 圖解大模型RLHF系列之:人人都能看懂的PPO原理與源碼解讀
圖解大模型RLHF系列之:人人都能看懂的PPO原理與源碼解讀
大家好,最近我又讀了讀RLHF的相關paper和一些開源實踐,有了一些心得體會,整理成這篇文章。過去在RLHF的初學階段,有一個問題最直接地困惑著我:
- 如何在NLP語境下理解強化學習的框架?例如,我知道強化學習中有Agent、Environment、Reward、State等要素,但是在NLP語境中,它們指什么?語言模型又是如何根據獎勵做更新的?
為了解答這個問題,我翻閱了很多資料,看了許多的公式推導,去研究RLHF的整體框架和loss設計。雖然吭吭哧哧地入門了,但是這個過程實在痛苦,最主要的原因是:理論的部分太多,直觀的解釋太少。
所以,在寫這篇文章時,我直接從一個RLHF開源項目源碼入手(deepspeed-chat),根據源碼的實現細節,給出盡可能豐富的訓練流程圖,并對所有的公式給出直觀的解釋。希望可以幫助大家更具象地感受RLHF的訓練流程。對于沒有強化學習背景的朋友,也可以無痛閱讀本文。關于RLHF,各家的開源代碼間都會有一些差異,同時也不止PPO一種RLHF方式。感興趣的朋友,也可以讀讀別家的源碼,做一些對比。后續有時間,這個系列也會對各種RLHF方式進行比較。
整體內容如下:
【一、強化學習概述】
1.1 強化學習整體流程
1.2 價值函數
【二、NLP中的強化學習】
【三、RLHF中的四個重要角色】
3.1 Actor Model
3.2 Reference Model
3.3 Critic Model
3.4 Reward Model
【四、RLHF中的loss計算】
4.1 Actor loss
(1) 直觀設計
(2) 引入優勢
(3) 重新設計獎勵函數
(4) 重新設計優勢
(5)ppo_epoch: 引入新約束,提升訓練效率
(6) Actor loss小結
【五、Critic loss】
(1) 實際收益優化
(2) 預估收益優化
一、強化學習概述
1. 強化學習整體流程
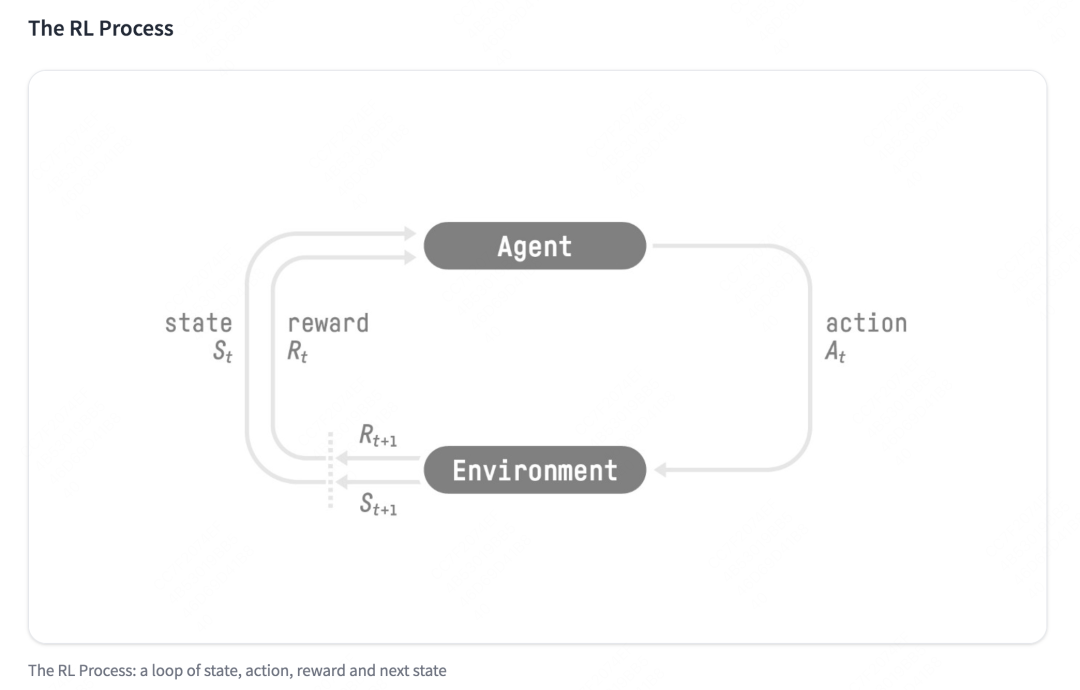
- 強化學習的兩個實體:智能體(Agent)與環境(Environment)
-
強化學習中兩個實體的交互:
- 狀態空間S:S即為State,指環境中所有可能狀態的集合
- 動作空間A:A即為Action,指智能體所有可能動作的集合
- 獎勵R:R即為Reward,指智能體在環境的某一狀態下所獲得的獎勵。
以上圖為例,智能體與環境的交互過程如下:
- 在時刻,環境的狀態為,達到這一狀態所獲得的獎勵為
- 智能體觀測到與,采取相應動作
- 智能體采取后,環境狀態變為,得到相應的獎勵
智能體在這個過程中學習,它的最終目標是:找到一個策略,這個策略根據當前觀測到的環境狀態和獎勵反饋,來選擇最佳的動作。
1.2 價值函數
在1.1中,我們談到了獎勵值,它表示環境進入狀態下的即時獎勵。
但如果只考慮即時獎勵,目光似乎太短淺了:當下的狀態和動作會影響到未來的狀態和動作,進而影響到未來的整體收益。
所以,一種更好的設計方式是:t時刻狀態s的總收益 = 身處狀態s能帶來的即時收益 + 從狀態s出發后能帶來的未來收益。寫成表達式就是:
其中:
- :時刻的總收益,注意這個收益蘊涵了“即時”和“未來”的概念
- :時刻的即時收益
- :時刻的總收益,注意這個收益蘊涵了“即時”和“未來”的概念。而對來說就是“未來”。
- :折扣因子。它決定了我們在多大程度上考慮將“未來收益”納入“當下收益”。
注:在這里,我們不展開討論RL中關于價值函數的一系列假設與推導,而是直接給出一個便于理解的簡化結果,方便沒有RL背景的朋友能傾注更多在“PPO策略具體怎么做”及“對PPO的直覺理解”上。
二、NLP中的強化學習
我們在第一部分介紹了通用強化學習的流程,那么我們要怎么把這個流程對應到NLP任務中呢?換句話說,NLP任務中的智能體、環境、狀態、動作等等,都是指什么呢?
