 誰說MySQL單表行數不要超過2000W?
誰說MySQL單表行數不要超過2000W?
背景
網上看了一篇文章《為什么說MySQL單表行數不要超過2000w》,親自實踐了一下,跟原作者有不同的結論。原文的結論是2000W左右性能會成指數級的下降,而我的結論是:隨著數據量成倍地增加,查詢的時間也剛好是成倍增加,是成正比的。
我并不會直接搬運網上的文章和結論,下邊的實踐過程是參考文章的實踐方式進行優化的。原文的理論感覺是正確的,但為啥我實踐的結果不支持他的理論?動手能力強的小伙伴,可以照的我的實踐過程試試。
前置條件
查看sql語句執行時間和效率
showprofiles;#是mysql提供可以用來分析當前會話中語句執行的資源消耗情況。可以用來SQL的調優測量。 select@@have_profiling;#查看是否支持profiling setprofiling=1;#設置MySQL支持profile selectcount(*)fromtmp.person;#執行自己的sql語句; showprofiles;就可以查到sql語句的執行時間;
效果如下
mysql>setprofiling=1; QueryOK,0rowsaffected,1warning(0.00sec) mysql>selectcount(*)fromtmp.person; +----------+ |count(*)| +----------+ |2| +----------+ 1rowinset(0.00sec) mysql>showprofiles; +----------+------------+---------------------------------+ |Query_ID|Duration|Query| +----------+------------+---------------------------------+ |1|0.00017775|selectcount(*)fromtmp.person| +----------+------------+---------------------------------+ 1rowinset,1warning(0.00sec)
實驗
建一張表
dropdatabaseifexiststmp; createdatabasetmp; usetmp; CREATETABLEperson( idintNOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主鍵', person_idtinyintnotnullcomment'用戶id', person_nameVARCHAR(200)comment'用戶名稱', gmt_createdatetimecomment'創建時間', gmt_modifieddatetimecomment'修改時間' )comment'人員信息表';
插入一條數據
insertintopersonvalues(1,1,'user_1',NOW(),now());
利用 mysql 偽列 rownum 設置偽列起始點為 1
select(@i:=@i+1)asrownum,person_namefromperson,(select@i:=100)asinit; set@i=1;
運行下面的 sql,連續執行 20 次,就是 2 的 20 次方約等于 100w 的數據;執行 23 次就是 2 的 23 次方約等于 800w , 如此下去即可實現千萬測試數據的插入,如果不想翻倍翻倍的增加數據,而是想少量,少量的增加,有個技巧,就是在 SQL 的后面增加limit條件,如limit 100控制將要新增的數據量。
insertintoperson(id,person_id,person_name,gmt_create,gmt_modified)
select@i:=@i+1,
left(rand()*10,10)asperson_id,
concat('user_',@i%2048),
date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND),
date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND)
fromperson;
此處需要注意的是,也許你在執行到近 800w 或者 1000w 數據的時候,會報錯:The total number of locks exceeds the lock table size,這是由于你的臨時表內存設置的不夠大,只需要擴大一下設置參數即可。
SETGLOBALtmp_table_size=512*1024*1024;#(512M) SETglobalinnodb_buffer_pool_size=1*1024*1024*1024;#(1G);
驗證
selectcount(1)fromperson; selectcount(1)frompersonwhereperson_id=6; showprofiles;
優化測試
MySQL函數
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (youmightwant to use the less safe log_bin_trust_function_creators variable)
這是因為mysql 默認不允許創建自定義函數(安全性的考慮),此時我們需要將參數 log_bin_trust_function_creators 設置為開啟狀態
showvariableslike'log_bin_trust_function_creators';
setgloballog_bin_trust_function_creators=1;
但這樣只是臨時設置,重啟終端后該設置即會失效。如果要配置永久的,需要在配置文件的 [mysqld] 上配置以下屬性: log_bin_trust_function_creators=1
--隨機產生字符串 dropfunctionifexistsrand_string;--先判斷是否已存在同名函數,如果已存在則先刪除 DELIMITER$$--兩個$$表示結束 createfunctionrand_string(nint)returnsvarchar(255) begin declarechars_strvarchar(100)default'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; declarereturn_strvarchar(255)default''; declareiintdefault0; whilei--隨機生成編號 dropfunctionifexistsrand_num; DELIMITER$$ createfunctionrand_num() returnsint(5) begin declareiintdefault0; seti=floor(100+rand()*10); returni; end$$ DELIMITER;
