 3D人體生成模型HumanGaussian實現原理
3D人體生成模型HumanGaussian實現原理
來源:公眾號 機器之心 授權
在 3D 生成領域,根據文本提示創建高質量的 3D 人體外觀和幾何形狀對虛擬試穿、沉浸式遠程呈現等應用有深遠的意義。傳統方法需要經歷一系列人工制作的過程,如 3D 人體模型回歸、綁定、蒙皮、紋理貼圖和驅動等。為了自動化 3D 內容生成,此前的一些典型工作(比如 DreamFusion [1] )提出了分數蒸餾采樣 (Score Distillation Sampling),通過優化 3D 場景的神經表達參數,使其在各個視角下渲染的 2D 圖片符合大規模預訓練的文生圖模型分布。然而,盡管這一類方法在單個物體上取得了不錯的效果,我們還是很難對具有復雜關節的細粒度人體進行精確建模。
為了引入人體結構先驗,最近的文本驅動 3D 人體生成研究將 SDS 與 SMPL 等模型結合起來。具體來說,一個常見的做法是將人體先驗集成到網格(mesh)和神經輻射場(NeRF)等表示中,或者通過將身體形狀作為網格 / 神經輻射場密度初始化,或者通過學習基于線性混合蒙皮(Linear Blend Skinning)的形變場。然而,它們大多在效率和質量之間進行權衡:基于 mesh 的方法很難對配飾和褶皺等精細拓撲進行建模;而基于 NeRF 的方法渲染高分辨率結果對時間和顯存的開銷非常大。如何高效地實現細粒度生成仍然是一個未解決的問題。
最近,3D Gaussian Splatting(3DGS)[2] 的顯式神經表達為實時場景重建提供了新的視角。它支持多粒度、多尺度建模,對 3D 人體生成任務非常適用。然而,想要使用這種高效的表達仍有兩個挑戰:1) 3DGS 通過在每個視錐體中排序和 alpha - 混合各向異性的高斯來表征基于圖塊的光柵化,這僅會反向傳播很少一部分的高置信度高斯。然而,正如 3D 表面 / 體積渲染研究所證實的那樣,稀疏的梯度可能會阻礙幾何和外觀的網絡優化。因此,3DGS 需要結構引導,特別是對于需要層次化建模和可控生成的人體領域。2)樸素的 SDS 需要一個較大的無分類器指導(Classifier-Free Guidance)來進行圖像文本對齊(例如,在 DreamFusion [1] 中使用的 100)。但它會因過度飽和而犧牲視覺質量,使真實的人類生成變得困難。此外,由于 SDS 損失的隨機性,3DGS 中原始的基于梯度的密度控制會變得不穩定,導致模糊的結果和浮動偽影。
在最近的一項工作中,香港中文大學、騰訊 AI Lab、北京大學、香港大學、南洋理工大學團隊推出最新有效且快速的 3D 人體生成模型 HumanGaussian,通過引入顯式的人體結構引導與梯度規范化來輔助 3D 高斯的優化過程,能夠生成多樣且逼真的高質量 3D 人體模型。目前,代碼與模型均已開源。
