") 搜索出生的百川智能大模型RAG爬坑之路總結(jié)
搜索出生的百川智能大模型RAG爬坑之路總結(jié)
今天對百川的RAG方法進行解讀,百川智能具有深厚的搜索背景,來看看他們是怎么爬RAG的坑的吧~
總的來說,百川通過長上下文模型(192k)+搜索增強結(jié)合的方法來解決知識更新,降低模型幻覺的問題,使得其在5000萬tokens的數(shù)據(jù)集中取得95%的精度。其主要在以下幾個方面做優(yōu)化:
1) Query拓展:這是我自己取的名字,可能不太準確,其主要參考Meta的CoVe[1]以及百川自研的Think Step-Further方法對原始用戶輸入的復雜問題進行拆解、拓展,挖掘用戶更深層次的子問題,借助子問題檢索效果更高的特點來解決復雜問題檢索質(zhì)量偏差的問題。
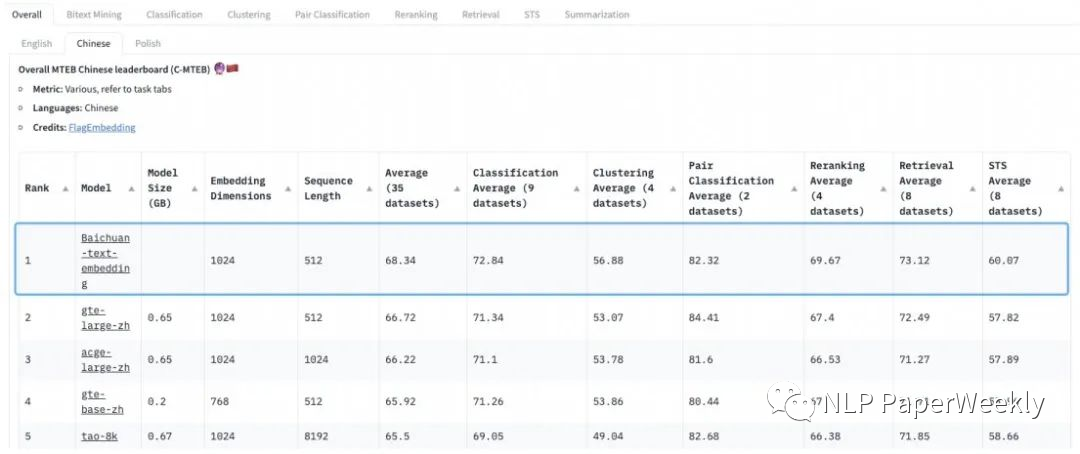
2) 優(yōu)化檢索鏈路:采用稀疏檢索+向量檢索+Rerank結(jié)合的方法,來提高檢索的召回率和準確率。并且其自研的Baichuan-Text-Embedding向量模型也登頂了C-MTEB語義向量評測標準。
3) 自我反省機制:百川智能通過self-Critique大模型自省機制來篩選更優(yōu)質(zhì)、知識密度更高的內(nèi)容。
一、概述
1Motivation
1.1 當前檢索增強RAG方法痛點
成本高、召回偏低:擴展上下文窗口+引入向量數(shù)據(jù)庫能以非常低的成本提高模型對新知識的接入能力,但是擴展上下文窗口容量有限(128k最多容納23萬漢字,相當于658kb文檔),成本比較高,性能下降明顯。向量數(shù)據(jù)庫也存在召回率偏低、開發(fā)門檻高等缺點。
用戶輸入變復雜:與傳統(tǒng)關(guān)鍵詞或者短語搜索邏輯不太一致,用戶輸入問題不再是詞或者短句,而是轉(zhuǎn)變成自然對話聲知識多輪對話數(shù)據(jù),問題形式更加多元,緊密關(guān)聯(lián)上下文,輸入風格更加口語化。