自定義函數的調用和其他普通函數的調用一樣,示例如下:
selectrand_string(5); selectrand_num();
一鍵測試
dropdatabaseifexiststmp; createdatabasetmp; usetmp; CREATETABLEperson( idintNOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主鍵', person_idtinyintnotnullcomment'用戶id', person_nameVARCHAR(200)comment'用戶名稱', gmt_createdatetimecomment'創建時間', gmt_modifieddatetimecomment'修改時間' )comment'userinfo'; SET@@profiling=0; SET@@profiling_history_size=0; SET@@profiling_history_size=100; SET@@profiling=1; insertintopersonvalues(1,1,'user_1',NOW(),now()); showprofiles; set@i=1; dropfunctionifexiststest_performance; DELIMITER$$#設置結束符 createfunctiontest_performance(numint)returnsvarchar(255) begin declarereturn_strvarchar(255)default''; if(num>0)then insertintoperson(id,person_id,person_name,gmt_create,gmt_modified) select@i:=@i+1, left(rand()*10,10)asperson_id, concat('user_',@i%2048), date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND), date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND) frompersonlimitnum; else insertintoperson(id,person_id,person_name,gmt_create,gmt_modified) select@i:=@i+1, left(rand()*10,10)asperson_id, concat('user_',@i%2048), date_add(gmt_create,interval+@i*cast(rand()*100assigned)SECOND), date_add(date_add(gmt_modified,interval+@i*cast(rand()*100assigned)SECOND),interval+cast(rand()*1000000assigned)SECOND) fromperson; endif; selectcount(1)intoreturn_strfrompersonwhereperson_id="9"; selectcount(1)intoreturn_strfromperson; returnreturn_str; end$$ DELIMITER; selecttest_performance(0);#2^1 selecttest_performance(0);#2^2 selecttest_performance(0);#2^3 selecttest_performance(0);#2^4 selecttest_performance(0);#2^5 selecttest_performance(0);#2^6 selecttest_performance(0);#2^7 selecttest_performance(0);#2^8 selecttest_performance(0);#2^9 selecttest_performance(0);#2^10 selecttest_performance(0);#2^11 selecttest_performance(0);#2^12 selecttest_performance(0);#2^13 selecttest_performance(0);#2^14 selecttest_performance(0);#2^15 selecttest_performance(0);#2^16 selecttest_performance(0);#2^17 selecttest_performance(0);#2^18 selecttest_performance(0);#2^19次方=524288 selecttest_performance(475712);#補上475712湊夠100w selecttest_performance(250000);#125w selecttest_performance(0);#250w selecttest_performance(0);#500w selecttest_performance(0);#1kw selecttest_performance(0);#2kw selecttest_performance(0);#4kw selecttest_performance(0);#8kw selecttest_performance(0);#16kw selecttest_performance(0);#32kw
實驗結果
| 數據量 | 有查詢條件 | 無查詢條件 |
| 125w | 0.1309075 | 0.08538975 |
| 250w | 0.25213025 | 0.18290725 |
| 500w | 0.4816255 | 0.35839375 |
| 1kw | 0.94493875 | 0.6809015 |
| 2kw | 1.878788 | 1.44631675 |
| 4kw | 5.40815725 | 3.05356825 |
| 8kw | 11.074242 | 6.6517985 |
| 16kw | 22.753852 | 17.94861325 |
| 2kw | 46.36041225 | 36.5971315 |
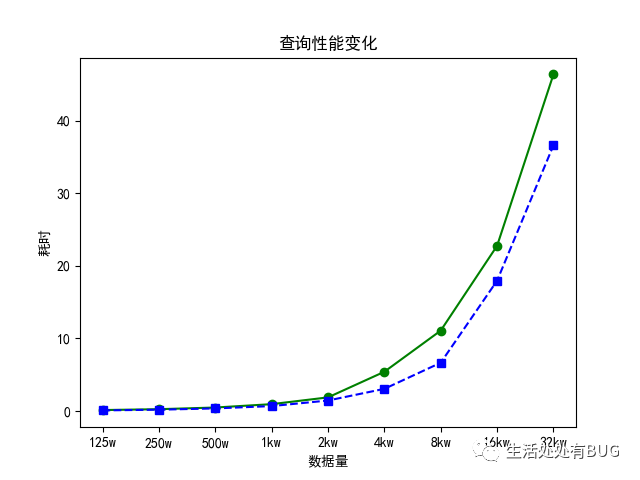 Figure_1
Figure_1
理論
單表數量限制
首先我們先想想數據庫單表行數最大多大?
