") 如何在不微調(diào)的情況下提高RAG的準(zhǔn)確性?
如何在不微調(diào)的情況下提高RAG的準(zhǔn)確性?
數(shù)據(jù)科學(xué)家、AI 工程師、MLOps 工程師和 IT 基礎(chǔ)設(shè)施專業(yè)人員在設(shè)計(jì)和部署檢索增強(qiáng)生成(RAG)工作流時(shí),必須考慮各項(xiàng)因素,比如大語(yǔ)言模型(LLM) 核心組件以及評(píng)估方法等等。
這是由于 RAG 是一個(gè)系統(tǒng),而不僅僅是一個(gè)或一組模型。該系統(tǒng)由若干階段組成,RAG 101:揭秘檢索增強(qiáng)生成工作流一文對(duì)這些階段進(jìn)行了深入討論。在這些階段中,您都可以根據(jù)需求做出設(shè)計(jì)決策。
以下是一些常見(jiàn)問(wèn)題與回答:
何時(shí)應(yīng)微調(diào) LLM?何時(shí)又該使用 RAG?
在 LLM 的世界里,您可以根據(jù)應(yīng)用的具體需求和限制,為 LLM 選擇微調(diào)、參數(shù)有效微調(diào)(PEFT)、提示工程或 RAG。
微調(diào)通過(guò)使用特定領(lǐng)域的數(shù)據(jù)集,更新模型大部分或全部參數(shù),從而定制一個(gè)專門用于特定領(lǐng)域的預(yù)訓(xùn)練 LLM。這種方法需要耗費(fèi)大量資源,但能為專門的用例提供很高的準(zhǔn)確性。
PEFT 側(cè)重于模型的一個(gè)子集,因此只需更新較少的參數(shù)就能修改預(yù)訓(xùn)練 LLM。該方法平衡了準(zhǔn)確性與資源使用,在數(shù)據(jù)和計(jì)算需求可控的情況下,為提示工程提供改進(jìn)。
提示工程在不改變模型參數(shù)的情況下,通過(guò)操縱 LLM 的輸入來(lái)引導(dǎo)模型輸出。這是一種最節(jié)省資源的方法,適用于數(shù)據(jù)和計(jì)算資源有限的應(yīng)用。
RAG 利用外部數(shù)據(jù)庫(kù)中的信息增強(qiáng)了 LLM 提示功能,它本質(zhì)上是一種復(fù)雜的提示工程。
使用哪種技術(shù)并不是關(guān)鍵,實(shí)際上,這些技術(shù)可以串聯(lián)使用。例如,可以將 PEFT 集成到 RAG 系統(tǒng)中,以進(jìn)一步完善 LLM 或嵌入模型。使用哪種方法最好取決于應(yīng)用的具體要求,同時(shí)還要兼顧準(zhǔn)確性、資源可用性和計(jì)算限制。
如要進(jìn)一步了解用于提高特定領(lǐng)域準(zhǔn)確性的自定義技術(shù),請(qǐng)參閱選擇大語(yǔ)言模型自定義技術(shù):https://developer.nvidia.com/blog/selecting-large-language-model-customization-techniques/
使用 LLM 構(gòu)建應(yīng)用程序時(shí),首先要使用 RAG,借助外部信息提升模型的響應(yīng)性。這種方法可以快速提高相關(guān)性和深度。
之后,如果您需要提高特定領(lǐng)域的準(zhǔn)確性,可以采用前面所述的模型自定義技術(shù)。該流程分為兩步,既能夠借助 RAG 進(jìn)行快速部署和通過(guò)模型定制實(shí)現(xiàn)有針對(duì)性的改進(jìn),又兼顧了高效開(kāi)發(fā)和持續(xù)改進(jìn)策略。
如何在不微調(diào)的情況下提高 RAG 的準(zhǔn)確性?
