") 阿里二面:了解MySQL事務(wù)底層原理嗎
阿里二面:了解MySQL事務(wù)底層原理嗎
MySQL 可以說(shuō)是每個(gè) Java 程序員必會(huì)的技能之一,作為 Java 的高級(jí)進(jìn)階必備技能點(diǎn),MySQL 的調(diào)優(yōu)和底層原理必然是需要知道的。
但是大家似乎形成了一種思維定勢(shì),那就是提到 MySQL 好像就一股腦的往 MySQL 的索引啊、優(yōu)化啊、之類的上面去鉆。本文我們拋開“熱門”的話題,來(lái)和大家一起來(lái)聊一聊比較冷門但比較重要的技術(shù)點(diǎn):MySQL 事務(wù)的底層原理
這事情還得從頭說(shuō)起
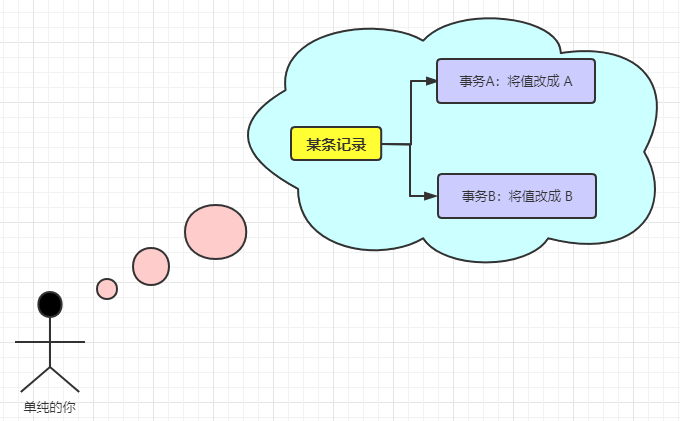
首先大家需要知道的是 MySQL 是支持事務(wù)并發(fā)執(zhí)行的,這又回到了最原始的問(wèn)題了,「并發(fā)安全性問(wèn)題」。在數(shù)據(jù)庫(kù)事務(wù)中并發(fā)問(wèn)題是這樣子的:A 事務(wù)來(lái)寫某條記錄的數(shù)據(jù),B 事務(wù)也在寫該條記錄的數(shù)據(jù)。那如果啥也不做,勢(shì)必會(huì)造成數(shù)據(jù)的錯(cuò)亂,MySQL 在設(shè)計(jì)之初就考慮到了這個(gè)問(wèn)題。
那么 MySQL 到底是如何解決這樣的問(wèn)題的呢?其實(shí)是使用了 MVCC 多版本控制機(jī)制、事務(wù)隔離機(jī)制、鎖機(jī)制等辦法來(lái)解決事務(wù)并發(fā)問(wèn)題。那說(shuō)到這里不知道各位有沒有想過(guò)這樣一個(gè)問(wèn)題:在數(shù)據(jù)庫(kù)中如果并發(fā)事務(wù)不做控制和處理,會(huì)有什么樣的危害呢?
帶著這樣的疑問(wèn),請(qǐng)繼續(xù)往下看。
臟數(shù)據(jù)
什么是臟數(shù)據(jù),它有哪些類型
臟數(shù)據(jù)的具體概念有以下四種,分別是:臟寫、臟讀、不可重復(fù)讀、幻讀。我們來(lái)看看這幾個(gè)概念的意思
1、臟寫
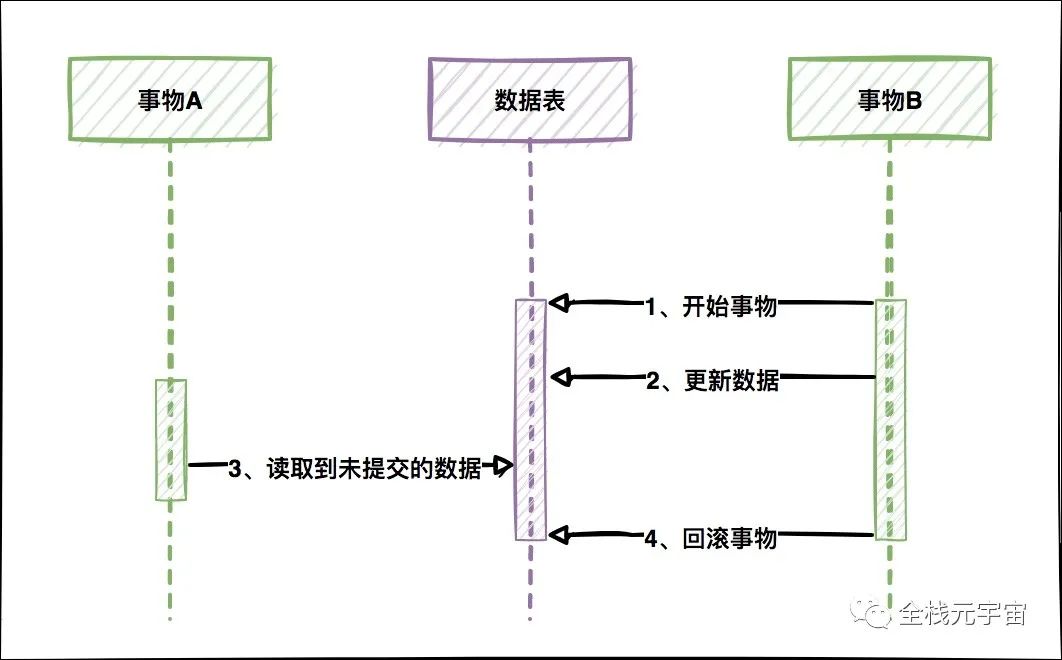
臟寫是指一個(gè)事務(wù)修改且已經(jīng)提交的數(shù)據(jù)被另外一個(gè)事務(wù)給回滾了
首先來(lái)分析一下概念:假設(shè)有兩個(gè)事務(wù) A、B。事務(wù) A 先開啟事務(wù),并且修改了一條 id 為 1 的記錄,將 name 改成 A(假設(shè)原來(lái)為 null),但是此時(shí) 事務(wù) A 還沒有提交。這個(gè)時(shí)候事務(wù) B 開啟了。事務(wù) B 將 id 為 1 的記錄中 name 改成了 B,并且將事務(wù)提交 了。但是這個(gè)時(shí)候事務(wù) A 不想修改了,就像之前自己修改的數(shù)據(jù)回滾了。也就是說(shuō)此時(shí)導(dǎo)致的結(jié)果就是 id 為 1 的這條記錄的 name 還是為 null。
然后事務(wù) B 去查詢這條記錄。結(jié)果蒙了。name 居然為 null。這就是臟寫。事務(wù) B 已經(jīng)寫入的記錄被事務(wù) A 給回滾了。
