 Spectrum 2023年熱門故事: AI啟示錄、ChatGPT幻覺、英偉達的成功等
Spectrum 2023年熱門故事: AI啟示錄、ChatGPT幻覺、英偉達的成功等
來源:IEEE Spectrum
2023年很可能會作為人工智能歷史上最瘋狂、最戲劇性的年份之一載入史冊。2022年年底OpenAI推出了ChatGPT,當人們還在努力了解OpenAI ChatGPT的強大功能時,該公司又于2023年3月發布了最新的大型語言模型GPT-4(大型語言模型本質上是面向消費者的應用程序背后的大腦)。
2023年整個春季,一些權威專業人士都對不斷改進的人工智能可能帶來的負面后果感到擔憂,即這些后果從令人不安到對生存造成的影響等。首先是一封公開信,呼吁暫停先進模型的開發,然后是一份關于存在風險的聲明、首屆人工智能安全國際峰會,以及美國行政命令和歐盟人工智能法案等具有里程碑意義的法規。
以下是Spectrum 2023年關于人工智能的前10篇文章,文章順序根據讀者閱讀時間排列。一起來品味閱讀可能會載入史冊的2023年人工智能吧……除非2024年更加瘋狂。
10.人工智能藝術生成器可能被濫用制作NSFW圖像
利用Dall-E 2和Stable Diffusion等文本到圖像生成器,用戶輸入描述他們想要生成的圖像的提示,模型就會完成剩下的工作。雖然他們有保護措施來防止用戶生成暴力、色情和其他不可接受的圖像,但人工智能研究人員和黑客都樂于找出如何規避這些保護措施的方法。對于白帽子和黑帽子來說,破解是新的愛好。
9. OpenAI的Moonshot:解決AI價值對齊問題
