 硬件、軟件和網絡互聯技術詳解
硬件、軟件和網絡互聯技術詳解
AI、元宇宙、大模型......每一個火爆名詞的背后都代表著巨大的算力需求。據了解,AI模型所需的算力每100天就要翻一倍,遠超摩爾定律的18-24個月。5年后,AI所需的算力規模將是今天的100萬倍以上。
在這種背景下,加速計算提供了必要的計算能力和內存,其解決方案涉及硬件、軟件和網絡的組合。接下來,我們將回顧和梳理常見的硬件加速器,如GPU、ASIC、TPU、FPGA等,以及如CUDA、OpenCL等軟件解決方案。此外,還將探討PCIe、NVLink、CXL、InfiniBand、以太網等網絡互聯技術。
硬件、軟件和網絡互聯
摩爾定律的終結標志著 CPU 性能增長的放緩,人們開始對當前價值 1 萬億美元的純 CPU 服務器市場的未來發展產生質疑。隨著對更強大的應用程序和系統的需求不斷增加,傳統的 CPU 難以與加速計算競爭。與傳統CPU相比,加速計算利用 GPU、ASIC、TPU 和 FPGA 等專用硬件來加速某些任務的執行。
加速計算適用于可并行化的任務,如HPC、AI/ML、深度學習和大數據分析等。通過將某些類型的工作負載卸載到專用硬件設備上,加速計算可極大提高性能和效率。
硬件加速器
硬件加速器是加速計算的基礎,包括圖形處理單元 (GPU)、專用集成電路 (ASIC) 和現場可編程門陣列 (FPGA)。
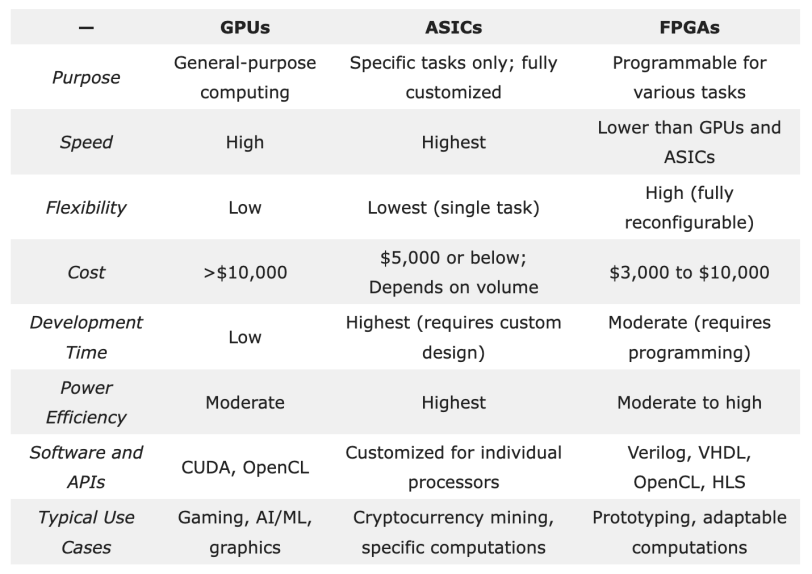
GPU廣泛應用于各種計算密集型任務,擅長同時執行許多復雜的計算,并行計算能力使其成為處理復雜數據集和大規模神經網絡訓練的理想選擇。
ASIC是為執行特定任務而設計的定制芯片,在速度、功耗和整體性能方面具有一定優勢。神經處理單元 (NPU) 和深度學習處理器 (DLP) 也屬于ASIC,旨在加速 AI 工作負載。谷歌的的張量處理單元 (TPU)也是ASIC家族的一員,專為加速機器學習工作負載而設計。
FPGA是一種半導體集成電路,與通用 CPU 相比,FPGA可以重新編程,更有效地執行特定任務。與 ASIC、GPU 和 CPU 中的固定架構不同,FPGA 硬件包括可配置邏輯塊和可編程互連。這樣就算在芯片發貨和部署后,也可以進行功能更新。
盡管FPGA因其靈活性在HPC和AI/ML領域備受青睞,但與GPU和專用ASIC相比,其開發速度較慢,軟件生態系統也相對不夠完善。由于其編程復雜性,FPGA 在人工智能工作負載中的采用較為緩慢,專業工程師的數量也有限。