1.2 RAG是當前大模型落地降低幻覺、更新數(shù)據(jù)的有效方法之一
行業(yè)大模型解決方案有后訓練(Post-Train)和有監(jiān)督微調(diào)(SFT),但是仍然無法解決大模型落地的幻覺和實效性問題。
后訓練(Post-Train)和有監(jiān)督微調(diào)(SFT)每次需要更新數(shù)據(jù),重新訓練,還可能會帶來其他問題,成本比較大。
2Methods
省流版總結(jié):
百川將長窗口與搜索/RAG(檢索增強生成)相結(jié)合,形成長窗口模型+搜索的完整技術(shù)棧。
百川RAG方案總結(jié):Query 擴展(參考Meta CoVe + 自研Think Step-Further) + 自研Baichuan-Text-Embedding向量模型 + 稀疏檢索(BM25、ES) + rerank模型 + 自研Self-Critique技術(shù)(過濾檢索結(jié)果)。
2.1 Query擴展
背景:與傳統(tǒng)關(guān)鍵詞或者短語搜索邏輯不太一致,用戶輸入問題不再是詞或者短句,而是轉(zhuǎn)變成自然對話聲知識多輪對話數(shù)據(jù),問題形式更加多元,緊密關(guān)聯(lián)上下文,輸入風格更加口語化。
目的:拆解復雜的prompt,檢索相關(guān)子問題,并深度挖掘用于口語化表達中深層次含義,借助子問題檢索效果更高的特點來解決復雜問題檢索質(zhì)量偏差的問題。
方法:參考Meta CoVe[1]以及Think Step-Further的方法,對用戶原始的Query進行擴展,拓展出多個相關(guān)問題,然后通過相關(guān)問題去檢索相關(guān)內(nèi)容,提高召回率。
百川Query擴展方案:
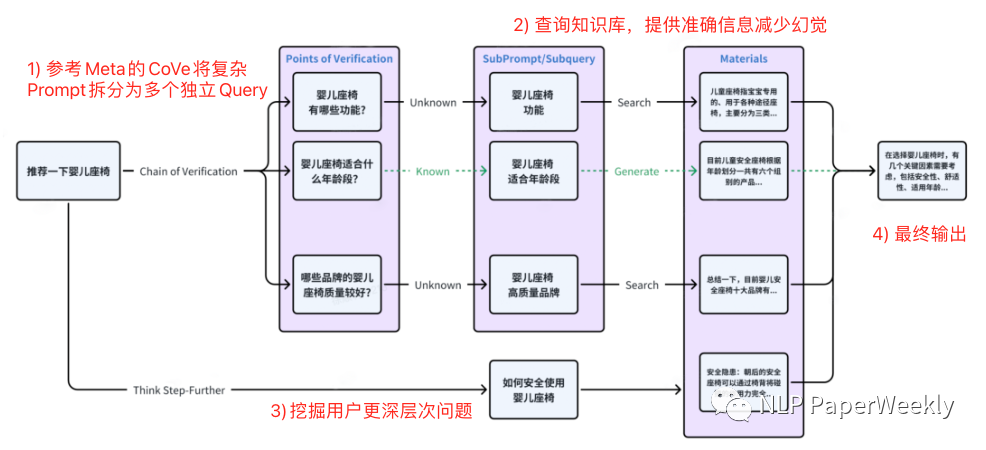
Meta CoVe方案:

2.2 自研Embedding模型
數(shù)據(jù):在超過1.5T tokens(看著訓練百川模型的數(shù)據(jù)都來訓embedding模型了?)。
