") 云原生數(shù)據(jù)庫(kù)GaiaDB架構(gòu)設(shè)計(jì)解析
云原生數(shù)據(jù)庫(kù)GaiaDB架構(gòu)設(shè)計(jì)解析
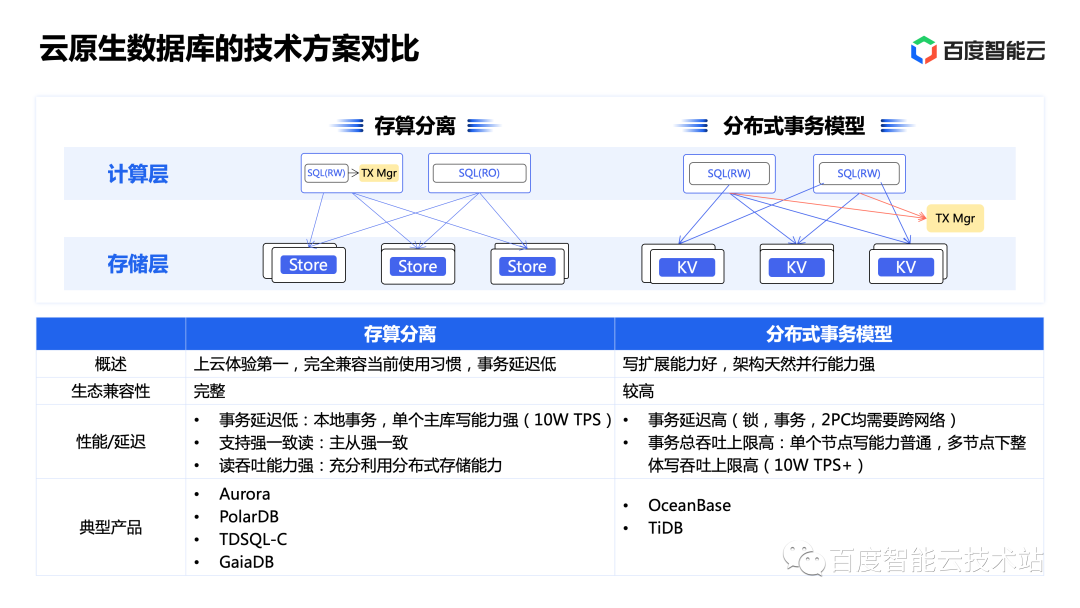
目前,云原生數(shù)據(jù)庫(kù)已經(jīng)被各行各業(yè)大規(guī)模投入到實(shí)際生產(chǎn)中,最終的目標(biāo)都是「單機(jī) + 分布式一體化」。但在演進(jìn)路線上,當(dāng)前主要有兩個(gè)略有不同的路徑。
一種是各大公有云廠商選擇的優(yōu)先保證上云兼容性的路線。它基于存算分離架構(gòu),對(duì)傳統(tǒng)數(shù)據(jù)庫(kù)進(jìn)行改造,典型產(chǎn)品有 AWS Aurora、阿里云 PolarDB、騰訊云 TDSQL-C、百度智能云 GaiaDB。
數(shù)據(jù)庫(kù)作為公有云上的核心基礎(chǔ)設(shè)施,第一要?jiǎng)?wù)是實(shí)現(xiàn)用戶(hù)上云的平滑性。目前像云網(wǎng)絡(luò)、云主機(jī),云盤(pán)都實(shí)現(xiàn)了完全透明兼容。云原生數(shù)據(jù)庫(kù)也必須實(shí)現(xiàn)從語(yǔ)法、使用習(xí)慣、再到生態(tài)上的全面兼容。因此,基于現(xiàn)有生態(tài)做分布式化改造成為了一條首選的演進(jìn)路線。使用存算分離路線的云原生數(shù)據(jù)庫(kù)可以完美兼容傳統(tǒng)的使用習(xí)慣,為交易類(lèi)場(chǎng)景提供低延遲的寫(xiě)事務(wù)能力,同時(shí)讀擴(kuò)展性與存儲(chǔ)擴(kuò)展性借助了分布式存儲(chǔ)的池化能力,也得到了很大增強(qiáng)。
另外一種路徑是先搭建一套分布式框架,然后在其中填充數(shù)據(jù)庫(kù)邏輯。OceanBase 和 TiDB 就是其中兩個(gè)比較典型的產(chǎn)品。它們將事務(wù)的子系統(tǒng)和鎖的子系統(tǒng)拆分為單獨(dú)的模塊。計(jì)算層通過(guò)與這些模塊交互,可讓多個(gè)節(jié)點(diǎn)均支持寫(xiě)請(qǐng)求。然后由統(tǒng)一的新事務(wù) + 鎖中心節(jié)點(diǎn)來(lái)進(jìn)行仲裁。這樣,對(duì)需要較多計(jì)算資源的寫(xiě)負(fù)載場(chǎng)景會(huì)有較好的提升。由于事務(wù)和鎖都需要跨網(wǎng)絡(luò)進(jìn)行交互,因此事務(wù)延遲相對(duì)較高,在鎖負(fù)載較重的情況下會(huì)成為一定的瓶頸。
目前這兩個(gè)路線并不是涇渭分明,獨(dú)立發(fā)展的,大家都在向著統(tǒng)一的目標(biāo)演進(jìn)。因此我們可以看到,存算分離路線在逐漸增強(qiáng) SQL 的多級(jí)并行能力,同時(shí)也在探索和支持多個(gè)寫(xiě)節(jié)點(diǎn)的庫(kù)表級(jí)/行級(jí)的多寫(xiě)能力。同時(shí)分布式事務(wù)路線也在積極探索在小數(shù)據(jù)規(guī)模下的單機(jī)部署架構(gòu)。
