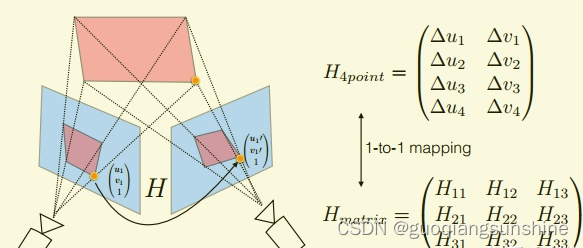
這樣做的好處是,把圖片對之間的矩陣關系,轉換成了點和點之間的關系,在進行精度評估時,可以直接根據轉換后的點的坐標與真實的坐標計算距離,作為誤差評估指標,而且,還可以用于網絡中損失函數的計算。
1.2.3 生成數據集
作者采用MS-COCO作為數據集,不過該數據集中沒有圖像對,也即沒有單應矩陣的真值,這是沒法進行訓練的。因此作者根據數據集中原有圖像,自動生成了圖像對。具體方法如下圖所示
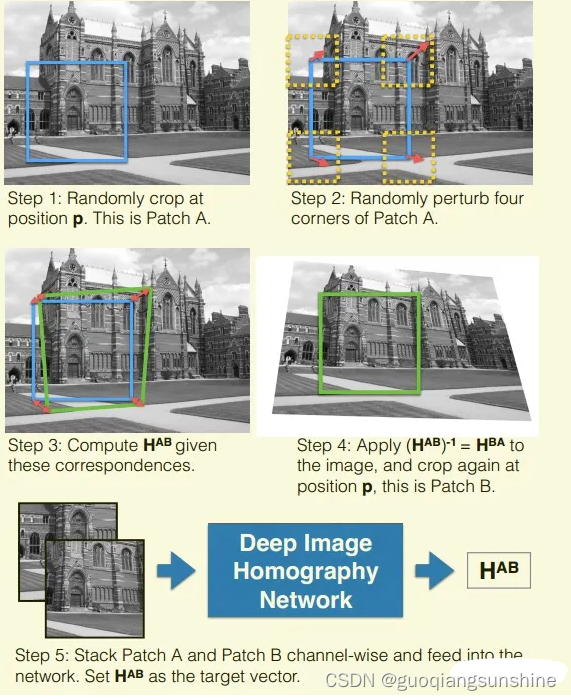
具體步驟為:
1.在圖像中選取一個長方形區域,區域就可以用上面說的四個點的模型來表示;
2.把區域的四個點隨機進行平移,這樣就得到一個四邊形,這兩個四邊形之間的單應矩陣也就是已知的;
3.把圖像按照這個單應矩陣進行變換,并選取被四邊形框住的區域;
4.這樣1)中和3)中得到的圖像就形成了一個已知真實單應矩陣的圖像對。
1.2.4 設計網絡結構
本文的網絡結構如下圖所示
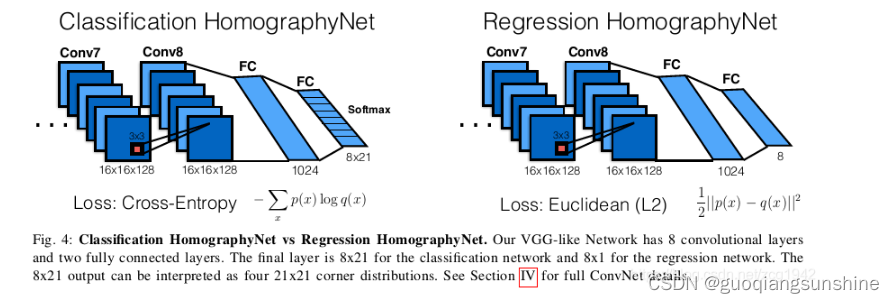
網絡分成兩部分,分別是Classification HomographyNet 和 Regression HomograhyNet,后者是直接輸出8個量,這8個量自然就是四個點各自的x和y坐標值。但這樣的缺點也很明顯,就是不知道每個坐標值的置信度是多少,比如在slam中設置方差時就沒有根據。因此Classification HomographyNet就是在Regression HomograhyNet的基礎上,把輸出端改成了8X21的輸出向量,這里的8仍然是四個點各自的x和y坐標,這里的21是每個坐標值的可能值之一,并且給出了該值的概率,這樣就可以定量分析置信度了。該網絡所輸出的置信度的可視化效果如下圖所示