CREATETABLEperson( idint(10)NOTNULLAUTO_INCREMENTPRIMARYKEYcomment'主鍵', person_idtinyintnotnullcomment'用戶id', person_nameVARCHAR(200)comment'用戶名稱', gmt_createdatetimecomment'創建時間', gmt_modifieddatetimecomment'修改時間' )comment'人員信息表';
看看上面的建表 sql,id 是主鍵,本身就是唯一的,也就是說主鍵的大小可以限制表的上限,如果主鍵聲明 int 大小,也就是 32 位,那么支持 2^32-1 ~~21 億;如果是 bigint,那就是 2^62-1 ?(36893488147419103232),難以想象這個的多大了,一般還沒有到這個限制之前,可能數據庫已經爆滿了!!
有人統計過,如果建表的時候,自增字段選擇無符號的 bigint , 那么自增長最大值是 18446744073709551615,按照一秒新增一條記錄的速度,大約什么時候能用完?
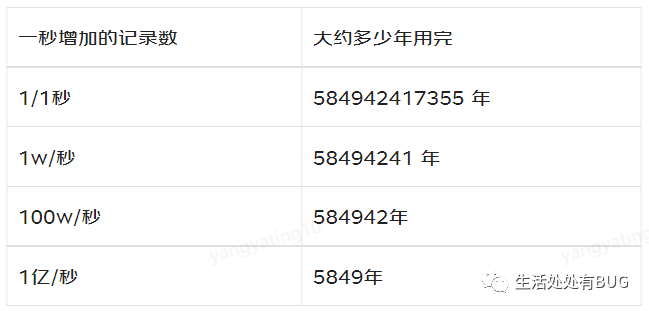 圖片
圖片
表空間
下面我們再來看看索引的結構,對了,我們下面講內容都是基于 Innodb 引擎的,大家都知道 Innodb 的索引內部用的是 B+ 樹
圖片