所以在未來(lái),這兩個(gè)路線會(huì)不斷融合。業(yè)務(wù)的數(shù)據(jù)規(guī)模不管多大,都可以平穩(wěn)快速地運(yùn)行在數(shù)據(jù)庫(kù)系統(tǒng)上,而不需要用戶(hù)去過(guò)分關(guān)注分區(qū)、索引、事務(wù)模型等信息。就像十年前如何在機(jī)器之間存儲(chǔ)海量小文件還是一個(gè)后端研發(fā)工程師的必修課,而隨著 S3 存儲(chǔ)的出現(xiàn),用戶(hù)再也不需要考慮如何通過(guò)哈希等方式來(lái)保證單個(gè)文件夾不會(huì)保存太多文件一樣。
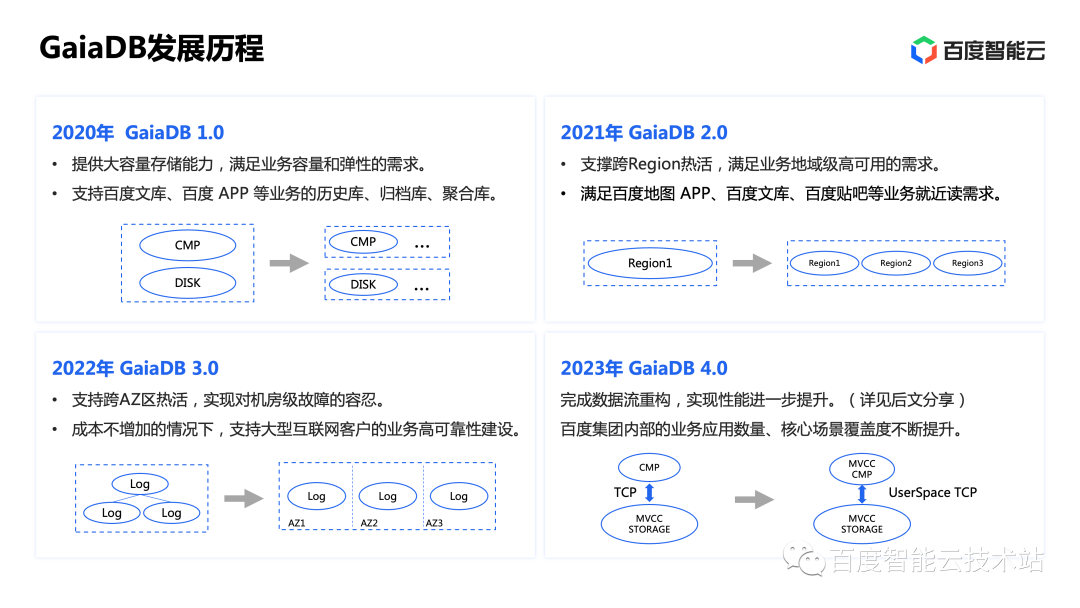
GaiaDB 是從百度智能云多年數(shù)據(jù)庫(kù)研發(fā)經(jīng)驗(yàn)積累中逐漸迭代而來(lái)。GaiaDB 于 2020 年發(fā)布首個(gè)版本,首次實(shí)現(xiàn)了基于存算分離的大容量存儲(chǔ)和快速?gòu)椥阅芰Γ鉀Q了百度內(nèi)部的歷史庫(kù)、歸檔庫(kù)等大容量存儲(chǔ)需求。
緊接著,為了滿(mǎn)足集團(tuán)內(nèi)大部分核心業(yè)務(wù)的跨地域熱活準(zhǔn)入門(mén)檻和就近讀性能需求,GaiaDB 于 2021 年發(fā)布了地域級(jí)熱活功能。跨地域熱活仍然使用存儲(chǔ)層同步的方案,同步延遲與吞吐都相較邏輯同步有很大提升,從地域可以實(shí)現(xiàn)與主地域接近相同的同步能力,不會(huì)成為拖慢整體系統(tǒng)的短板,也不會(huì)像邏輯同步那樣在大事務(wù)等場(chǎng)景下出現(xiàn)延遲飆升的問(wèn)題。
所以 2.0 版本上線后,GaiaDB 逐漸接入了手百、貼吧、文庫(kù)等多個(gè)核心產(chǎn)品線,解決了業(yè)務(wù)在跨地域場(chǎng)景下的延遲與性能痛點(diǎn)。
隨著業(yè)務(wù)的逐漸上云,多可用區(qū)高可用的需求慢慢凸顯,如何實(shí)現(xiàn)單機(jī)房故障不影響服務(wù)成為了很多業(yè)務(wù)上云的關(guān)注點(diǎn)。為此 GaiaDB 打造了可支持跨可用區(qū)熱活的 3.0 版本,每個(gè)可用區(qū)都可以實(shí)時(shí)提供服務(wù)并且不增加額外的存儲(chǔ)成本。而在今年, GaiaDB 推出了更加智能化的 4.0 架構(gòu),性能進(jìn)一步提升,功能完整度也在持續(xù)完成覆蓋。
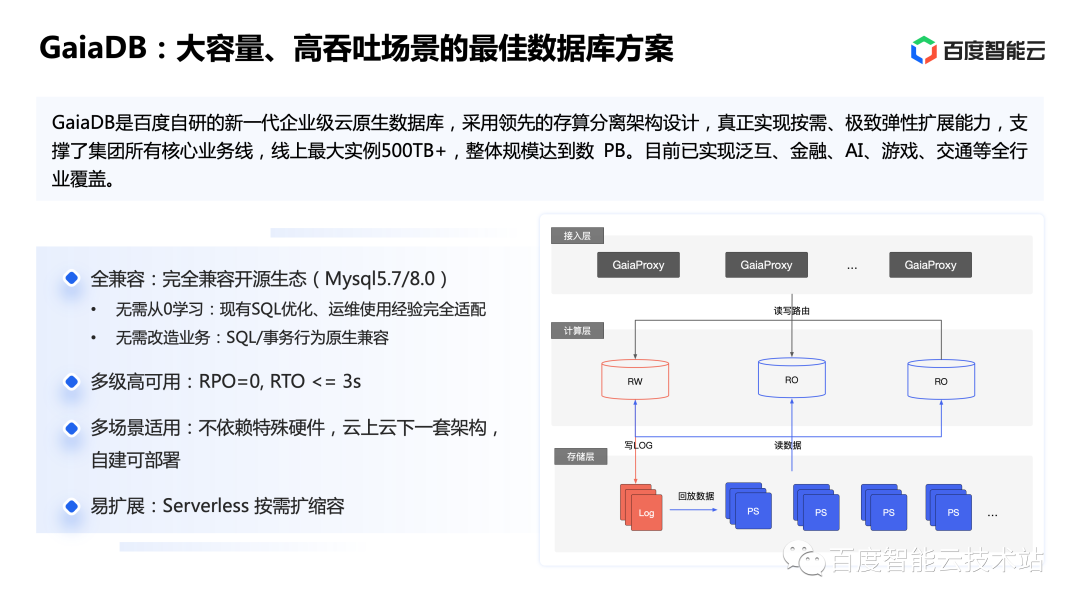
接下來(lái)整體介紹一下 GaiaDB。目前 GaiaDB 已經(jīng)實(shí)現(xiàn)了線上全行業(yè)場(chǎng)景覆蓋,最大實(shí)例達(dá)到了數(shù)百 TB,不僅兼容開(kāi)源生態(tài),還實(shí)現(xiàn)了 RPO=0 的高可靠能力。在成本方面,由于在架構(gòu)設(shè)計(jì)上采用了融合的技術(shù)理念,GaiaDB 不依賴(lài)特殊硬件和網(wǎng)絡(luò)環(huán)境也可以保證性能,實(shí)現(xiàn)云上云下一套架構(gòu)。
