 【飛騰派4G版免費試用】 第三章:抓取圖像,手動標注并完成自定義目標檢測模型訓練和測試
【飛騰派4G版免費試用】 第三章:抓取圖像,手動標注并完成自定義目標檢測模型訓練和測試
抓取圖像,手動標注并完成自定義目標檢測模型訓練和測試
在第二章中,我介紹了模型訓練的一般過程,其中關鍵的過程是帶有標注信息的數據集獲取。訓練過程中可以已有的數據集合不能滿足自己的要求,這時候就需要自己獲取素材并進行標注然后完成模型的訓練,本章就介紹下,如何從網絡抓取素材并完成佩奇的目標檢測。整個過程由如下幾個部分:
- 抓取素材,這里我使用下面的python腳本完成
#!/bin/python3
# 支持根據關鍵詞抓取百度圖片搜索的圖片
import requests
import os
import re
def get_images_from_baidu(keyword, page_num, save_dir):
# UA 偽裝:當前爬取信息偽裝成瀏覽器
# 將 User-Agent 封裝到一個字典中
# 【(網頁右鍵 → 審查元素)或者 F12】 → 【Network】 → 【Ctrl+R】 → 左邊選一項,右邊在 【Response Hearders】 里查找
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
# 請求的 url
url = 'https://image.baidu.com/search/acjson?'
n = 0
for pn in range(0, 30 * page_num, 30):
# 請求參數
param = {'tn': 'resultjson_com',
# 'logid': '7603311155072595725',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': '', # 這個參數沒公開,但是不可少
'pn': pn, # 顯示:30-60-90
'rn': '30', # 每頁顯示 30 條
'gsm': '1e',
'1618827096642': ''
}
request = requests.get(url=url, headers=header, params=param)
if request.status_code == 200:
print('Request success.')
request.encoding = 'utf-8'
# 正則方式提取圖片鏈接
html = request.text
image_url_list = re.findall('"thumbURL":"(.*?)",', html, re.S)
print(image_url_list)
# # 換一種方式
# request_dict = request.json()
# info_list = request_dict['data']
# # 看它的值最后多了一個,刪除掉
# info_list.pop()
# image_url_list = []
# for info in info_list:
# image_url_list.append(info['thumbURL'])
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for image_url in image_url_list:
image_data = requests.get(url=image_url, headers=header).content
with open(os.path.join(save_dir, f'{n:06d}.jpg'), 'wb') as fp:
fp.write(image_data)
n = n + 1
if __name__ == '__main__':
keyword = '佩奇'
save_dir = keyword
page_num = 3
get_images_from_baidu(keyword, page_num, save_dir)
print('Get images finished.')
將抓取的圖片,篩選以后(剔除沒有佩奇的圖片)分為兩組數據,訓練集和檢驗集。結構是類似這樣的:
? tree peppa_jpg/ | head -n 10
peppa_jpg/
├── 000000.jpg
├── 000001.jpg
├── 000002.jpg
├── 000003.jpg
├── 000004.jpg
├── 000005.jpg
├── 000006.jpg
├── 000007.jpg
├── 000008.jpg
┏─?[red]?─?[22:07:44]?─?[0]
┗─?[~/Projects/ai_track_feiteng/demo3]
? tree peppa_valid_jpg/ | head -n 10
peppa_valid_jpg/
├── 000067.jpg
├── 000072.jpg
├── 000077.jpg
├── 000078.jpg
├── 000079.jpg
├── 000083.jpg
├── 000088.jpg
├── 000089.jpg
├── 000090.jpg
- 手工標注素材,這里我使用的是 labelImg ,標注的過程類似這樣:
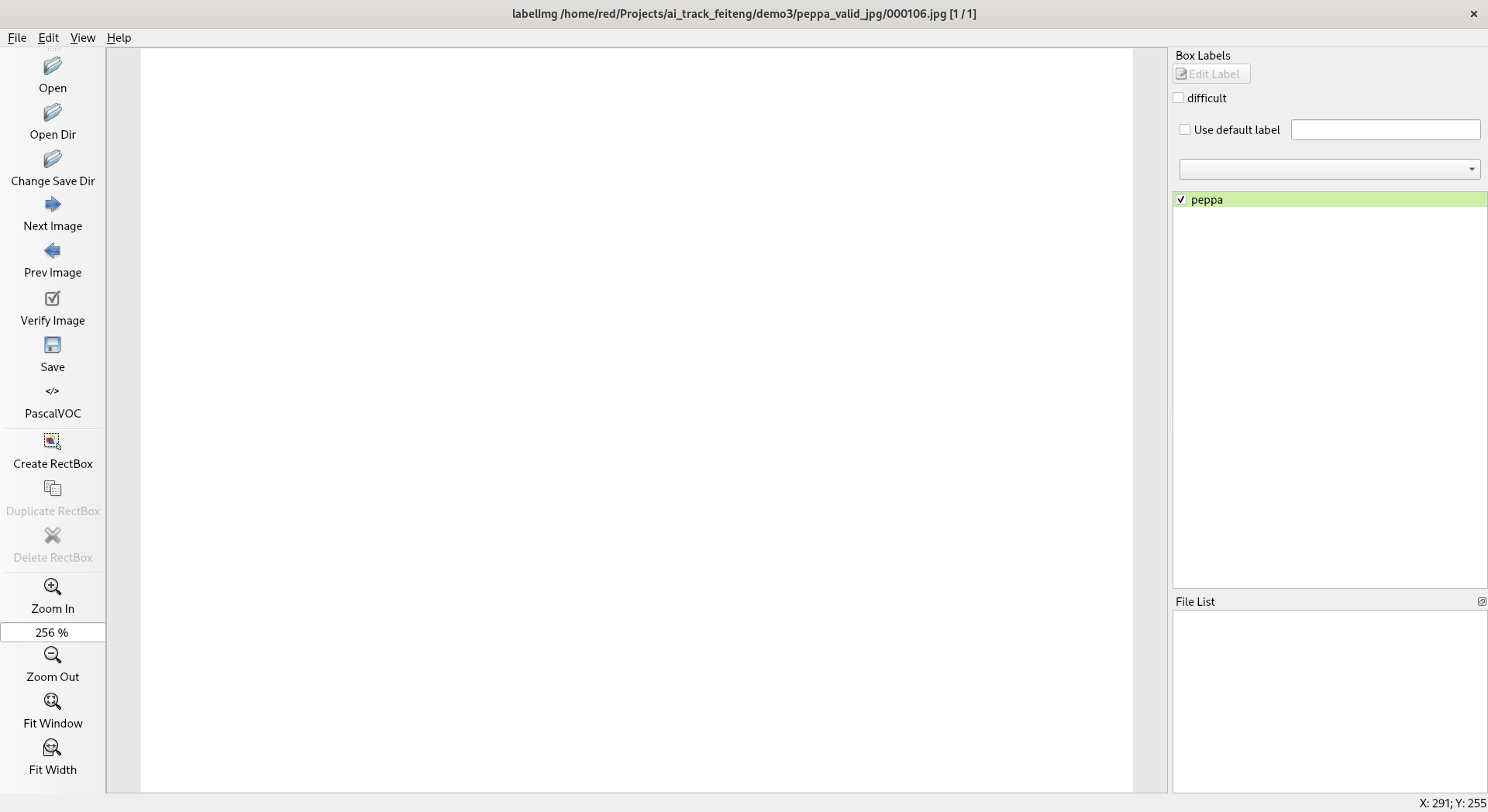
然后存儲為 PascalVOC 的 xml 文件。這里轉存之后是這樣的:
? tree peppa_xml/ | head -n 10
peppa_xml/
├── 000000.xml
├── 000001.xml
├── 000002.xml
├── 000004.xml
├── 000006.xml
├── 000007.xml
├── 000008.xml
├── 000010.xml
├── 000011.xml
┏─?[red]?─?[09:27:00]?─?[0]
┗─?[~/Projects/ai_track_feiteng/demo3]
? tree peppa_valid_xml/ | head -n 10
peppa_valid_xml/
├── 000067.xml
├── 000072.xml
├── 000077.xml
├── 000078.xml
├── 000079.xml
├── 000083.xml
├── 000088.xml
├── 000089.xml
├── 000090.xml
- 格式轉換為TFRecord 格式,這里我參考raccoon_dataset使用了兩個步驟,首先轉換為csv文件,然后再轉換為TFRecord 格式文件。這里我對其中涉及到的腳本進行了微調,其中 xml_to_csv.py 文件我改成下下面的內容:
#!/bin/python3.8
import os
import sys
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main(xml_path, csv_file):
image_path = os.path.join(os.getcwd(), xml_path)
xml_df = xml_to_csv(image_path)
xml_df.to_csv(csv_file, index=None)
print('Successfully converted xml to csv.')