方法:采用無監(jiān)督方法(估計類似SimCSE[2]系列),通過自研損失函數(shù)解決對比學習方式依賴batchsize問題。
效果:登頂C-MTEB,在分類、聚類、排序、檢索和文本相似度5個任務(wù)評分取得領(lǐng)先。
2.3 多路召回+rerank
方法:稀疏檢索+向量檢索 + rerank模型。其中稀疏檢索應(yīng)該是指BM25、ES等傳統(tǒng)檢索的方法,rerank模型百川沒有提到,不確定是用大模型來做rerank還是直接訓練相關(guān)rerank模型來對檢索結(jié)果排序。
效果:召回率95%,對比其他開源向量模型召回率低于80%。
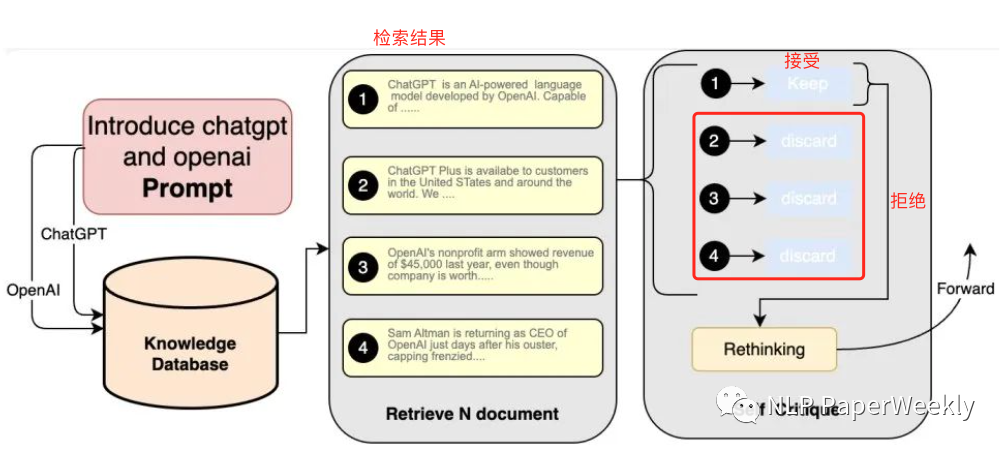
2.4 self-Critique
方法:讓大模型基于 Prompt、從相關(guān)性和可用性等角度對檢索回來的內(nèi)容自省,進行二次查看,從中篩選出與 Prompt 最匹配、最優(yōu)質(zhì)的候選內(nèi)容。
目的:提升檢索結(jié)果的知識密度和廣度,降低檢索結(jié)果中的知識噪聲。
3 Conclusion
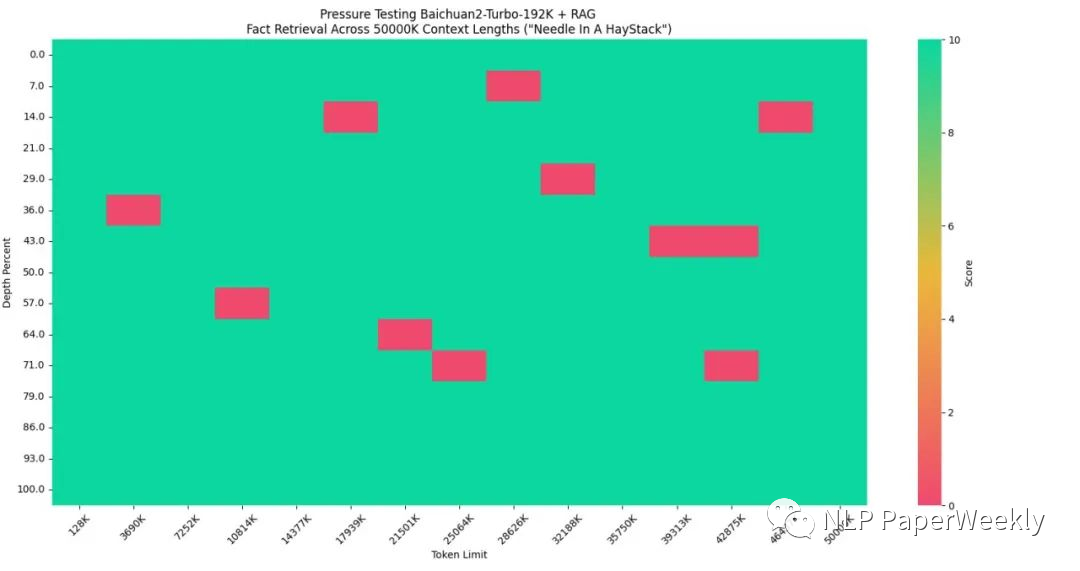
百川192K上下文模型表現(xiàn)不錯,實現(xiàn)了100%的回答精度。
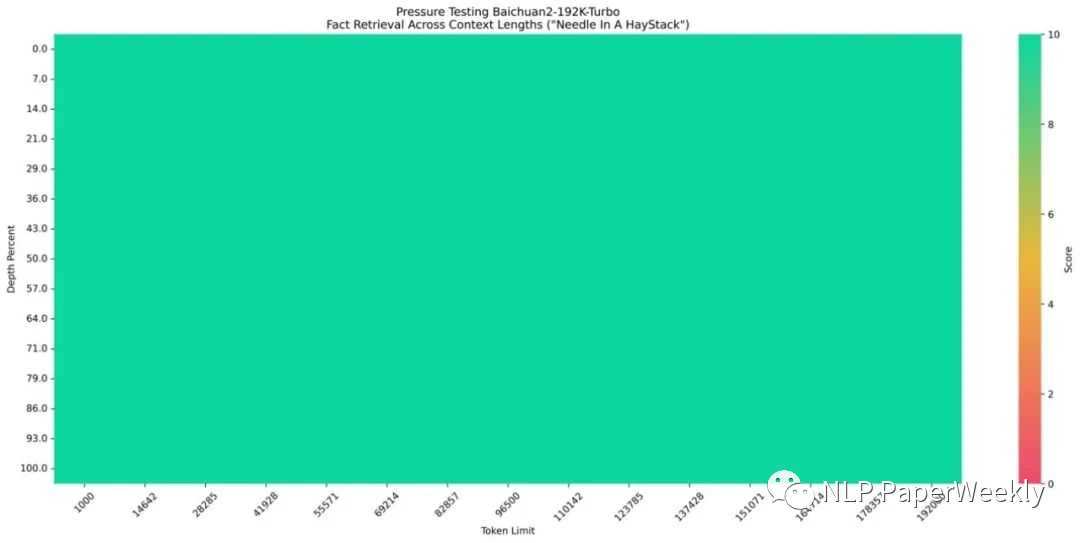
長上下文窗口模型+搜索增強技術(shù)使5000萬Tokens數(shù)據(jù)集達到95%的回答精度。
二、總結(jié)
多輪問答等場景的召回和傳統(tǒng)搜索引擎的召回分布還不太一樣。百川借助子問題檢索效果更高的特點,對原始復雜問題進行拆解、拓展來解決復雜問題檢索質(zhì)量偏差的問題。
