") 帶分區(qū)的大規(guī)模LDAP介紹
帶分區(qū)的大規(guī)模LDAP介紹
介紹
LDAP是一個常見的目錄信息源;該協(xié)議的第一個版本是在1993年編纂的。它通常用于各種應(yīng)用,包括管理Linux實例的用戶/組信息,以及控制VPN和傳統(tǒng)應(yīng)用的認(rèn)證。
傳統(tǒng)上,公司的LDAP服務(wù)器是在內(nèi)部運行的;通常是微軟的ActiveDirectory的一部分,或者是開放源碼OpenLDAP項目的一個部署。現(xiàn)在,SaaS供應(yīng)商可以提供LDAP支持;包括Foxpass,它是第一個從頭開始建立一個多用戶、以云為中心的LDAP實施的云LDAP供應(yīng)商。
簡單介紹一下:LDAP通常有以下基元:綁定、搜索、比較和添加。在創(chuàng)建一個TCP連接后,應(yīng)用程序首先需要通過發(fā)送一個用戶名和密碼進(jìn)行綁定。一旦綁定成功,客戶端將向LDAP服務(wù)器發(fā)出命令;通常是與過濾器一起的搜索命令。TCP連接一直保持到客戶端或服務(wù)器斷開連接。
Foxpass的LDAP
在Foxpass,我們的LDAP服務(wù)是在Twisted之上編寫的,Twisted是一種流行的基于事件的Python服務(wù)框架。該服務(wù)托管在 AWS的ECS平臺上,運行在數(shù)十個容器(節(jié)點)上。由于 LDAP連接是持久的,因此集群必須能夠同時維護數(shù)十萬個TCP會話。
我們將客戶的數(shù)據(jù)保存在RAM中。這樣做的原因是多方面的。首先,數(shù)據(jù)集相對較小,即使對于大客戶也是如此。其次,LDAP查詢語言允許搜索任意字段(這很重要,因為Foxpass允許自定義字段)。這意味著傳統(tǒng)的 RDBMS系統(tǒng)將無法構(gòu)建有效的索引,我們必須將數(shù)據(jù)轉(zhuǎn)換為不同的內(nèi)存表示形式。第三,將數(shù)據(jù)保存在 RAM中可以實現(xiàn)最快的響應(yīng)時間:延遲通常在100毫秒左右(見圖a)。
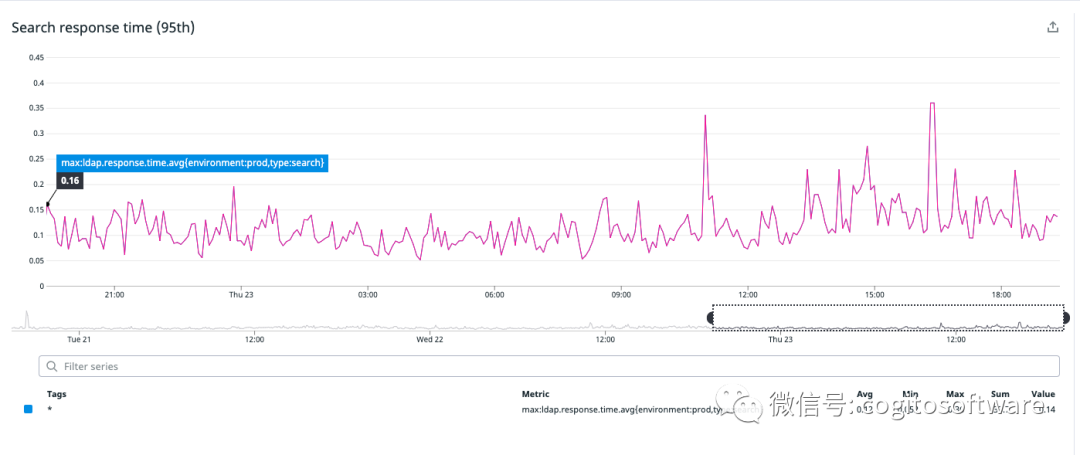 |
| 圖a:“搜索”命令的第95個百分位響應(yīng)時間 |
