") 詳細(xì)分析算力網(wǎng)絡(luò)的發(fā)展
詳細(xì)分析算力網(wǎng)絡(luò)的發(fā)展
2023年12月底,由國家發(fā)展改革委、國家數(shù)據(jù)局、中央網(wǎng)信辦、工業(yè)和信息化部、國家能源局五部門聯(lián)合印發(fā)的《關(guān)于深入實施“東數(shù)西算”工程 加快構(gòu)建全國一體化算力網(wǎng)的實施意見》正式公布。
算力網(wǎng)絡(luò)是未來數(shù)字經(jīng)濟(jì)發(fā)展的核心基礎(chǔ)設(shè)施。要想實現(xiàn)算力網(wǎng)絡(luò)的偉大愿景,還有非常多的底層技術(shù)挑戰(zhàn)需要解決。
接下來若干篇系列文章,“軟硬件融合”公眾號將從技術(shù)的視角,詳細(xì)分析算力網(wǎng)絡(luò)的發(fā)展。
本篇是系列文章的第一篇,算力提升綜述。
01.宏觀算力綜述
算力和性能的區(qū)別在哪里?性能是一個微觀話題,通常的說法是“芯片的性能”,較少說“芯片的算力”(隨著算力的概念深入人心,也有不少人采用單芯片算力的算法)。同時,算力是一個宏觀概念,比如評價一個數(shù)據(jù)中心,通常則采用“算力”這個說法,很少會用“性能”這個說法。
總之,算力和性能本質(zhì)上是一體的,區(qū)別在于性能是微觀概念,算力是宏觀概念。那么算力和性能之間的聯(lián)系是什么?
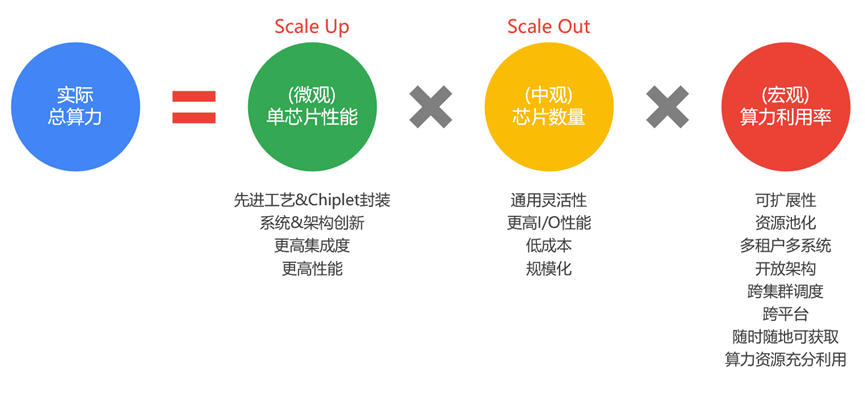
如上圖所示,我們定性分析,可以在性能和算力之間構(gòu)建一個關(guān)聯(lián)的公式。從上述公式可以看到,要想提升宏觀的實際總算力,可以通過三個方法:
方法一,Scale Up方式,提升單芯片的性能。一方面底層先進(jìn)工藝和Chiplet封裝支撐,另一方面越來越多的大算力場景需求,都驅(qū)動著在系統(tǒng)架構(gòu)和微架構(gòu)方面的創(chuàng)新,來實現(xiàn)單芯片層次更高的性能。這是算力提升最本質(zhì)的做法。
方法二,Scale Out方式,提升芯片落地的規(guī)模/數(shù)量。通過增加芯片落地規(guī)模的方式提升總算力,比較好理解。挑戰(zhàn)在于,如何讓芯片更好地增加數(shù)量?芯片要想大規(guī)模落地:需要覆蓋非常多的業(yè)務(wù)場景和業(yè)務(wù)迭代,這就需要芯片具有非常高的通用性;此外,芯片需要支持更大規(guī)模的集群計算。
方法三,則是提高算力利用率。提升算力利用率有很多方法,例如,資源擴(kuò)展性、資源池化、開放架構(gòu)等等。算力網(wǎng)絡(luò),是提升算力利用率的綜合解決方案。
本系列文章聚焦算力網(wǎng)絡(luò),因此,篇幅分配會有很大不同。本篇文章中,將簡要介紹提升算力的三種方式。
02.如何提升單芯片性能?