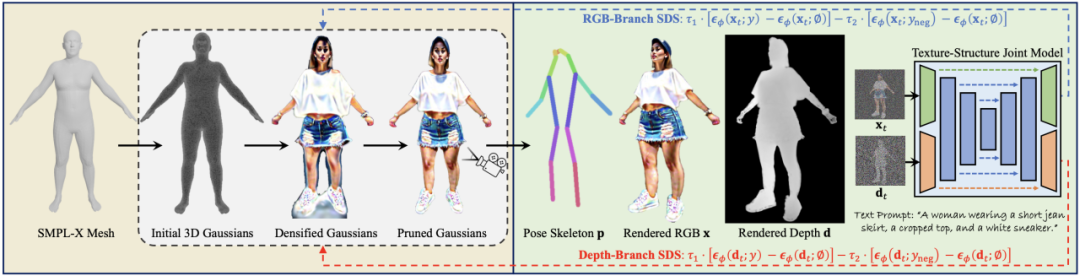
核心方法
(1)Structure-Aware SDS
研究者基于 SMPL-X 網格形狀初始化 3D 高斯中心位置:
1)以前的研究使用運動結構點(Structure-from-Motion)或 Shap-E [3] 和 Point-E [4] 等通用文本到點云先驗。然而,此類方法通常在人體類別中存在點過于稀疏或身體結構不連貫等問題。
2)作為 SMPL 的擴展,SMPL-X 補充了人臉和手部的形狀拓撲,有利于進行具有細粒度細節的復雜人體建模。基于這些觀察,研究者提出了在 SMPL-X 網格表面均勻采樣點作為 3DGS 初始化。他們對 3DGS 進行縮放和變換,使其達到合理的人體尺寸并位于 3D 空間的中心。
由于 SMPL-X 先驗僅用作初始化,因此需要更全面的指導來促進 3DGS 訓練。研究者提出使用一個同時捕獲紋理和結構聯合分布的 SDS 源模型,而不是從僅學習外觀或幾何形狀的單一模態擴散模型中學習 3D 場景。他們使用結構專家分支擴展預訓練的 Stable Diffusion 模型,以同時對圖像 RGB 和深度圖進行去噪:
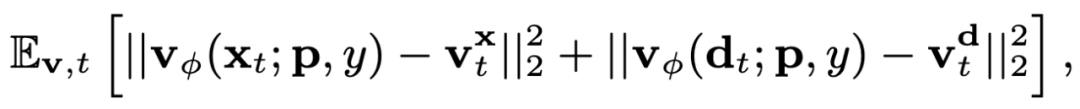
借助這種方式,研究者獲得了一個統一的模型,可以捕獲外觀的圖像紋理和前景 / 背景關系的結構,該模型可以在 SDS 中用于促進 3DGS 學習。
通過生成空間對齊圖像 RGB 和深度的擴展擴散模型,可以從結構和紋理方面同時指導 3DGS 優化過程:
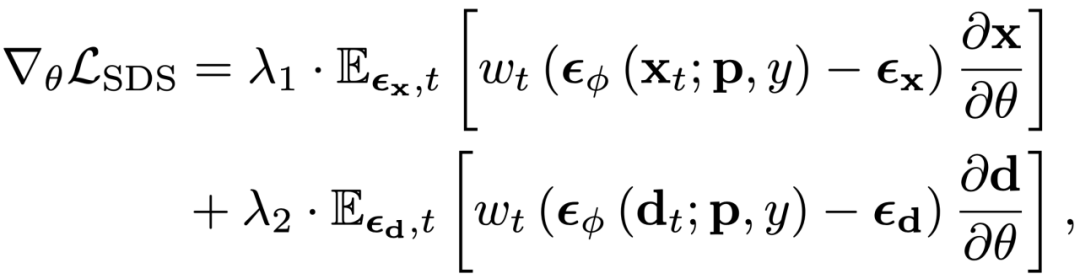
這種結構正則化有助于減少幾何失真,從而有利于具有稀疏梯度信息的 3DGS 優化。
(2)Annealed Negative Prompt Guidance
為了促進文本與 3D 生成內容之間的對齊,DreamFusion [1] 使用較大的無分類器引導尺度來更新 3D 場景優化的分數匹配差異項:
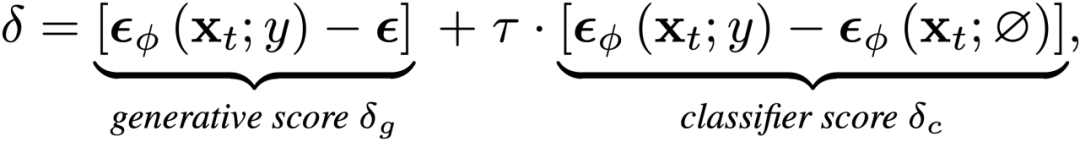
在這個公式中,可以自然地將分數匹配差異分解為兩部分,其中前一項是將圖像推向更真實的流形的生成分數;后一項是將樣本與隱式分類器對齊的分類器分數。然而,由于生成分數包含高方差的高斯噪聲,它提供了損害訓練穩定性的隨機梯度信息。為了解決這個問題,DreamFusion 特地使用較大的無分類器引導尺度,使分類器分數主導優化,導致模式過度飽和。相反,研究者僅利用更清晰的分類器分數作為 SDS 損失。
在文生圖和文生 3D 領域中,負文本被廣泛用于避免生成不需要的屬性。基于此,研究者提出增加負文本分類器分數以實現更好的 3DGS 學習。