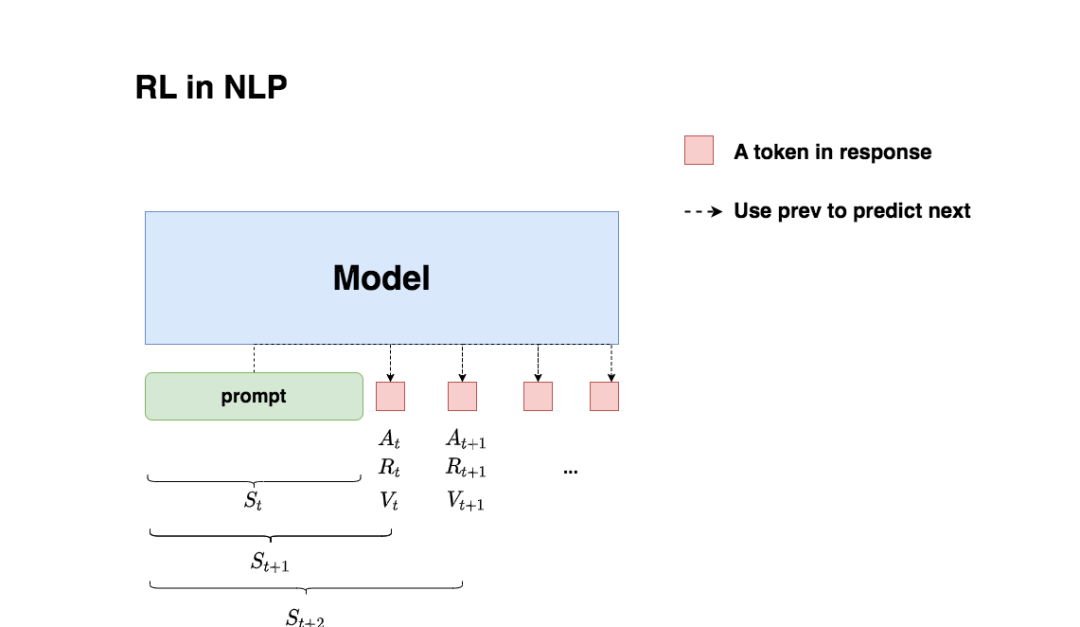
回想一下我們對NLP任務做強化學習(RLHF)的目的:我們希望給模型一個prompt,讓模型能生成符合人類喜好的response。再回想一下gpt模型做推理的過程:每個時刻只產生一個token,即token是一個一個蹦出來的,先有上一個token,再有下一個token。
復習了這兩點,現在我們可以更好解讀上面這張圖了:
-
我們先喂給模型一個prompt,期望它能產出符合人類喜好的response
-
在時刻,模型根據上文,產出一個token,這個token即對應著強化學習中的動作,我們記為。因此不難理解,在NLP語境下,強化學習任務的動作空間就對應著詞表。
-
在時刻,模型產出token 對應著的即時收益為,總收益為(復習一下,蘊含著“即時收益”與“未來收益”兩個內容)。這個收益即可以理解為“對人類喜好的衡量”。此刻,模型的狀態從變為,也就是從“上文”變成“上文 + 新產出的token”
-
在NLP語境下,智能體是語言模型本身,環境則對應著它產出的語料
這樣,我們就大致解釋了NLP語境下的強化學習框架,不過針對上面這張圖,你可能還有以下問題:
(1)問題1:圖中的下標是不是寫得不太對?例如根據第一部分的介紹,應該對應著,應該對應著,以此類推?
答:你說的對。但這里我們不用太糾結下標的問題,只需要記住在對應的response token位置,會產生相應的即時獎勵和總收益即可。之所以用圖中這樣的下標,是更方便我們后續理解代碼。
(2)問題2:我知道肯定是由語言模型產生的,那么是怎么來的呢,也是語言模型產生的嗎?
答:先直接說結論,是由我們的語言模型產生的,則分別由另外兩個模型來產生,在后文中我們會細說。
(3)問題3:語言模型的參數在什么時候更新?是觀測到一個,就更新一次參數,然后再去產生嗎?
答:當然不是。你只看到某個時刻的收益,就急著用它更新模型,這也太莽撞了。我們肯定是要等有足夠的觀測數據了(例如等模型把完整的response生成完),再去更新它的參數。這一點我們也放在后文細說。
(4)問題4:再談談吧,在NLP的語境下我還是不太理解它們。
答:
- 首先,“收益”的含義是“對人類喜好的衡量”
- :即時收益,指語言模型當下產生token 帶來的收益
- :實際期望總收益(即時+未來),指對語言模型“當下產生token ,一直到整個response生產結束”后的期收益預估。因為當下語言模型還沒產出后的token,所以我們只是對它之后一系列動作的收益做了估計,因而稱為“期望總收益”。
