 數獨、寄存器和相信的力量
數獨、寄存器和相信的力量
當人工智能 (AI) 下沉到各式各樣的應用當中,作為市場上最大量的物聯網設備也將被賦予智能性。ArmHelium 技術正是為基于Arm Cortex-M 處理器的設備帶來關鍵機器學習與數字信號處理的性能提升。
在上周的 Helium 技術講堂中,大家了解了 Helium 技術的核心“節拍式”執行。今天,我們將共同探討一些復雜而又有趣的交錯加載/存儲指令。若您想要了解如何高效利用 Helium,千萬別錯過文末視頻,通過 Arm 技術專家的實例演示,詳解 Helium 如何為端點設備引入更多智能。
Arm Helium 技術誕生的由來
數獨、寄存器和相信的力量
DSP 處理中一個重要部分就是對不同的數據格式進行高效處理,這些數據格式通常需要轉換成不同的排列方式進行計算。圖像數據就是一個很好的例子,它通常以紅、綠、藍和 alpha 像素值交錯流的形式被存儲。但是,為了將計算矢量化,就需要將所有紅色像素放在一個矢量中,綠色像素放在另一個矢量中,以此類推。在 Neon 架構中,VLD4/VST4 指令可以執行這種轉換,如下圖所示。
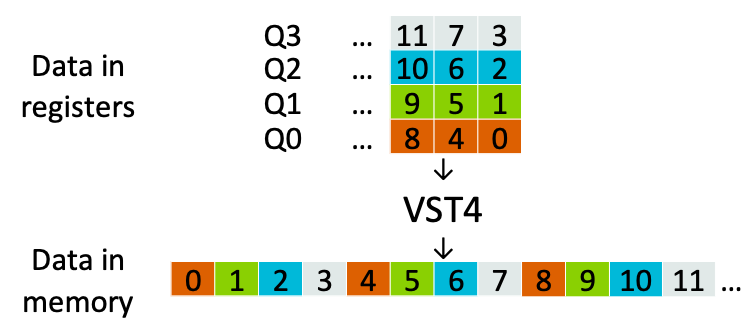
VST4 將四個 128 位寄存器交錯排列,共存儲 512 位數據。Neon 架構有多種交織/去交織運算,可支持不同的格式。例如,提供的 VST2 可用于交織立體聲音頻的左右聲道。這些指令還支持從 8 到 32 位不等的元素大小。
MVE 的“節拍式”執行的主要優點之一,是它允許內存和 ALU 運算重疊,即使在單發射處理器上也是如此。如下圖所示,基于此技術要實現性能的翻倍,所有指令必須執行相同的工作量。
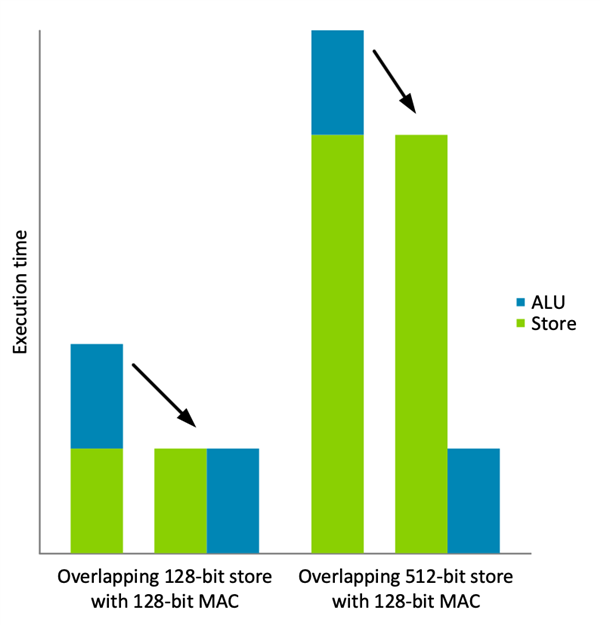
顯而易見,重疊帶來的性能提升會因 VST4 這樣的寬存儲指令而大打折扣。MVE 提供的解決方案是將存儲空間分割成與 ALU 運算相平衡的塊,每個塊存儲 128 位數據。MVE 允許由 VST40、VST41、VST42 和 VST43 這四條指令構成四路交織。但到此并未結束,仍有不少問題存在:
顯而易見的拆分方法是讓四條指令分別存儲不同的數據流(例如 VST40 存儲所有紅色像素,VST41 存儲綠色像素等)。對于 8 位像素數據,這意味著每條指令將存儲 16 個非連續字節。這種訪問模式對內存子系統來說非常復雜,會導致大量停滯。相反,指令需要生成大塊連續請求。
要正確配合其他矢量指令,必須將寄存器文件端口設置為訪問寄存器文件的行(即整個矢量寄存器),而不是列(即四個寄存器的第一個字節),如果要將數據交織存儲到連續內存塊中,則需要訪問列。
為了避免我在上一篇內容中描述的時間跨越問題,我們需要將指令分成幾個“節拍”,先讀取寄存器的 [63:0] 位,然后在下一個周期讀取 [127:64] 位。
解決方案必須同時適用于兩路交織和四路交織,以及 8、16 和 32 位數據運算。