2 GaiaDB 的高性能&多級(jí)高可用設(shè)計(jì)
接下來(lái)我來(lái)分享一下 GaiaDB 的性能核心設(shè)計(jì)理念——通過(guò)融合和裁剪,將數(shù)據(jù)庫(kù)和分布式存儲(chǔ)進(jìn)行深度融合,為全鏈路的同步轉(zhuǎn)異步化提供條件,從而實(shí)現(xiàn)極致的性能與通用性。
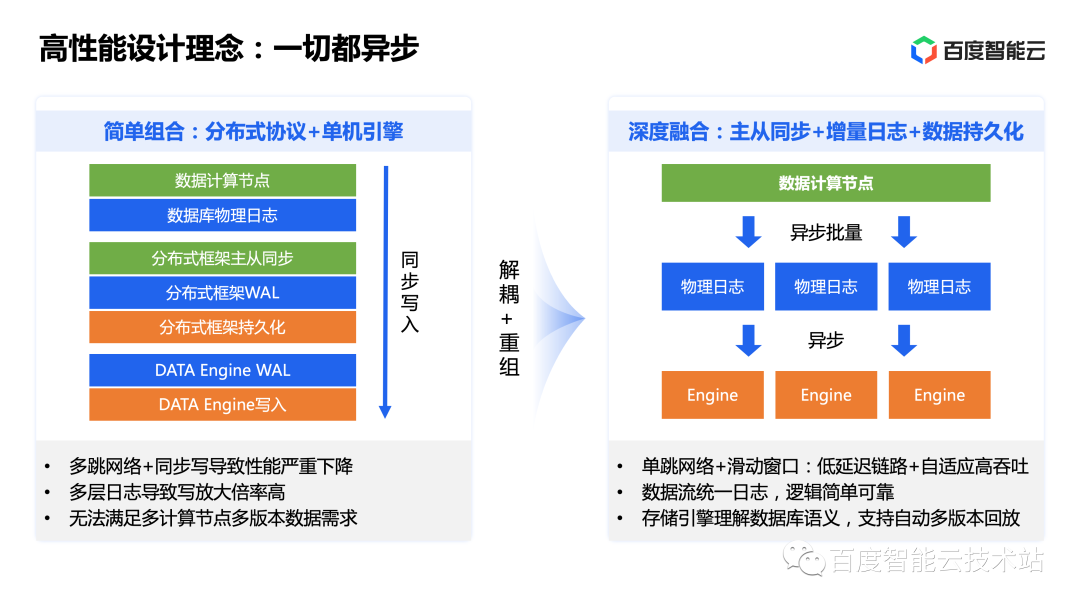
我們可以看到,如果數(shù)據(jù)庫(kù)簡(jiǎn)單使用通用分布式協(xié)議和單機(jī)存儲(chǔ)引擎,如左圖所示,那么數(shù)據(jù)庫(kù)需要處理主從同步,需要有 CrashSafe 所需要的物理日志。同時(shí),一致性協(xié)議也要有主從同步,要寫(xiě)自己的 WAL 以及持久化快照。而單機(jī)引擎同樣需要 CrashSafe 以及一套日志系統(tǒng)和數(shù)據(jù)存儲(chǔ)邏輯。
我們發(fā)現(xiàn),多層日志的嵌套帶來(lái)了層層延遲與寫(xiě)放大。更復(fù)雜的是,數(shù)據(jù)流中嵌套多層邏輯后,也給系統(tǒng)整體數(shù)據(jù)安全帶來(lái)了一定挑戰(zhàn)。同時(shí)由于多層之間需要串行等待,所以在加入了網(wǎng)絡(luò)延遲后會(huì)給數(shù)據(jù)庫(kù)帶來(lái)很大的性能下降。雖然可以使用定制化硬件與網(wǎng)絡(luò)來(lái)縮短網(wǎng)絡(luò)和磁盤(pán)落盤(pán)的延遲以降低鏈路耗時(shí),但這又引入了新的不確定性并導(dǎo)致了更高的成本。
GaiaDB 的解決思路是將事務(wù)和主從同步邏輯、日志邏輯、快照和存儲(chǔ)持久化邏輯重新組合和排布。
首先是將分布式協(xié)議的主從同步邏輯融合進(jìn)數(shù)據(jù)庫(kù)計(jì)算節(jié)點(diǎn)中。由于計(jì)算層本身就需要處理主從同步、事務(wù)和一致性問(wèn)題,相關(guān)的工作量增加并不大。這樣一來(lái),最直接的收益就是將兩跳網(wǎng)絡(luò)和 I/O 精簡(jiǎn)為一跳,直接降低了鏈路延遲。
其次 GaiaDB 將多層增量日志統(tǒng)一改為使用數(shù)據(jù)庫(kù) Redo 物理日志,由 LogService 日志服務(wù)統(tǒng)一負(fù)責(zé)其可用性與可靠性。
除此之外,GaiaDB 也將持久化、快照和數(shù)據(jù)庫(kù)回放功能融合入存儲(chǔ)節(jié)點(diǎn)。由于存儲(chǔ)層支持了數(shù)據(jù)庫(kù)回放能力,可以很輕松實(shí)現(xiàn)數(shù)據(jù)頁(yè)級(jí)別的 MVCC。這樣全鏈路只剩下了數(shù)據(jù)庫(kù)語(yǔ)義,數(shù)據(jù)流簡(jiǎn)單可靠,邏輯大大簡(jiǎn)化。
下面我們一起來(lái)看下共識(shí)模型上的改變。
