 如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
如何解決Python爬蟲中文亂碼問題?Python爬蟲中文亂碼的解決方法
在Python爬蟲過程中,遇到中文亂碼問題是常見的情況。亂碼問題主要是由于編碼不一致所導致的,下面我將詳細介紹如何解決Python爬蟲中文亂碼問題。
一、了解字符編碼
在解決亂碼問題之前,我們首先需要了解一些基本的字符編碼知識。常見的字符編碼有ASCII、UTF-8和GBK等。
1. ASCII:是一種用于表示英文字母、數字和常用符號的字符編碼,它使用一個字節(8位)來表示一個字符。
2. UTF-8:是一種可變長度的字符編碼,它使用1至4個字節來表示一個字符,并支持全球范圍內的所有字符。
3. GBK:是一種針對漢字的字符編碼標準,它采用雙字節來表示一個漢字。
二、網頁編碼判斷
在爬取網頁內容時,我們需要確定網頁使用的字符編碼,以便正確解析其中的中文內容。
1. 查看HTTP響應頭部信息
爬蟲通常使用HTTP協議請求網頁內容,網頁的字符編碼信息一般會在響應頭部的Content-Type字段中指定。我們可以通過檢查響應頭部的Content-Type字段來獲取網頁的字符編碼。
示例代碼如下:
```python
import requests
url = "http://www.example.com"
response = requests.get(url)
content_type = response.headers['Content-Type']
print(content_type)
```
2. 使用chardet庫自動檢測編碼
有些網頁的響應頭部并沒有明確指定字符編碼,這時我們可以使用chardet庫來自動檢測網頁的編碼方式。
示例代碼如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = chardet.detect(response.content)['encoding']
print(encoding)
```
3. 多種方式組合判斷
有些網站采用了一些特殊的方式來指定字符編碼,但是chardet庫無法檢測到。這時我們可以根據網頁內容的一些特征進行判斷,然后再使用chardet庫進行編碼檢測。
示例代碼如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
content = response.content
# 根據網頁內容特征判斷編碼方式
if "charset=gb2312" in content.lower() or "charset=gbk" in content.lower():
encoding = 'gbk'
elif "charset=utf-8" in content.lower():
encoding = 'utf-8'
else:
encoding = chardet.detect(content)['encoding']
print(encoding)
```
三、解碼網頁內容
當我們獲得網頁的正確編碼后,就需要將網頁內容進行解碼,以得到正確的中文字符。
1. 使用requests庫自動解碼
requests庫在獲取網頁內容時,會根據響應頭部的Content-Type字段自動解碼網頁內容。
示例代碼如下:
```python
import requests
url = "http://www.example.com"
response = requests.get(url)
content = response.text
print(content)
```
2. 使用指定編碼進行手動解碼
如果requests庫無法正確解碼網頁內容,我們可以手動指定網頁內容的編碼方式進行解碼。
示例代碼如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假設網頁內容使用utf-8編碼
content = response.content.decode(encoding)
print(content)
```
四、編碼問題修復
在將爬取到的中文內容存儲或處理時,仍然可能會遇到編碼問題。下面介紹解決編碼問題的幾種常見方法。
1. 使用正確的編碼方式進行存儲
當將爬取到的中文內容存儲到數據庫或文件中時,需要確保使用正確的編碼方式進行存儲。通常情況下,使用UTF-8編碼是一個可以接受的選擇。
示例代碼如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假設網頁內容使用utf-8編碼
content = response.content.decode(encoding)
# 將內容存儲到文件
with open("output.txt", "w", encoding='utf-8') as file:
file.write(content)
```
2. 使用encode()方法進行編碼轉換
當需要將爬取到的中文內容傳遞給其他模塊或函數時,可能需要進行編碼轉換。可以使用字符串的encode()方法將其轉換為字節類型,然后再進行傳遞。
示例代碼如下:
```python
import requests
import chardet
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假設網頁內容使用utf-8編碼
content = response.content.decode(encoding)
# 將內容傳遞給其他模塊或函數
content_bytes = content.encode(encoding)
other_module.process(content_bytes)
```
3. 使用第三方庫進行編碼修復
如果以上方法都無法解決編碼問題,可以考慮使用第三方庫來修復編碼問題。例如,可以使用ftfy(fixes text for you)庫來修復文本中的亂碼問題。
示例代碼如下:
```python
import requests
import chardet
import ftfy
url = "http://www.example.com"
response = requests.get(url)
encoding = 'utf-8' # 假設網頁內容使用utf-8編碼
content = response.content.decode(encoding)
# 使用ftfy庫修復編碼問題
fixed_content = ftfy.fix_text(content)
print(fixed_content)
```
綜上所述,解決Python爬蟲中文亂碼問題的方法包括:了解字符編碼、網頁編碼判斷、解碼網頁內容以及編碼問題修復等。在實際爬蟲過程中,我們根據具體情況選擇最合適的方法來解決亂碼問題,以確保爬取到的中文內容正常顯示和處理。
-
python
+關注
關注
56文章
4782瀏覽量
84452 -
HTTP協議
+關注
關注
0文章
61瀏覽量
9705
發布評論請先 登錄
相關推薦
Vivado編輯器亂碼問題
詳細解讀爬蟲多開代理IP的用途,以及如何配置!
用pycharm進行python爬蟲的步驟
ESP32設置中文藍牙設備名稱會異常顯示亂碼,原因是什么?
鴻蒙OS開發問題:(ArkTS) 【解決中文亂碼 string2Uint8Array、uint8Array2String】
鴻蒙OS開發問題:(ArkTS)【 RSA加解密,解決中文亂碼等現象】
全球新聞網封鎖OpenAI和谷歌AI爬蟲
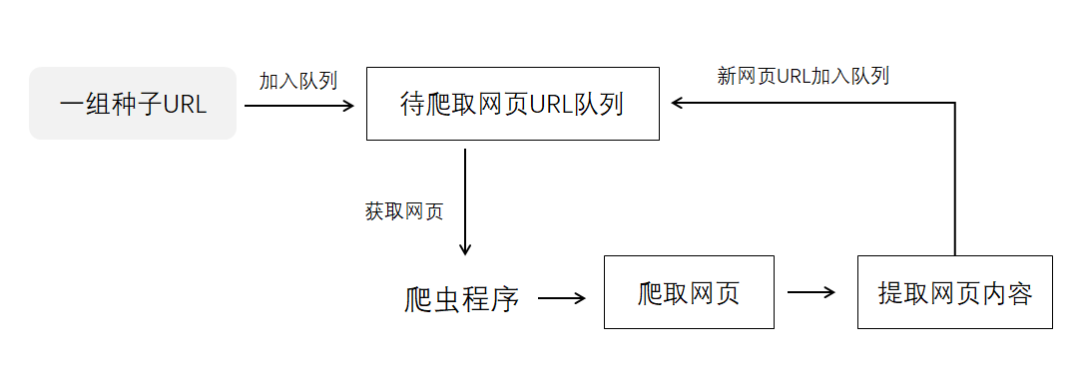
爬蟲的基本工作原理 用Scrapy實現一個簡單的爬蟲





 工商網監
工商網監
評論