") 基于YOLOv8實現自定義姿態(tài)評估模型訓練
基于YOLOv8實現自定義姿態(tài)評估模型訓練
前言
Hello大家好,今天給大家分享一下如何基于YOLOv8姿態(tài)評估模型,實現在自定義數據集上,完成自定義姿態(tài)評估模型的訓練與推理。
01tiger-pose數據集
YOLOv8官方提供了一個自定義tiger-pose數據集(老虎姿態(tài)評估),總計數據有263張圖像、其中210張作為訓練集、53張作為驗證集。
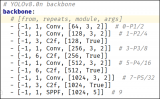
其中YOLOv8-pose的數據格式如下:
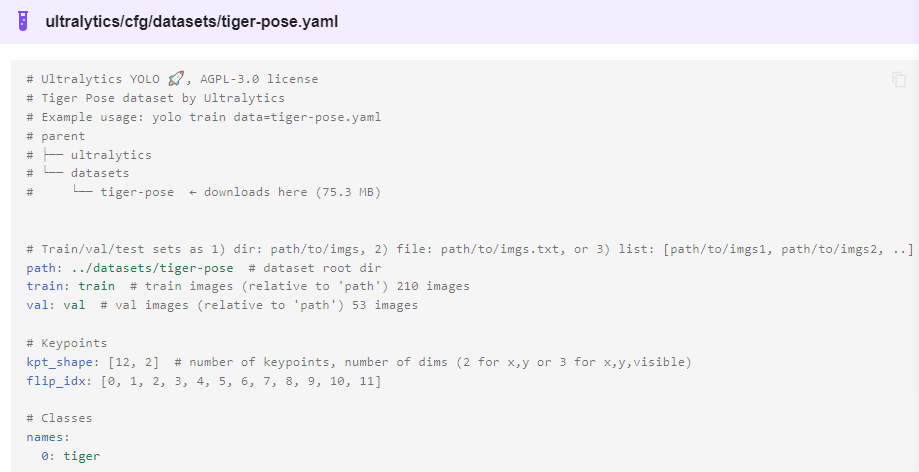
解釋一下:
Class-index 表示對象類型索引,從0開始 后面的四個分別是對象的中心位置與寬高 xc、yc、width、height px1,py1表示第一個關鍵點坐標、p1v表示師傅可見,默認填2即可。 kpt_shape=12x2表示有12個關鍵點,每個關鍵點是x,y
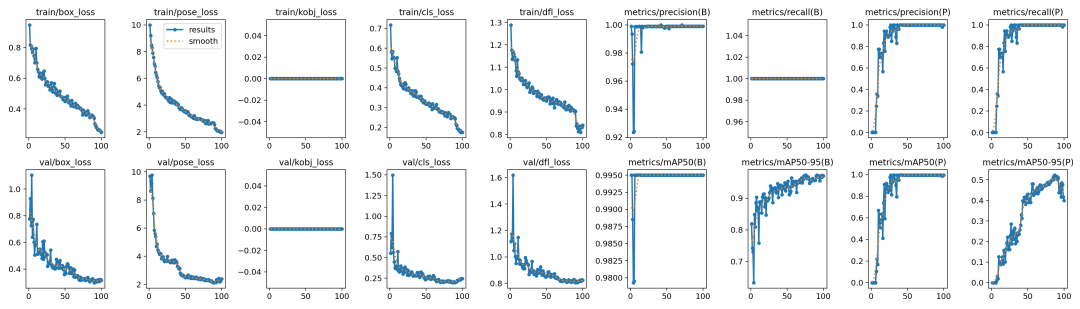
02模型訓練
跟訓練YOLOv8對象檢測模型類似,直接運行下面的命令行即可:
yolotrainmodel=yolov8n-pose.ptdata=tiger_pose_dataset.yamlepochs=100imgsz=640batch=1
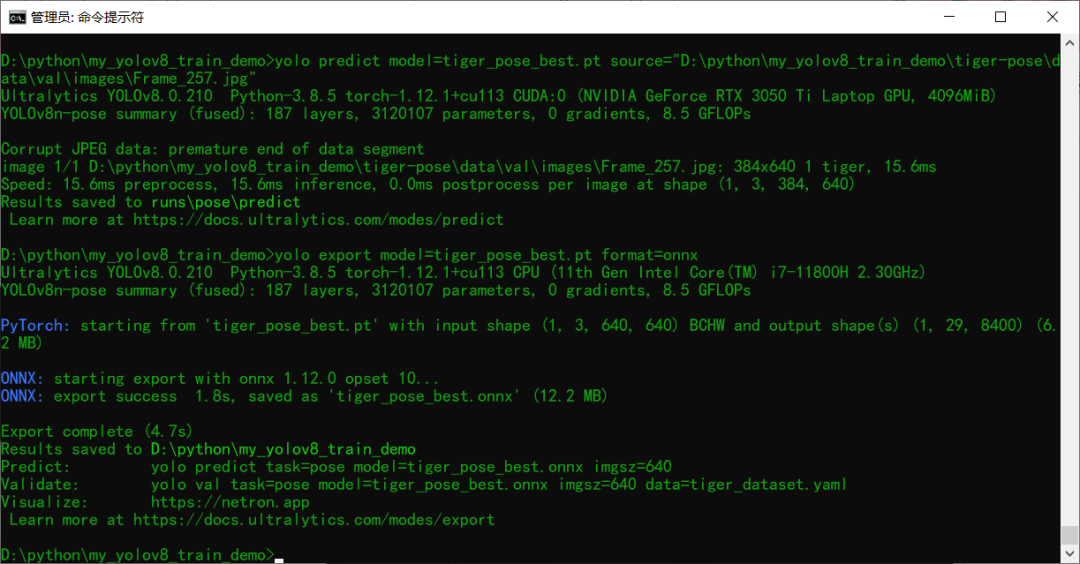
03模型導出預測
訓練完成以后模型預測推理測試 使用下面的命令行:
yolo predict model=tiger_pose_best.pt source=D:/123.jpg
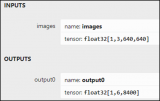
導出模型為ONNX格式,使用下面命令行即可
yolo export model=tiger_pose_best.pt format=onnx
04部署推理
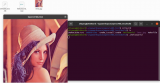
基于ONNX格式模型,采用ONNXRUNTIME推理結果如下:
ORT相關的推理演示代碼如下:
def ort_pose_demo():
# initialize the onnxruntime session by loading model in CUDA support
model_dir = "tiger_pose_best.onnx"
session = onnxruntime.InferenceSession(model_dir, providers=['CUDAExecutionProvider'])
# 就改這里, 把RTSP的地址配到這邊就好啦,然后直接運行,其它任何地方都不準改!
# 切記把 yolov8-pose.onnx文件放到跟這個python文件同一個文件夾中!
frame = cv.imread("D:/123.jpg")
bgr = format_yolov8(frame)
fh, fw, fc = frame.shape
start = time.time()
image = cv.dnn.blobFromImage(bgr, 1 / 255.0, (640, 640), swapRB=True, crop=False)
# onnxruntime inference
ort_inputs = {session.get_inputs()[0].name: image}
res = session.run(None, ort_inputs)[0]
# matrix transpose from 1x8x8400 => 8400x8
out_prob = np.squeeze(res, 0).T
result_kypts, confidences, boxes = wrap_detection(bgr, out_prob)
for (kpts, confidence, box) in zip(result_kypts, confidences, boxes):
cv.rectangle(frame, box, (0, 0, 255), 2)