對于沒見過的語料直接用向量檢索的結(jié)果可能不太理想。百川在大量語料上利用無監(jiān)督方法訓練embedding模型來優(yōu)化效果。而行業(yè)大模型更傾向于私有的數(shù)據(jù),要提升私有數(shù)據(jù)的訓練效果還得繼續(xù)在私有化數(shù)據(jù)上訓練效果會更佳。
Query拓展 + 多路召回 + Rerank + self-Critique可能是現(xiàn)階段比較好的一種RAG方式,但是其也會帶來更多成本。總體思路有點像ReAct[3]系列的進階版本,其在搜索側(cè)和答案修正側(cè)都做了更多的一些工作來優(yōu)化實際效果。其缺點是需要多次調(diào)用大模型,會帶來額外的成本,真實線上是否采用這種策略還有待驗證。
審核編輯:劉清
-
SFT
+關(guān)注
關(guān)注
0文章
9瀏覽量
6807
原文標題:百川智能RAG方案總結(jié):搜索出生的百川智能大模型RAG爬坑之路
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
白海科技與百川智能順勢而為、攜手共進,助力領(lǐng)域大模型應(yīng)用快速落地
海基新能源再獲百川股份資金加持
百川的大模型KnowHow介紹
百川智能獲阿里騰訊小米等3億美元投資
寒武紀的思元(MLU)云端智能加速卡與百川智能完成大模型適配,攜手創(chuàng)新生成式AI

百川智能發(fā)布Baichuan2 Turbo系列API,或?qū)⑻娲袠I(yè)大模型
百川智能發(fā)布超千億大模型Baichuan 3
數(shù)勢聯(lián)動百川,發(fā)布首批大模型聯(lián)合解決方案,推動中國大模型價值落地
百川智能與北京大學將共建通用人工智能聯(lián)合實驗室
百川智能發(fā)布Baichuan 4大模型及首款AI助手“百小應(yīng)”
亞馬遜云科技接入百川智能和零一萬物基礎(chǔ)模型
百川智能完成50億元A輪融資
大模型廠商“輸血”不斷,百川智能完成50億元A輪融資!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論