像 Raft 協(xié)議是需要兩跳網(wǎng)絡(luò)才能實(shí)現(xiàn)一次提交確認(rèn)的,右上角就是 Raft 的數(shù)據(jù)流架構(gòu):CN 節(jié)點(diǎn)將寫(xiě)發(fā)送給 Leader 后,需要等待 Leader 發(fā)送給 Follower 并至少收到一個(gè)返回后才能成功。
這里就帶來(lái)了兩跳網(wǎng)絡(luò)和 I/O 的同步等待問(wèn)題。而 GaiaDB 則是計(jì)算節(jié)點(diǎn)直接發(fā)送給多個(gè) Log 服務(wù)并等待多數(shù)派返回,這樣不依賴(lài)任何特殊硬件與網(wǎng)絡(luò)就降低了延遲。這樣系統(tǒng)里不管是事務(wù)的一致性還是多副本一致性,統(tǒng)一由計(jì)算節(jié)點(diǎn)統(tǒng)籌維護(hù),所有的增量日志也統(tǒng)一為數(shù)據(jù)庫(kù)物理日志,整體數(shù)據(jù)流簡(jiǎn)單可控。
對(duì)于數(shù)據(jù)風(fēng)險(xiǎn)最高的 Crash Recovery 場(chǎng)景,由于統(tǒng)一使用了數(shù)據(jù)庫(kù)語(yǔ)義,整體流程更加健壯,數(shù)據(jù)可靠性更高,降低了數(shù)據(jù)在多種日志邏輯之間轉(zhuǎn)換和同步帶來(lái)的復(fù)雜度風(fēng)險(xiǎn)。而在性能方面,由于存儲(chǔ)層自身具備回放能力,可以充分利用 LogService 層的日志緩存能力。對(duì)于寫(xiě)操作來(lái)說(shuō),不需要每次更改都刷盤(pán),可以批次回放刷盤(pán),大大節(jié)省了磁盤(pán)吞吐與 I/O。
經(jīng)過(guò)以上改造,線上吞吐性能可以提升 40% 。同時(shí)由于鏈路簡(jiǎn)化,也大大優(yōu)化了長(zhǎng)尾延遲。像之前計(jì)算節(jié)點(diǎn)與分布式主節(jié)點(diǎn)之間發(fā)生網(wǎng)絡(luò)抖動(dòng)的場(chǎng)景,就會(huì)被多數(shù)派的返回特性來(lái)優(yōu)化。

分享完一致性協(xié)議層優(yōu)化,接下來(lái)我們來(lái)探討一下鏈路層優(yōu)化。
我們知道,總吞吐與并發(fā)度成正比,與延遲成反比。一致性協(xié)議層改造并縮短了數(shù)據(jù)鏈路,可以通過(guò)降低延遲來(lái)增加吞吐。那么有沒(méi)有辦法通過(guò)提升數(shù)據(jù)流的并發(fā)度來(lái)提升吞吐呢?答案是可以。由于數(shù)據(jù)庫(kù)的物理日志自帶版本號(hào)與數(shù)據(jù)長(zhǎng)度,所以不需要像通用存儲(chǔ)一樣實(shí)現(xiàn)塊級(jí)別串行提交。之所以使用通用存儲(chǔ)需要串行提交,是因?yàn)榇鎯?chǔ)端只能根據(jù)請(qǐng)求到達(dá)的先后確定數(shù)據(jù)版本,如果亂序到達(dá),最后生效的版本是不可知的。