if len(sys.argv) < 2:
print("please input xml_path and out csv file")
else:
main(sys.argv[1], sys.argv[2])
這里通過命令:
? ./red_xml2csv.py peppa_xml/ peppa_jpg/pegga_train_labels.csv
Successfully converted xml to csv.
? ./red_xml2csv.py peppa_valid_xml/ peppa_valid_jpg/peppa_valid_labels.csv
Successfully converted xml to csv.
就可以分別將訓練集和校驗集轉換為相應的 csv 文件并存儲到圖像數據集的目錄中,因為后續會分別在對應的目錄中執行轉換為TFRecord格式的操作進行。
執行的命令分別是:
?python3.8 ../generate_tfrecord.py --csv_input=pegga_train_labels.csv --output_path=pegga_train.record
?python3.8 ../generate_tfrecord.py --csv_input=pegga_valid_labels.csv --output_path=pegga_valid.record
至此,就完成了從原始的圖像數據,到含有標注信息的TFRecord格式數據集的轉換。接下來就是訓練和校驗了。
- 訓練和校驗的過程和第二章一樣,只是數據集變了,這里只是展示下訓練過程和模型導出過程的截圖。
模型訓練:
模型導出:
模型到處完成后,我們會看到模型在如下目錄,以及其中的文件和從網上下載的TensorFlow2的模型壓縮包里面的結構一樣。
我們可以對比看看,我從網上下載的efficientdet_d0_coco17_tpu-32模型中的內容結構:
- 模型導出之后就是測試過程了,測試方法和第二章的方法一樣,我就直接附上我從網上下載的測試圖片和標注以后的圖片:
希望本章可以為想上手通過機器學習進行目標檢測的伙伴提供一點幫助,下一章,我就準備將模型部署到飛騰派進行測試了,敬請期待。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
模型
+關注
關注
1文章
3178瀏覽量
48729 -
目標檢測
+關注
關注
0文章
205瀏覽量
15590 -
飛騰派
+關注
關注
2文章
9瀏覽量
206
發布評論請先 登錄
相關推薦
【飛騰派4G版免費試用】飛騰派開發板運行Ubuntu系統
飛騰派4G版開發板是一款做工精細,布線合理的開發板,今天給大家介紹一下如何運行Ubuntu系統,下面是網上的資料,幫助大家快速認識飛騰派
發表于 01-08 22:40
【飛騰派4G版免費試用】飛騰派4G版開發板套裝測試及環境搭建
先簡單介紹一下這款飛騰派4G版開發板套裝;
飛騰派是由中電港螢火工場研發的一款面向行業工程師、學生和愛好者的開源硬件。主板處理器采用
發表于 01-22 00:47
【飛騰派4G版免費試用】4.手把手玩轉QT界面設計
完成了使用Qt Designer進行界面設計的全部流程!是不是覺得像魔法一樣神奇呢?趕緊試試吧!
接上三篇:
【飛騰派4G版
發表于 01-27 12:49
【新品體驗】飛騰派4G版基礎套裝免費試用
飛騰派是由飛騰攜手中電港螢火工場研發的一款面向行業工程師、學生和愛好者的開源硬件,采用飛騰嵌入式四核處理器,兼容ARM V8架構,板載64位 DDR
發表于 10-25 11:44







 工商網監
工商網監
評論