") 使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理優(yōu)化實踐
使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理優(yōu)化實踐
使其可部署在 24GB 顯存的單張 NVIDIA A10 Tensor Core GPU
概述
CodeFuse是由螞蟻集團開發(fā)的代碼語言大模型,旨在支持整個軟件開發(fā)生命周期,涵蓋設(shè)計、需求、編碼、測試、部署、運維等關(guān)鍵階段。
為了在下游任務(wù)上獲得更好的精度,CodeFuse 提出了多任務(wù)微調(diào)框架(MFTCoder),能夠解決數(shù)據(jù)不平衡和不同收斂速度的問題。
通過對比多個預(yù)訓(xùn)練基座模型的精度表現(xiàn),我們發(fā)現(xiàn)利用 MFTCoder [1,2]微調(diào)后的模型顯著優(yōu)于原始基座模型。其中,尤為值得關(guān)注的是采用了 MFTCoder 框架,并利用多任務(wù)數(shù)據(jù)集進行微調(diào)的 CodeFuse-CodeLlama-34B [3] 模型,在 HumanEval 評估數(shù)據(jù)集中取得了當(dāng)時的最好結(jié)果。具體來說,基于 CodeLlama-34b-Python 模型進行微調(diào)的 CodeFuse-CodeLlama-34B 在 HumanEval-python 上實現(xiàn)了 74.4% 的 pass@1(貪婪解碼)。以下是完整的代碼能力評估結(jié)果 :
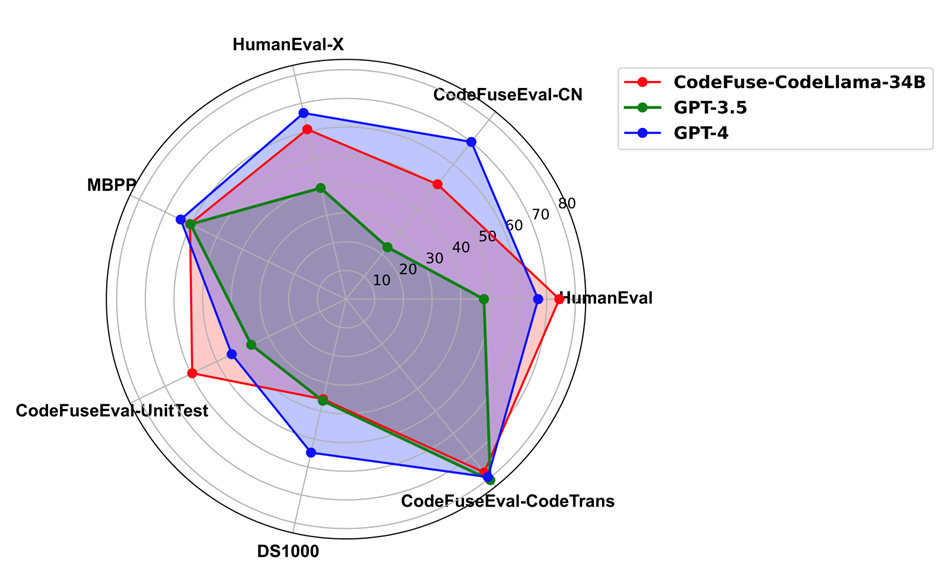
在代碼補全、text2code、代碼翻譯、單測生成以及代碼生成任務(wù)上,CodeFuse-CodeLlama-34B 全面超過 GPT-3.5;CodeFuse-CodeLlama-34B 能夠在單測生成和代碼補全(HumanEval )任務(wù)上超過 GPT-4。同時,上述微調(diào)模型、MFTCoder 訓(xùn)練框架和高質(zhì)量代碼數(shù)據(jù)集已經(jīng)開源。
然而,CodeFuse-CodeLlama-34B 的部署遇到了如下兩個挑戰(zhàn):
1)數(shù)據(jù)類型為 fp16 的 34B 模型,顯存占用為 68 GB,至少需要 3 張 A10 才能加載模型,部署成本很高;
2)在模型推理的生成階段,通常伴隨著長條形的矩陣運算,此時計算量較小,不足以掩蓋 GPU 的訪存延遲,即 memory bound 問題,此時程序的性能受限于 GPU 帶寬。
為了解決上述問題,我們利用 GPTQ 量化技術(shù),在降低了部署成本的同時,也緩解了 GPU 的帶寬壓力 ,從而顯著提升了推理速度。最終,CodeFuse-CodeLlama-34B 的 int4 量化模型可以部署在單張 A10 顯卡上,推理速度可以達到 20 tokens/s (batch_size=1)。同時,相較于 fp16 數(shù)據(jù)精度的模型,通過算法上的優(yōu)化,int4 量化引入的精度下降可以控制在 1% 以內(nèi)。下面,我們從模型量化和測試兩個方面展示我們是如何實現(xiàn) CodeFuse-CodeLlama-34B 模型的 int4 量化部署的。另外,TensorRT-LLM 也支持了 CodeFuse 中基于 MFTCoder 訓(xùn)練的開源模型部署。