這張表數據,在硬盤上存儲也是類似如此的,它實際是放在一個叫 person.ibd (innodb data)的文件中,也叫做表空間;雖然數據表中,他們看起來是一條連著一條,但是實際上在文件中它被分成很多小份的數據頁,而且每一份都是 16K。
大概就像下面這樣,當然這只是我們抽象出來的,在表空間中還有段、區、組等很多概念,但是我們需要跳出來看。
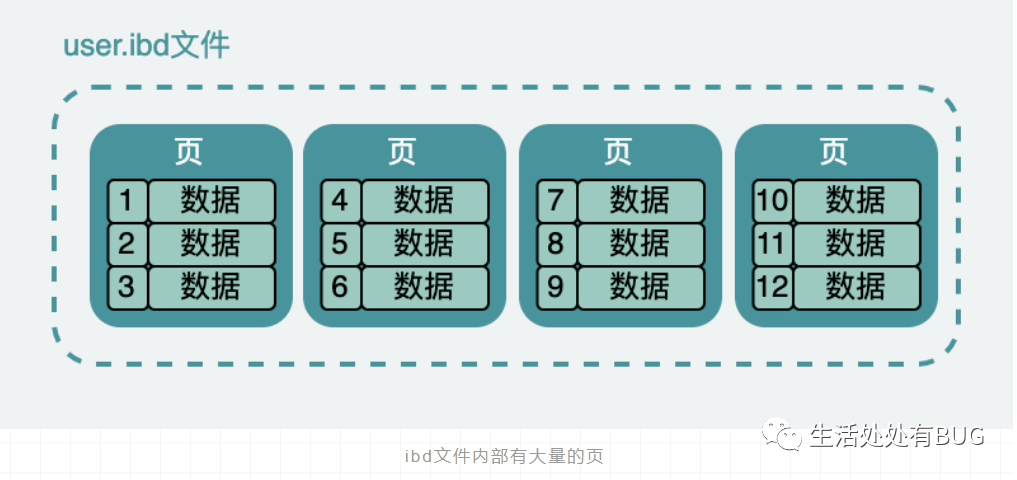
圖片
頁的數據結構
因為每個頁只有 16K 的大小,但是如果數據很多,那一頁肯定就放不下這些數據,那數據肯定就會被分到其他的頁中,所以為了把這些頁關聯起來,肯定就會有記錄前后頁地址,方便找到對應頁;同時每頁都是唯一的,那就會需要有一個唯一標志來標記頁,就是頁號;
頁中會記錄數據所以會存在讀寫操作,讀寫操作會存在中斷或者其他異常導致數據不全等,那就會需要有校驗機制,所以里面還有會校驗碼,而讀操作最重要的就是效率問題,如果按照記錄一個個進行遍歷,那肯定是很費勁的,所以這里面還會為數據生成對應的頁目錄(Page Directory); 所以實際頁的內部結構像是下面這樣的。
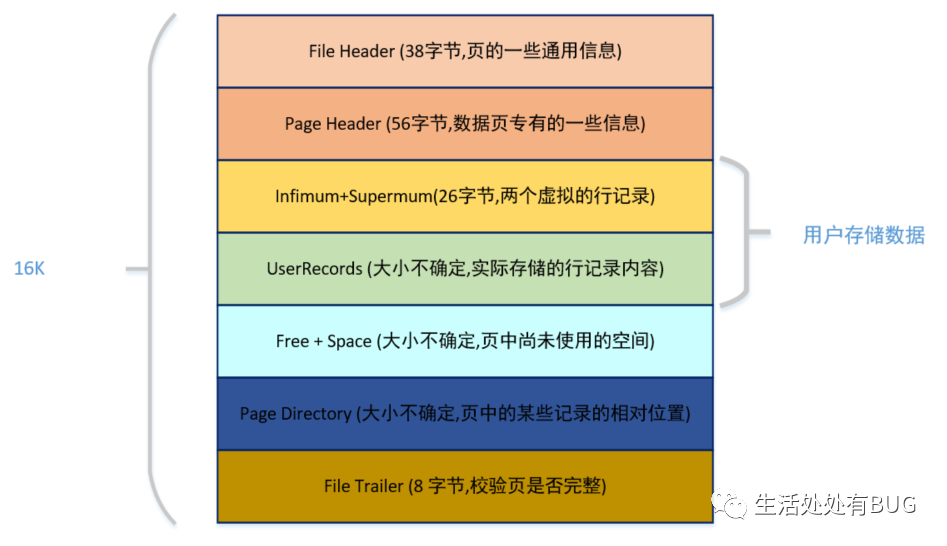
圖片
從圖中可以看出,一個 InnoDB 數據頁的存儲空間大致被劃分成了 7 個部分,有的部分占用的字節數是確定的,有的部分占用的字節數是不確定的。
在頁的 7 個組成部分中,我們自己存儲的記錄會按照我們指定的行格式存儲到 User Records 部分。
