 Triton編譯器的原理和性能
Triton編譯器的原理和性能
我們推出了一個新的系列,對PytorchConference2023 的博客進行中文編譯,會陸續在公眾號發表。
Triton是一種用于編寫高效自定義深度學習原語的語言和編譯器。Triton的目的是提供一個開源環境,以比CUDA更高的生產力編寫快速代碼,但也比其他現有DSL具有更大的靈活性。Triton已被采用為Torch inductor的基本組件,以合成針對GPU的高效內核。與傳統庫使用相比,這具有多種優勢。它允許創建各種各樣的融合,它可以獨立調整,并且它的內存占用更小。本次演講將介紹Triton編譯器,并描述使其能夠以最少的用戶努力生成閃電般快速內核的過程。
全文
今天我要和大家談談的是Triton。那么,我將要討論的大致內容是Triton是什么?我們為什么要創建這個工具?它可以用來做什么?然后,我將討論如何將其集成在ML編譯器堆棧中。最后,我將簡要介紹其背后的原理以及編譯器是如何簡化管理的。
Triton是一個Python DSL(領域特定語言),旨在用于編寫機器學習內核。 最初,它嚴格用于GPU內核,但慢慢地擴展以支持用于機器學習的任何硬件,包括CPU、ASIC等。Triton的目標是讓那些沒有GPU經驗的研究人員能夠編寫高性能代碼。如果你看到幻燈片底部的圖表,那真的是Triton想要達到的地方。通過少量的開發工作,你可以非常接近峰值性能。
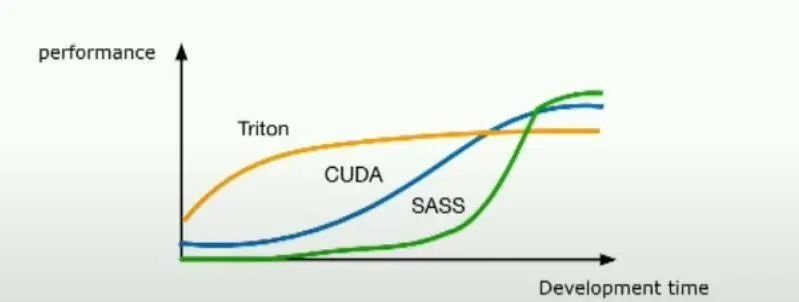
簡而言之,Triton是一個幫助研究人員輕松編寫高性能機器學習內核的工具,無論他們是否有GPU經驗。
當然,總是會有像CUDA或匯編語言這樣的其他語言,它們能讓你獲得同樣或更高的性能,但通常你需要對硬件有更多的了解,并花費更多的時間。為什么我們需要這種新的語言呢?如果你看看現有的選擇,例如在不同的硬件上編程機器學習,有PyTorch這樣的工具,它允許你輕松地將不同類型的操作映射到硬件上,并且非常容易從中獲得高性能。
但問題在于你對它的控制非常有限。如果現有的操作集中沒有你需要的東西,你就只能束手無策,唯一的解決辦法是走向另一個極端,例如編寫CUDA或編寫PTX,甚至直接編寫匯編代碼。但問題在于,要編寫這些語言,你需要真正成為硬件方面的專家,并且用這些語言編寫高效的內核可能非常棘手 。所以Triton實際上是嘗試在這里找到一個中間地帶,它允許用戶編寫高效的內核,并有大量的控制權,但又不必關心那些微小的細節。
是的,硬件的細節以及如何在特定硬件上獲得性能。實際上,設計的難點在于找到這個最佳平衡點。Triton的設計方式就是找到這個抽象的平衡點,即你想向用戶暴露什么,以及你想讓編譯器做什么?