CodeFuse-CodeLlama-34B int4 量化
這里我們使用 GPTQ [4]技術(shù)對模型進行 int4 量化。GPTQ 是對逐層量化范式經(jīng)典框架 OBQ(Optimal Brain Quantization)[5]的高效實現(xiàn),能夠利用單張 A100-80G 在 4 小時內(nèi)完成 OPT-175B 模型的量化,并且可以獲得較好的準確率。
另外,我們這里采用了靜態(tài)量化方式,即通過矯正數(shù)據(jù)離線地進行量化,得到諸如縮放因子和零點的量化參數(shù),在推理時不再進行量化參數(shù)的更新。與之對應(yīng)的是動態(tài)量化,會在模型推理的同時根據(jù)輸入進行量化參數(shù)的調(diào)整。最后,我們這里進行的是 int4-weight-only 量化,即只對權(quán)重進行量化而不對層輸入進行量化,即 W4A16 量化。
GPTQ 算法
為了量化權(quán)重 ,OBQ 框架對層重建損失函數(shù)
,OBQ 框架對層重建損失函數(shù)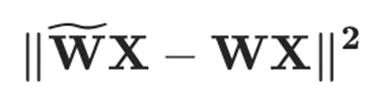 進行二階泰勒級數(shù)展開,同時假設(shè)在未量化的權(quán)重值處一階梯度為零,從而得到如下優(yōu)化問題:
進行二階泰勒級數(shù)展開,同時假設(shè)在未量化的權(quán)重值處一階梯度為零,從而得到如下優(yōu)化問題:
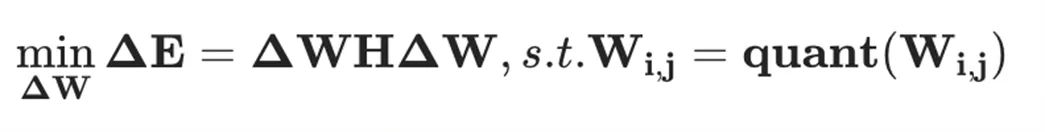
其中, 是所有未量化權(quán)重對應(yīng)的 Hessian 矩陣。那么,量化誤差以及權(quán)重更新值分別為
是所有未量化權(quán)重對應(yīng)的 Hessian 矩陣。那么,量化誤差以及權(quán)重更新值分別為
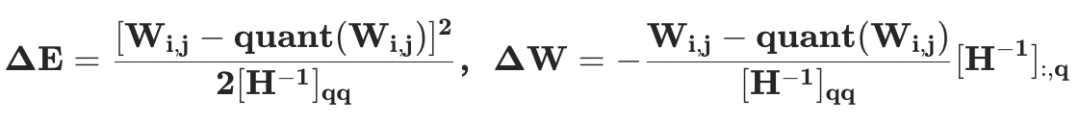
上面的兩個公式意味著所有未量化權(quán)重需要通過 更新以補償量化帶來的量化誤差。同時,層重建損失函數(shù)可以按照輸出通道(output channel, OC)分解為獨立的子問題,例如:
更新以補償量化帶來的量化誤差。同時,層重建損失函數(shù)可以按照輸出通道(output channel, OC)分解為獨立的子問題,例如:
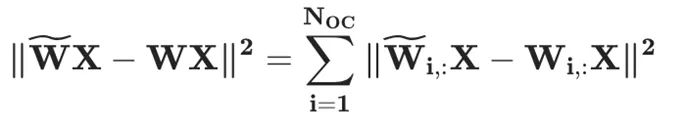
其中Hessian 矩陣為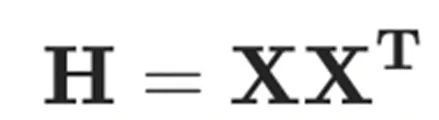 。為了充分利用 GPU 的能力,GPTQ 做了如下三個改進:
。為了充分利用 GPU 的能力,GPTQ 做了如下三個改進:
所有輸出通道共享相同的量化順序,從而使得行間共享同一份 Hessian 矩陣,大大減少了算法計算量。