簡(jiǎn)而言之,在利用 RAG 的企業(yè)解決方案中,獲得準(zhǔn)確性是至關(guān)重要的,而微調(diào)只是一種可能提高 RAG 系統(tǒng)準(zhǔn)確性的技術(shù),反之亦然。
首先,也是最重要的一點(diǎn),是找到一種衡量 RAG 準(zhǔn)確性的方法。在起點(diǎn)都不清楚的情況下,改進(jìn)又從何談起?目前有幾個(gè)評(píng)估 RAG 系統(tǒng)的框架,如 Ragas、ARES 和 Bench 等。
在對(duì)準(zhǔn)確性進(jìn)行評(píng)估后,就可以在無(wú)需進(jìn)行微調(diào)的情況下,通過(guò)多種途徑來(lái)提高準(zhǔn)確性。
雖然這聽(tīng)起來(lái)很麻煩,但首先要檢查并確保您的數(shù)據(jù)被正確解析和加載。例如,當(dāng)文檔包含表格甚至圖像時(shí),某些數(shù)據(jù)加載器可能會(huì)遺漏文檔中的信息。
在攝取數(shù)據(jù)后,要對(duì)其進(jìn)行分塊,也就是將文本分割成片段的過(guò)程。分塊可以是固定長(zhǎng)度的字符,但也有許多種其他的分塊方法,如句子分割和遞歸分塊等。文本的分塊方式?jīng)Q定了如何將其存儲(chǔ)在嵌入向量中以便檢索。
除此之外,還有許多索引和相關(guān)檢索模式。例如,可以為不同類型的用戶問(wèn)題構(gòu)建多個(gè)索引、可以根據(jù) LLM 將用戶查詢引導(dǎo)至相應(yīng)的索引等。
檢索策略也是多種多樣的。最基本的策略是利用索引的余弦相似性,BM25、自定義檢索器或知識(shí)圖也可以用來(lái)提高檢索效率。
根據(jù)特殊要求,對(duì)檢索結(jié)果進(jìn)行重新排序也可以提高靈活性和準(zhǔn)確性。查詢轉(zhuǎn)換可以很好地分解更加復(fù)雜的問(wèn)題。即使只是改變 LLM 的系統(tǒng)提示,也能極大地提高準(zhǔn)確性。
歸根結(jié)底,重要的是要花時(shí)間進(jìn)行試驗(yàn),并衡量各種方法所產(chǎn)生的準(zhǔn)確性變化。
像 LLM 或嵌入模型這樣的模型只是 RAG 系統(tǒng)的一部分。有很多方法可以在不需要進(jìn)行任何微調(diào)的情況下改進(jìn) RAG 系統(tǒng),使其達(dá)到更高的準(zhǔn)確性。
如何將 LLM 連接到數(shù)據(jù)源?
有多種框架可以將 LLM 連接到數(shù)據(jù)源,如 LangChain 和 LlamaIndex 等。這些框架提供評(píng)估程序庫(kù)、文檔加載器、查詢方法等各種功能,新的解決方案也層出不窮。建議您先了解各種框架,然后選擇最適合您應(yīng)用的軟件和軟件組件。
RAG 能否列出檢索數(shù)據(jù)的來(lái)源?
可以。列出檢索數(shù)據(jù)的來(lái)源能夠改善用戶體驗(yàn)。在 GitHub 資源庫(kù)中的 /NVIDIA/GenerativeAIExamples 的 AI 聊天機(jī)器人 RAG 工作流示例中
RAG 需要哪類數(shù)據(jù)?如何確保數(shù)據(jù)安全?