面對所有這些相互矛盾的限制,我們就像掉進了兔子洞,我不禁想起了《愛麗絲夢游仙境》中的情節:
愛麗絲:這是不可能的。
瘋帽匠:只要你相信,一切皆有可能。
所以,讓我們暫且放下懷疑的態度,仔細研究一下讀取端口,看看會發生什么。
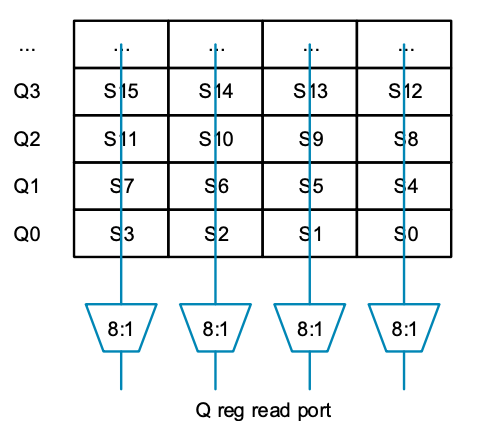
MVE 重復使用浮點寄存器文件,因此矢量寄存器(Q0 至 Q7)由每四個一組的若干組 “S” 寄存器組成。每個列多路復用器選擇相同的行,然后將數據合并以訪問整個 Q 寄存器(見上圖)。但是,如果不能從一列中的任何寄存器中選擇,而是將端口扭曲,從交替列中的寄存器中選擇,如下圖所示,會如何呢:
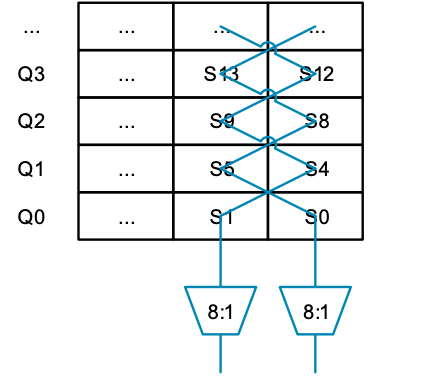
如果 8:1 多路復用器上的控制輸入設置為相同值,則可讀取一行數據(例如 S0 和 S1)。但是,如果使用不同的值,則可以讀取一列中的一對值(如 S0 和 S4)。現在看起來似乎可行,我們能夠從列和行中讀取數據。如果我們把圖的下面放大,并將寄存器編號替換為它們所連接的多路復用器的編號,就會得到下圖結果:
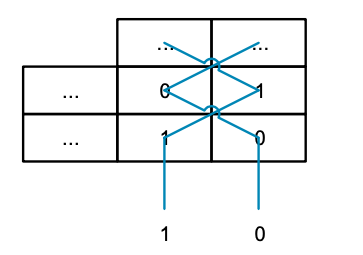
這類似于一道簡單的數獨謎題,在重復矩陣的每一行和每一列中,每個數字只會出現一次,只不過這個矩陣是 2 x 2 的,而不是平常的 9 x 9。由于只能從一列中讀取兩個值,并且只能處理 32 位值(多路復用器的寬度),因此這種模式只能提供兩路交織的解決方案。由于我們需要一種可處理所有交錯模式和數據寬度組合的模式,因此可想象將所有組合垂直堆疊起來,得到一個多分辨率的三維數獨謎題。解決一層謎題輕而易舉,但解決整個三維謎題的過程一定令人嘆為觀止。此外,我們還需要考慮上文提到的其他限制因素,如連續內存訪問,以及在不同周期內拆分對寄存器上下 64 位的訪問。
經過一番思索,我意識到可以將問題一分為二:一是確定一種可在單個統一的問題空間中表示全部約束的方法,二是解決這些約束的單調任務。由于該模式類似于一個非常復雜的數獨問題,而許多數獨程序都是基于 SAT 解算器的,因此我產生了使用 SAT 解算器來完成單調約束求解任務的想法。經過努力,我想出了一種能表示所有約束的方法,一番調試后,第一個可行的解決方案誕生了。雖然它不完善,而且會導致多路復用器的控制邏輯難以實施,但至少勝利在望了。由于不想對解決方案進行手動清理,我們添加了一些額外的約束條件,引入了一些對稱性,并產出了最終的解決方案,它竟然是一對雙嵌套四重螺旋結構:
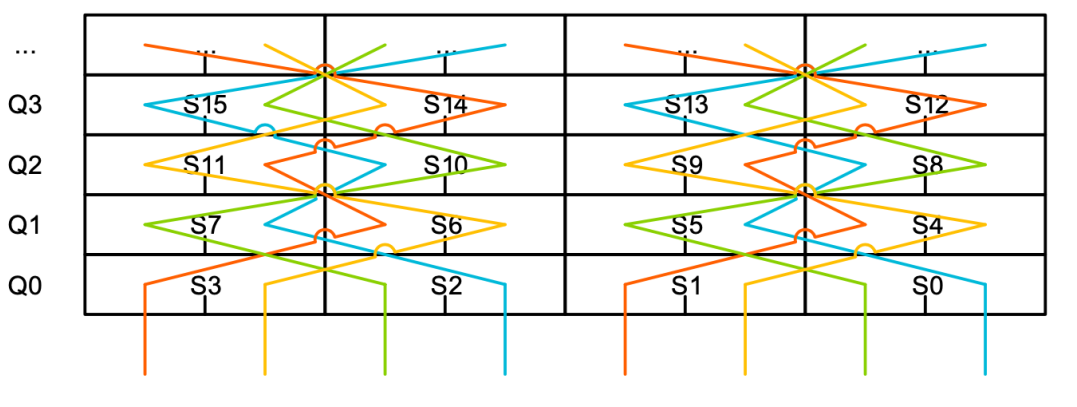
為了讓大家看到嵌套的螺旋線,我在下圖中標注了單個多路復用器的路徑。如圖所示,路徑每行交替通過 32 位 “S” 寄存器(如左圖所示),每兩行交換通過 “S” 寄存器上下兩半 16 位區域(如右圖所示)。
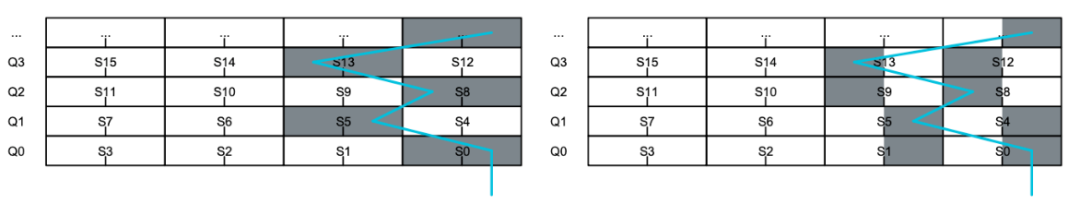
直覺告訴我,這種扭曲的方法對于三路交織來說是行不通的,經證實我是對的,SAT 解算器正式證明無解。