而對(duì)于 GaiaDB 來(lái)說(shuō),由于 LogService 具備數(shù)據(jù)庫(kù)語(yǔ)義的識(shí)別功能,所以計(jì)算節(jié)點(diǎn)只需要異步進(jìn)行寫(xiě)入,日志服務(wù)就會(huì)自動(dòng)根據(jù)數(shù)據(jù)版本選取最新數(shù)據(jù),然后根據(jù)寫(xiě)入情況批量返回成功,這樣鏈路就可以實(shí)現(xiàn)延遲與吞吐的解耦。
當(dāng)然計(jì)算層依然會(huì)等待日志層批量返回的最新落盤(pán)版本后再返回事務(wù)提交成功,所以依然可以滿(mǎn)足提交成功的事務(wù)一致性、持久化的要求。
另外針對(duì)高負(fù)載下 I/O 請(qǐng)求與數(shù)據(jù)庫(kù)業(yè)務(wù)請(qǐng)求爭(zhēng)搶 CPU 的問(wèn)題,我們使用了 I/O 線程隔離技術(shù),通過(guò)資源隔離的方式,將 I/O 線程與數(shù)據(jù)庫(kù)業(yè)務(wù)線程進(jìn)行隔離。這樣即使在復(fù)雜負(fù)載場(chǎng)景下,I/O 延遲仍可以保持在較低水平。

在分析完前面兩部分之后,可能會(huì)有同學(xué)有疑問(wèn):既然日志層到存儲(chǔ)層不是同步寫(xiě),是不是最終系統(tǒng)的一致性降低了?有沒(méi)有可能發(fā)生數(shù)據(jù)丟失或不一致的問(wèn)題呢?答案是不會(huì)。因?yàn)?GaiaDB 的存儲(chǔ)是一套支持 MVCC 的多版本系統(tǒng)。所以即使回放實(shí)現(xiàn)上是異步,但是由于請(qǐng)求方會(huì)提供所需要的數(shù)據(jù)版本,存儲(chǔ)層可以提供對(duì)應(yīng)版本的強(qiáng)一致數(shù)據(jù)視圖。
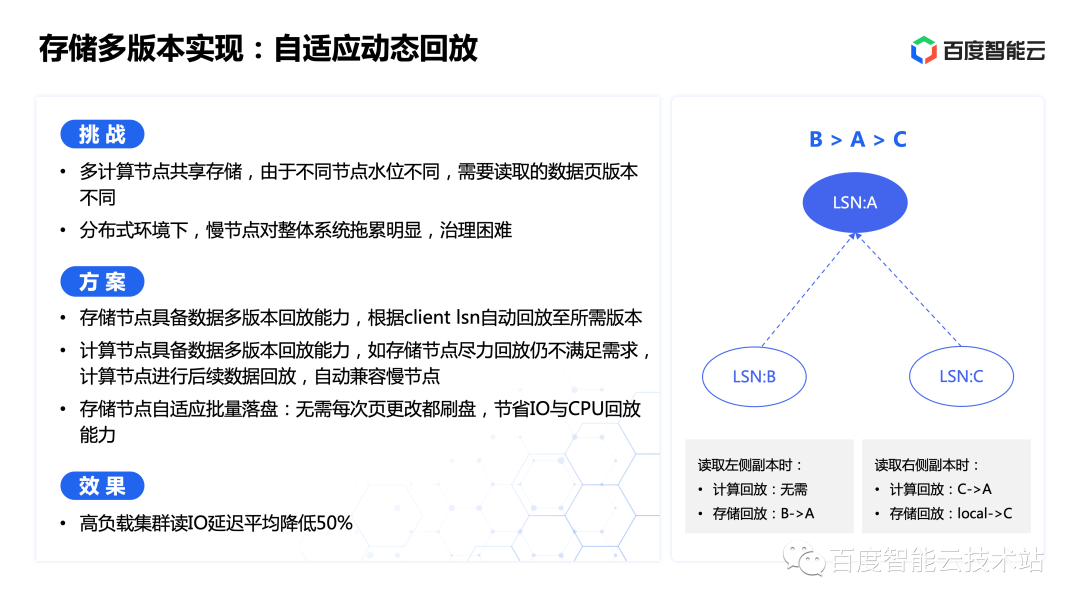
GaiaDB 的存儲(chǔ)節(jié)點(diǎn)支持?jǐn)?shù)據(jù)頁(yè)的回放功能,可以動(dòng)態(tài)回放至任意目標(biāo)版本后再返回,在之前的版本里,假如由于異步的因素還沒(méi)有獲取到這部分增量日志,存儲(chǔ)節(jié)點(diǎn)也會(huì)啟用優(yōu)先拉取的策略實(shí)時(shí)拉取一次日志后再回放,以此來(lái)提供較好的時(shí)效性。而在最新的 GaiaDB 版本中,我們也在計(jì)算層添加了同樣的回放能力,存儲(chǔ)節(jié)點(diǎn)盡力回放后仍不滿(mǎn)足需求的,由計(jì)算節(jié)點(diǎn)進(jìn)行剩余任務(wù)。
這樣對(duì)于存儲(chǔ)慢節(jié)點(diǎn)的兼容能力就大大增強(qiáng)了,同時(shí)由于存儲(chǔ)節(jié)點(diǎn)會(huì)盡力回放,所以也可以最大化利用存儲(chǔ)層的算力資源。對(duì)于刷臟邏輯目前也完全下沉到了存儲(chǔ)層,存儲(chǔ)節(jié)點(diǎn)可以自主控制刷盤(pán)策略和時(shí)機(jī),盡量合并多次寫(xiě)后再進(jìn)行落盤(pán),大大節(jié)省了磁盤(pán) I/O 負(fù)載,平均 I/O 延遲降低了 50%。
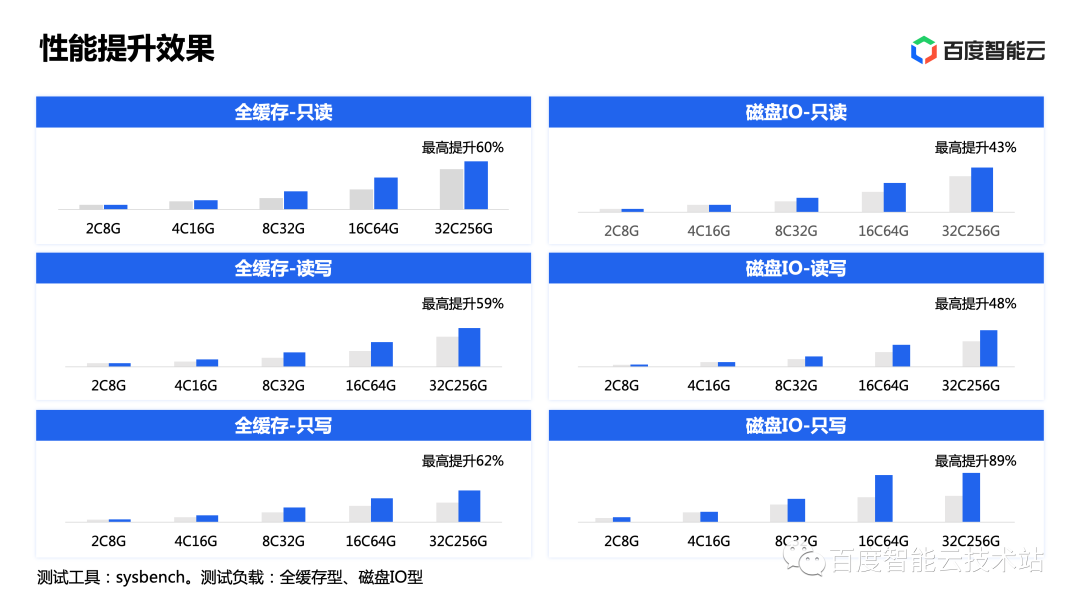