目前,RAG 支持文本數(shù)據(jù)。隨著多模態(tài)用例研究的深入,RAG 系統(tǒng)對(duì)圖像和表格等其他形式數(shù)據(jù)的支持也在不斷改進(jìn)。您可能需要根據(jù)數(shù)據(jù)及其位置編寫(xiě)額外的數(shù)據(jù)預(yù)處理工具。LlamaHub 和 LangChain 提供了多種數(shù)據(jù)加載器。如要進(jìn)一步了解如何使用鏈構(gòu)建強(qiáng)化管線,請(qǐng)參閱保護(hù) LLM 系統(tǒng)不受提示注入的影響:https://developer.nvidia.com/zh-cn/blog/securing-llm-systems-against-prompt-injection/
確保數(shù)據(jù)安全對(duì)企業(yè)來(lái)說(shuō)是至關(guān)重要的。例如,某些索引數(shù)據(jù)可能只針對(duì)特定用戶。基于角色的訪問(wèn)控制(Role-based access control, RBAC)可以根據(jù)角色來(lái)限制對(duì)系統(tǒng)的訪問(wèn),從而實(shí)現(xiàn)數(shù)據(jù)訪問(wèn)控制。比如,在向矢量數(shù)據(jù)庫(kù)發(fā)出請(qǐng)求時(shí),可以使用用戶會(huì)話 token,這樣就不會(huì)返回超出該用戶權(quán)限范圍的信息。
許多用于保護(hù)環(huán)境中模型的術(shù)語(yǔ),與用于保護(hù)數(shù)據(jù)庫(kù)或其他關(guān)鍵資產(chǎn)的術(shù)語(yǔ)相同。您需要考慮您的系統(tǒng)將如何記錄生產(chǎn)管線產(chǎn)生的活動(dòng)(提示輸入、輸出和錯(cuò)誤結(jié)果)。雖然這些活動(dòng)可以為產(chǎn)品的訓(xùn)練和改進(jìn)提供豐富的數(shù)據(jù)集,但它們同時(shí)也是 PII 等數(shù)據(jù)泄漏的來(lái)源,因此必須像管理模型管線本身一樣謹(jǐn)慎管理。
人工智能模型有許多常見(jiàn)的云部署模式。您應(yīng)該充分利用 RBAC、速率限制等工具以及此類環(huán)境中常見(jiàn)的其他控制措施,來(lái)提高 AI 部署的穩(wěn)健性。模型只是這些強(qiáng)大管線中的一個(gè)元素。
與終端用戶的交互性質(zhì)是所有 LLM 部署的工作重點(diǎn)之一。RAG 管線大部分都圍繞自然語(yǔ)言輸入和輸出。您應(yīng)該考慮如何通過(guò)輸入/輸出調(diào)節(jié)來(lái)確保體驗(yàn)符合一致的期望。
人們可能會(huì)用多種不同方式提問(wèn)。您可以通過(guò) NeMo Guardrails 等工具助 LLM “一臂之力”,這些工具可以對(duì)輸入和輸出進(jìn)行二次檢查,以確保系統(tǒng)處于最佳運(yùn)行狀態(tài)、解決系統(tǒng)所要解決的問(wèn)題,并引導(dǎo)用戶到其他地方解決 LLM 應(yīng)用無(wú)法處理的問(wèn)題。
如何加速 RAG 管線?
數(shù)據(jù)預(yù)處理
數(shù)據(jù)去重是識(shí)別并刪除重復(fù)數(shù)據(jù)的過(guò)程。在對(duì) RAG 數(shù)據(jù)進(jìn)行預(yù)處理時(shí),可以使用數(shù)據(jù)去重,減少為檢索而必須建立索引的相同文檔數(shù)量。
NVIDIA NeMo Data Curator 使用 NVIDIA GPU,通過(guò)并行執(zhí)行最小哈希算法、Jaccard 相似性計(jì)算和連接組件分析來(lái)加速數(shù)據(jù)去重,可以大大減少數(shù)據(jù)去重所需的時(shí)間。
另一個(gè)方法是分塊。由于下游嵌入模型只能對(duì)低于最大長(zhǎng)度的句子進(jìn)行編碼,因此必須將大型文本語(yǔ)料庫(kù)分成更小、更易于管理的語(yǔ)塊。流行的嵌入模型(如 OpenAI)最多可以編碼 1,536 個(gè)詞元。如果文本的詞元超過(guò)這個(gè)數(shù)量,就會(huì)被截?cái)唷?/p>
NVIDIA cuDF 可通過(guò)在 GPU 上執(zhí)行并行數(shù)據(jù)幀操作來(lái)加速分塊處理,可以大大減少對(duì)大型語(yǔ)料庫(kù)進(jìn)行分塊處理所需的時(shí)間。
最后,您可以在 GPU 上加速分詞器,分詞器負(fù)責(zé)將文本轉(zhuǎn)換成整數(shù)詞元供嵌入模型使用。文本分詞過(guò)程的計(jì)算成本很高,對(duì)于大型數(shù)據(jù)集來(lái)說(shuō)尤其如此。
索引和檢索
RAG 非常適合經(jīng)常更新的知識(shí)庫(kù),經(jīng)常需要重復(fù)生成嵌入。檢索是在推理時(shí)進(jìn)行,因此要求實(shí)現(xiàn)低延遲。NVIDIA NeMo Retriever 可以加速這些流程。NeMo Retriever 用于提供最先進(jìn)的商用模型和微服務(wù),這些模型和微服務(wù)專為實(shí)現(xiàn)最低延遲和最高吞吐量而優(yōu)化。
LLM 推理
LLM 至少可用于生成完全成型的回答,還可用于查詢分解和路由選擇等任務(wù)。
由于需要多次調(diào)用 LLM,低延遲對(duì)于 LLM 至關(guān)重要。NVIDIA NeMo 包含用于模型部署的 TensorRT-LLM,可優(yōu)化 LLM 以實(shí)現(xiàn)突破性的推理加速和 GPU 效率。
NVIDIA Triton 推理服務(wù)器也可以部署經(jīng)過(guò)優(yōu)化的 LLM,以實(shí)現(xiàn)高性能、高成本效益和低延遲的推理。
有哪些辦法可以改善聊天機(jī)器人的延遲?