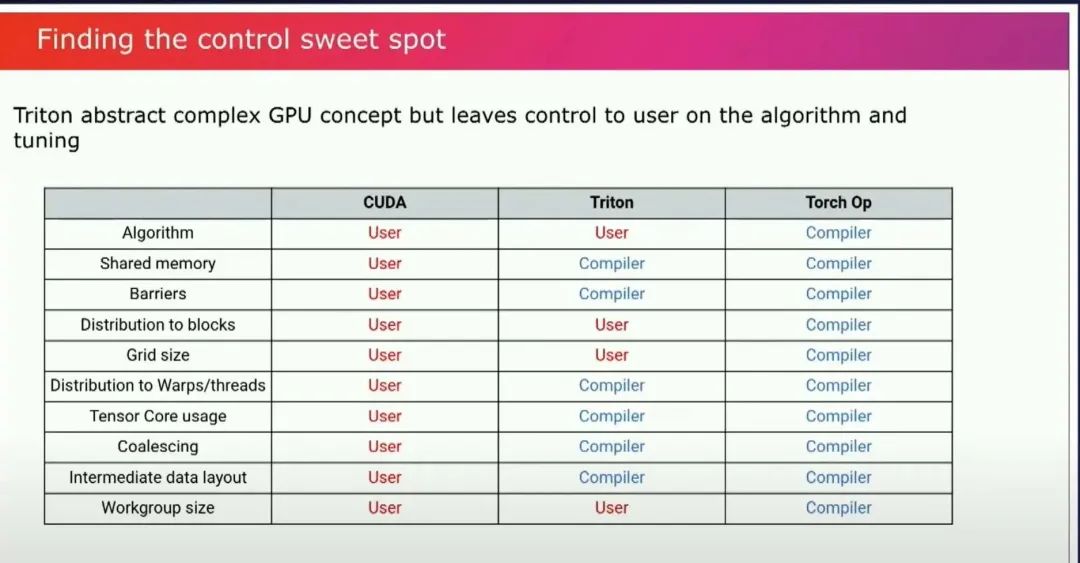
編譯器是生產力工具,真的……在這方面,Triton的目標是讓編譯器為你完成你不想做的工作,但仍然讓你能夠控制算法、你想要用來進行調整的任何tuning。Triton介于Cuda和Torch之間,因為你仍然可以編寫自己的算法,你仍然可以控制自己的類型,你仍然需要決定是否需要以某種類型來保存中間值,你控制所有的精度。你不必關心如何處理共享內存、在目標有張量核時使用張量核、如何很好地處理負載聚合,以便你有良好的內存訪問模式。 這些人們在編寫GPU內核時經常要考慮的事情。你總是要擔心這些問題,或者弄清楚我的中間數據的布局是什么等等。編譯器會為你完成這些工作。
讓我們來看一個例子。這是一個softmax內核的示例。這是一個工作解決方案的復制品,它是有效的。
#https://github.com/openai/triton/blob/main/python/tutorials/02-fused-softmax.py @triton.jit defsoftmax_kernel(output_ptr,input_ptr,input_row_stride,output_row_stride,n_cols,BLOCK_SIZE:tl.constexpr): #Therowsofthesoftmaxareindependent,soweparallelizeacrossthose row_idx=tl.program_id(0) #Thestriderepresentshowmuchweneedtoincreasethepointertoadvance1row row_start_ptr=input_ptr+row_idx*input_row_stride #Theblocksizeisthenextpoweroftwogreaterthann_cols,sowecanfiteach #rowinasingleblock col_offsets=tl.arange(0,BLOCK_SIZE) input_ptrs=row_start_ptr+col_offsets #LoadtherowintoSRAM,usingamasksinceBLOCK_SIZEmaybe>thann_cols row=tl.load(input_ptrs,mask=col_offsets