三、RLHF中的四個重要角色
在本節中,我們在第二部分的基礎上更進一步:更詳細理清NLP語境下RLHF的運作流程。
我們從第二部分中已經知道:生成token 和對應收益的并不是一個模型。那么在RLHF中到底有幾個模型?他們是怎么配合做訓練的?而我們最終要的是哪個模型?
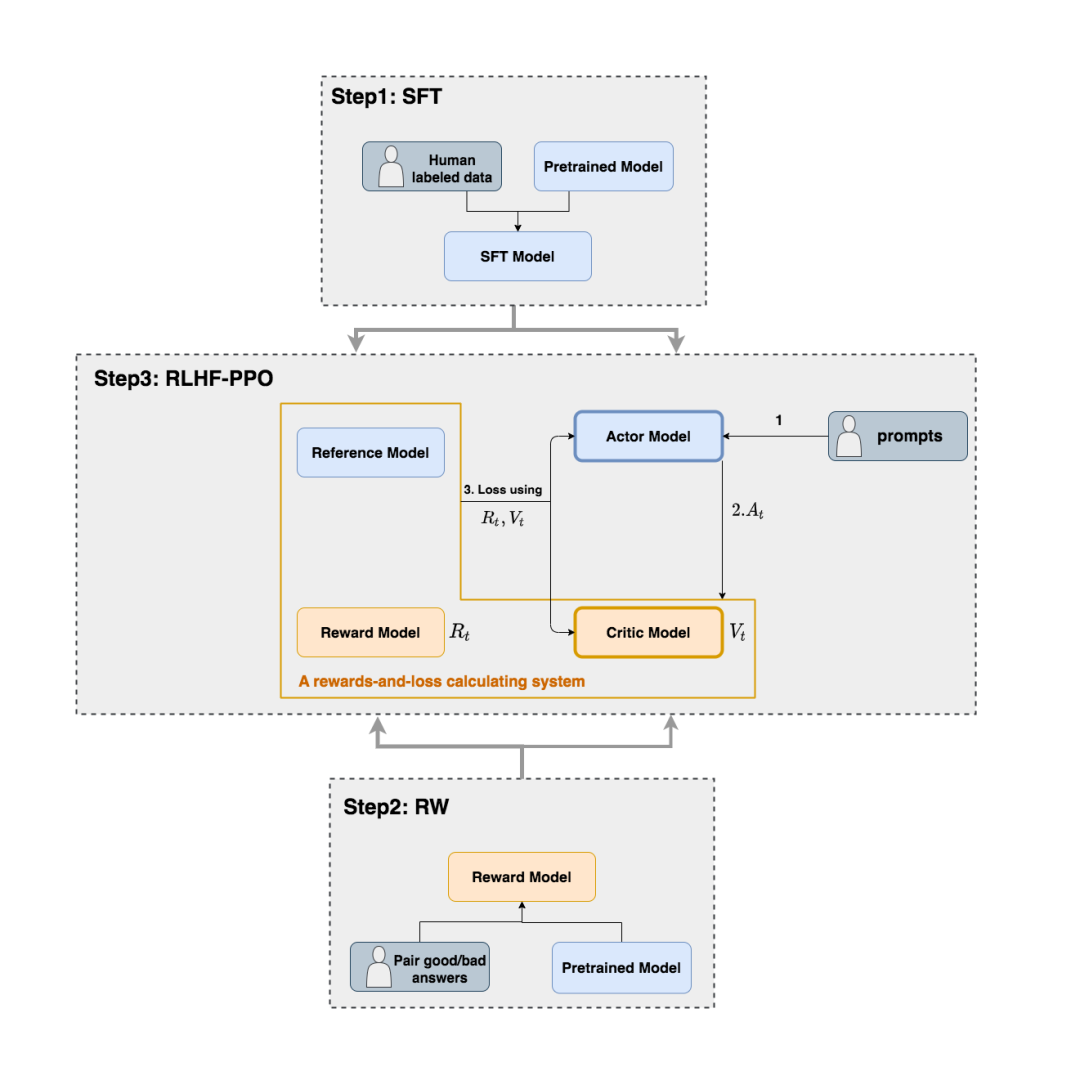
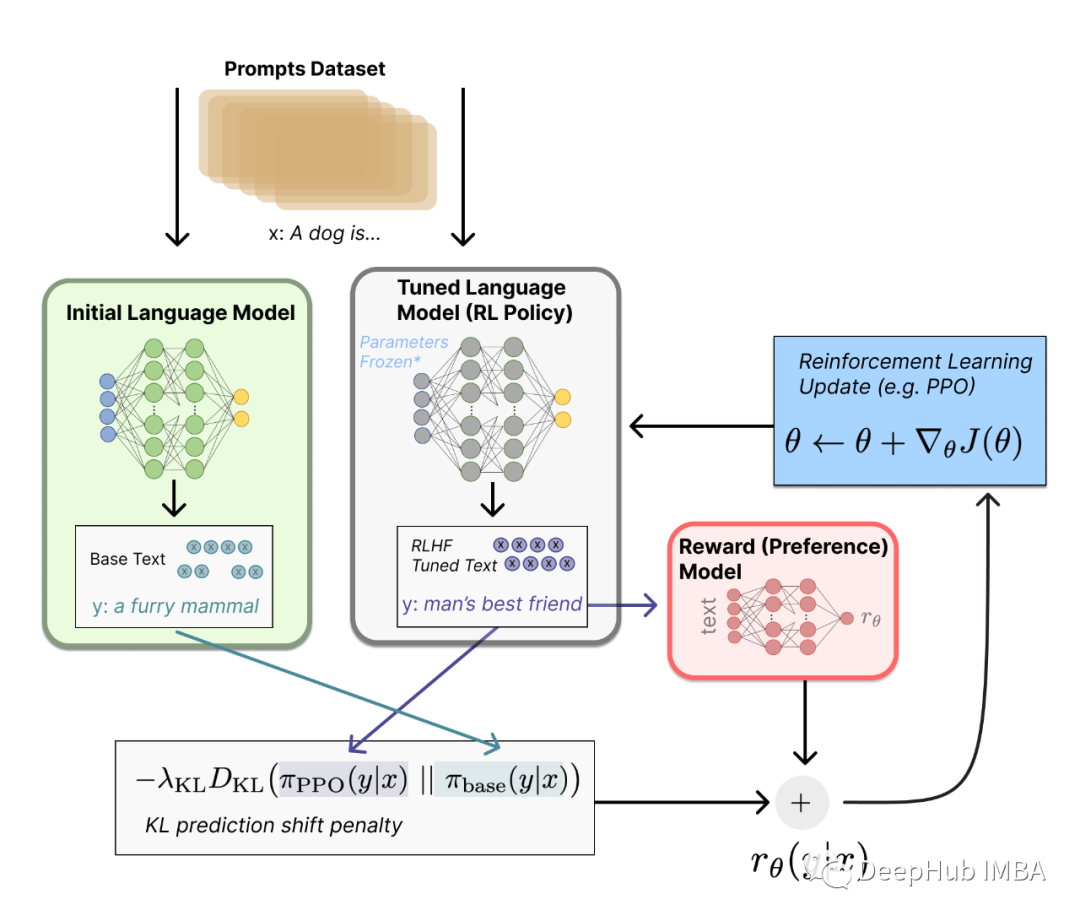
如上圖,在RLHF-PPO階段,一共有四個主要模型,分別是:
- Actor Model:演員模型,這就是我們想要訓練的目標語言模型
- Critic Model:評論家模型,它的作用是預估總收益
- Reward Model:獎勵模型,它的作用是計算即時收益
- Reference Model:參考模型,它的作用是在RLHF階段給語言模型增加一些“約束”,防止語言模型訓歪(朝不受控制的方向更新,效果可能越來越差)
其中:
- Actor/Critic Model在RLHF階段是需要訓練的(圖中給這兩個模型加了粗邊,就是表示這個含義);而Reward/Reference Model是參數凍結的。
- Critic/Reward/Reference Model共同組成了一個“獎勵-loss”計算體系(我自己命名的,為了方便理解),我們綜合它們的結果計算loss,用于更新Actor和Critic Model
我們把這四個部分展開說說。
3.1 Actor Model (演員模型)
正如前文所說,Actor就是我們想要訓練的目標語言模型。我們一般用SFT階段產出的SFT模型來對它做初始化。
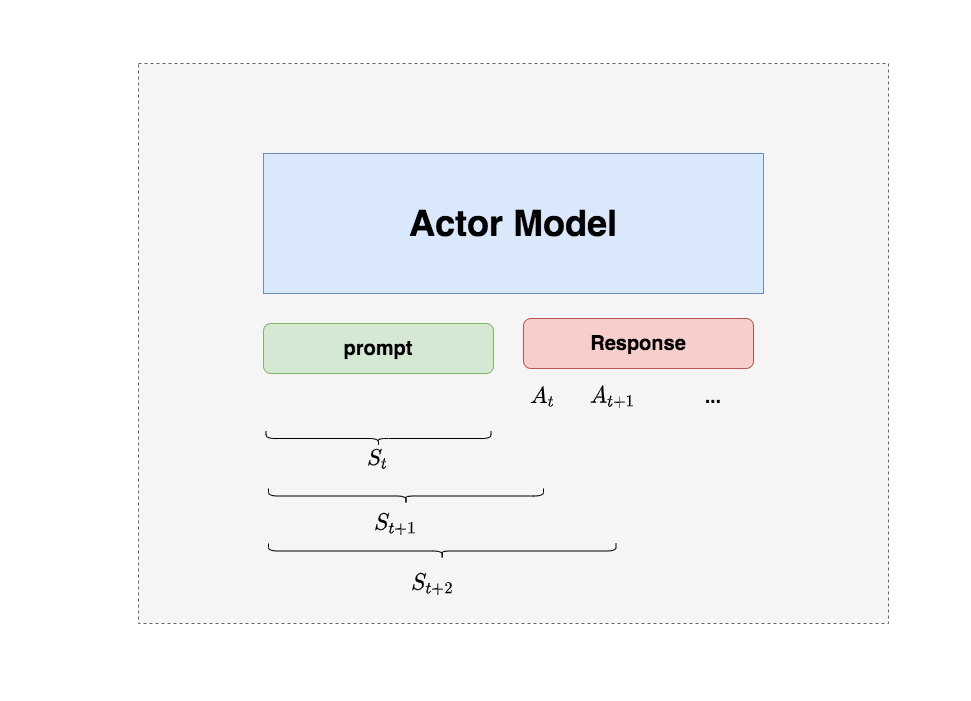
我們的最終目的是讓Actor模型能產生符合人類喜好的response。所以我們的策略是,先喂給Actor一條prompt(這里假設batch_size = 1,所以是1條prompt),讓它生成對應的response。然后,我們再將“prompt + response"送入我們的“獎勵-loss”計算體系中去算得最后的loss,用于更新actor。
3.2 Reference Model(參考模型)
Reference Model(以下簡稱Ref模型)一般也用SFT階段得到的SFT模型做初始化,在訓練過程中,它的參數是凍結的。Ref模型的主要作用是防止Actor”訓歪”,那么它具體是怎么做到這一點的呢?