OpenAI的Jan Leike的問答深入探討了AI價值對齊問題。一些人擔心,人類可能會建立超級智能的人工智能系統,這種系統的目標與人類的目標不一致,從而可能導致人類物種的滅絕。這確實是一個重要的問題,OpenAI正在投入大量資源尋找方法來對尚不存在的問題進行實證研究(因為超級智能AI系統尚不存在)。
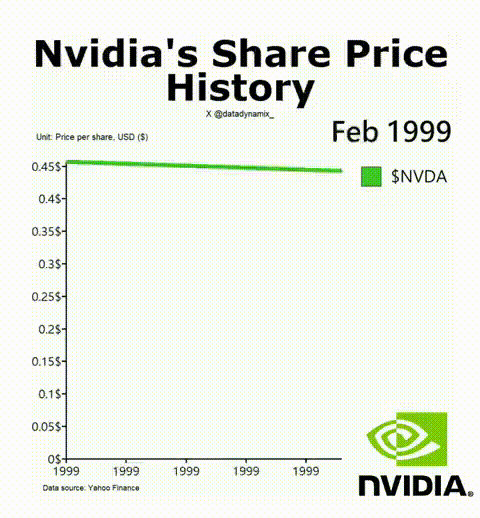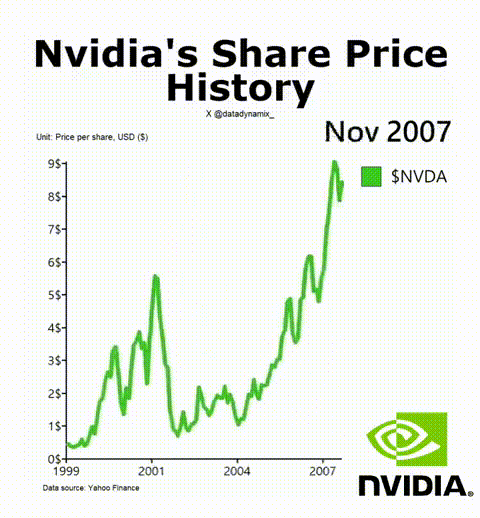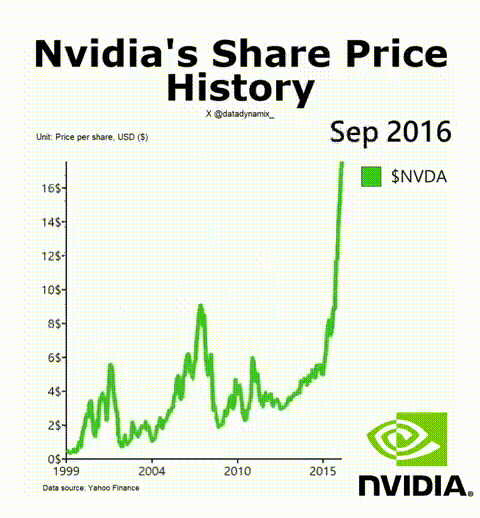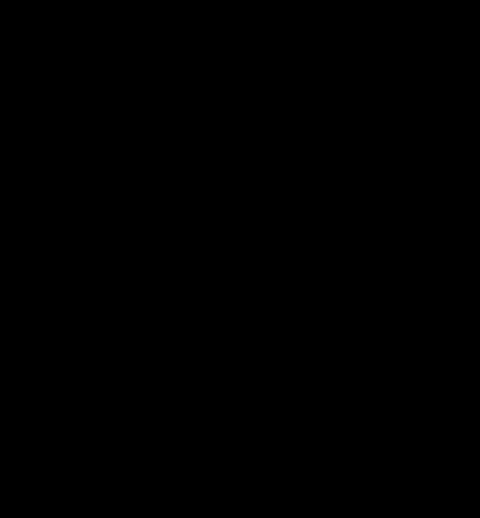
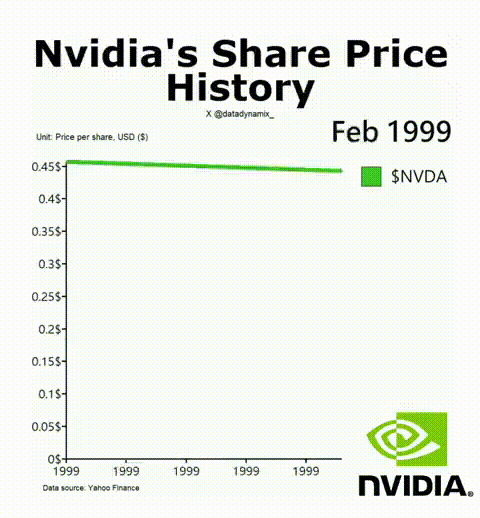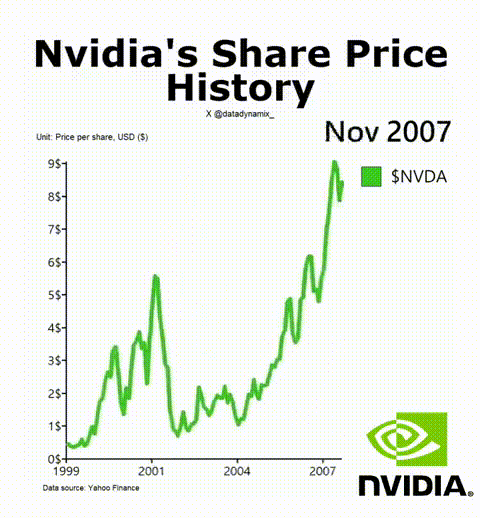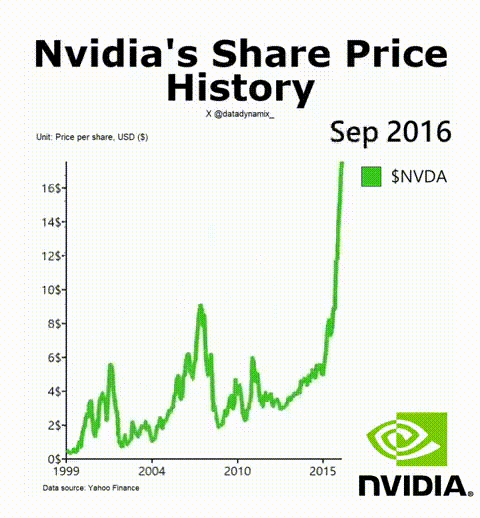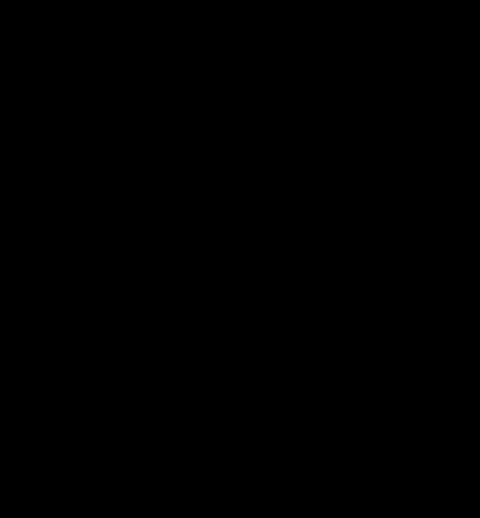
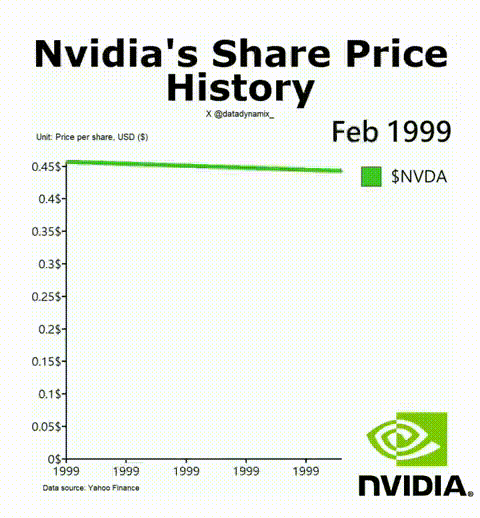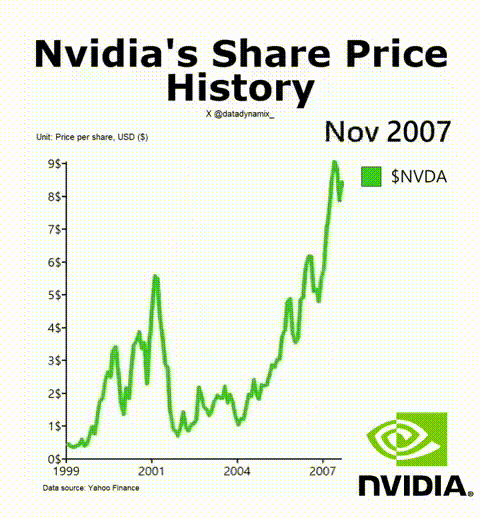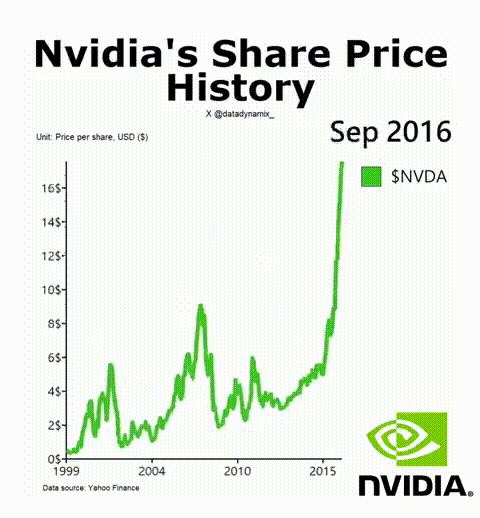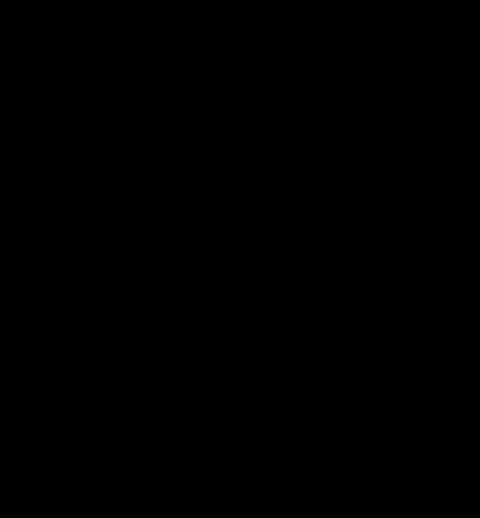
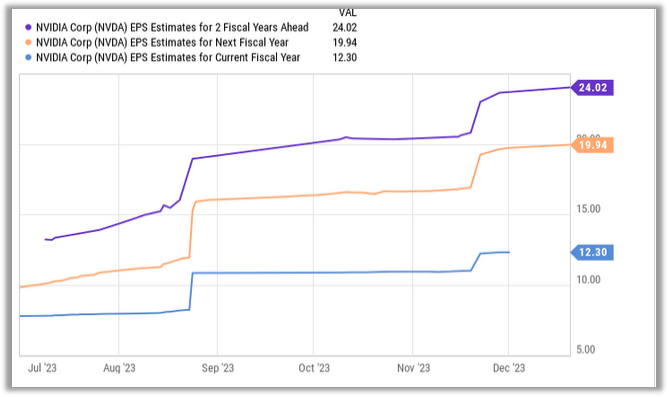
8. 英偉達成功的秘訣
英偉達AI加速GPU讓其迎來了美好的一年,其H-100無疑成為了科技領域最熱門的硬件。該公司的首席科學家Bill Dally在一次會議上反思了推動英偉達邁入頂層的四種要素。IEEE Spectrum高級編輯Sam Moore寫道:“摩爾定律只是英偉達魔法中令人驚訝的一小部分,而新的數字格式則占很大一部分。”