看不懂沒有關(guān)系,我們先來(lái)看一張圖
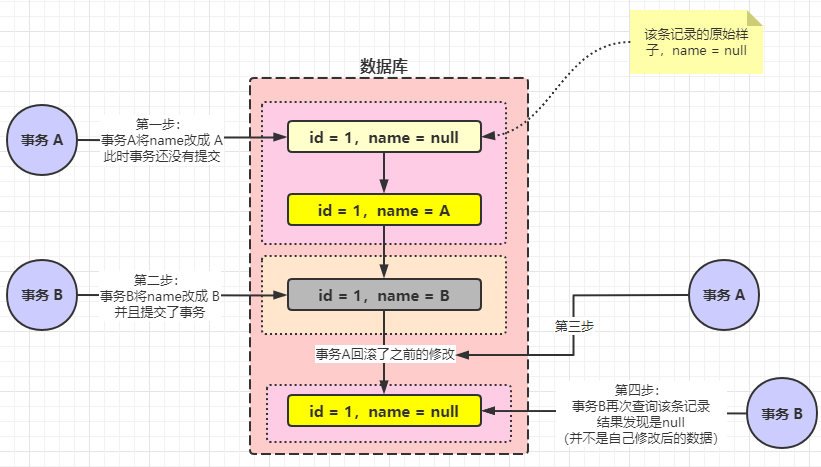
對(duì)著圖再來(lái)看一下上面的分析過(guò)程。
那 MySQL 是如何來(lái)解決臟寫這種問(wèn)題的?沒錯(cuò),就是鎖。MySQL 在開啟一個(gè)事務(wù)的時(shí)候,他會(huì)將某條記錄和事務(wù)做一個(gè)綁定。這個(gè)其實(shí)和 JVM 鎖是類似的。因?yàn)榇藭r(shí)事務(wù) A 先開啟了,并關(guān)聯(lián)綁定了這條記錄。所以事務(wù) B 此時(shí)如果想操作同樣的記錄,只能等待。當(dāng)事務(wù) A 執(zhí)行完成了,就會(huì)通知正在等在事務(wù)。然后下一個(gè)事務(wù)繼續(xù)操作執(zhí)行。
啥?說(shuō)好的并發(fā),這說(shuō)到底不還是串行嗎?這樣數(shù)據(jù)庫(kù)豈不是慢的要死。實(shí)際上這些操作都是在內(nèi)存中執(zhí)行的。具體一點(diǎn)是在 Buffer Pool 中執(zhí)行的。所以速度是非常快的。
2、臟讀
臟讀是指一個(gè)事務(wù)讀取到了另外一個(gè)事務(wù)沒有提交的記錄
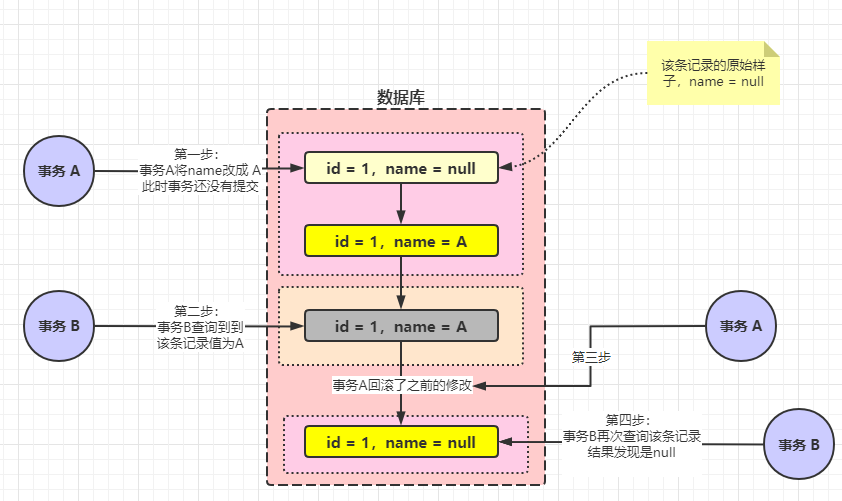
其實(shí)臟讀是最好理解的。我們還是假設(shè)有兩個(gè)事務(wù) A、B。事務(wù) A 先開啟了,將 id 為 1 的記錄中的 name 改成了 A,但是還沒有提交。此時(shí)事務(wù) B 開啟了。事務(wù) B 查詢到當(dāng)前 name 的值為 A,然后就會(huì)按照 A 邏輯去執(zhí)行處理。結(jié)果事務(wù) A 回滾了事務(wù),事務(wù) B 再次查詢的時(shí)候發(fā)現(xiàn)記錄值不是 A。這就是臟讀。
事務(wù) B 讀取到的 name 值是事務(wù) A 修改但是沒有提交的記錄。
來(lái)張圖來(lái)直觀的理解下:
3、不可重復(fù)讀
不可重復(fù)讀是指前后讀取到的某條記錄的結(jié)果不一樣
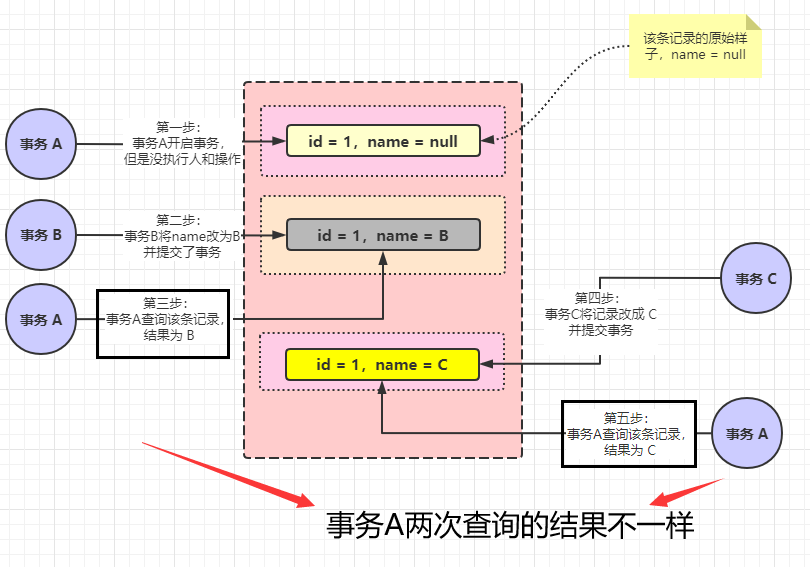
廢話少說(shuō),直接進(jìn)分析:假設(shè)有三個(gè)事務(wù) A、B、C ,事務(wù) A 先開啟了,但是還沒有執(zhí)行任何的操作,事務(wù) B 開啟了,事務(wù) B 將 id 為 1 的記錄的 name 改為 B 并提交了事務(wù),此時(shí)事務(wù) A 開始活動(dòng)了,查詢到的這條記錄的 name 值為 B,還是還未執(zhí)行任何操作。此時(shí)事務(wù) C 開啟了,事務(wù) C 將 id 為 1 的記錄的 name 改為 C 并提交了事務(wù)。此時(shí)事務(wù) A 又開始活動(dòng)了,結(jié)果查詢到的 id 為 1 的 name 值又變成了 C。這就是不可重復(fù)讀
其實(shí)理解起來(lái)還是很簡(jiǎn)單的。看起來(lái)高大上名字,實(shí)際上就這么幾句話就能描述結(jié)束了。下面還是來(lái)一張圖來(lái)更直觀認(rèn)識(shí)下:
4、幻讀
幻讀是指前后讀取到的記錄的數(shù)量不一樣
幻讀和不可重復(fù)讀有點(diǎn)類似,不可重復(fù)讀強(qiáng)調(diào)的是數(shù)據(jù)的值不一樣,重點(diǎn)是修改,而幻讀強(qiáng)調(diào)的是記錄的數(shù)量不一樣,重點(diǎn)是新增或刪除。就好像是看花眼產(chǎn)生重影一樣。
先來(lái)分析一下幻讀。還是假設(shè)有兩個(gè)事務(wù) A、B。事務(wù) A 先開啟了,并執(zhí)行了這樣的 SQL:select * from user,假設(shè)現(xiàn)在結(jié)果是 5 條,此時(shí)事務(wù) B 開啟了,并往 user 表中插入了一條記錄,并提交了事務(wù),此時(shí)事務(wù) A 又執(zhí)行了 select * from user結(jié)果發(fā)現(xiàn)是 6 條記錄。懵逼了。還以為自己餓昏了眼花了。這就是所謂的幻讀。
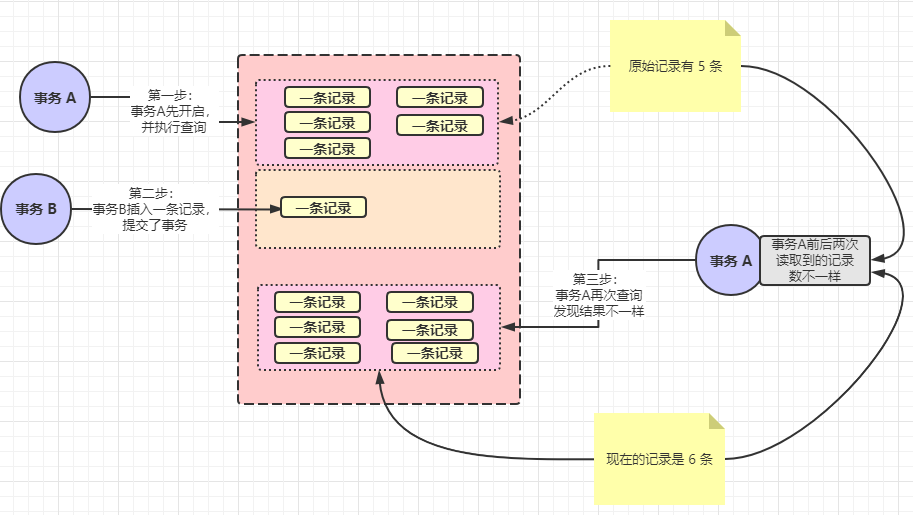
以上的四個(gè)問(wèn)題是現(xiàn)代數(shù)據(jù)庫(kù)典型的問(wèn)題,這些問(wèn)題會(huì)在不同的數(shù)據(jù)庫(kù)的事務(wù)隔離級(jí)別下產(chǎn)生。所以下面要分析的就是事務(wù)的隔離級(jí)別。
事務(wù)的隔離級(jí)別
事務(wù)的隔離級(jí)別有以下四種
-
Read Uncommitted:讀取未提交【生產(chǎn)估計(jì)沒人這么設(shè)置的】
意思就是一個(gè)事務(wù)能夠讀取到另一個(gè)事務(wù)未提交的修改 -
Read Committed[簡(jiǎn)稱 RC]:讀取已提交
意思就是一個(gè)事務(wù)能讀取到另一個(gè)事務(wù)已經(jīng)提交了的修改 -
Repeatable read[簡(jiǎn)稱 RR]:可重復(fù)讀
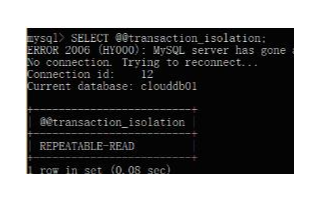
【MySQL 的默認(rèn)隔離級(jí)別】,即事務(wù)之間只要是在進(jìn)行中,彼此之間不會(huì)有任何的干擾 -
serializable:串行化
這個(gè)就有點(diǎn)狠了,就好比 Java 中的 synchroinzed 關(guān)鍵字,所有的請(qǐng)求只能一個(gè)一個(gè)來(lái)還行,很顯然效率最低,基本也不會(huì)使用這種隔離劑唄
| 隔離級(jí)別 | 臟讀 | 臟寫 | 不可重復(fù)讀 | 幻讀 |
|---|---|---|---|---|
| Read Uncommitted:讀取未提交 | √ | × | √ | √ |
| Read Committed:讀取已提交 | × | × | √ | √ |
| Repeatable read:可重復(fù)讀 | × | × | × | √ |
| Serializable:串行化(也有稱序列化的) | × | × | × | × |
MVCC 機(jī)制