使用一次 Cholesky 分解代替了在 GPTQ 每次迭代中對整個 Hessian 矩陣的逆矩陣的高斯消元迭代更新方式。既大大減少了計算量,又得以利用成熟 GPU 矩陣庫中的 Cholesky 算法,且避免了迭代更新方式在矩陣運算中所帶來的數(shù)值不穩(wěn)定問題。
通過將整個計算過程由對單個輸入通道進行更新,等效轉(zhuǎn)變?yōu)閯澐?batch 并逐 batch 更新的方式,避免了每次量化對整個 Hessian 與權(quán)重矩陣的 GPU 讀寫操作,大大降低了 GPU 訪存數(shù)量。
上述的改進使得 GPTQ 可以有效提升 GPU 利用率,從而能夠?qū)Υ竽P瓦M行高效量化。
int4-weight-only 量化
這里我們利用開源工具 AutoGPTQ進行量化,工具超參數(shù)如下;
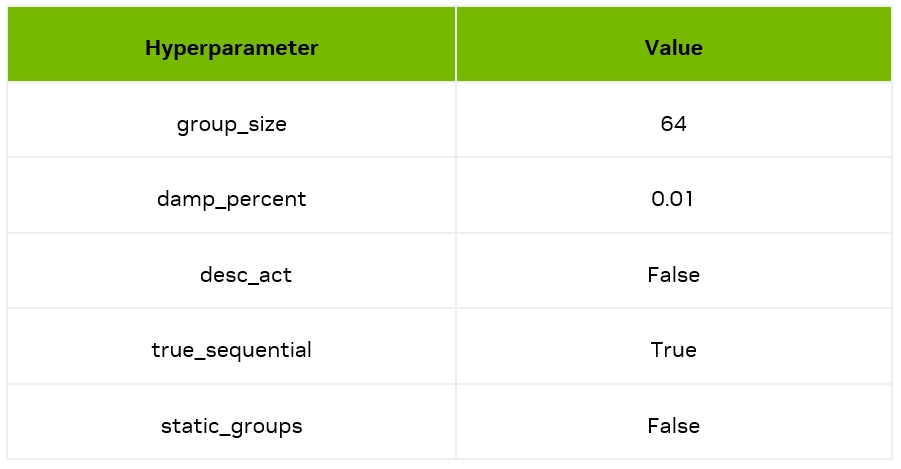
利用 AutoGPTQ 進行模型加載和推理的例子如下:
import os import torch import time from modelscope import AutoTokenizer, snapshot_download from auto_gptq import AutoGPTQForCausalLM os.environ["TOKENIZERS_PARALLELISM"] = "false" def load_model_tokenizer(model_path): """ Load model and tokenizer based on the given model name or local path of downloaded model. """ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False, lagecy=False) tokenizer.padding_side = "left" tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids("") tokenizer.eos_token_id = tokenizer.convert_tokens_to_ids("") model = AutoGPTQForCausalLM.from_quantized(model_path, inject_fused_attention=False, inject_fused_mlp=False, use_cuda_fp16=True, disable_exllama=False, device_map='auto' # Support multi-gpus ) return model, tokenizer def inference(model, tokenizer, prompt): """ Uset the given model and tokenizer to generate an answer for the speicifed prompt. """ st = time.time() inputs = prompt if prompt.endswith(' ') else f'{prompt} ' input_ids = tokenizer.encode(inputs, return_tensors="pt", padding=True, add_special_tokens=False).to("cuda") with torch.no_grad(): generated_ids = model.generate( input_ids=input_ids, top_p=0.95, temperature=0.1, do_sample=True, max_new_tokens=512, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id ) print(f'generated tokens num is {len(generated_ids[0][input_ids.size(1):])}') outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) print(f'generate text is {outputs[0][len(inputs): ]}') latency = time.time() - st print('latency is {} seconds'.format(latency)) if __name__ == "__main__": model_dir = snapshot_download('codefuse-ai/CodeFuse-CodeLlama-34B-4bits', revision='v1.0.0') prompt = 'Please write a QuickSort program in Python' model, tokenizer = load_model_tokenizer(model_dir) inference(model, tokenizer, prompt)
在做靜態(tài)量化時,GPTQ 使用矯正數(shù)據(jù)集作為輸入計算 Hessian 矩陣,從而更新未量化權(quán)重進而補償量化帶來的誤差。如果推理階段的輸入和矯正數(shù)據(jù)集有偏差(bias),那么量化時用矯正數(shù)據(jù)得到的 Hessian 矩陣就無法完全反映推理輸入,這會導(dǎo)致 GPTQ 的誤差補償失效(失效的程度和偏差成正比),出現(xiàn)量化模型在推理輸入上量化誤差變大的情況,進而導(dǎo)致量化模型的精度下降。
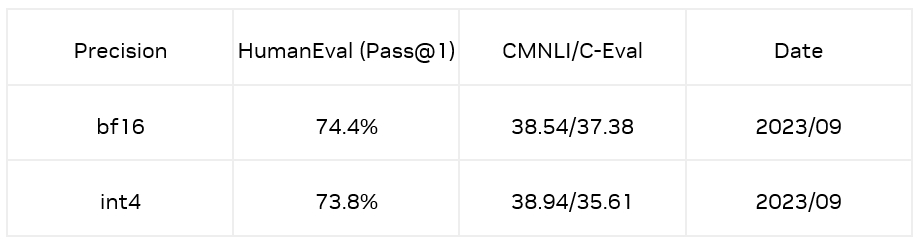
為了解決上述問題,對于微調(diào)模型,我們使用了一種數(shù)據(jù)分布對齊技術(shù)減少模型量化帶來的損失。通過抽取訓(xùn)練數(shù)據(jù)(CodeFuse 開源的高質(zhì)量代碼數(shù)據(jù)集 evol)中的 Question 作為引導(dǎo)方式,利用原始模型生成 Answer,將 Question 和 Answer 拼接起來作為矯正數(shù)據(jù);最終在 HumanEval Benchmarks 的 Python pass@1 取得了 73.8% 的準確率,相較于 bf16 模型僅有 0.6% 的精度損失。同時,在 CMNLI 和 C-Eval 兩個數(shù)據(jù)集的精度損失也比較少。