這種方法的一個缺點是緩存失效。當(dāng)客戶的數(shù)據(jù)發(fā)生變化時(例如,添加或刪除用戶),LDAP節(jié)點必須從我們的主RDBMS刷新它們的數(shù)據(jù)。在我們之前的架構(gòu)中,這是一個相對昂貴的操作;當(dāng)每個節(jié)點刷新同一家公司的數(shù)據(jù)時,它可能會導(dǎo)致LDAP延遲和后備存儲負(fù)載出現(xiàn)明顯的峰值。
延遲敏感性挑戰(zhàn)
如上所述,由于延遲要求,每個容器都將所有客戶的數(shù)據(jù)存儲在內(nèi)存中(見圖a)。當(dāng)請求到達(dá)一個節(jié)點時(如果它尚未存在),數(shù)據(jù)將按需獲取,然后只要來自該客戶的至少一個連接存在,數(shù)據(jù)就會一直存在。
由于傳入的連接請求可以到達(dá)任何容器(通過負(fù)載均衡器),因此提供查詢的容器也會加載和存儲客戶的所有數(shù)據(jù)。隨后,容器向 redispubsub 服務(wù)注冊以接收失效消息。當(dāng)公司數(shù)據(jù)發(fā)生更新時,將廣播無效信號,接收節(jié)點會清除該公司的數(shù)據(jù)緩存,并轉(zhuǎn)到數(shù)據(jù)庫重新獲取公司數(shù)據(jù)。隨著我們不斷發(fā)展并將新客戶添加到我們的系統(tǒng)中,這對擴展我們的LDAP服務(wù)提出了以下挑戰(zhàn):
跨所有節(jié)點(N)的客戶(M)的所有數(shù)據(jù)都需要在失效時重新加載。盡管實際上并非每個節(jié)點都承載來自每個客戶的連接,但在最壞的情況下,會對數(shù)據(jù)庫進(jìn)行MxN次調(diào)用以刷新數(shù)據(jù)。隨著更多客戶的添加 (M),數(shù)據(jù)庫提取的數(shù)量會增加N倍。這也意味著,為了不讓數(shù)據(jù)庫機器不堪重負(fù),需要額外的數(shù)據(jù)庫讀取器實例來處理請求的激增。
由于跨客戶(M)的所有數(shù)據(jù)都存儲在跨多個節(jié)點(N)的內(nèi)存中,因此所有節(jié)點的內(nèi)存繼續(xù)增加,并與客戶數(shù)量(M)成比例。這也意味著容器的內(nèi)存需求必須增長以容納內(nèi)存中的所有數(shù)據(jù),這反過來又增加了整體基礎(chǔ)設(shè)施成本。
上述挑戰(zhàn)非常明顯,讓我們傾向于跨節(jié)點分布客戶數(shù)據(jù),而不是在每個節(jié)點上復(fù)制所有客戶的數(shù)據(jù)。這使我們找到了分布式緩存管理解決方案。