MVCC(全稱 Multi-Version Concurrency Control),即多版本并發(fā)控制。MVCC 是一種并發(fā)控制的方法,一般在數(shù)據(jù)庫(kù)管理系統(tǒng)中,實(shí)現(xiàn)對(duì)數(shù)據(jù)庫(kù)的并發(fā)訪問(wèn);
我們本文的重點(diǎn)是事務(wù)的隔離級(jí)別的底層原理,但是似乎說(shuō)到現(xiàn)在也并沒有發(fā)現(xiàn)關(guān)于事務(wù)原理的影子(想發(fā)水文?)。
實(shí)際上要了解事務(wù)的底層原理,根本沒法上來(lái)就開魯,我相信那樣的文章寫出來(lái)不僅沒人看,更是看不懂。所以為了讓大家由淺入深的慢慢掌握。我必須要做很多鋪墊,將相關(guān)的知識(shí)點(diǎn)進(jìn)行拋磚引玉,然后一層一層剖析到原理。這里還請(qǐng)大家明白。
說(shuō)到這里,我們又要提到一個(gè)新的概念了。就是數(shù)據(jù)在磁盤存儲(chǔ)的時(shí)候,每一條存儲(chǔ)的記錄都會(huì)有事務(wù) ID 和回滾指針(其他的是什么本文不需要關(guān)注,學(xué)習(xí)抓住脈路即可,否則必定走火入魔)。

這兩個(gè)到底是干嘛的?我們還是先從概念說(shuō)起
事務(wù) ID:就是每個(gè)事務(wù)的唯一標(biāo)識(shí)回滾指針:該事務(wù)之前的記錄的引用(指針)。換句話說(shuō)就是相對(duì)現(xiàn)在時(shí)間節(jié)點(diǎn)的老數(shù)據(jù)
假設(shè)你需要操作某條記錄,首先該條記錄一定是先被加載到 Buffer Pool 中的,并且有這樣的一條 undo log 記錄。
畫外音:undo log 就是修改前的記錄。用于回滾的。

假設(shè)現(xiàn)在事務(wù) A 開啟了事務(wù),將值改為 A
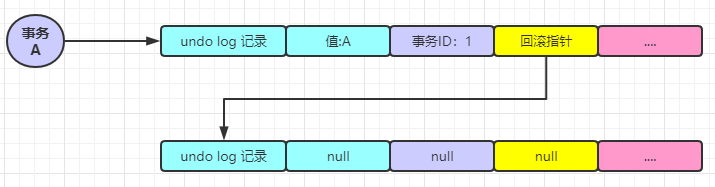
事務(wù) A 還在活躍中,這個(gè)時(shí)候事務(wù) B 開啟了,將值改為 B
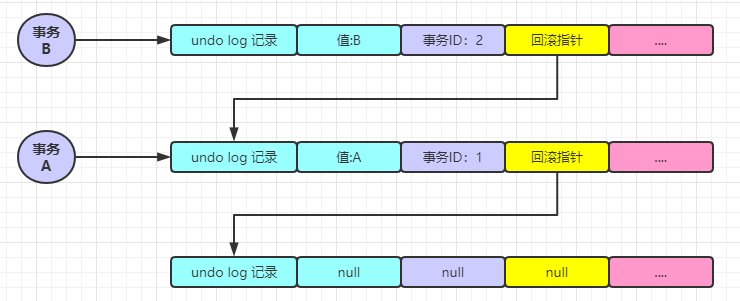
此時(shí)事務(wù) A 和事務(wù) B 都還在活躍中,這個(gè)時(shí)候事務(wù) C 開啟了,并將值改為 C
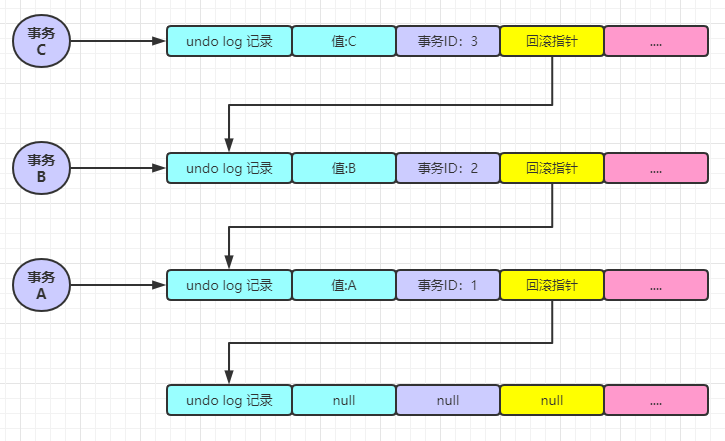
看到這里是不是稍微有一點(diǎn)感覺了。這上面的圖有一個(gè)專有名詞:MVCC 版本控制鏈。同時(shí)這里又涉及到一個(gè)新的名詞:ReadView。就是每個(gè)事務(wù)在開啟的時(shí)候都會(huì)創(chuàng)建一個(gè) ReadView 視圖。那具體什么叫 ReadView ,我們這里還不能一帶而過(guò),相反需要我們來(lái)詳細(xì)的討論分析下。
ReadView
ReadView 可能是你理解事務(wù)底層原理的核心部分,那么什么是 ReadView 呢
在每個(gè)事務(wù)開啟的時(shí)候都會(huì)創(chuàng)建一個(gè) ReadView 視圖,作用就是用來(lái)記錄每個(gè)事務(wù)中的操作的一些 Undo Log 記錄。