7. ChatGPT的幻覺可能會阻礙其成功
困擾大型語言模型的一個問題是他們編造事實的習慣——用最自信的語氣說出不可預測的謊言。當人們試圖將其用于真正重要的事情(例如撰寫法律摘要)時,這種習慣就會成為一個特殊的問題。OpenAI認為這是一個可以解決的問題,而一些外部專家(例如Meta AI的Yann LeCun)則不同意。
6. 圖表中對2023年人工智能狀況的十大重要見解
這是列表中的列表!每年,Spectrum編輯都會對斯坦福以人為本的人工智能研究所發布的海量人工智能指數進行分析,將報告提煉成幾張反映最重要趨勢的圖表。2023年的亮點包括訓練大型模型的成本和能源需求,以及在招聘博士和構建模型方面工業界相對于學術界的主導地位。
5.令人毛骨悚然的新型數字來世產業
以下摘錄自Wendy H. Wong所著的《我們,便是數據》(We, the Data)一書。這段摘錄對作為新型數字來世行業的一部分而出現的服務進行了深入研究:一些公司會在您去世后,代表您發送消息,另一些公司則允許您記錄故事,其他人可以在以后通過提問來回放。已經有一些例子表明人們根據已故親人留下的數據構建他們的數字復制品。
4. 人工智能啟示錄:記分卡
這個項目是在Spectrum編輯討論真正智能的人工智能方面的從業者(在該領域工作了數十年的人)對兩個重要問題持如此截然不同的觀點是多么令人驚訝時產生的。也就是說,今天的大型語言模型是否預示著人工智能將很快實現超人的智能,而這種超級智能的人工智能系統是否會為智人帶來厄運?為了幫助讀者了解意見的范圍,我們制作了一個記分卡。