cv.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), (0, 255, 255), -1)
cv.putText(frame, ("%.2f" % confidence), (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))
cv.circle(frame, (int(kpts[0]), int(kpts[1])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[2]), int(kpts[3])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[4]), int(kpts[5])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[6]), int(kpts[7])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[8]), int(kpts[9])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[10]), int(kpts[11])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[12]), int(kpts[13])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[14]), int(kpts[15])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[16]), int(kpts[17])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[18]), int(kpts[19])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[20]), int(kpts[21])), 3, (255, 0, 255), 4, 8, 0)
cv.circle(frame, (int(kpts[22]), int(kpts[23])), 3, (255, 0, 255), 4, 8, 0)
cv.imshow("Tiger Pose Demo - gloomyfish", frame)
cv.waitKey(0)
cv.destroyAllWindows()
審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規(guī)問題,請聯系本站處理。
舉報投訴
-
模型
+關注
關注
1文章
3178瀏覽量
48729 -
數據集
+關注
關注
4文章
1205瀏覽量
24649 -
命令行
+關注
關注
0文章
77瀏覽量
10382
原文標題:【YOLOv8】自定義姿態(tài)評估模型訓練
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
maixcam部署yolov5s 自定義模型
maixcam部署yolov5s 自定義模型
本博客將向你展示零基礎一步步的部署好自己的yolov5s模型(博主展示的是安全帽
發(fā)表于 04-23 15:43
YOLOv8自定義數據集訓練到模型部署推理簡析
如果你只是想使用而不是開發(fā),強烈推薦通過pip安裝方式獲取YOLOv8包!YOLOv8安裝命令行
TensorRT 8.6 C++開發(fā)環(huán)境配置與YOLOv8實例分割推理演示
對YOLOv8實例分割TensorRT 推理代碼已經完成C++類封裝,三行代碼即可實現YOLOv8對象檢測與實例分割模型推理,不需要改任何代碼即可支持
在AI愛克斯開發(fā)板上用OpenVINO?加速YOLOv8目標檢測模型
《在 AI 愛克斯開發(fā)板上用 OpenVINO 加速 YOLOv8 分類模型》介紹了在 AI 愛克斯開發(fā)板上使用 OpenVINO 開發(fā)套件部署并測評 YOLOv8 的分類模型,本文將