他里面涉及到幾個(gè)字段。分別是:m_ids、min_trx_id、max_trx_id、creator_trx_id。他們的具體含義如下:
-
m_ids:用于記錄活躍中的事務(wù)的 ID;
-
min_trx_id:當(dāng)前活躍的事務(wù)中的最小的事務(wù) ID;
-
max_trx_id:下一個(gè)即將要生成的事務(wù) ID。注意這里并不是指的最大的事務(wù) ID,這個(gè)事務(wù)一定是當(dāng)前的 m_ids 中不存在的。(事務(wù) ID 的生成是遞增的);
-
creator_trx_id:當(dāng)前活躍事務(wù)的 ID;
不要慌,光說(shuō)概念一定是在耍流氓。下面我會(huì)通過(guò)圖文并茂的形式來(lái)一一說(shuō)明解釋。假設(shè)有一個(gè)記錄現(xiàn)在是這樣存放的

看到這里大家應(yīng)該知道的是,這條記錄一定是原來(lái)的某一個(gè)事務(wù)修改后的結(jié)果。也就是說(shuō)這是一條原本的已經(jīng)存在的記錄。
現(xiàn)在假設(shè)有 A、B、C 三個(gè)事務(wù),他們分別先后開啟,假設(shè)他們的事務(wù) ID 依次為:4、5、6。
先來(lái)看事務(wù) A,此時(shí)的m_ids 為:[4、5、6],min_trx_id 為:4,max_trx_id 為 7(下圖第三行為max_trx_id),creator_trx_id 為 4。
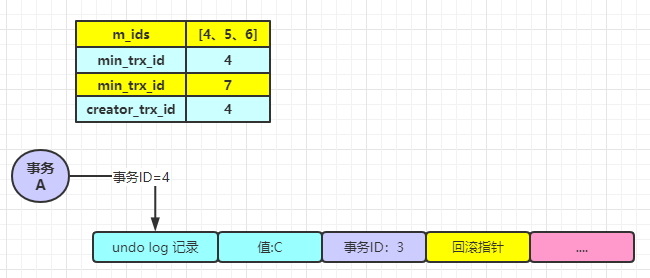
事務(wù) A 首先執(zhí)行了一次查詢操作,他此時(shí)是這么執(zhí)行的:
首先他會(huì)順著 MVCC 的版本控制鏈往下找。找啥?找該條記錄的以前操作它的事務(wù) ID,他發(fā)現(xiàn)找到的這個(gè) undolog 日志的對(duì)應(yīng)的事務(wù) ID 為 3,比自己的 4 要小,所以可以肯定這條記錄不是自己修改的,而又因?yàn)?m_ids 中的事務(wù) ID 為 4、5、6,3 是比他們都要小的,所以可推斷出查找到的這條記錄是在本次事務(wù)開啟之前就已經(jīng)存在的。所以事務(wù) A 查詢到的值為 C。
此時(shí)事務(wù) B 同樣開始查詢這條記錄了。以此類推事務(wù) B 此時(shí)的執(zhí)行流程大概是這樣子的,首先事務(wù) B 會(huì)以同樣的方式查詢數(shù)據(jù)(PS:這些操作都是在內(nèi)存中的)同樣查詢到的結(jié)果是 C,經(jīng)過(guò)上面的的對(duì)于事務(wù) A 的分析,相信這里已經(jīng)不是問(wèn)題了。但是假如現(xiàn)在事務(wù) B 將該值改成了 B,也就是下面的這張圖的樣子。
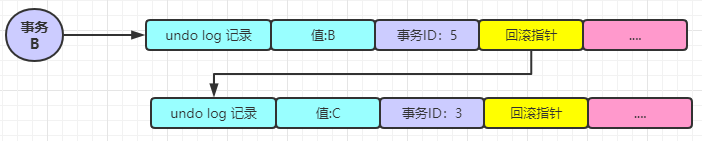
此時(shí)事務(wù) A 又開始活躍了,還是執(zhí)行查詢操作,這個(gè)時(shí)候結(jié)果該是多少呢?
首先事務(wù) A 發(fā)現(xiàn)同樣會(huì)順著該條記錄的 MVCC 版本控制鏈往下找,發(fā)現(xiàn)事務(wù) ID 為 5 ,比 m_ids 中的最小的事務(wù) ID 4 要大,那么可以且是存在于該集合中的,此時(shí)就可以斷定事務(wù) ID 為 5 的事務(wù)是正在進(jìn)行中的事務(wù),所以事務(wù) A 是不會(huì)取該條 undo log 的值的。