下圖中我們可以看到,在綜合了多項(xiàng)優(yōu)化后,讀寫(xiě)性能實(shí)現(xiàn)了最高 89% 的提升,其中寫(xiě)鏈路線路提升尤其明顯。這些都是在使用普通存儲(chǔ)介質(zhì)和網(wǎng)絡(luò)環(huán)境的情況下測(cè)試得出的,主要得益于數(shù)據(jù)鏈路的縮短與同步轉(zhuǎn)異步的自適應(yīng)高吞吐能力。
在討論完性能后,再分享一下 GaiaDB 在高可用方面的思考和設(shè)計(jì)理念。
數(shù)據(jù)庫(kù)作為底層數(shù)據(jù)存儲(chǔ)環(huán)節(jié),其可用性與可靠性直接影響系統(tǒng)整體。而線上情況是復(fù)雜多變的,機(jī)房里時(shí)時(shí)刻刻都可能有異常情況發(fā)生,小到單路電源故障,大到機(jī)房級(jí)網(wǎng)絡(luò)異常,無(wú)時(shí)無(wú)刻不在給數(shù)據(jù)造成可用性隱患。
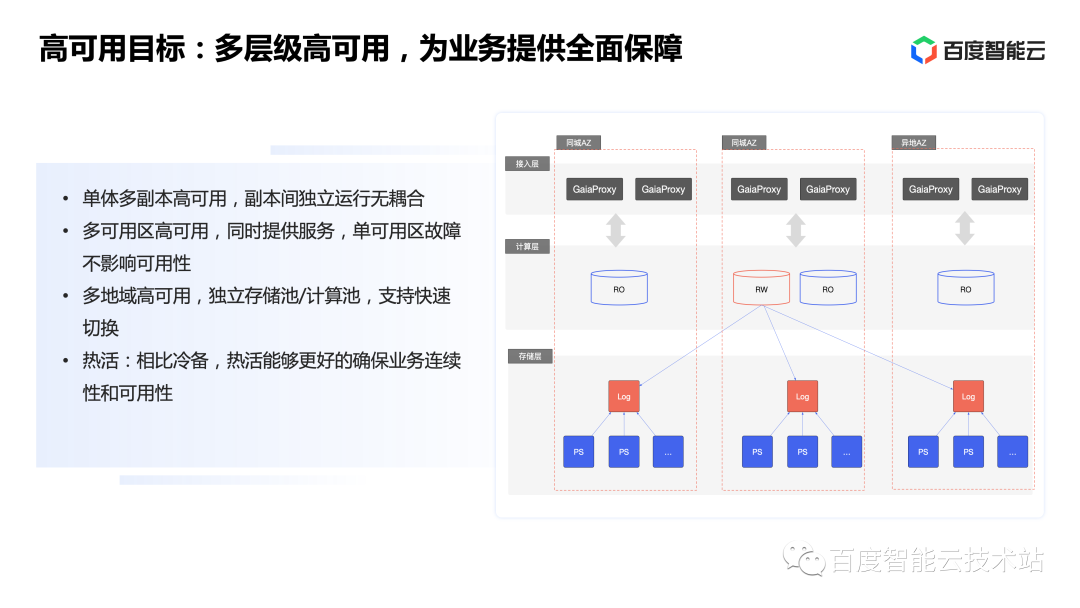
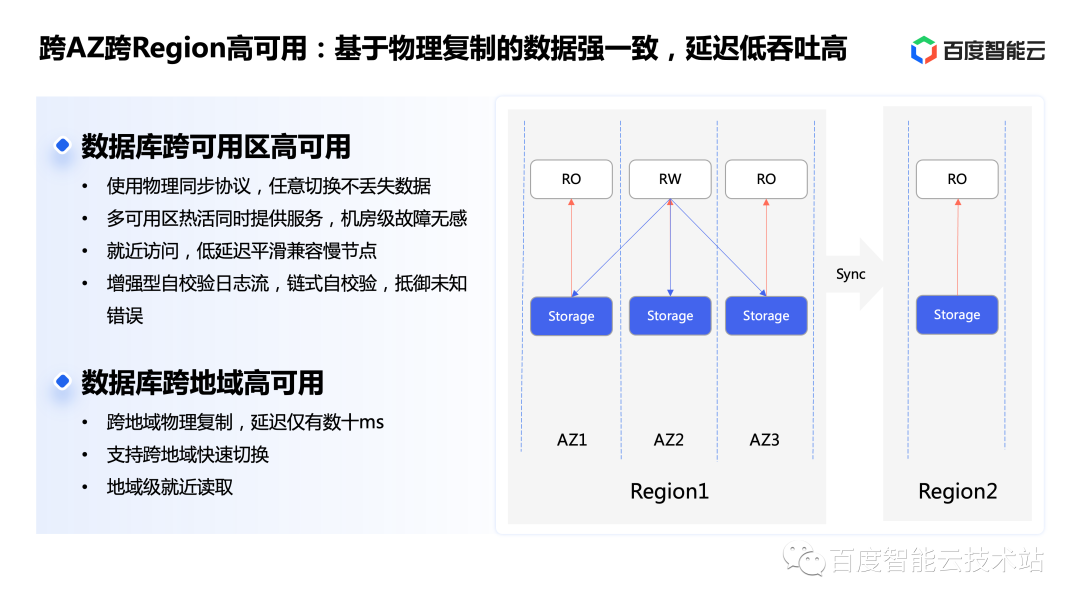
作為商業(yè)數(shù)據(jù)庫(kù),具備多級(jí)高可用能力是最核心的必備能力。這樣才能抵御不同級(jí)別的異常情況,有力保障客戶(hù)業(yè)務(wù)的平穩(wěn)運(yùn)行。GaiaDB 支持多副本、跨可用區(qū)、跨地域三級(jí)別高可用,創(chuàng)新性地實(shí)現(xiàn)了多可用區(qū)熱活高可用、單個(gè)實(shí)例支持跨可用區(qū)部署。在不增加成本的情況下,每個(gè)可用區(qū)均可提供在線服務(wù),任何可用區(qū)故障都不會(huì)打破存儲(chǔ)一致性。下面我們來(lái)分別看一下每個(gè)級(jí)別高可用能力的實(shí)現(xiàn)。
首先是實(shí)例的多副本高可用能力。
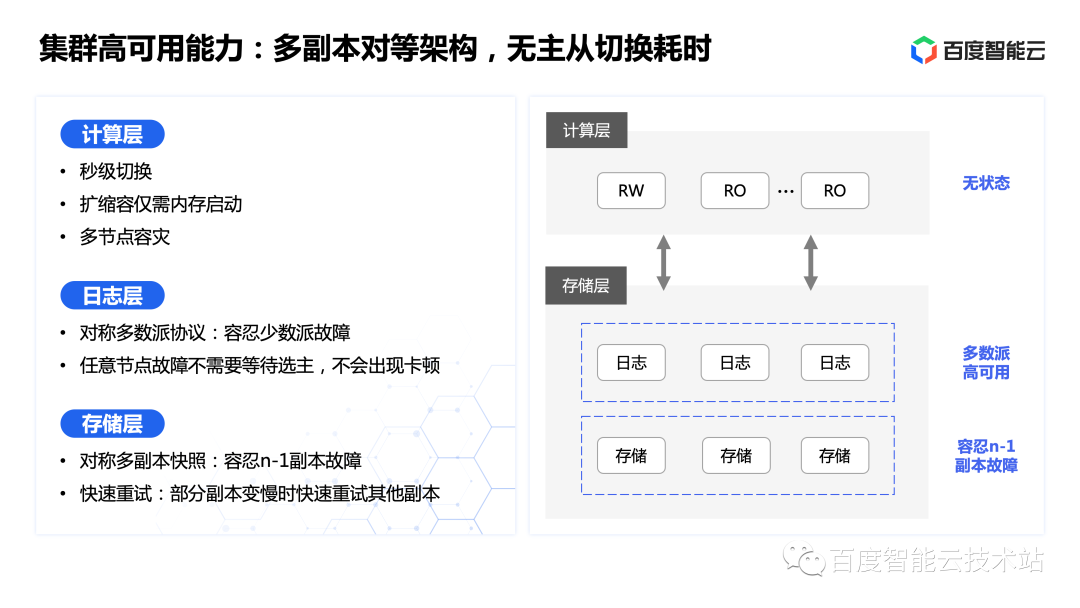
GaiaDB 對(duì)整體的分布式架構(gòu)進(jìn)行了重新設(shè)計(jì),系統(tǒng)共分為三層,即計(jì)算層、日志層、存儲(chǔ)層。
其中計(jì)算層本身無(wú)狀態(tài),僅負(fù)責(zé)事務(wù)處理與一致性維護(hù),所以獲得了很強(qiáng)的彈性能力,實(shí)現(xiàn)了秒級(jí)切換、多節(jié)點(diǎn)容災(zāi),同時(shí)擴(kuò)縮容只需要內(nèi)存啟動(dòng)即可。
日志層負(fù)責(zé)系統(tǒng)增量日志部分的持久化,實(shí)現(xiàn)了多數(shù)派高可用。同時(shí)由于一致性協(xié)調(diào)角色上移到了計(jì)算層,所以該層全對(duì)稱(chēng),任意節(jié)點(diǎn)故障不需要進(jìn)行等待選主,也不會(huì)有重新選主帶來(lái)的風(fēng)暴和業(yè)務(wù)中斷問(wèn)題。