3. 200年歷史的數學打開了人工智能的神秘黑匣子
眾所周知,為當今人工智能提供動力的神經網絡都是黑匣子。研究人員為他們提供訓練數據并查看結果,但對中間發生的情況并沒有太多了解。一組從事流體動力學研究的研究人員決定使用傅立葉分析(一種數學技術用于識別已經存在了大約200年的模型)來研究經過訓練來預測湍流的神經網絡。
2. 多鄰國的AI如何學習您需要學習的內容
本文是Spectrum標志性的深入研究之一,是由構建該技術的專家撰寫的專題文章。在本例中,它是語言學習應用程序多鄰國背后的人工智能團隊。他們解釋了如何開發人工智能系統Birdbrain,它利用教育心理學和機器學習來向用戶提供難度適中的課程,以保持用戶的參與度。
1. GPT-4熱度已經降下來了
Spectrum讀者都有逆向思維,因此非常喜歡Rodney Brooks的問答,他自稱是人工智能懷疑論者,在該領域工作了數十年。Brooks并沒有稱贊GPT-4是邁向通用人工智能的一步,而是提請注意大型語言模型在從一項任務推廣到另一項任務方面的困難。他表示,“大型語言模型擅長的是說出聽起來應該是什么樣子的答案,但這與應該是什么的答案不同”。
審核編輯 黃宇
-
AI
+關注
關注
87文章
30146瀏覽量
268411 -
英偉達
+關注
關注
22文章
3747瀏覽量
90833 -
ChatGPT
+關注
關注
29文章
1548瀏覽量
7493
發布評論請先 登錄
相關推薦
【書籍評測活動NO.49】大模型啟示錄:一本AI應用百科全書



英偉達首席執行官黃仁勛:AI模型推動英偉達AI芯片需求
“網紅”芯片Groq讓英偉達蒸發5600億





 工商網監
工商網監
評論