然后繼續(xù)往下找,找到了事務(wù) ID 為 3 的 undo log 記錄,對(duì)比后發(fā)現(xiàn) 3 不在 m_ids 中,且比 m_ids 中的最小的事務(wù) ID 都要小。下面的判斷就和剛開始的查詢判斷一樣了。
假設(shè)此時(shí)事務(wù) A 將該條記錄的值改成 A ,然后事務(wù) A 再查詢這條記錄,那么請(qǐng)問(wèn)這個(gè)時(shí)候事務(wù) A 查詢是怎么樣子的(這一步非常重要)?現(xiàn)在這些事務(wù)以及數(shù)據(jù)在我們的腦袋中應(yīng)該是這樣子的:
那么事務(wù) A 到底是怎么查詢的?查出來(lái)的結(jié)果到底是 A 還是 B?先來(lái)看下這張圖,然后根據(jù)圖一步一步來(lái)分析
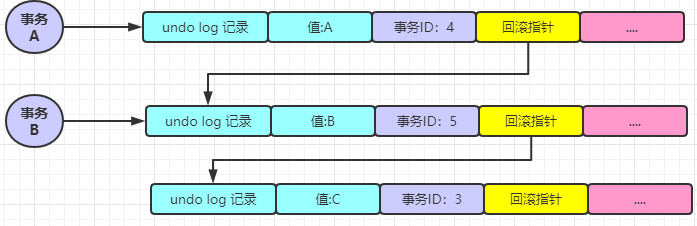
事務(wù) A 開始查詢,返現(xiàn)此時(shí)的 undo log 日志針對(duì)于該條記錄的 undo log 鏈(MVCC 版本鏈的另一種叫法)的第一條記錄的事務(wù) ID 為 4 ,一對(duì)比發(fā)現(xiàn)不就是自己修改的值嗎?那么查詢的結(jié)果就是 A。
那么此時(shí)如果是事務(wù) B 來(lái)執(zhí)行查詢呢?結(jié)果你能否分析一下?那就是首先 B 發(fā)現(xiàn)最新的事務(wù) ID 為 4 ,且在 m_ids 中,可以斷定這是一條正在執(zhí)行中的事務(wù),且不和自己的一樣,所以是不會(huì)取該值的。
然后繼續(xù)順著 undo log 日志鏈往下找,找到了事務(wù) ID 為 5 的記錄,發(fā)現(xiàn)和自己的一樣,那這個(gè)不就是需要查找的結(jié)果嗎?也就是說(shuō) 事務(wù) B 查找到的結(jié)果是 B。
以上是關(guān)于 ReadView 的相關(guān)的介紹,總體內(nèi)容不算難,但是是需要認(rèn)真思考的,這里先來(lái)一個(gè)小總結(jié)
-
ReadView 其實(shí)使用版本鏈機(jī)制
-
他里面的核心屬性為:
-
m_ids: 一個(gè)列表, 存儲(chǔ)當(dāng)前系統(tǒng)活躍的事務(wù) id (重點(diǎn))
-
min_trx_id: 當(dāng)前 m_ids 活動(dòng)事務(wù)中的最小的事務(wù) ID
-
max_trx_id: 下一個(gè)即將被分配出來(lái)的事務(wù) ID
-
creator_trx_id: 當(dāng)前的事務(wù)的 ID
-
ReadView 記錄的是:每個(gè)事務(wù)中的 Undo log 日志
說(shuō)到這里,下面繼續(xù)來(lái)分析本文的主題知識(shí)點(diǎn):事務(wù)的底層原理(其實(shí)上面多多少少都說(shuō)到了)。其實(shí)事務(wù)的底層就是基于 ReadView 來(lái)設(shè)計(jì)的。關(guān)于事務(wù)的底層原理,我們以 RC(Read Commit)和 RR(Repeatable read)來(lái)分析