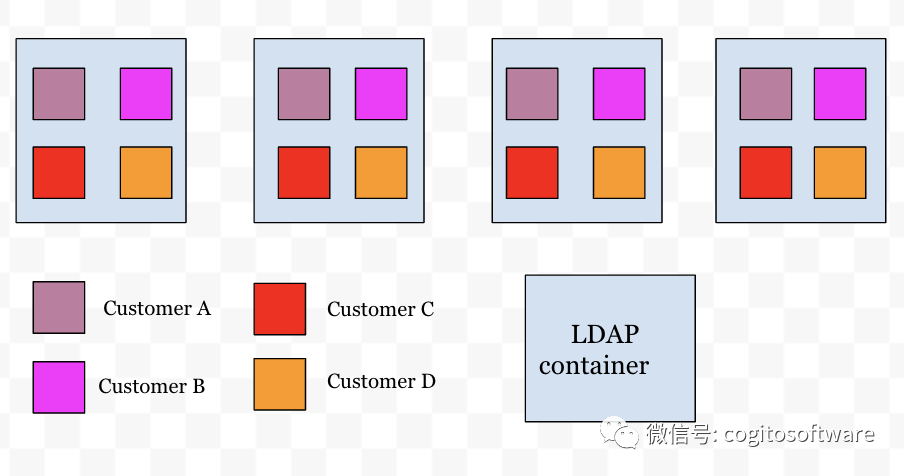 |
| 圖a |
分布式緩存管理
我們在LDAP服務(wù)中引入了一個智能路由層,如果連接所在的容器未托管數(shù)據(jù),該層會將請求轉(zhuǎn)發(fā)到托管客戶數(shù)據(jù)的節(jié)點。為實現(xiàn)這一目標(biāo),我們縮小了路由層的以下設(shè)計要求:
客戶需要在添加時動態(tài)分布在節(jié)點之間。
客戶的數(shù)據(jù)需要隨著節(jié)點收縮、擴展和節(jié)點故障而動態(tài)分布
能夠增加和減少特定客戶的分區(qū)數(shù)量,以便流量不平衡不會壓倒任何單個節(jié)點。
我們引入了ApacheHelix,它可以跨實例分配資源。Helix控制器是helix生態(tài)系統(tǒng)的大腦。當(dāng)添加或刪除節(jié)點或客戶時,它會跨節(jié)點做出資源分配決策。我們對 ApacheHelix 控制器、Rest服務(wù)器進(jìn)行了docker化,并將其部署在ECS上。Helix控制器依賴于Zookeeper來監(jiān)聽集群的變化。我們實施了一種在 ECS上部署Zookeeper的可靠方法。Helix和Zookeeper的整個基礎(chǔ)架構(gòu)都運行在ECS上。
每個LDAP節(jié)點都與Zookeeper交互以注冊自己以加入集群。每個 LDAP實例作為Helix參與者出現(xiàn),參與集群以由Helix控制器進(jìn)行客戶到節(jié)點的分配。當(dāng) LDAP節(jié)點動態(tài)創(chuàng)建新客戶時,該客戶的分區(qū)數(shù)(每個分區(qū)代表一個托管數(shù)據(jù)的節(jié)點)根據(jù)用戶數(shù)確定。通過這種集成,我們的 LDAP節(jié)點可以了解集群中發(fā)生的事件,即添加新客戶或可用節(jié)點集發(fā)生變化時。
有了這種集群意識,我們LDAP服務(wù)中的路由層提供了節(jié)點和客戶之間的映射。現(xiàn)在每個傳入連接都將通過路由層來決定連接必須路由到哪個節(jié)點。這樣,客戶的數(shù)據(jù)就會分配給特定的節(jié)點(見圖 b)。
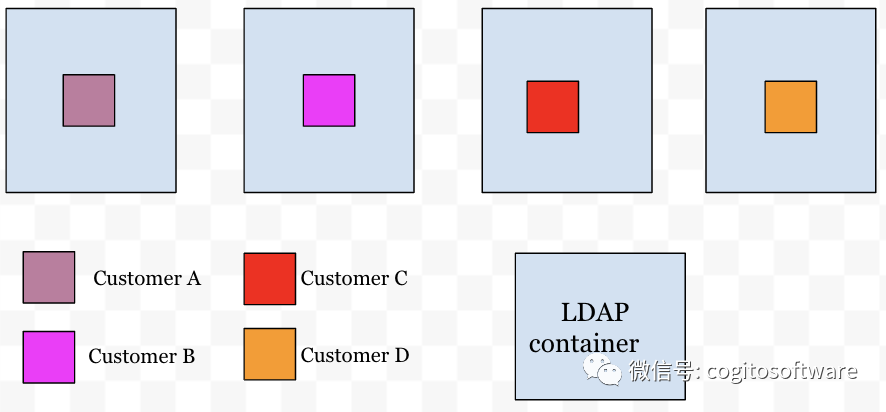 |
| 圖b |