構(gòu)建 TensorRT 引擎
在通過 AutoGPTQ 可以得到 safetensors 格式的 int4 量化模型[6]后,我們的目標是構(gòu)建單卡 TensorRT 引擎,同時保證 activation 是 fp16 的數(shù)據(jù)精度。通過 examples/llama/build.py 進行 TensorRT 引擎構(gòu)建時,需要關(guān)注如下參數(shù):
dtype:設(shè)置為 fp16
use_gpt_attention_plugin:設(shè)置為 fp16,構(gòu)建引擎時利用 gpt a ttention plugin 并且數(shù)據(jù)精度為 fp16
use_gemm_plugin:設(shè)置為 fp16,構(gòu)建引擎時利用 gemm_plugin 并且數(shù)據(jù)精度為 fp16
use_weight_only:觸發(fā) weight only 量化
weight_only_precision:設(shè)置為 int4 _gptq,表示構(gòu)建 W4A16 的 GPTQ 量化模型引擎
per_group:gptq 為group-wise 量化,所以需要觸發(fā) per-group
max_batch_size: TensorRT 引擎最大允許 batch size
max_input_len:TensorRT 引擎最大允許輸入長度
max_output_len:TensorRT 引擎最大允許輸出長度
綜上,我們在單卡 A10/A100上構(gòu)建 TensorRT 引擎的命令如下:
python build.py --model_dir "${model_dir}"
--quant_safetensors_path "${quant_safetensors_path}"
--dtype float16
--use_gpt_attention_plugin float16
--use_gemm_plugin float16
--use_weight_only
--weight_only_precision int4_gptq
--max_batch_size 1
--max_input_len 2048
--max_output_len 1024
--per_group
--output_dir "${engin_dir}" 2>&1 | tee dev_build.log
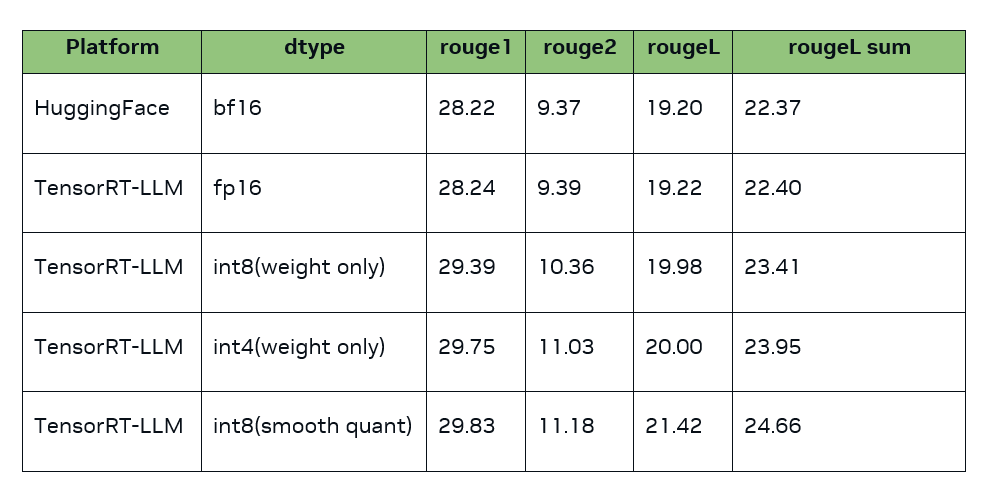
測試
性能
下面,我們主要測試了batch size 為 1 時,不同的輸入輸出長度和量化精度情況下,TensorRT-LLM 在 A10/A100 上的推理速度表現(xiàn)。可以看到,在 A100 上,TensorRT-LLM 的 int4 相對 fp16,最高能夠帶來 2.4 倍的加速,相對 int8 最高也能帶來 1.7 倍的加速。
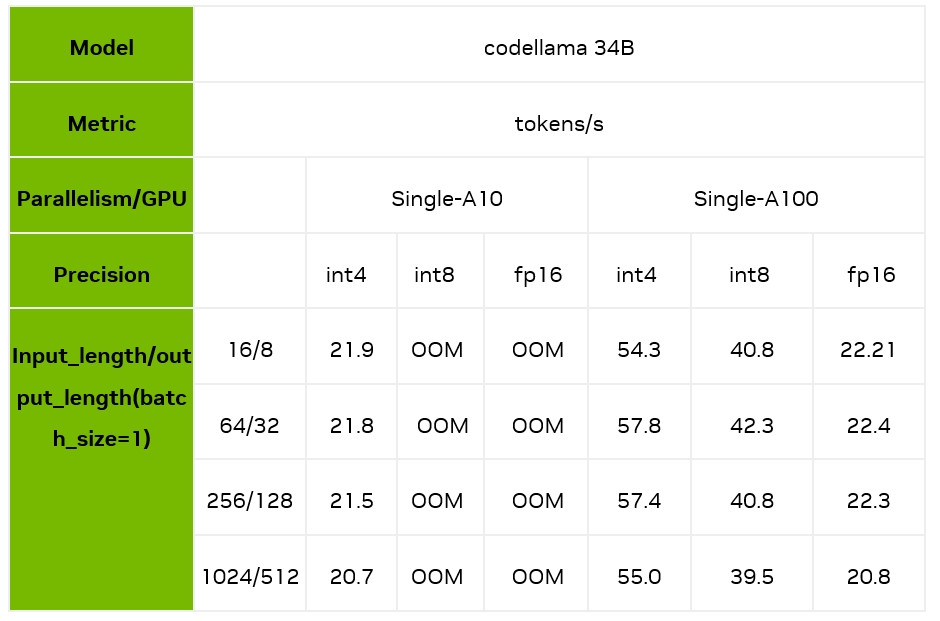
注意:以上性能測試均基于 TensorRT-LLM 的 0.6.1 版本
顯存占用和結(jié)果測試