再往下是存儲(chǔ)層,負(fù)責(zé)數(shù)據(jù)頁(yè)本身持久化與更新。由于上層保留了增量日志,所以存儲(chǔ)層可以容忍 n-1 副本故障。簡(jiǎn)單來(lái)說(shuō)就是只要有一個(gè)副本完好,加上上層提供的增量日志,即可回放出所有版本的完整數(shù)據(jù),實(shí)現(xiàn)了相比傳統(tǒng)多數(shù)派協(xié)議更高的可靠性能力。
其次是跨可用區(qū)與跨地域的高可用能力。
GaiaDB 的多級(jí)高可用都是基于存儲(chǔ)層物理日志的直接復(fù)制。相比邏輯復(fù)制,數(shù)據(jù)鏈路大大縮短,同步延遲也不再受上層大事務(wù)或者 DDL 等操作影響,在主從同步延遲上具有很大優(yōu)勢(shì)。
對(duì)于跨可用區(qū)高可用來(lái)說(shuō),由于 GaiaDB 具有對(duì)稱(chēng)部署架構(gòu),所以可以很方便地進(jìn)行跨可用區(qū)部署。這樣可以在不增加存儲(chǔ)成本的情況下實(shí)現(xiàn)多可用區(qū)熱活,任一可用區(qū)故障都不影響數(shù)據(jù)可靠性。
寫(xiě)數(shù)據(jù)流可以自適應(yīng)只跨一跳最短的機(jī)房間網(wǎng)絡(luò),不需要擔(dān)心分布式主節(jié)點(diǎn)不在同機(jī)房帶來(lái)的兩跳跨機(jī)房網(wǎng)絡(luò)和跨遠(yuǎn)端機(jī)房問(wèn)題,而讀依然是就近讀取,提供與單機(jī)房部署接近的延遲體驗(yàn)。由于跨機(jī)房傳輸?shù)木W(wǎng)絡(luò)環(huán)境更為復(fù)雜,GaiaDB 添加了數(shù)據(jù)流的鏈?zhǔn)阶孕r?yàn)機(jī)制,使數(shù)據(jù)錯(cuò)誤可以主動(dòng)被發(fā)現(xiàn),保障了復(fù)雜網(wǎng)絡(luò)環(huán)境下的數(shù)據(jù)可靠性。
對(duì)于跨地域高可用來(lái)說(shuō),由于同樣使用了異步并行加速的物理同步,及時(shí)在長(zhǎng)距離傳輸上,吞吐依然可以追齊主集群,不會(huì)成為吞吐瓶頸,在計(jì)入網(wǎng)絡(luò)延遲的情況下,國(guó)內(nèi)可以實(shí)現(xiàn)數(shù)十毫秒的同步延遲,這是因?yàn)榭绲赜蛲瑯涌梢允褂卯惒讲⑿袑?xiě)加速,自動(dòng)適應(yīng)延遲和吞吐之間的關(guān)系。同時(shí)地域之間還可以實(shí)現(xiàn)主動(dòng)快速切換和默認(rèn)就近讀取。
所以在使用了 GaiaDB 的情況下,業(yè)務(wù)可以不做復(fù)雜的數(shù)據(jù)同步邏輯就可以實(shí)現(xiàn)低成本的跨可用區(qū)與跨地域高可用。
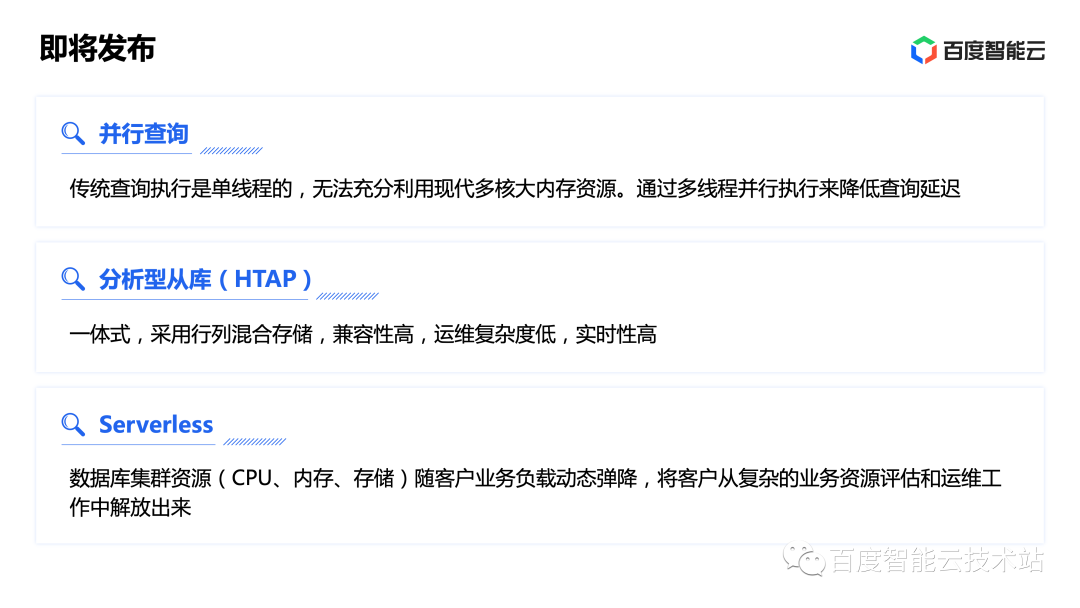
介紹完高性能和高可用兩部分的設(shè)計(jì)理念后,接下來(lái)再介紹一下我們正在內(nèi)部灰度中的新功能:
并行查詢(xún):并行查詢(xún)從并發(fā)度上進(jìn)行加速的并行查詢(xún)能力,這對(duì)大數(shù)據(jù)規(guī)模下的多行查詢(xún)有非常好的加速作用,可以充分利用計(jì)算節(jié)點(diǎn)的 CPU 和內(nèi)存資源和分布式存儲(chǔ)層的并行 I/O 能力。