但是在一開始生成頁的時候,其實并沒有 User Records 這個部分,每當我們插入一條記錄,都會從 Free Space 部分,也就是尚未使用的存儲空間中申請一個記錄大小的空間劃分到 User Records 部分,當 Free Space 部分的空間全部被 User Records 部分替代掉之后,也就意味著這個頁使用完了,如果還有新的記錄插入的話,就需要去申請新的頁了。這個過程的圖示如下。
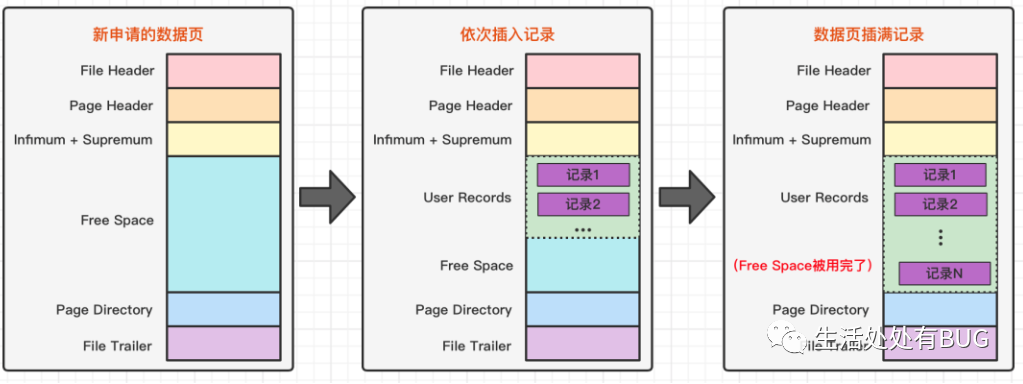
圖片
剛剛上面說到了數據的新增的過程。
那下面就來說說,數據的查找過程,假如我們需要查找一條記錄,我們可以把表空間中的每一頁都加載到內存中,然后對記錄挨個判斷是不是我們想要的,在數據量小的時候,沒啥問題,內存也可以撐;但是現實就是這么殘酷,不會給你這個局面;為了解決這問題,mysql 中就有了索引的概念;大家都知道索引能夠加快數據的查詢,那到底是怎么個回事呢?下面我就來看看。
索引的數據結構
在 mysql 中索引的數據結構和剛剛描述的頁幾乎是一模一樣的,而且大小也是 16K, 但是在索引頁中記錄的是頁 (數據頁,索引頁) 的最小主鍵 id 和頁號,以及在索引頁中增加了層級的信息,從 0 開始往上算,所以頁與頁之間就有了上下層級的概念。
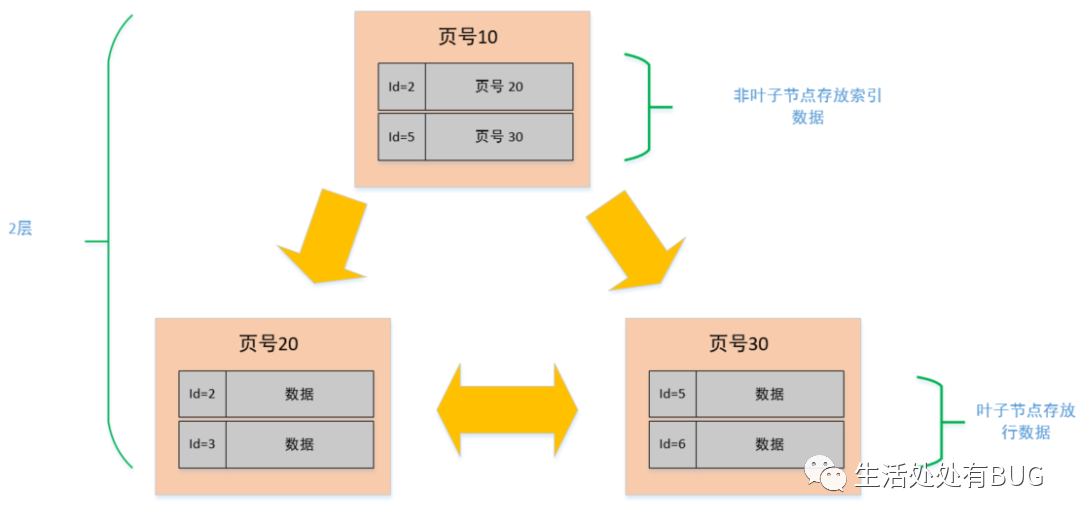
圖片
看到這個圖之后,是不是有點似曾相似的感覺,是不是像一棵二叉樹啊,對,沒錯!它就是一棵樹,只不過我們在這里只是簡單畫了三個節點,2 層結構的而已,如果數據多了,可能就會擴展到 3 層的樹,這個就是我們常說的 B+ 樹,最下面那一層的 page level =0, 也就是葉子節點,其余都是非葉子節點。