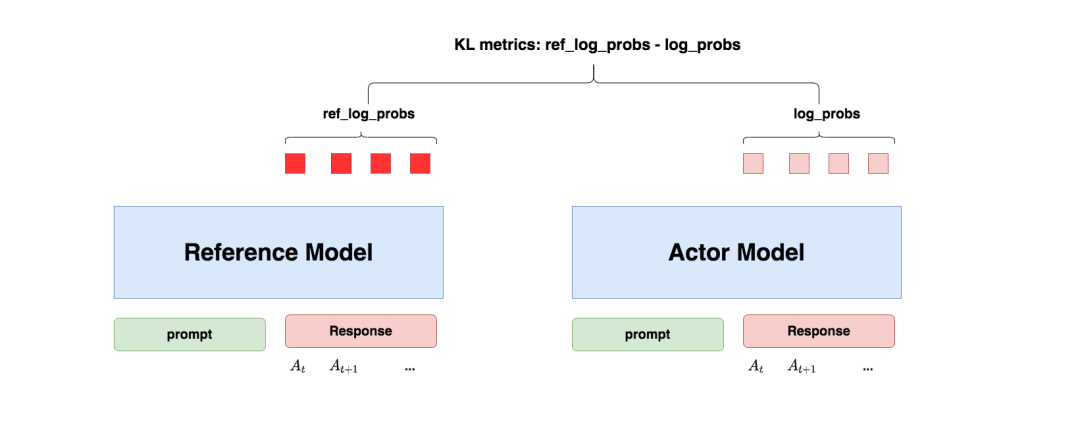
“防止模型訓歪”換一個更詳細的解釋是:我們希望訓練出來的Actor模型既能達到符合人類喜好的目的,又盡量讓它和SFT模型不要差異太大。簡言之,我們希望兩個模型的輸出分布盡量相似。那什么指標能用來衡量輸出分布的相似度呢?我們自然而然想到了KL散度。
如圖所示:
-
對Actor模型,我們喂給它一個prompt,它正常輸出對應的response。那么response中每一個token肯定有它對應的log_prob結果呀,我們把這樣的結果記為log_probs
-
對Ref模型,我們把Actor生成的"prompt + response"喂給它,那么它同樣能給出每個token的log_prob結果,我們記其為ref_log_probs
-
那么這兩個模型的輸出分布相似度就可以用ref_log_probs - log_probs來衡量,我們可以從兩個方面來理解這個公式:
-
從直覺上理解,ref_log_probs越高,說明Ref模型對Actor模型輸出的肯定性越大。即Ref模型也認為,對于某個,輸出某個的概率也很高()。這時可以認為Actor模型較Ref模型沒有訓歪
-
從KL散度上理解,
,這個值越小意味著兩個分布的相似性越高。而這個值越小等價于ref_log_probs - log_probs越大
-
注:你可能已經注意到,按照KL散度的定義,這里寫成log_probs - ref_log_probs更合適一些。這里之所以寫成ref_log_probs - log_probs,是為了方便大家從直覺上了解這個公式。
現在,我們已經知道怎么利用Ref模型和KL散度來防止Actor訓歪了。KL散度將在后續被用于loss的計算,我們在后文中會詳細解釋。
3.3 Critic Model(評論家模型)
Critic Model用于預測期望總收益,和Actor模型一樣,它需要做參數更新。實踐中,Critic Model的設計和初始化方式也有很多種,例如和Actor共享部分參數、從RW階段的Reward Model初始化而來等等。我們講解時,和deepspeed-chat的實現保持一致:從RW階段的Reward Model初始化而來。
你可能想問:訓練Actor模型我能理解,但我還是不明白,為什么要單獨訓練一個Critic模型用于預測收益呢?
這是因為,當我們在前文討論總收益(即時 + 未來)時,我們是站在上帝視角的,也就是這個就是客觀存在的、真正的總收益。但是我們在訓練模型時,就沒有這個上帝視角加成了,也就是在時刻,我們給不出客觀存在的總收益,我們只能訓練一個模型去預測它。
所以總結來說,在RLHF中,我們不僅要訓練模型生成符合人類喜好的內容的能力(Actor),也要提升模型對人類喜好量化判斷的能力(Critic)。這就是Critic模型存在的意義。我們來看看它的大致架構:
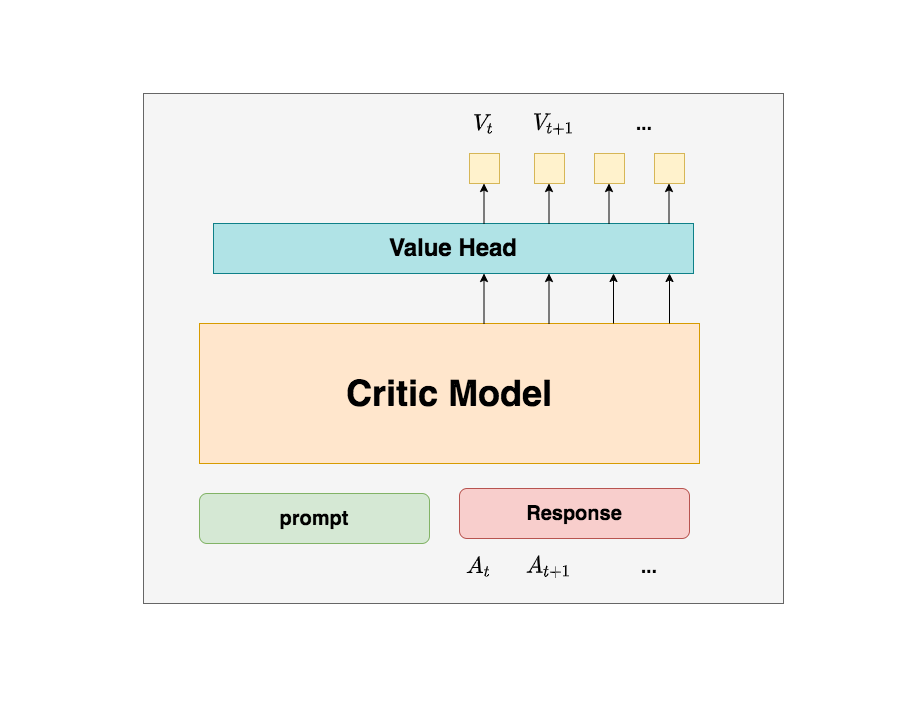
deepspeed-chat采用了Reward模型作為它的初始化,所以這里我們也按Reward模型的架構來簡單畫畫它。你可以簡單理解成,Reward/Critic模型和Actor模型的架構是很相似的(畢竟輸入都一樣),同時,它在最后一層增加了一個Value Head層,該層是個簡單的線形層,用于將原始輸出結果映射成單一的值。
在圖中,表示Critic模型對時刻及未來(response完成)的收益預估。
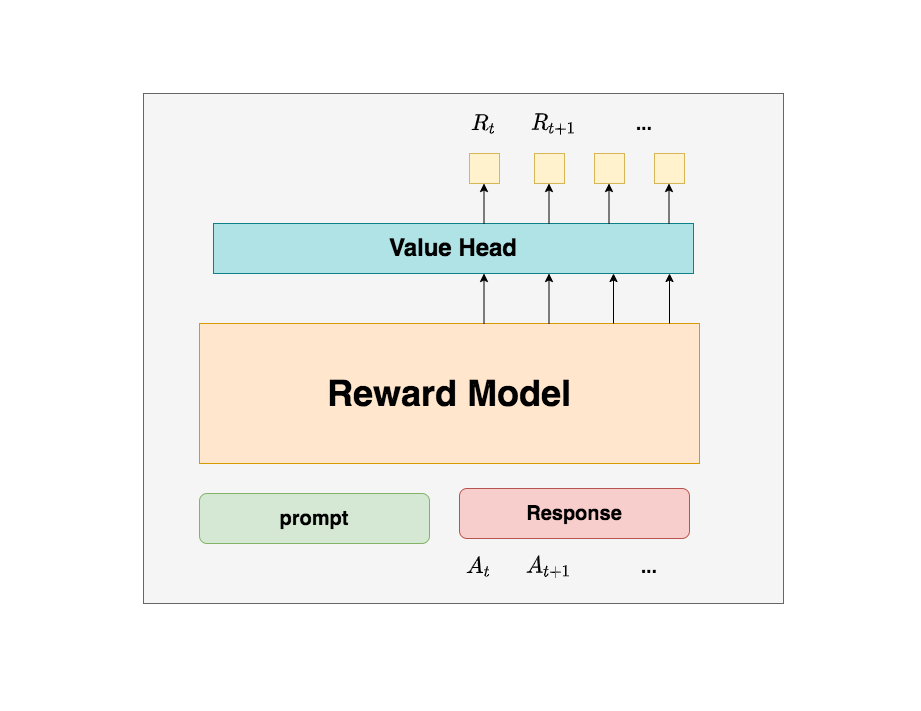
3.4 Reward Model(獎勵模型)
Reward Model用于計算生成token 的即時收益,它就是RW階段所訓練的獎勵模型,在RLHF過程中,它的參數是凍結的。
你可能想問:為什么Critic模型要參與訓練,而同樣是和收益相關的Reward模型的參數就可以凍結呢?
這是因為,Reward模型是站在上帝視角的。這個上帝視角有兩層含義:
- 第一點,Reward模型是經過和“估算收益”相關的訓練的,因此在RLHF階段它可以直接被當作一個能產生客觀值的模型。
- 第二點,Reward模型代表的含義就是“即時收益”,你的token 已經產生,因此即時收益自然可以立刻算出。
你還可能想問:我已經用Critic預測出了,而這個包含了“即時”和“未來”的概念,那我還需要代表“即時”的做什么呢?直接用不就好了嗎?
為了解答這個問題,我們先回顧下1.2部分中給出的價值函數:
這個函數告訴我們,我們當前可以用兩個結果來表示時刻的總收益:
-
結果1:Critic模型預測的
-
結果2:Reward模型預測的和critic模型預測的
那么哪一個結果更靠近上帝視角給出的客觀值呢?當然是結果2,因為結果1全靠預測,而結果2中的是事實數據。
我們知道Critic模型也是參與參數更新的,我們可以用MSE(上帝視角的客觀收益-Critic模型預測的收益)來衡量它的loss。但是上帝視角的客觀收益我們是不知道的,只能用已知事實數據去逼近它,所以我們就用來做近似。這就是同時存在的意義