軟件
加速計算利用API 和編程模型(如CUDA和OpenCL)將軟件和硬件加速器連接,API 和編程模型使開發人員能夠編寫在 GPU 上運行的代碼,并利用軟件庫來高效實現算法。
CUDA(統一計算架構)是英偉達開發的專有 GPU 編程框架,與英偉達的 GPU 緊密集成,充分利用了 GPU 的并行計算能力和專用硬件優化。CUDA 提供了更底層的編程接口,允許開發人員直接訪問 GPU 的內部特性和功能。
CUDA 的生態系統主要集中在英偉達的 GPU 上,由于其專用硬件優化和與 GPU 的緊密集成,可以提供更高的性能。英偉達還提供了豐富的開發工具和庫,使得 CUDA 在深度學習、科學計算等領域得到廣泛應用。
OpenCL(開放計算語言)是一個開放的、跨平臺的編程框架,由 Khronos Group 組織開發和維護。它的設計目標是支持各種硬件平臺,包括不僅限于 GPU 的處理器單元,如 CPU、FPGA 等。OpenCL 使用基于 C 語言的編程模型,允許開發人員利用各種設備上的并行計算能力。
OpenCL 擁有更廣泛的硬件支持,包括多個廠商的 GPU、CPU 以及其他加速設備。這意味著開發人員可以在不同的硬件平臺上使用相同的代碼進行開發,并且能夠更靈活地適應不同的需求。
OpenCL和CUDA都是強大的GPU加速計算框架,CUDA在與英偉達GPU的緊密結合下提供了更高性能,適用于專注于英偉達平臺開發者;而OpenCL具有跨平臺兼容性和多廠商支持的優勢,適用于需要在不同硬件平臺上進行開發的場景。
網絡互聯
網絡在加速計算中發揮著至關重要的作用,它促進了數以萬計的處理單元(例如 GPU、內存和存儲設備)之間的通信。各種網絡技術被用來實現計算設備之間的通信,多個設備之間共享數據。常見的技術包括:
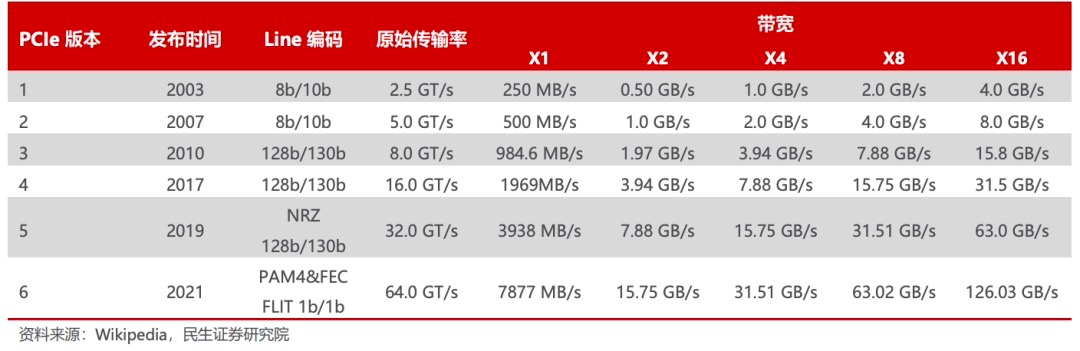
PCI Express (PCIe)是一種高速串行計算機擴展總線標準,主要用于連接CPU與各類高速外圍設備,如GPU、SSD、網卡、顯卡等。與傳統的PCI總線相比,PCIe采用點對點連接方式,具有更高的性能和可擴展性。伴隨著AI、自動駕駛、AR/VR等應用快速發展,計算要求愈來愈高,處理器I/O帶寬的需求每三年實現翻番,PCIe也大致按照3年一代的速度更新演進,每一代升級幾乎能夠實現傳輸速率的翻倍,并有著良好的向后兼容性。