我們測量了模型加載后占用的顯存占用情況,以及輸入 2048/1024 tokens 并輸出 1024/2048 tokens 時的顯存使用情況;同時我們也測試了量化前后的精度情況,如下表所示:
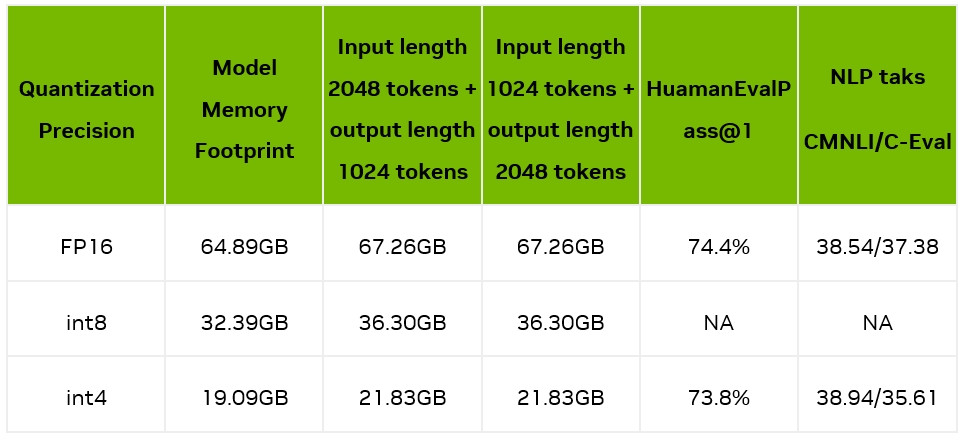
可見,4bit 量化后,顯存占用大幅縮小,在一張 A10(24GB 顯存)上就能部署 34B 的大模型,具備非常好的實用性。
模型演示
我們通過終端命令行[7]以及網(wǎng)頁聊天機器人 [8]兩種不同的方式,展示我們最終的推理效果,具體細節(jié)可以訪問開源的鏈接。
Cli Demo

WebuiDemo
總結(jié)
在這篇文章中,我們介紹了如何使用 TensorRT-LLM 來加速 CodeFuse 的推理性能。具體而言,我們按照順序展示了如何使用 GPTQ Int4 量化方法、增強 GPTQ 量化算法精度的自動對齊技術(shù)、TensorRT-LLM int4 量化模型的使用方法以及相應(yīng)的評估過程。通過 TensorRT-LLM 的支持,CodeFuse 實現(xiàn)了較低的推理延遲和優(yōu)化的部署成本。
審核編輯:劉清
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4949瀏覽量
102826 -
python
+關(guān)注
關(guān)注
56文章
4783瀏覽量
84473 -
GPT
+關(guān)注
關(guān)注
0文章
352瀏覽量
15316 -
LLM
+關(guān)注
關(guān)注
0文章
276瀏覽量
306
原文標題:使用NVIDIA TensorRT-LLM支持CodeFuse-CodeLlama-34B上的int4量化和推理優(yōu)化實踐
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

TensorRT-LLM低精度推理優(yōu)化

NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)

【飛凌嵌入式OK3576-C開發(fā)板體驗】rkllm模型量化構(gòu)建
魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
LLM大模型推理加速的關(guān)鍵技術(shù)
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
利用NVIDIA組件提升GPU推理的吞吐
自然語言處理應(yīng)用LLM推理優(yōu)化綜述

基于NVIDIA Megatron Core的MOE LLM實現(xiàn)和訓(xùn)練優(yōu)化

利用NVIDIA產(chǎn)品技術(shù)組合提升用戶體驗
Torch TensorRT是一個優(yōu)化PyTorch模型推理性能的工具

OpenVINO? 2023.2 發(fā)布:讓生成式AI在實際場景中更易用
低比特量化技術(shù)如何幫助LLM提升性能

如何在 NVIDIA TensorRT-LLM 中支持 Qwen 模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論