1.2.5 實驗結果
實驗結果的精度評測方法就是根據每個點的坐標按照單應矩陣進行轉換后,和真實坐標進行L2距離測量,再把四個點的誤差值取平均得到。作者把網絡兩部分的輸出和ORB特征計算的結果分別進行了評測,對比結果如下:
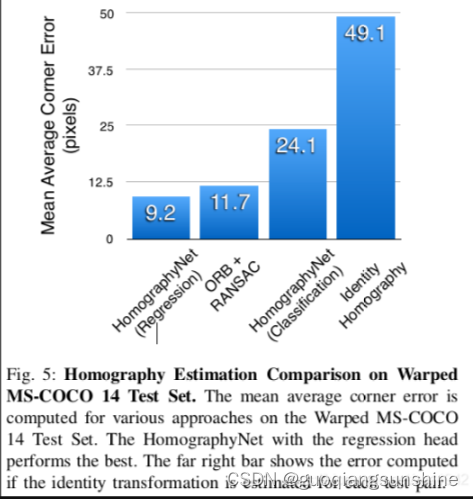
從這張表里看,并沒有比ORB表現出明顯的優勢,但是作者展示了幾張圖片,每個圖片里顯示了矯正之后的方框對,從方框對中可以明顯看出區別。左邊是ORB方法的,右邊是本文方法的。
1.3. 總結與思考
設計了一種端到端的單應矩陣的估計方法,采用提取定點的結構等效單應矩陣,基于這種結構設計了數據集產生方法和精度評測方法,最終的結果顯示效果要明顯高于ORB進行的提取。
可以看到回歸的方法效果最好,但是分類的方法可以得到置信度,且可以可視化地糾正實驗結果,在某些應用中是有優勢的。
作者總結了這個系統的兩個優勢:
第一,速度快,借助英偉達的泰坦顯卡,可以實現每秒處理300幀的圖像。
第二,將計算機視覺中最基礎的單應矩陣的估計問題轉化為機器學習的問題,可以針對應用情景如使用SLAM的室內導航機器人做特定優化。
事實上,單應矩陣在圖像拼接,ORB-SLAM算法和Augmented Reality(AR),相機標定中都有很重要的應用。這篇文章的三個作者都來自Magic Leap公司,一家做AR的公司,已經得到了Google和阿里巴巴等公司是十幾億美金的投資。
新的思考:
1)這種將深度學習用于解決傳統方法中遇到的困難的設計模式值的我們思考與學習,這樣可以充分的將誒和傳統與深度學習的共同特點。
2)這種從圖像中產生真值,然后在利用這些圖像去估計矩陣的方式是由于過擬合導致效果好?
3)單應矩陣一般特征共面時使用,論文中最后對比效果所列的圖片明顯不是這種情況(展示數據可以理解為遠視角場景),它之所以能對齊,是因為它用這個訓練的,而ORB是根據真實的場景估計的,沒有共面假設,對比實驗設計的合理性。
-
算法
+關注
關注
23文章
4601瀏覽量
92677 -
SLAM
+關注
關注
23文章
419瀏覽量
31789 -
深度學習
+關注
關注
73文章
5493瀏覽量
121000
原文標題:【SLAM】SuperPoint 語義 SLAM 深度學習用于特征提取
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于卷積神經網絡的雙重特征提取方法
模擬電路故障診斷中的特征提取方法
HOOFR-SLAM的系統框架及其特征提取
基于已知特征項和環境相關量的特征提取算法
故障特征提取的方法研究
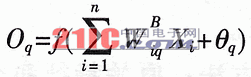
基于Gabor的特征提取算法在人臉識別中的應用
Curvelet變換用于人臉特征提取與識別

基于LBP的深度圖像手勢特征提取算法
基于主成分分析方向深度梯度直方圖的特征提取算法
基于HTM架構的時空特征提取方法
機器學習之特征提取 VS 特征選擇

計算機視覺中不同的特征提取方法對比

深度解析深度學習下的語義SLAM






 工商網監
工商網監
評論