分析型從庫(kù)(HTAP):分析型從庫(kù)具備多種行列加速能力,既有支持百 TB 級(jí)別數(shù)據(jù)計(jì)算的分析型節(jié)點(diǎn)解決方案,也有支持百萬(wàn)行以上檢索加速的列式索引引擎。其中列式索引引擎同樣采用物理日志同步,不需要業(yè)務(wù)維護(hù)數(shù)據(jù)一致性,可以和當(dāng)前交易類(lèi)負(fù)載的事務(wù)隔離級(jí)別兼容。
Serverless:我們也在探索充分利用內(nèi)部潮汐算力的資源優(yōu)化調(diào)度方案,在白天業(yè)務(wù)高峰期,將資源向?qū)崟r(shí)性更強(qiáng)的交易類(lèi)業(yè)務(wù)傾斜,在低峰期自動(dòng)縮容,將資源復(fù)用投入到離線計(jì)算類(lèi)業(yè)務(wù)中,不但客戶(hù)節(jié)省了運(yùn)維成本與資源成本,也避免了資源閑置和浪費(fèi),實(shí)現(xiàn)了更高的資源利用率。
以上功能預(yù)計(jì)都會(huì)在近期開(kāi)放灰度試用。
審核編輯:劉清
-
cpu
+關(guān)注
關(guān)注
68文章
10641瀏覽量
208722 -
DDL
+關(guān)注
關(guān)注
0文章
12瀏覽量
6308 -
AWS
+關(guān)注
關(guān)注
0文章
415瀏覽量
24143 -
百度智能云
+關(guān)注
關(guān)注
0文章
47瀏覽量
1867
原文標(biāo)題:高性能和多級(jí)高可用,云原生數(shù)據(jù)庫(kù) GaiaDB 架構(gòu)設(shè)計(jì)解析
文章出處:【微信號(hào):AI前線,微信公眾號(hào):AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
京東云原生安全產(chǎn)品重磅發(fā)布
從積木式到裝配式云原生安全
華為云多模數(shù)據(jù)庫(kù) GeminiDB 架構(gòu)與應(yīng)用實(shí)踐直播問(wèn)答實(shí)錄
華為云原生多模數(shù)據(jù)庫(kù) GeminiDB 架構(gòu)與應(yīng)用實(shí)踐

米哈游大數(shù)據(jù)云原生實(shí)踐

云原生數(shù)據(jù)庫(kù)GaiaDB架構(gòu)設(shè)計(jì)解析

誠(chéng)邀報(bào)名 | AI 向量、云原生、開(kāi)源,今年的數(shù)據(jù)庫(kù)熱點(diǎn)技術(shù)都在這里

誠(chéng)邀報(bào)名 | AI 向量、云原生、開(kāi)源,今年的數(shù)據(jù)庫(kù)熱點(diǎn)技術(shù)都在這里
什么是JSON數(shù)據(jù)庫(kù)

NoSQL 數(shù)據(jù)庫(kù)如何選型
MySQL數(shù)據(jù)庫(kù)基礎(chǔ)知識(shí)
什么是NoSQL?NoSQL數(shù)據(jù)庫(kù)的使用場(chǎng)景和架構(gòu)介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論