1. Read commit
Read Commit 是事務(wù)隔離級(jí)別的其中一種,含義是:讀取已經(jīng)提交的記錄。舉個(gè)例子來(lái)說(shuō),假設(shè)有事務(wù) A 和事務(wù) B 都在活動(dòng)中,事務(wù) B 提交的記錄是能夠被事務(wù) A 讀取到的。
具體我們開始一步一步來(lái)分析。首先需要大家知道的是在 RC 隔離級(jí)別下,一個(gè)事務(wù)的每次查詢操作,數(shù)據(jù)庫(kù)都會(huì)為其創(chuàng)建一個(gè)新的 ReadView,這就是 RC 的核心思想。
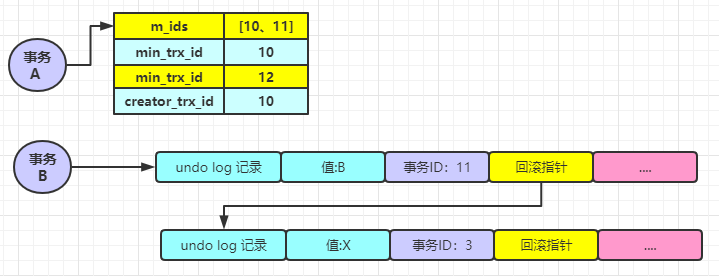
假設(shè)有事務(wù) A 和事務(wù) B ,事務(wù) ID 分別為 10 和 11,事務(wù) A 還沒開始活躍,事務(wù) B 就將某條記錄的值改為 B(假設(shè)原來(lái)的值為 X),但是還未提交,現(xiàn)在你可以想象一下下面這張圖:

此時(shí)事務(wù) A 開始活躍了,他首先執(zhí)行了一次查詢操作。按照上面的核心思想,此時(shí)數(shù)據(jù)庫(kù)會(huì)重新創(chuàng)建一個(gè) ReadView 里面的幾個(gè)屬性的值分別為:
-
m_ids:[10,11]
-
min_trx_id:10
-
max_trx_id: 12
-
creator_trx_id:10
接著就是就是和上面說(shuō)過(guò)的一樣的查詢過(guò)程了,首先 A 查詢到的最近的一個(gè)事務(wù) ID 為 11,發(fā)現(xiàn)在 m_ids 中,但是又和自己的事務(wù) ID 不相等,所以就會(huì)順著 undo log 鏈繼續(xù)查找,然后找到了事務(wù) ID 為 3 的記錄,發(fā)現(xiàn)不在 m_ids 中且,比最小的事務(wù) ID 10 還要小,所以可以斷定出事務(wù) ID 為 3 的這個(gè)記錄是原本就存在的記錄,所以查詢到的結(jié)果就是 X。
接著事務(wù) B 又開始活躍了,事務(wù) B 直接提交了事務(wù),然后事務(wù) A 又發(fā)起了一起查詢操作。現(xiàn)在這個(gè)時(shí)候就是 RC 的核心了:這個(gè)時(shí)候數(shù)據(jù)庫(kù)會(huì)再次為事務(wù) A 創(chuàng)建一個(gè)新的 ReadView 里面的四個(gè)屬性分別為:
-
m_ids:[10]
-
min_trx_id:10
-
max_trx_id: 12
-
creator_trx_id:10
然后 A 按照正常的流程去查詢,首先查詢到的是事務(wù) ID 為 11 的記錄,結(jié)果發(fā)現(xiàn)不在 m_ids 中,那這個(gè)時(shí)候就可以斷定的是:這個(gè)是最近已經(jīng)提交的記錄,所以是能夠查詢到 B 這個(gè)值的,也就是說(shuō)這次查詢得到的結(jié)果就是 B 。
這就是 RC,是不是如果看懂了 ReadView 原理,這些再看起來(lái)就非常簡(jiǎn)單了?