除了建議使用 Triton 推理服務(wù)器和 TensorRT-LLM 來(lái)加速 RAG 管線(如 NeMo 檢索器和 NeMo 推理容器等)外,您還可以考慮使用流式傳輸來(lái)改善聊天機(jī)器人的感知延遲。響應(yīng)可能用時(shí)很久,流式傳輸用戶界面可先顯示部分已準(zhǔn)備好的內(nèi)容,減少可感知的延遲。
也可以考慮針對(duì)您的用例使用經(jīng)過(guò)微調(diào)的較小 LLM。通常情況下,較小的 LLM 的延遲遠(yuǎn)低于較大的 LLM。
一些經(jīng)過(guò)微調(diào)的 7B 模型在特定任務(wù)(如 SQL 生成)上的準(zhǔn)確性已經(jīng)超過(guò)了 GPT-4。例如,ChipNeMo 是 NVIDIA 為幫助公司內(nèi)部工程師生成和優(yōu)化芯片設(shè)計(jì)軟件而定制的 LLM,該模型使用的就是 13B 微調(diào)模型,而不是 70B 參數(shù)模型。TensorRT-LLM 提供的閃存、FlashAttention、PagedAttention、蒸餾和量化等模型優(yōu)化功能適合在本地運(yùn)行規(guī)模較小的微調(diào)模型,這些模型可減少 LLM 所使用的內(nèi)存。
LLM 的響應(yīng)延遲取決于首個(gè)詞元的生成時(shí)間(TTFT)和單個(gè)輸出詞元的生成時(shí)間(TPOT)。
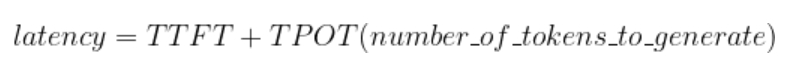
對(duì)于較小的 LLM 來(lái)說(shuō),TTFT 和 TPOT 都會(huì)比較低。
開(kāi)始在您的企業(yè)中構(gòu)建 RAG
通過(guò)使用 RAG,您可以輕松地為 LLM 提供最新的專有信息,并構(gòu)建一個(gè)能夠提高用戶信任度、改善用戶體驗(yàn)和減少幻覺(jué)問(wèn)題的系統(tǒng)。
審核編輯:劉清
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28231瀏覽量
206614 -
SQL
+關(guān)注
關(guān)注
1文章
760瀏覽量
44081 -
LLM
+關(guān)注
關(guān)注
0文章
276瀏覽量
306
原文標(biāo)題:RAG 101:檢索增強(qiáng)生成相關(guān)問(wèn)題解答
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
系統(tǒng)快速性、穩(wěn)定性和準(zhǔn)確性之間的權(quán)衡
如何提高工程預(yù)算的準(zhǔn)確性
怎么提高頻率測(cè)量的準(zhǔn)確性
合同智能審核軟件-提高審查效率和準(zhǔn)確性
如何提高交流脈沖對(duì)HPMMM充磁和去磁時(shí)磁場(chǎng)定向的準(zhǔn)確性?
如何提高投標(biāo)報(bào)價(jià)編制的準(zhǔn)確性
提高中溫?zé)崃艿老到y(tǒng)溫度測(cè)量準(zhǔn)確性的研究_栗鵬飛
AI可提高天氣預(yù)報(bào)的準(zhǔn)確性和準(zhǔn)確性,助力農(nóng)民和可再生能源行業(yè)
如何在沒(méi)有Arduino情況下制作機(jī)器人

在不犧牲尺寸的情況下提高脈搏血氧儀溶液的性能





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論