路由層托管一個緩存,其中包含客戶和節(jié)點的路由信息。路由層監(jiān)視任何客戶到節(jié)點的分配更改,并在檢測到更改時立即更新。這樣,每個 LDAP節(jié)點都會在客戶到節(jié)點的更改發(fā)生時立即意識到它們。通過上述緩存管理解決方案,解決了延遲敏感性挑戰(zhàn)部分中提到的可擴展性挑戰(zhàn):
我們現(xiàn)在的客戶分布在各個節(jié)點上。每個節(jié)點將僅托管一部分客戶,并負(fù)責(zé)在收到 pubsub無效時僅獲取一部分客戶數(shù)據(jù)。這顯著減少了對數(shù)據(jù)庫的讀取次數(shù),無需添加數(shù)據(jù)庫讀取器節(jié)點來處理大量數(shù)據(jù)庫讀取。LDAP集群現(xiàn)在比以前減少了75%的數(shù)據(jù)庫讀取。
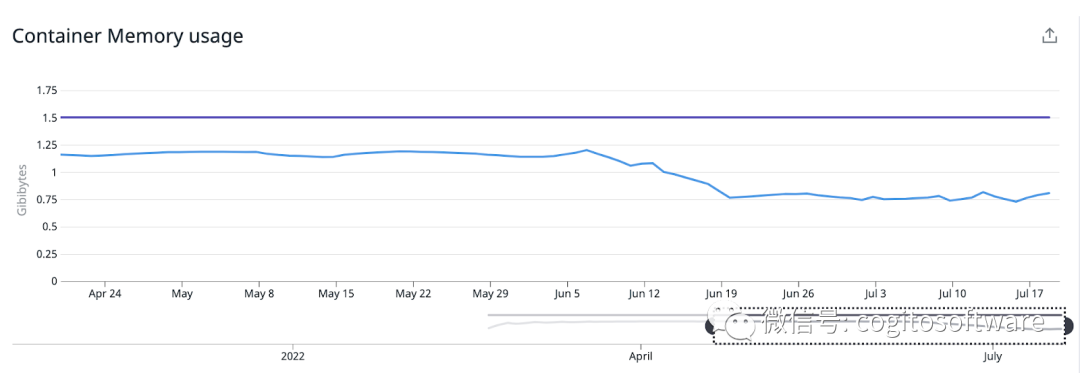
我們還提高了內(nèi)存效率,因為我們沒有將所有客戶(M)數(shù)據(jù)存儲在所有節(jié)點(N)的內(nèi)存中。這種架構(gòu)提供了水平擴展的能力,而無需增加實例大小。每個 LDAP節(jié)點現(xiàn)在消耗的內(nèi)存比以前減少了40%。
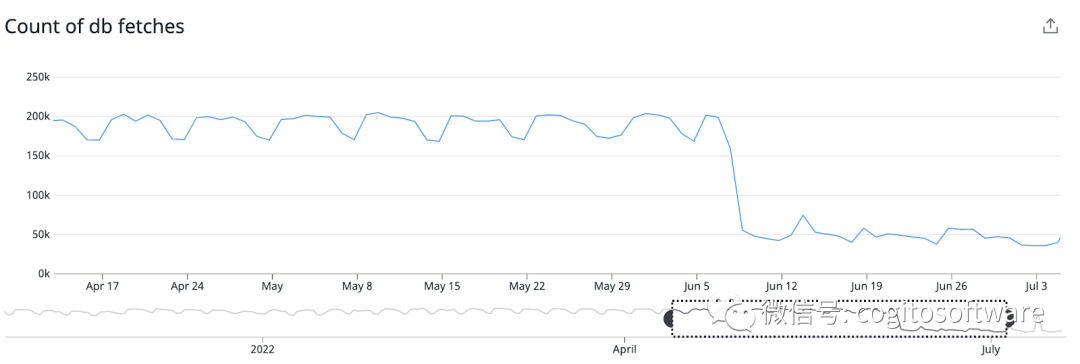 |
 |
當(dāng)前的挑戰(zhàn)
對于上述實現(xiàn),挑戰(zhàn)之一是節(jié)點接收到不相等數(shù)量的TCP連接。與其他節(jié)點相比,這種分布不平衡會導(dǎo)致某些節(jié)點(熱節(jié)點)上的CPU使用率更高。但是與以前相比,節(jié)點間的平均整體 CPU利用率仍然保持不變。
審核編輯:劉清
-
TCP
+關(guān)注
關(guān)注
8文章
1351瀏覽量
78999 -
過濾器
+關(guān)注
關(guān)注
1文章
427瀏覽量
19563 -
python
+關(guān)注
關(guān)注
56文章
4783瀏覽量
84473 -
RDBMS
+關(guān)注
關(guān)注
0文章
9瀏覽量
5835 -
LDAP
+關(guān)注
關(guān)注
0文章
9瀏覽量
7657
原文標(biāo)題:LDAP:帶分區(qū)的大規(guī)模LDAP
文章出處:【微信號:哲想軟件,微信公眾號:哲想軟件】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論