第一個有趣的事情是這段代碼相對較短。如果你用CUDA編寫同樣的內核,它實際需要更多的努力。我們可以注意到一些有趣的事情。例如,你可以控制如何在計算機上分配工作。多虧了這些編程思想。你可以看到,你仍然可以控制你的內存訪問,因為你可以訪問指針。你可以基于一些原始指針加載一大塊數據。然后編譯器將在后臺決定將其映射到硬件的最佳方式,以及如何進行聚合,如何處理所有事情,以便這個加載將是有效的,并將分布到你的GPU的不同線程和warp上。但你不必擔心這些。在底部,我們可以看到有一個歸約操作,通常它會隱式地使用共享內存,但你不必擔心它。編譯器將確保你為其選擇最佳實現,并為你使用共享內存。
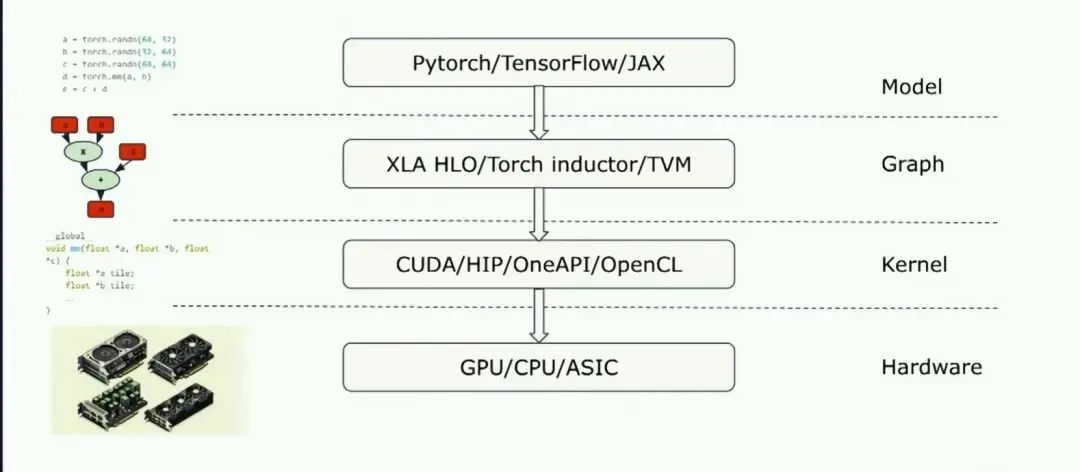
之后我將討論,如何在典型的設備上使用triton,除了內核他還可以集成到完整的graph編譯器堆棧中:
Triton為你提供了一個非常容易、非常自然的從graph表示直接到實現的lowering過程,并且它實際上允許更簡單的graph表示實現,因為你不必一次性生成一個完美的內核。你可以只生成Triton部分,然后Triton編譯器將完成繁重的工作,找出如何有效地將其映射到硬件上。
Triton可以被用作的另一個地方是它可以被用作自定義操作語言 。像PyTorch這樣的工具,因為如果你陷入困境,而PyTorch中沒有實現某些功能,添加自定義操作是你能夠完成你想要做的事情的唯一解決方案。
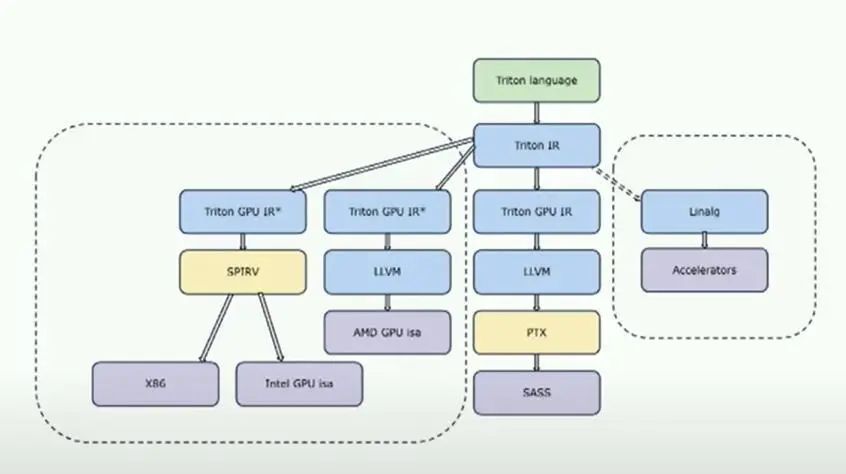
讓我們稍微看一下編譯器架構。這是一個非常高層次的查看Triton架構的方式。
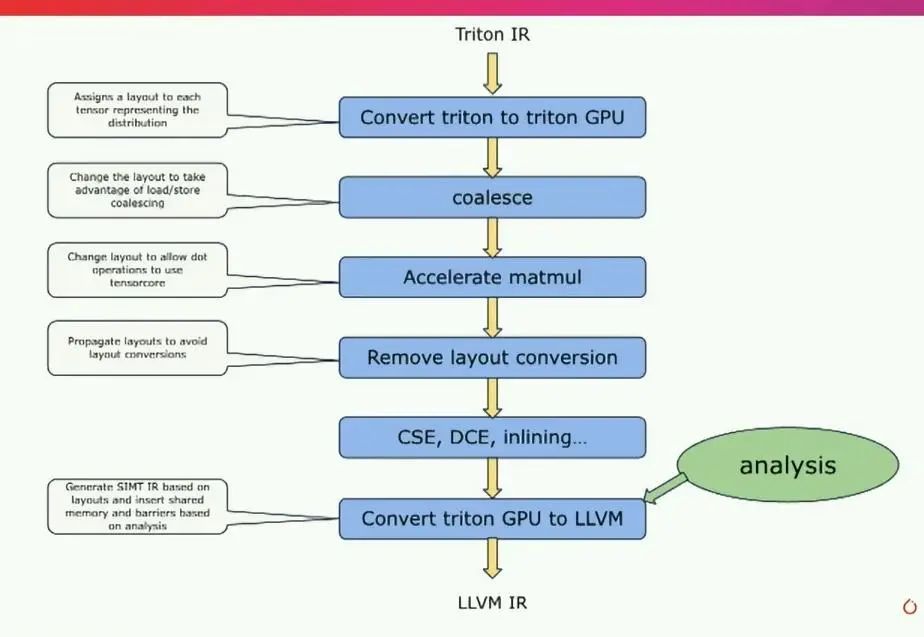
Triton被構建為一個老式編譯器,包括前端、中端和后端。這里有趣的部分是這兩個塊,Triton IR和Triton GPU IR,它們是Triton的中間IR,這里有很多魔法發生。你可以在這里看到的另一件有趣的事情是,Triton IR真的允許你針對不同的硬件進行定位,因為Triton IR本身對于這硬件是完全無關的。如果我們放大這個有趣的部分,即基本上發生在Triton IR和最終的LLVM IR之間的事情,LLVM IR是最終的目標。