YOLOv8版本升級支持小目標檢測與高分辨率圖像輸入
YOLOv8版本最近版本又更新了,除了支持姿態(tài)評估以外,通過模型結構的修改還支持了小目標檢測與高分辨率圖像檢測。原始的YOLOv8
AI愛克斯開發(fā)板上使用OpenVINO加速YOLOv8目標檢測模型
《在AI愛克斯開發(fā)板上用OpenVINO加速YOLOv8分類模型》介紹了在AI愛克斯開發(fā)板上使用OpenVINO 開發(fā)套件部署并測評YOLOv8的分類模型,本文將介紹在AI愛克斯開發(fā)板

教你如何用兩行代碼搞定YOLOv8各種模型推理
大家好,YOLOv8 框架本身提供的API函數是可以兩行代碼實現 YOLOv8 模型推理,這次我把這段代碼封裝成了一個類,只有40行代碼左右,可以同時支持

三種主流模型部署框架YOLOv8推理演示
深度學習模型部署有OpenVINO、ONNXRUNTIME、TensorRT三個主流框架,均支持Python與C++的SDK使用。對YOLOv5~YOLOv8的系列模型,均可以通過C+
YOLOv8實現任意目錄下命令行訓練
當你使用YOLOv8命令行訓練模型的時候,如果當前執(zhí)行的目錄下沒有相關的預訓練模型文件,YOLOv8
基于YOLOv8的自定義醫(yī)學圖像分割
YOLOv8是一種令人驚嘆的分割模型;它易于訓練、測試和部署。在本教程中,我們將學習如何在自定義數據集上使用YOLOv8。但在此之前,我想告

如何基于深度學習模型訓練實現圓檢測與圓心位置預測
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現圓檢測與圓心位置預測,主要是通過對YOLOv8姿態(tài)

如何基于深度學習模型訓練實現工件切割點位置預測
Hello大家好,今天給大家分享一下如何基于深度學習模型訓練實現工件切割點位置預測,主要是通過對YOLOv8姿態(tài)

YOLOv8實現旋轉對象檢測
YOLOv8框架在在支持分類、對象檢測、實例分割、姿態(tài)評估的基礎上更近一步,現已經支持旋轉對象檢測(OBB),基于DOTA數據集,支持航拍圖像的15個類別對象檢測,包括車輛、船只、典型各種場地等。包含2800多張圖像、18W個實
YOLOv8+PyQT5打造細胞計數與識別應用說明
YOLOv8對象檢測模型基于自定義數據集訓練紅白細胞檢測模型,然后通過工具導出模型為ONNX,基
基于OpenCV DNN實現YOLOv8的模型部署與推理演示
基于OpenCV DNN實現YOLOv8推理的好處就是一套代碼就可以部署在Windows10系統、烏班圖系統、Jetson的Jetpack系統





 工商網監(jiān)
工商網監(jiān)
評論