定性的分析,一個芯片的性能有三個維度:
維度一,指令復(fù)雜度。依據(jù)指令復(fù)雜度,典型的處理器引擎分為CPU、協(xié)處理器、GPU、FPGA、DSA和ASIC六大類。理論上,指令復(fù)雜度越高,性能越好。但實際上,需要考慮系統(tǒng)的通用性,以及目標(biāo)工作任務(wù)的靈活性特征,來選擇合適的處理器引擎。
維度二,運行頻率。運行頻率提升,主要是先進(jìn)工藝,以及更復(fù)雜的流水線設(shè)計。
維度三,并行度。提高并行度比較好理解,并行也主要有同構(gòu)并行、(兩個處理器的)異構(gòu)并行和(三個以上)更多異構(gòu)的并行。
這三個維度里,指令復(fù)雜度提升和運行頻率提升,都受到到各種因素的制約,真正對性能影響最大的則是并行度。提升并行度,不是簡單的復(fù)制,而是需要全面考慮系統(tǒng)工作任務(wù)特征,尋找合適的處理引擎,實現(xiàn)復(fù)雜的并行計算:
同構(gòu)并行,僅指CPU同構(gòu)并行(其他處理器無法單獨存在,需要CPU協(xié)助),摩爾定律已經(jīng)失效,CPU并行性能有局限。
異構(gòu)并行,指CPU+其他加速處理器的并行計算,異構(gòu)并行是兩類處理器的協(xié)同計算。
異構(gòu)融合并行,指的是CPU+兩種以上不同類型或子類型的處理器組成的計算架構(gòu)。因為處理器增多,則需要考慮各個處理器之間的協(xié)同問題。因此,異構(gòu)融合計算,中心在于處理器之間的深度協(xié)作和融合。
03.如何提升芯片的落地規(guī)模?
通用靈活性
芯片只有大規(guī)模落地,才能顯著地提升宏觀算力;不能落地芯片,即使性能再高,與宏觀算力的提升也毫無意義。芯片要想大規(guī)模落地,一定是要覆蓋非常多的業(yè)務(wù)場景,以及非常多的業(yè)務(wù)迭代。這樣,勢必需要芯片具有非常高的通用靈活性。 同時,芯片大規(guī)模落地,成本也是一個非常重要的因素。跟小芯片相比,大算力芯片的成本主要是前期的研發(fā)投入的均攤成本,芯片實際的生產(chǎn)成本反而占比相對較少。只有實現(xiàn)了相對通用的芯片設(shè)計,才能覆蓋更多的場景和迭代,才能攤薄成本。成本下降之后,反過來,進(jìn)一步促進(jìn)芯片的大規(guī)模落地。
高性能網(wǎng)絡(luò)
與此同時,大算力芯片,需要支持大規(guī)模集群和跨集群的計算。更多計算節(jié)點組成的集群/跨集群計算,內(nèi)部流量占據(jù)絕大部分。 以目前流行的大模型計算集群為例,其東西向(內(nèi)部)流量占比超過96%,南北向(外網(wǎng))流量占比僅有3%左右。并且,隨著集群規(guī)模的進(jìn)一步擴(kuò)大,南北向流量占比仍在進(jìn)一步減少。 此外,隨著系統(tǒng)規(guī)模的擴(kuò)大,南北向的流量也是逐漸增加的。兩相疊加,需要個體的芯片的網(wǎng)絡(luò)帶寬指數(shù)級提升,同時需要支持高效的內(nèi)網(wǎng)和外網(wǎng)高性能網(wǎng)絡(luò)。 總之,只有實現(xiàn)了足夠的通用靈活性,以及高性能網(wǎng)絡(luò),才能支撐更高性能更高效率的超大規(guī)模的集群/跨集群計算,才能真正支撐宏觀算力的顯著提升,與此同時降低算力的成本。
04.如何提升算力利用率?