2003 年PCIe 1.0 正式發布,可支持每通道傳輸速率為 250MB/s,總傳輸速率為 2.5 GT/s。
2007 年推出PCIe 2.0 規范。在 PCIe 1.0 的基礎上將總傳輸速率提高了一倍,達到 5 GT/s,每通道傳輸速率從 250 MB/s 上升至 500 MB/s。
2022 年 PCIe 6.0 規范正式發布,總帶寬提高至 64 GT/s。
2022年6月,PCI-SIG聯盟宣布PCIe 7.0版規范,單條通道(x1)單向可實現128GT/s傳輸速率,計劃于2025年推出最終版本。
NVLink 是英偉達開發的高速互連技術,旨在加快 CPU 與 GPU、GPU 與 GPU 之間的數據傳輸速度,提高系統性能。NVLink通過GPU之間的直接互聯,可擴展服務器內的多GPU I/O,相較于傳統PCIe總線可提供更高效、低延遲的互聯解決方案。
NVLink的首個版本于2014年發布,首次引入了高速GPU互連。2016年發布的P100搭載了第一代NVLink,提供 160GB/s 的帶寬,相當于當時 PCIe 3.0 x16 帶寬的 5 倍。V100搭載的NVLink2將帶寬提升到300GB/s ,A100搭載了NVLink3帶寬為600GB/s。目前NVLink已迭代至第四代,可為多GPU系統配置提供高于以往1.5倍的帶寬以及更強的可擴展性,H100中包含18條第四代NVLink鏈路,總帶寬達到900 GB/s,是PCIe 5.0帶寬的7倍。

Infinity Fabric是AMD 開發的高速互連技術,被用于連接AMD處理器內部的各個核心、緩存和其他組件,以實現高效的數據傳輸和通信。Infinity Fabric采用了一種分布式架構,其中包含多個獨立的通道,每個通道都可以進行雙向數據傳輸。這種設計使得不同核心之間可以直接進行快速而低延遲的通信,從而提高了整體性能。此外,Infinity Fabric還具備可擴展性和靈活性。它允許在不同芯片之間建立連接,并支持將多顆處理器組合成更強大的系統。
Compute Express Link (CXL)是一種開放式行業標準互連,可在主機處理器與加速器、內存緩沖區和智能 I/O 設備等設備之間提供高帶寬、低延遲連接,從而滿足高性能異構計算的要求,并且其維護CPU內存空間和連接設備內存之間的一致性。CXL優勢主要體現在極高兼容性和內存一致性兩方面上。