這種扭曲方法意味著可以同時訪問寄存器文件行和列中的數據。但問題在于,讀取端口返回的字節可能順序有誤,而順序取決于訪問的寄存器。要糾正此情況,就需要使用一個交叉多路復用器,將一切交換回正確的位置。由于如 VREV 等其他指令和復數原生操作指令會用到交叉多路復用器,所以我們正好能免費使用它。這正印證了那句話:“如果你必須使用一個硬件,請物盡其用。”
下圖顯示了由讀取端口扭曲模式衍生出的一些指令訪問模式。第一種情況 (VST2n.S32) 顯示從矢量寄存器 Q0 和 Q1 讀取 32 位 (S32),并將其兩路交織(如左右音頻通道)。圖中顏色代表兩條指令分別讀取的寄存器部分(即 VST20 讀取橙色部分),元素中的文字表示內存中存儲的字節偏移。

可以發現,上述 S8 和 S16 模式都將相同的數據放在寄存器的相同顏色區域內;唯一不同的是每節中字節的排列方式。這意味著,只需在交叉多路復用器中使用不同的配置,16 位模式也能支持 8 位。這些模式也適用于加載指令所使用的寫入端口。除了可以建立寄存器文件端口外,這些模式還意味著內存訪問始終是一對 64 位的連續塊,這樣可以提高內存訪問的效率。另外,這些數據塊地址的第 [3] 位總是不同的,因此可以在擁有兩組交織 64 位內存的系統上并行發送。
研究團隊從這些指令中積累了兩條重要的經驗。首先,要想在 gate 數量和效率方面取得突破式進展,就必須在設計架構的同時對微架構的細節同步思考設計。其次,要保持信念,相信一切皆有可能。
您是否想要更深入了解 Helium 技術?由 Arm 物聯網事業部技術管理總監 Mark Quartermain 與 Arm 物聯網事業部嵌入式工具集成高級經理 Matthias Hertel 共同為大家錄制了 Helium 技術視頻,通過實例演示詳解如何高效利用 Helium。
我們將在下一篇 Helium 文章中繼續探討以內存訪問為主題的相關內容,并介紹一些實現循環緩沖的技術知識。持續關注 Helium 技術講堂,我們下期再見!
-
ARM
+關注
關注
134文章
9046瀏覽量
366817 -
寄存器
+關注
關注
31文章
5317瀏覽量
120008 -
機器學習
+關注
關注
66文章
8377瀏覽量
132409
原文標題:Helium 技術講堂 | 數獨、寄存器和相信的力量
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
寄存器間接尋址和寄存器尋址的區別
寄存器的類型和作用
寄存器故障分析
寄存器是什么意思?寄存器是如何構成的?
寄存器尋址和直接尋址的區別
寄存器尋址的實現方式
寄存器分為基本寄存器和什么兩種
移位寄存器右移是怎么移位的

寄存器屬于時序邏輯電路嗎 寄存器是什么邏輯電路
CPU的6個主要寄存器
移位寄存器可降低LED設計的尺寸和成本
移位寄存器的工作原理 移位寄存器左移和右移怎么算
寄存器陣列低功耗設計方案
寄存器查看器的功能和使用






 工商網監
工商網監
評論