如果每個計算節(jié)點都是孤島,即使某一個節(jié)點算力利用率很高,但更多的節(jié)點可能處于閑置或者低利用率狀態(tài),宏觀地看,其算力利用率必然很低。要想真正提升算力利用率,首先勢必需要把計算節(jié)點池化,形成算力資源池,才好談高利用率的問題。
我們來系統(tǒng)分析一下如何有效地提升算力利用率。
資源可擴(kuò)展性
資源可擴(kuò)展性是一個非常重要的前提條件。 以CPU為例,通過虛擬化,一個物理的CPU核可以分為數(shù)以百計的邏輯CPU核,一個邏輯核可以當(dāng)作CPU的最小粒度;同時,一個CPU芯片有數(shù)十個甚至上百個CPU核,常見的服務(wù)器通常有1-8個CPU芯片,并且還有眾多服務(wù)器組成的計算集群。因此,CPU是可以從1個邏輯核擴(kuò)展到成千上萬的邏輯核的。這就是CPU極致可擴(kuò)展性的體現(xiàn)。 其他的資源,如各類GPU、DSA等各類加速器計算資源、內(nèi)存(Memory)資源、網(wǎng)絡(luò)I/O資源、存儲(Storage)I/O資源等。這些資源,也需要像CPU一樣,具有非常好的擴(kuò)展性。
資源池化
資源具有足夠好的可擴(kuò)展性,物理的資源通過合適粒度進(jìn)行邏輯切分,并且跨物理資源、跨芯片、跨計算節(jié)點,甚至跨集群的資源資源可以組成一個整體,最終形成統(tǒng)一的宏觀資源池。只有形成足夠好的可擴(kuò)展性才能支持靈活的資源池化和資源的靈活分配。
多租戶多系統(tǒng)
多租戶多系統(tǒng)是云計算非常重要的特征,通過多租戶多系統(tǒng)實現(xiàn)資源的共享和成本分?jǐn)偅源藖硖岣咚懔寐屎徒档统杀尽?/p>
開放架構(gòu)
隨著CPU的性能瓶頸,越來越多的異構(gòu)算力成為算力提升的主力。即使某個處理器具有足夠高的可擴(kuò)展性,但一種架構(gòu)的資源,就意味著一個獨立的資源池。這樣,多樣性的異構(gòu)算力,會導(dǎo)致架構(gòu)和生態(tài)的碎片化。通過開放架構(gòu),可以盡可能地實現(xiàn)架構(gòu)的收斂,才能最大化地發(fā)揮資源池化的價值。
跨集群調(diào)度
算力網(wǎng)絡(luò),最核心的價值在于把非常多的各種計算集群連接到一起。因此跨集群的資源共享和業(yè)務(wù)調(diào)度是必然要支持的能力。算力網(wǎng)絡(luò),需要實現(xiàn)跨不同的集群、跨不同的數(shù)據(jù)中心、跨云網(wǎng)邊端。
跨平臺
隨著異構(gòu)的資源越來越多,從一個計算階段遷移到本集群或者其他集群其他計算節(jié)點的時候,它的資源種類不一定和當(dāng)前節(jié)點資源一致。這樣,對業(yè)務(wù)能力跨不同架構(gòu)處理器運行提出了更高的要求。比如,業(yè)務(wù)可以跨x86、ARM和riscv CPU處理器運行,業(yè)務(wù)還可以跨CPU、GPU、DSA處理器運行,等等。
便利性,隨時隨地可獲取
相比傳統(tǒng)自建機(jī)房,云計算已經(jīng)實現(xiàn)了算力的方便獲取。但還不夠。隨著AI大模型、自動駕駛、元宇宙XR等各類大算力場景越來越多,對算力的多樣性要求也越來越大,云端算力、多層次的邊緣算力,甚至更加便利的終端算力,都需要納入算力網(wǎng)絡(luò)的范疇,提供宏觀的算力資源整合方案,方便用戶隨時隨地輕松獲取。 總結(jié)一下。通過上述這些方式,以及其他可能的上面沒有提到的方式,來實現(xiàn)宏觀算力資源的充分利用,從而為客戶提供極致成本的海量算力。
審核編輯:湯梓紅
-
處理器
+關(guān)注
關(guān)注
68文章
19159瀏覽量
229113 -
芯片
+關(guān)注
關(guān)注
453文章
50387瀏覽量
421783 -
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7514瀏覽量
88626 -
算力
+關(guān)注
關(guān)注
1文章
925瀏覽量
14740
原文標(biāo)題:算力網(wǎng)絡(luò)系列文章(一):算力提升綜述
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論