基本上,編譯器首先接收Triton IR,Triton IR與語言本身非常相似。然后,編譯器要做的第一件事是為描述張量如何分布到線程上的布局進行關聯。這真的是編譯器的核心機制,因為基于這些布局,有多種路徑可以改變這些布局,并能夠生成一些能夠有效地映射到硬件上的東西。因此,我們會像進行coalesce一樣,嘗試選擇一個布局,以便加載存儲聚合能夠高效進行。
如果機器有tensorcore,我們會嘗試使用非常適合tensorcore的布局。然后,我們會嘗試避免任何布局轉換,應用一系列典型的編譯器傳遞,然后在此基礎上進行轉換,基于分析轉到llvm ir。
這是非常高層次的,但這就是編譯器的工作原理。嗯,這就是我想告訴你的全部內容。Triton正在完全開源的情況下進行開發,非常歡迎貢獻者。我們每個月都會舉行社區會議。
Triton IR本身對硬件無關。但是,如果你把一個在目標上運行良好的內核拿過來,你可能需要重新調整它,以便在另一個目標上運行良好。
審核編輯:湯梓紅
-
內核
+關注
關注
3文章
1362瀏覽量
40228 -
gpu
+關注
關注
28文章
4700瀏覽量
128695 -
Triton
+關注
關注
0文章
16瀏覽量
7026 -
編譯器
+關注
關注
1文章
1618瀏覽量
49048 -
深度學習
+關注
關注
73文章
5492瀏覽量
120975
原文標題:《PytorchConference2023 翻譯系列》6-Triton編譯器
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于CoSy的編譯器開發的研究

編譯器是如何工作的_編譯器的工作過程詳解
編譯器原理到底是怎樣的帶你簡單的了解編譯器原理
如何在Keil MDK中使用GCC編譯器工具鏈
Verilog HDL 編譯器指令說明

GH集成開發環境和編譯器
交叉編譯器安裝教程
領域編譯器發展的前世今生
新版編譯器的設計思路和優化方法

編譯器的優化選項





 工商網監
工商網監
評論