Reward模型和critic模型非常相似,這里我們就只給出架構圖,不再做過多的說明。關于Reward模型的訓練過程,后續有時間也會出個原理和代碼解析。
四、RLHF中的loss計算
到目前為止,我們已經基本了解了RLHF的訓練框架,以及其中的四個重要角色(訓練一個RLHF,有4個模型在硬件上跑,可想而知對存儲的壓力)。在本節中,我們一起來解讀RLHF的loss計算方式。在解讀中,我們會再一次理一遍RLHF的整體訓練過程,填補相關細節。在這之后,我們就可以來看代碼解析了。
在第三部分的講解中,我們知道Actor和Critic模型都會做參數更新,所以我們的loss也分成2個:
-
Actor loss:用于評估Actor是否產生了符合人類喜好的結果,將作用于Actor的BWD上。
-
Critic loss:用于評估Critic是否正確預測了人類的喜好,將作用于Critic的BWD上。
我們詳細來看這兩者。
4.1 Actor loss
(1)直觀設計
我們先來看一個直觀的loss設計方式:
-
Actor接收到當前上文,產出token()
-
Critic根據,產出對總收益的預測
-
那么Actor loss可以設計為:
求和符號表示我們只考慮response部分所有token的loss,為了表達簡便,我們先把這個求和符號略去(下文也是同理),也就是說:
我們希望minimize這個actor_loss。
這個設計的直觀解釋是:
- 當時,意味著Critic對Actor當前采取的動作給了正向反饋,因此我們就需要在訓練迭代中提高,這樣就能達到減小loss的作用。
- 當時,意味著Critic對Actor當前采取的動作給了負向反饋,因此我們就需要在訓練迭代中降低,這樣就能到達到減小loss的作用。
一句話總結:這個loss設計的含義是,對上文而言,如果token產生的收益較高,那就增大它出現的概率,否則降低它出現的概率。
(2)引入優勢(Advantage)
在開始講解之前,我們舉個小例子:
假設在王者中,中路想支援發育路,這時中路有兩種選擇:1. 走自家野區。2. 走大龍路。
中路選擇走大龍路,當她做出這個決定后,Critic告訴她可以收1個人頭。結果,此刻對面打野正在自家采靈芝,對面也沒有什么茍草英雄,中路一路直上,最終收割2個人頭。
因為實際收割的人頭比預期要多1個,中路嘗到了甜頭,所以她增大了“支援上路走大龍路”的概率。
這個多出來的“甜頭”,就叫做“優勢”(Advantage)。
對NLP任務來說,如果Critic對的總收益預測為,但實際執行后的總收益是,我們就定義優勢為:
我們用替換掉,則此刻actor_loss變為:
(3)重新設計
總結一下,到目前為止,我們的actor_loss形式為:
其中,
同時注意,這個actor_loss應該是response的所有token loss的sum或者avg。這里為了表達方便,我們的公式略去了求和或求平均的符號。
按照這個理解,應該表示每個Actor產出token 帶來的即時收益,正如下圖所示(其中表示最后一個時刻):
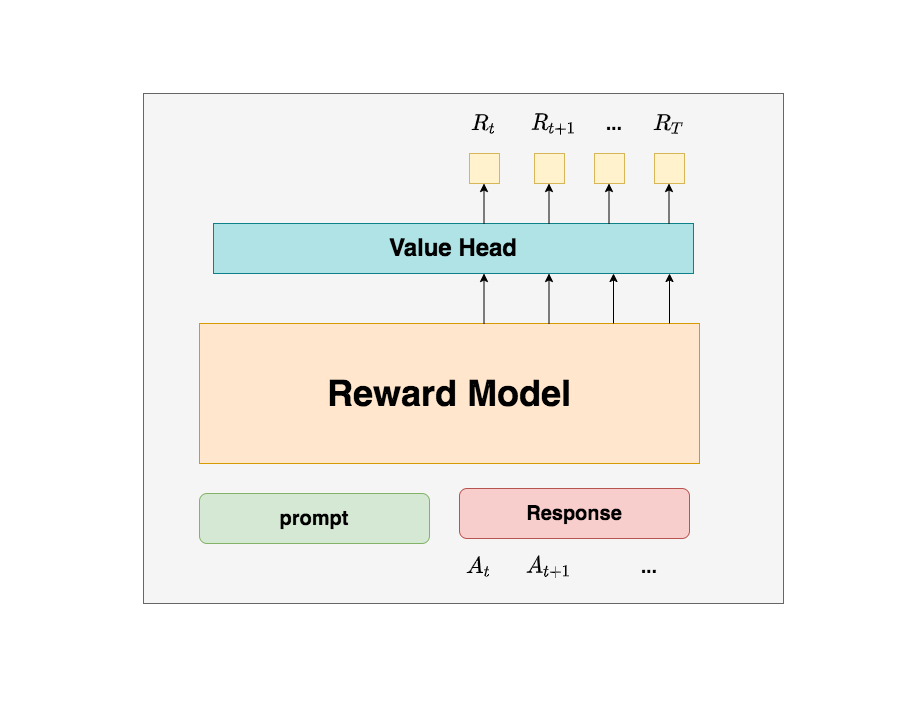
但在deepspeed-chat的RLHF實踐中,對做了另一種設計:
-
:常量,可以理解成是一個控制比例的縮放因子,在deepspeed-chat中默認設為0.1
-
:這一項你是不是非常眼熟,這就是我們在3.2部分介紹的Actor和Ref模型間的KL散度呀,寫成更容易理解的形式,就是ref_log_probs - log_probs。在3.2中我們說過,為了防止模型訓歪,我們需要把這個KL散度加入loss計算中,所以這里我們就在做這件事
基于這些,上面這個對的設計可理解成:
- 當時,我們更加關心Actor是否有在Ref的約束下生產token
- 當時,我們不僅關心Actor是否遵從了Ref的約束,也關心真正的即時收益
需要注意的是,的設計并不只有這一種(其實我覺得只取時刻的不太合理,deepspeed在自己的代碼注釋中也有提過,可以嘗試把最后一個時刻的替換成所有token的平均值;或者在我來看時也應該納入對的考慮)。
代碼實踐如下:
defcompute_rewards(self,prompts,log_probs,ref_log_probs,reward_score,
action_mask):
"""
reward_function:計算最終的reward分數
復習一下幾個相關參數的默認值:
self.kl_ctl=0.1
self.clip_reward_value=5
對于batch中的某個prompt來說,它最終的reward分數為:
(1)先計算actor和ref_model的logit相似度:-self.kl_ctl *(log_probs - ref_log_probs)
其實寫成self.kl_ctl*(ref_log_probs-log_probs)更好理解些