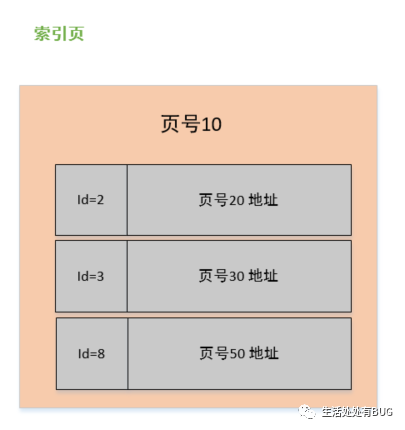
圖片
看上圖中,我們是單拿一個節點來看,首先它是一個非葉子節點(索引頁),在它的內容區中有 id 和 頁號地址兩部分,這個 id 是對應頁中記錄的最小記錄 id 值,頁號地址是指向對應頁的指針;而數據頁與此幾乎大同小異,區別在于數據頁記錄的是真實的行數據而不是頁地址,而且 id 的也是順序的。
單表建議值
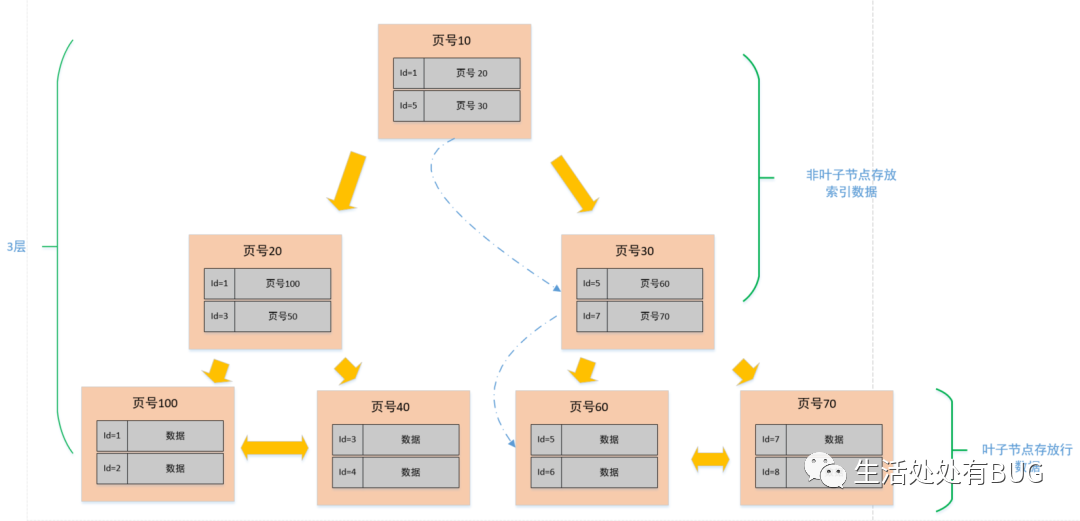
下面我們就以 3 層,2 分叉(實際中是 M 分叉)的圖例來說明一下查找一個行數據的過程。
比如說我們需要查找一個 id=6 的行數據,因為在非葉子節點中存放的是頁號和該頁最小的 id,所以我們從頂層開始對比,首先看頁號 10 中的目錄,有 [id=1, 頁號 = 20],[id=5, 頁號 = 30], 說明左側節點最小 id 為 1,右側節點最小 id 是 5;6>5, 那按照二分法查找的規則,肯定就往右側節點繼續查找,找到頁號 30 的節點后,發現這個節點還有子節點(非葉子節點),那就繼續比對,同理,6>5&&6<7, 所以找到了頁號 60,找到頁號 60 之后,發現此節點為葉子節點(數據節點),于是將此頁數據加載至內存進行一一對比,結果找到了 id=6 的數據行。
從上述的過程中發現,我們為了查找 id=6 的數據,總共查詢了三個頁,如果三個頁都在磁盤中(未提前加載至內存),那么最多需要經歷三次的磁盤 IO。需要注意的是,圖中的頁號只是個示例,實際情況下并不是連續的,在磁盤中存儲也不一定是順序的。