CXL 3.0是2022年8月份發布的標準,在許多方面都進行了較大的革新。CXL3.0建立在PCI-Express 6.0之上(CXL1.0/1.1和2.0版本建立在PCIe5.0之上),其帶寬提升了兩倍,并且其將一些復雜的標準設計簡單化,確保了易用性。
InfiniBand是一種高速、低延遲互連技術,由 IBTA(InfiniBand Trade Association)提出,其規定了一整套完整的鏈路層到傳輸層(非傳統OSI七層模型的傳輸層,而是位于其之上)規范,但是其無法兼容現有以太網。InfiniBand擁有高吞吐量和低延遲,擴展性好,通過交換機在節點間的點對點通道進行數據傳輸,通道私有且受保護。
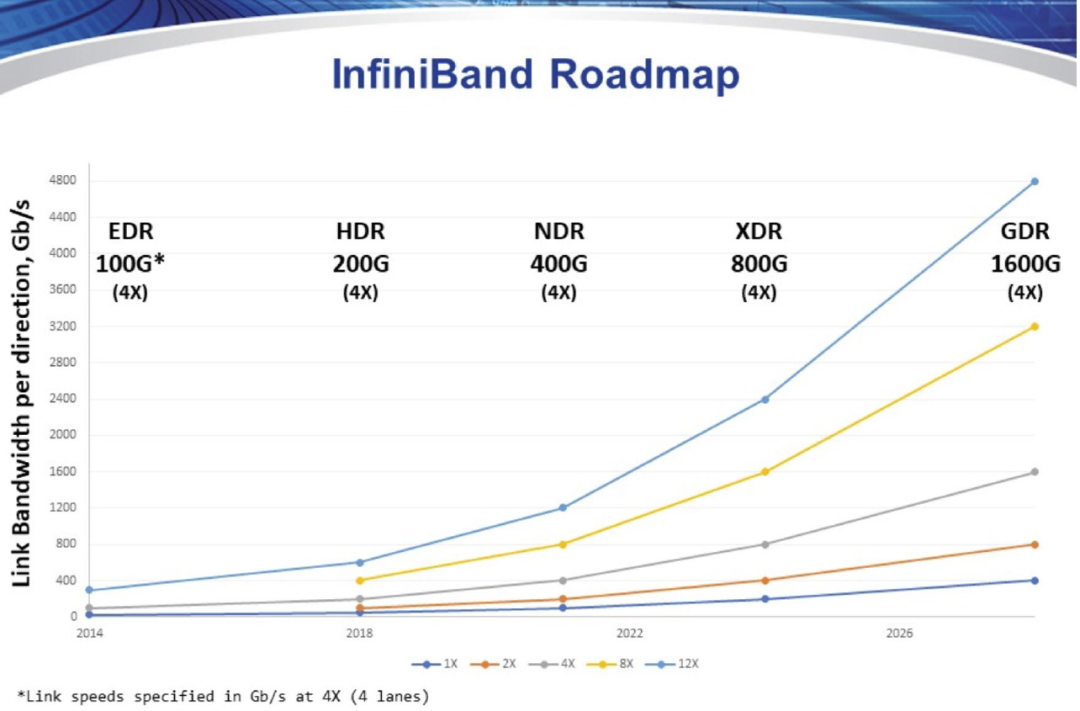
目前InfiniBand的傳輸速度為400Gb/s,路線圖顯示,IBTA計劃于2024年推出XDR 800Gb/s InfiniBand產品,并在2026年后推出GDR 1600Gb/s產品。InfiniBand的高傳輸速度打通高性能計算中數據傳輸速率瓶頸,提升吞吐量和計算效率。
以太網是應用最廣泛最成熟的網絡技術,可在數據中心的服務器之間傳輸大量數據,這對于許多加速計算任務至關重要。RoCE協議下,以太網融合RDMA功能,在高性能計算場景下的通信性能大幅提升。今年,為應對AI 和HPC工作負載提出的新挑戰,網絡巨頭聯合成立了超以太網聯盟(UEC),超以太網解決方案堆棧將利用以太網的普遍性和靈活性處理各種工作負載,同時具有可擴展性和成本效益,為以太網注入了新的活力。
加速計算為傳統CPU和日益增長的數據需求之間搭起了一座橋梁,從數據中心到邊緣計算,加速計算已廣泛應用于各種領域。英偉達創始人黃仁勛曾表示,計算已經發生了根本性的變化,CPU擴展的時代已結束,購買再多的CPU已無法解決問題。加速計算將與AI一起推動,新計算時代“引爆點”已到來。
審核編輯:湯梓紅
-
以太網
+關注
關注
40文章
5288瀏覽量
169680 -
網絡互聯
+關注
關注
0文章
15瀏覽量
9532 -
gpu
+關注
關注
27文章
4591瀏覽量
128149 -
硬件
+關注
關注
11文章
3113瀏覽量
65853 -
軟件
+關注
關注
69文章
4570瀏覽量
86703
原文標題:從硬件、軟件到網絡互聯,AI時代下的加速計算技術
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦








 工商網監
工商網監
評論