這個值越大,說明ref_model對actor生成的結果的認可度越高(即表明rlhf沒有訓歪),
沒有訓歪的情況下我們也應該給模型一些獎勵,這個獎勵就是self.kl_ctl*(ref_log_probs-log_probs)
(2)由于我們只取最后一個token對應位置的分數作為reward_score,因此我們只需要:
self.kl_ctl*(ref_log_probs-log_probs)的最后一位+reward_score
(3)同時我們對reward_score也做了大小限制,最大不超過self.clip_reward_value(超過統一給成self.clip_reward_value),
最小不低于-self.clip_reward_value(低于統一給成-self.clip_reward_value)
(4)最后返回的rewards大小為:(batch_size, 各條數據的長度),對batch中的每條數據來說:
- response的最后一位:self.kl_ctl *(ref_log_probs - log_probs)的最后一位+ reward_score
- response的其余位置:self.kl_ctl *(ref_log_probs - log_probs)
"""
kl_divergence_estimate=-self.kl_ctl*(log_probs-ref_log_probs)
rewards=kl_divergence_estimate
#---------------------------------------------------------------------------------------------------
#response開始的位置
#(因為我們對prompt做過padding處理,因此batch中每個prompt長度一致,也就意味著每個response開始的位置一致)
#(所以這里start是不加s的,只是一個int)
#---------------------------------------------------------------------------------------------------
start=prompts.shape[1]-1
#---------------------------------------------------------------------------------------------------
#response結束的位置
#(因為一個batch中,每個response的長度不一樣,所以response的結束位置也不一樣)
#(所以這里end是加s的,ends的尺寸是(batch_size,)
#---------------------------------------------------------------------------------------------------
ends=start+action_mask[:,start:].sum(1)+1
#---------------------------------------------------------------------------------------------------
#對rewards_score做限制
#---------------------------------------------------------------------------------------------------
reward_clip=torch.clamp(reward_score,-self.clip_reward_value,
self.clip_reward_value)
batch_size=log_probs.shape[0]
forjinrange(batch_size):
rewards[j,start:ends[j]][-1]+=reward_clip[j]#
returnrewards
(4)重新設計優勢
好,再總結一下,目前為止我們的actor_loss為:
其中,
同時,我們對進行來改造,使其能夠衡量Actor模型是否遵從了Ref模型的約束。
現在我們把改造焦點放在上,回想一下,既然對于收益而言,分為即時和未來,那么對于優勢而言,是不是也能引入對未來優勢的考量呢?這樣,我們就可以把改寫成如下形式:
(熟悉強化學習的朋友應該能一眼看出這是GAE,這里我們不打算做復雜的介紹,一切都站在直覺的角度理解)
其中,新引入的也是一個常量,可將其理解為權衡因子,直覺上看它控制了在計算當前優勢時對未來優勢的考量。(從強化學習的角度上,它控制了優勢估計的方差和偏差)
看到這里,你可能想問:這個代表未來優勢的,我要怎么算呢?
注意到,對于最后一個時刻,它的未來收益()和未來優勢()都是0,也就是,這是可以直接算出來的。而有了,我們不就能從后往前,通過動態規劃的方法,把所有時刻的優勢都依次算出來了嗎?