圖片
至此,我們大概已經了解了表的數據是怎么個結構了,也大概知道查詢數據是個怎么的過程了,這樣我們也就能大概估算這樣的結構能存放多少數據了。
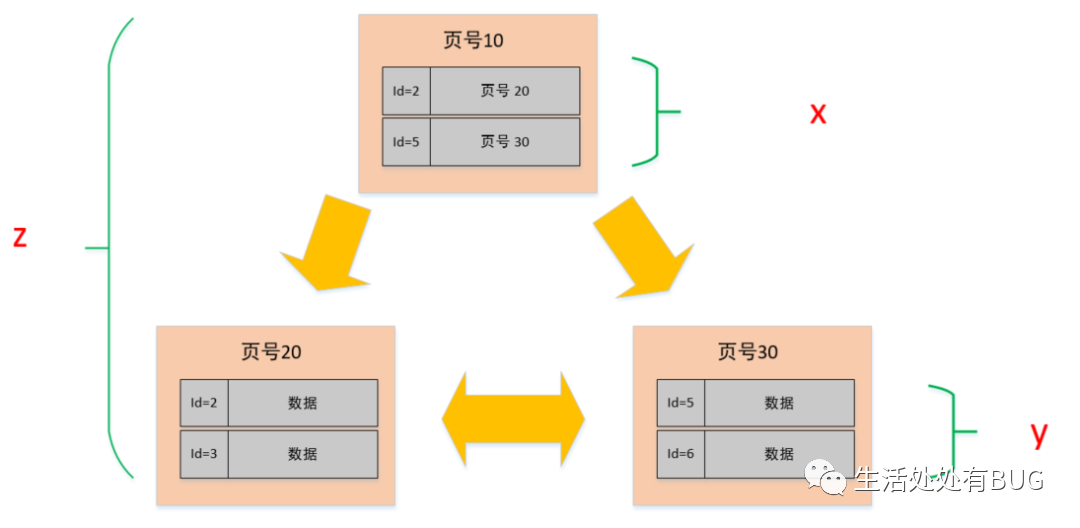
從上面的圖解我們知道 B+ 數的葉子節點才是存在數據的,而非葉子節點是用來存放索引數據的。
所以,同樣一個 16K 的頁,非葉子節點里的每條數據都指向新的頁,而新的頁有兩種可能
? 如果是葉子節點,那么里面就是一行行的數據
? 如果是非葉子節點的話,那么就會繼續指向新的頁
假設
? 非葉子節點內指向其他頁的數量為 x
? 葉子節點內能容納的數據行數為 y
? B+ 數的層數為 z
如下圖中所示 Total =x^(z-1) *y 也就是說總數會等于 x 的 z-1 次方 與 Y 的乘積。
圖片
X =?
在文章的開頭已經介紹了頁的結構,索引也也不例外,都會有 File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上頁目錄,大概 1k 左右,我們就當做它就是 1K, 那整個頁的大小是 16K, 剩下 15k 用于存數據,在索引頁中主要記錄的是主鍵與頁號,主鍵我們假設是 Bigint (8 byte), 而頁號也是固定的(4Byte), 那么索引頁中的一條數據也就是 12byte; 所以 x=15*1024/12≈1280 行。
Y=?