2. Repeatable read
Repeatable read 是 MySQL 默認(rèn)的隔離級(jí)別,既然是默認(rèn)的,那一定是很厲害咯?其實(shí)你看完會(huì)發(fā)現(xiàn) just so so ?
RR 的核心思想是:ReadView 創(chuàng)建以后直到事務(wù)提交,都不會(huì)再次重新生成。
首先還是有事務(wù) A 和事務(wù) B,事務(wù) ID 分別為 10 和 11 ,事務(wù) B 首先將值改為 B (假設(shè)原來(lái)值為 X),然后 事務(wù) A 發(fā)起了一次查詢的操作:
查詢過(guò)程和前面的一模一樣。我就不再贅述了。
接著事務(wù) B 又開始活躍了,直接提交了事務(wù),然后事務(wù) A 又發(fā)起了一次查詢。這個(gè)時(shí)候奇跡就出現(xiàn)了。因?yàn)槲覀儎倓傉f(shuō)了:ReadView 創(chuàng)建以后直到事務(wù)提交,都不會(huì)再次重新生成。因?yàn)槭聞?wù) A 在創(chuàng)建 ReadView 的時(shí)候 m_ids 是 10 和 11,所以現(xiàn)在查詢的時(shí)候里面仍然是這個(gè)值,現(xiàn)在的查詢是這樣子的:事務(wù) A 首先查詢到的事務(wù) ID 為 11 ,結(jié)果發(fā)現(xiàn)在 m_ids 中,也就不會(huì)取該值,會(huì)繼續(xù)查找,當(dāng)查找到事務(wù) ID 為 3 的時(shí)候,發(fā)現(xiàn)不在 m_ids 中,所以查詢到的就是 X。
現(xiàn)在你知道為什么這個(gè)隔離級(jí)別下的事務(wù)不會(huì)互相干擾了吧?這就是原理
本文小結(jié)
本文為了說(shuō)明事務(wù)的底層原理,做了大量的鋪墊,相信大家看完不光對(duì)不同隔離級(jí)別下事務(wù)的實(shí)現(xiàn)會(huì)有更深刻地理解,也同時(shí)明白了 undo log 記錄的作用,所以多探索一下底層你會(huì)發(fā)現(xiàn)各種知識(shí)點(diǎn)是如何串在一起工作的,這種通透的感覺確實(shí)很奇妙^_^
-
JAVA
+關(guān)注
關(guān)注
19文章
2958瀏覽量
104546 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3765瀏覽量
64276 -
MySQL
+關(guān)注
關(guān)注
1文章
802瀏覽量
26444
原文標(biāo)題:阿里二面:了解 MySQL 事務(wù)底層原理嗎
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
在制造多層板的時(shí)候,最底層的基板,它二面鍍銅,二面都要腐蝕電路嗎?
全球唯一:MySQL社區(qū)2018年度公司貢獻(xiàn)獎(jiǎng)?lì)C給阿里云
比傳統(tǒng)事務(wù)快10倍?一張圖讀懂阿里云全局事務(wù)服務(wù)GTS
雙11同款!阿里云發(fā)布全局事務(wù)服務(wù)GTS:每秒處理10萬(wàn)筆事務(wù)
詳解Mysql數(shù)據(jù)庫(kù)InnoDB存儲(chǔ)引擎事務(wù)
關(guān)于MySQL事務(wù)一個(gè)多小時(shí)的面試 太難了
MySQL事務(wù)日志
MySQL事務(wù)的四大隔離級(jí)別詳解
MySQL的底層原理和技術(shù)學(xué)習(xí)
MySQL事務(wù)隔離級(jí)別要實(shí)際解決的問(wèn)題
你是否對(duì)MySQL數(shù)據(jù)庫(kù)中的事務(wù)已經(jīng)有所了解呢?
MYSQL事務(wù)的底層原理詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論