代碼實踐如下(其中返回值中的returns表示實際收益,將被用于計算Critic模型的loss,可以參見4.2,其余細節都在代碼注釋中):
defget_advantages_and_returns(self,values,rewards,start):
"""
Adoptedfromhttps://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
沒有引入GAE前的t時刻的優勢值:
detal_t=r_t+gamma*V_t+1-V_t
其中:
-r_t表示t時刻的即時收益
-V_t+1表示未來時刻的預期收益
-r_t+gamma*V_t+1可理解成t時刻的實際預期收益
-V_t可理解成t時刻的預估預期收益(是模型,例如criticmodel自己估算出來的)
引入GAE后的t時刻的優勢值:
A_t=delta_t+gamma*lambda*A_t+1
粗暴理解為在t時刻時,不僅考慮當下優勢,還考慮了未來的優勢
為了知道A_t, 我們得知道A_t+1,所以在本算法中采取了從后往前做動態規劃求解的方法,也即:
假設T是最后一個時刻,則有A_T+1=0,所以有:A_T=delta_T
知道了A_T,就可以依次往前倒推,把A_t-1,A_t-2之類都算出來了
引入GAE后t時刻的實際預期收益
returns_t=A_t+V_t
=delta_t+gamma*lambda*A_t+1+V_t
=r_t+gamma*V_t+1-V_t+gamma*lambda*A_t+1+V_t
=r_t+gamma*(V_t+1+lambda*A_t+1)
注意,這里不管是advantages還是returns,都只算response的部分
"""
#Adoptedfromhttps://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam=0
advantages_reversed=[]
length=rewards.size()[-1]
#注意這里用了reversed,是采取從后往前倒推計算的方式
fortinreversed(range(start,length)):
nextvalues=values[:,t+1]ift1else0.0
delta=rewards[:,t]+self.gamma*nextvalues-values[:,t]
lastgaelam=delta+self.gamma*self.lam*lastgaelam
advantages_reversed.append(lastgaelam)
advantages=torch.stack(advantages_reversed[::-1],dim=1)#優勢
returns=advantages+values[:,start:]#實際收益
#values:預期收益
returnadvantages.detach(),returns
(5) PPO-epoch: 引入新約束
總結一下,目前為止我們的actor_loss為:
其中,
同時
- 我們已經對進行來改造,使其能夠衡量Actor模型是否遵從了Ref模型的約束。
- 我們已經對進行改造,使其不僅考慮了當前時刻的優勢,還考慮了未來的優勢
基于這些改造,我們重新理一遍RLHF-PPO的訓練過程。
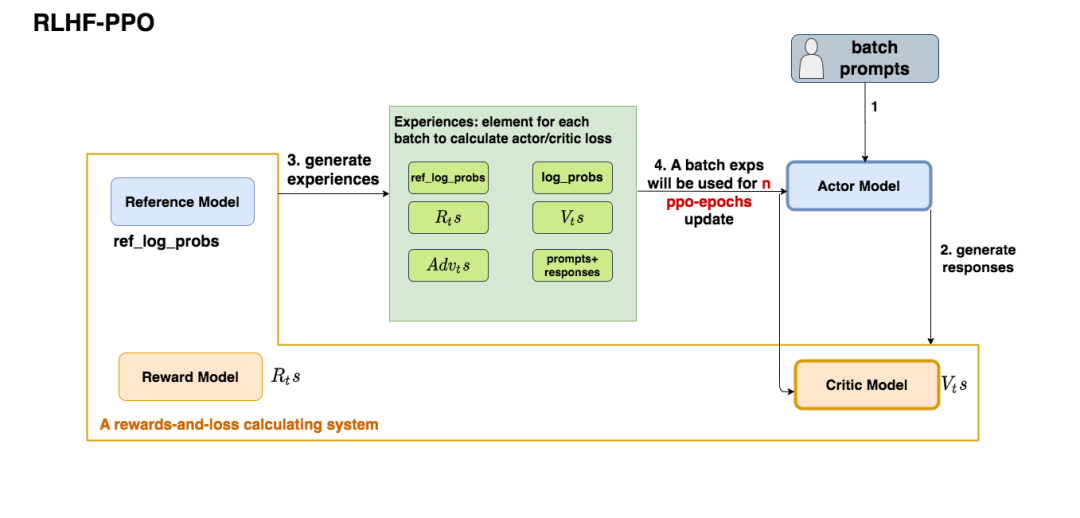
-
第一步,我們準備一個batch的prompts
-
第二步,我們將這個batch的prompts喂給Actor模型,讓它生成對應的responses
-
第三步,我們把prompt+responses喂給我們的Critic/Reward/Reference模型,讓它生成用于計算actor/critic loss的數據,按照強化學習的術語,我們稱這些數據為經驗(experiences)。critic loss我們將在后文做詳細講解,目前我們只把目光聚焦到actor loss上
-
第四步,我們根據這些經驗,實際計算出actor/critic loss,然后更新Actor和Critic模型
這些步驟都很符合直覺,但是細心的你肯定發現了,文字描述中的第四步和圖例中的第四步有差異:圖中說,這一個batch的經驗值將被用于n次模型更新,這是什么意思呢?
我們知道,在強化學習中,收集一個batch的經驗是非常耗時的。對應到我們RLHF的例子中,收集一次經驗,它要等四個模型做完推理才可以,正是因此,一個batch的經驗,只用于計算1次loss,更新1次Actor和Critic模型,好像有點太浪費了。
所以,我們自然而然想到,1個batch的經驗,能不能用來計算ppo-epochs次loss,更新ppo-epochs次Actor和Critic模型?簡單寫一下偽代碼,我們想要:
#--------------------------------------------------------------
#初始化RLHF中的四個模型
#--------------------------------------------------------------
actor,critic,reward,ref=initialize_models()
#--------------------------------------------------------------
#訓練
#--------------------------------------------------------------
#對于每一個batch的數據
foriinsteps:
#先收集經驗值
exps=generate_experience(prompts,actor,critic,reward,ref)
#一個batch的經驗值將被用于計算ppo_epochs次loss,更新ppo_epochs次模型
#這也意味著,當你計算一次新loss時,你用的是更新后的模型
forjinppo_epochs:
actor_loss=cal_actor_loss(exps,actor)
critic_loss=cal_critic_loss(exps,critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()
而如果我們想讓一個batch的經驗值被重復使用ppo_epochs次,等價于我們想要Actor在這個過程中,模擬和環境交互ppo_epochs次。舉個例子:
-
如果1個batch的經驗值只使用1次,那么在本次更新完后,Actor就吃新的batch,正常和環境交互,產出新的經驗值
-
但如果1個batch的經驗值被使用ppo_epochs次,在這ppo_epochs中,Actor是不吃任何新數據,不做任何交互的,所以我們只能讓Actor“模擬”一下和環境交互的過程,吐出一些新數據出來。
那怎么讓Actor模擬呢?很簡單,讓它觀察一下之前的數據長什么樣,讓它依葫蘆畫瓢,不就行了嗎?我們假設最開始吃batch,吐出經驗的actor叫,而在偽代碼中,每次做完ppo_epochs而更新的actor叫,那么我們只要盡量保證每次更新后的能模仿最開始的那個,不就行了嗎?
誒!是不是很眼熟!兩個分布,通過什么方法讓它們相近!那當然是KL散度!所以,再回到我們的actor_loss上來,它現在就可被改進成:
我們再稍作一些改動將log去掉(這個其實不是“稍作改動去掉log”的事,是涉及到PPO中重要性采樣的相關內容,大家有興趣可以參考https://www.cnblogs.com/xingzheai/p/15931681.html):
其中,表示真正吃了batch,產出經驗值的Actor;P表示ppo_epochs中實時迭代更新的Actor,它在模仿的行為。所以這個公式從直覺上也可以理解成:在Actor想通過模擬交互的方式,使用一個batch的經驗值更新自己時,它需要收到真正吃到batch的那個時刻的Actor的約束,這樣才能在有效利用batch,提升訓練速度的基礎上,保持訓練的穩定。
但是,謹慎的你可能此時又有新的擔心了:雖然我們在更新Actor的過程中用做了約束,但如的約束能力不夠,比如說還是超出了可接受的范圍,那怎么辦?