葉子節點和非葉子節點的結構是一樣的,同理,能放數據的空間也是 15k;但是葉子節點中存放的是真正的行數據,這個影響的因素就會多很多,比如,字段的類型,字段的數量;每行數據占用空間越大,頁中所放的行數量就會越少;這邊我們暫時按一條行數據 1k 來算,那一頁就能存下 15 條,Y≈15。
算到這邊了,是不是心里已經有譜了啊 根據上述的公式,Total =x^(z-1) y,已知 x=1280,y=15 假設 B+ 樹是兩層,那就是 Z =2, Total = (1280 ^1 )15 = 19200 假設 B+ 樹是三層,那就是 Z =3, Total = (1280 ^2) *15 = 24576000 (約 2.45kw)
哎呀,媽呀!這不是正好就是文章開頭說的最大行數建議值 2000w 嘛!對的,一般 B+ 數的層級最多也就是 3 層,你試想一下,如果是 4 層,除了查詢的時候磁盤 IO 次數會增加,而且這個 Total 值會是多少,大概應該是 3 百多億吧,也不太合理,所以,3 層應該是比較合理的一個值。
到這里難道就完了?
不我們剛剛在說 Y 的值時候假設的是 1K ,那比如我實際當行的數據占用空間不是 1K , 而是 5K, 那么單個數據頁最多只能放下 3 條數據 同樣,還是按照 Z=3 的值來計算,那 Total = (1280 ^2) *3 = 4915200 (近 500w)
所以,在保持相同的層級(相似查詢性能)的情況下,在行數據大小不同的情況下,其實這個最大建議值也是不同的,而且影響查詢性能的還有很多其他因素,比如,數據庫版本,服務器配置,sql 的編寫等等,MySQL 為了提高性能,會將表的索引裝載到內存中。在 InnoDB buffer size 足夠的情況下,其能完成全加載進內存,查詢不會有問題。但是,當單表數據庫到達某個量級的上限時,導致內存無法存儲其索引,使得之后的 SQL 查詢會產生磁盤 IO,從而導致性能下降,所以增加硬件配置(比如把內存當磁盤使),可能會帶來立竿見影的性能提升哈。
總結
1.Mysql 的表數據是以頁的形式存放的,頁在磁盤中不一定是連續的。
2.頁的空間是 16K, 并不是所有的空間都是用來存放數據的,會有一些固定的信息,如,頁頭,頁尾,頁碼,校驗碼等等。
3.在 B+ 樹中,葉子節點和非葉子節點的數據結構是一樣的,區別在于,葉子節點存放的是實際的行數據,而非葉子節點存放的是主鍵和頁號。
4.索引結構不會影響單表最大行數,2kw 也只是推薦值,超過了這個值可能會導致 B + 樹層級更高,影響查詢性能。
上邊理論是原文的,我的實踐結果是:隨著數據量成倍地增加,查詢的時間也剛好是成倍增加,是成正比的。
我感覺原作者的理論是對的,但我照著原作者的實踐思路,得出的結果并不支持他的理論,有高手來評判一下嗎?
審核編輯:湯梓紅
-
數據
+關注
關注
8文章
6888瀏覽量
88826 -
內存
+關注
關注
8文章
2998瀏覽量
73881 -
SQL
+關注
關注
1文章
759瀏覽量
44069 -
MySQL
+關注
關注
1文章
801瀏覽量
26441
原文標題:理論
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2000W功率放大器

KHPA-0811W:500/1000/2000W X波段脈沖放大器廢棄數據表

KHPA0608-XXXWP:500/1000/2000W C波段脈沖放大器數據表

為什么 MySQL 單表不能超過 2000 萬行?

2000W手持激光焊接機價格鐳拓這個配置才叫性價比







 工商網監
工商網監
評論