根據經驗,研究者發現負文本分類器分數會在小時間步長內損害質量,因此使用退火的負文本引導來結合兩個分數進行監督:
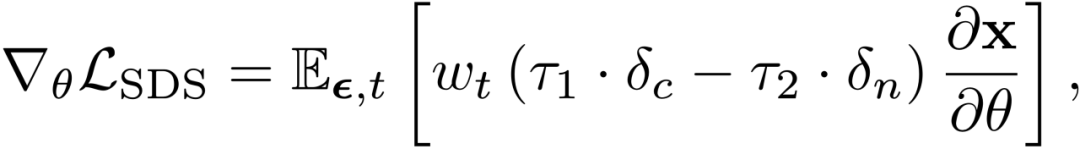
實驗結果
研究者與通用的文生 3D 和 3D 人體生成領域的模型進行對比。可以看到,HumanGaussian 取得了優越的性能,渲染出更真實的人體外觀、更連貫的身體結構、更好的視圖一致性、更細粒度的細節捕捉:
此外,研究者還通過消融實驗驗證了各個模塊的有效性。可以看出,SMPL-X 提供的人體結構先驗可以給 3DGS 優化提供初始化信息;負文本引導可以確保逼真的人體紋理外觀;圖像 RGB 與深度圖雙分支的 SDS 監督約束可以同時對人體的幾何和紋理進行優化;最后根據高斯大小進行剪枝可以去除霧狀的偽影:
更多樣本請參考文章的項目主頁以及 demo 視頻。
總結與未來工作
本文提出 HumanGaussian,一種有效且快速的框架用于生成具有細粒度幾何形狀和逼真外觀的高質量 3D 人體。HumanGaussian 提出兩點核心貢獻:
(1)設計了結構感知的 SDS,可以顯式地引入人體結構先驗,并同時優化人體外觀和幾何形狀;
(2)設計了退火的負文本引導,保證真實的結果而不會過度飽和并消除浮動偽影。總體來說,HumanGaussian 能夠生成多樣且逼真的高質量 3D 人體模型,渲染出更真實的人體外觀、更連貫的身體結構、更好的視圖一致性、更細粒度的細節捕捉。
未來工作:
由于現有的文生圖模型對于手部和腳部生成的性能有限,研究者發現它有時無法高質量地渲染這些部分;
后背視圖的渲染紋理可能看起來模糊,這是因為 2D 姿勢條件模型大多是在人類正面視圖上訓練的,而人類后視圖的先驗知識很少。
審核編輯:湯梓紅
-
3D
+關注
關注
9文章
2835瀏覽量
106991 -
開源
+關注
關注
3文章
3123瀏覽量
42065 -
模型
+關注
關注
1文章
3029瀏覽量
48345
原文標題:HumanGaussian開源:基于Gaussian Splatting,高質量 3D 人體生成新框架
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
你沒看錯,浩辰3D軟件中CAD圖紙與3D模型高效轉化這么好用!
浩辰3D軟件入門教程:如何比較3D模型
AD的3D模型繪制功能介紹
MCAD生成PCB 3D模型報錯
3D掃描儀成熱點:可生成任意3D模型
人工智能系統VON,生成最逼真3D圖像
華為基于AI技術實現3D圖像數字服務
NVIDIA生成式AI研究實現在1秒內生成3D形狀

歡創播報 騰訊元寶首發3D生成應用






 工商網監
工商網監
評論