很簡單,那就剪裁(clip)它吧!
我們給設置一個范圍,例如(0.8 ,1.2),也就是如果這個值一旦超過1.2,那就統一變成1.2;一旦小于0.8,那就統一變成0.8。這樣就能保證和的分布相似性在我們的掌控之內了。此時actor_loss變為:
這時要注意,如果超過變化范圍,將強制設定為一個常數后,就說明這一部分的loss和Actor模型無關了,而這項本身也與Actor無關。所以相當于,在超過約束范圍時,我們停止對Actor模型進行更新。
整體代碼如下:
defactor_loss_fn(self,logprobs,old_logprobs,advantages,mask):
"""
logprobs:實時計算的,response部分的prob(只有這個是隨著actor實時更新而改變的)
old_logprobs:老策略中,response部分的prob (這個是固定的,不隨actor實時更新而改變)
advantages:老策略中,response部分每個token對應的優勢(這個是固定的,不隨actor實時更新而改變)
mask:老策略中,response部分對應的mask情況這個是固定的,不隨actor實時更新而改變)
之所以要引入logprobs計算actor_loss,是因為我們不希望策略每次更新的幅度太大,防止模型訓歪
self.cliprange:默認值是0.2
"""
##policygradientloss
#-------------------------------------------------------------------------------------
#計算新舊策略間的KL散度
#-------------------------------------------------------------------------------------
log_ratio=(logprobs-old_logprobs)*mask
ratio=torch.exp(log_ratio)
#-------------------------------------------------------------------------------------
#計算原始loss和截斷loss
#-------------------------------------------------------------------------------------
pg_loss1=-advantages*ratio
pg_loss2=-advantages*torch.clamp(ratio,1.0-self.cliprange,1.0+self.cliprange)
pg_loss=torch.sum(torch.max(pg_loss1,pg_loss2)*mask)/mask.sum()#最后是取每個非mask的responsetoken的平均loss作為最終loss
returnpg_loss
(6)Actor loss小結
(1)~(5)中我們一步步樹立了actor_loss的改進過程,這里我們就做一個總結吧:
其中:
-
-
我們已經對進行來改造,使其能夠衡量Actor模型是否遵從了Ref模型的約束
-
我們已經對進行改造,使其不僅考慮了當前時刻的優勢,還考慮了未來的優勢
-
我們重復利用了1個batch的數據,使本來只能被用來做1次模型更新的它現在能被用來做ppo_epochs次模型更新。我們使用真正吃了batch,產出經驗值的那個時刻的Actor分布來約束ppo_epochs中更新的Actor分布
-
我們考慮了剪裁機制(clip),在ppo_epochs次更新中,一旦Actor的更新幅度超過我們的控制范圍,則不對它進行參數更新。
4.2 Critic loss
我們知道,1個batch產出的經驗值,不僅被用來更新Actor,還被用來更新Critic。對于Critic loss,我們不再像Actor loss一樣給出一個“演變過程”的解讀,我們直接來看它最后的設計。
首先,在之前的解說中,你可能有這樣一個印象:
-
:Critic對t時刻的總收益的預估,這個總收益包含即時和未來的概念(預估收益)
-
:Reward計算出的即時收益,Critic預測出的及之后時候的收益的折現,這是比更接近t時刻真值總收益的一個值(實際收益)
所以,我們的第一想法是:
現在,我們對“實際收益”和“預估收益”都做一些優化。
(1)實際收益優化
我們原始的實際收益為,但是當我們在actor_loss中引入“優勢”的概念時,“優勢”中刻畫了更為豐富的實時收益信息,所以,我們將實際收益優化為:
(2)預估收益優化
我們原始的預估收益為。
類比于Actor,Critic模型在ppo_epochs的過程中也是不斷更新的。所以這個可以理解成是,也就是真正吃了batch,參與產出經驗的那個時候的Critic產出的收益預測結果。
我們同樣想用舊模型去約束新模型,但對于Critic我們采用的約束策略就比較簡單了,我們直接看代碼,從中可以看出,我們用老設計了了一個變動范圍,然后用這個變動范圍去約束新
#self.cliprange_value是一個常量
#old_values:老critic的預測結果
# values:新critic的預測結果
values_clipped=torch.clamp(
values,
old_values-self.cliprange_value,
old_values+self.cliprange_value,
)
那么最終我們就取實際收益和預估收益的MSE做為loss就好,這里注意,計算實際收益時都是老Critic(真正吃了batch的那個)產出的結果,而預估收益是隨著ppo_epochs而變動的。
代碼如下:
defcritic_loss_fn(self,values,old_values,returns,mask):
"""
values:實時critic跑出來的預估預期收益(是變動的,隨著ppoepoch迭代而改變)
old_values:老critic跑出來的預估預期收益(是固定值)
returns:實際預期收益
mask:response部分的mask
self.cliprange_value=0.2
"""
##valueloss
#用舊的value去約束新的value
values_clipped=torch.clamp(
values,
old_values-self.cliprange_value,
old_values+self.cliprange_value,
)
ifself.compute_fp32_loss:
values=values.float()
values_clipped=values_clipped.float()
#critic模型的loss定義為(預估預期收益-實際預期收益)**2
vf_loss1=(values-returns)**2
vf_loss2=(values_clipped-returns)**2
vf_loss=0.5*torch.sum(
torch.max(vf_loss1,vf_loss2)*mask)/mask.sum()#同樣,最后也是把criticloss平均到每個token上
returnvf_loss
至此,關于RLHF-PPO訓練的核心部分和代碼解讀就講完了,建議大家親自閱讀源碼,如果有硬件條件,可以動手實踐。源碼地址:
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning
-
源碼
+關注
關注
8文章
633瀏覽量
29140 -
強化學習
+關注
關注
4文章
266瀏覽量
11214 -
大模型
+關注
關注
2文章
2328瀏覽量
2483
原文標題:圖解大模型RLHF系列之:人人都能看懂的PPO原理與源碼解讀
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
運行tas5086gui軟件后要實現低音要加載cfg文件嗎?
解讀 MEMS 可編程 LVCMOS 振蕩器 SiT1602 系列:精準頻率的創新之選

解讀 MEMS 可編程 LVCMOS 振蕩器 SiT8008 系列:精準與靈活的時脈之選

解讀PyTorch模型訓練過程
這一次,騰訊要讓人人都能「用好」大模型

硬件工程師只要會照著芯片規格書畫外圍電路就夠了嗎?高級硬件工程師多了這項技能
CubeAI-7.0.0生成的C語言代碼,神經網絡運行函數是哪個,輸入輸出分別是哪個變量啊?
微軟4月1日推出生成式AI安全產品“Securit Copilot”
程序中的R地址都是什么意思?怎么樣才能看懂?
大模型Reward Model的trick應用技巧

OneFlow Softmax算子源碼解讀之BlockSoftmax
OneFlow Softmax算子源碼解讀之WarpSoftmax
拆解大語言模型RLHF中的PPO算法
使用Huggingface創建大語言模型RLHF訓練流程





 工商網監
工商網監
評論